23,019 candidates and the patch bottleneck Mythos exposed
Anthropic CVD dashboard shows that verification, disclosure, and patch delivery are becoming the new bottleneck in AI-assisted security.
- What happened: Anthropic published an initial
Project Glasswingupdate and a Coordinated Vulnerability Disclosure dashboard.- The dashboard snapshot is dated May 22, 2026 at 10:27 PT and covers an open-source vulnerability disclosure pipeline.
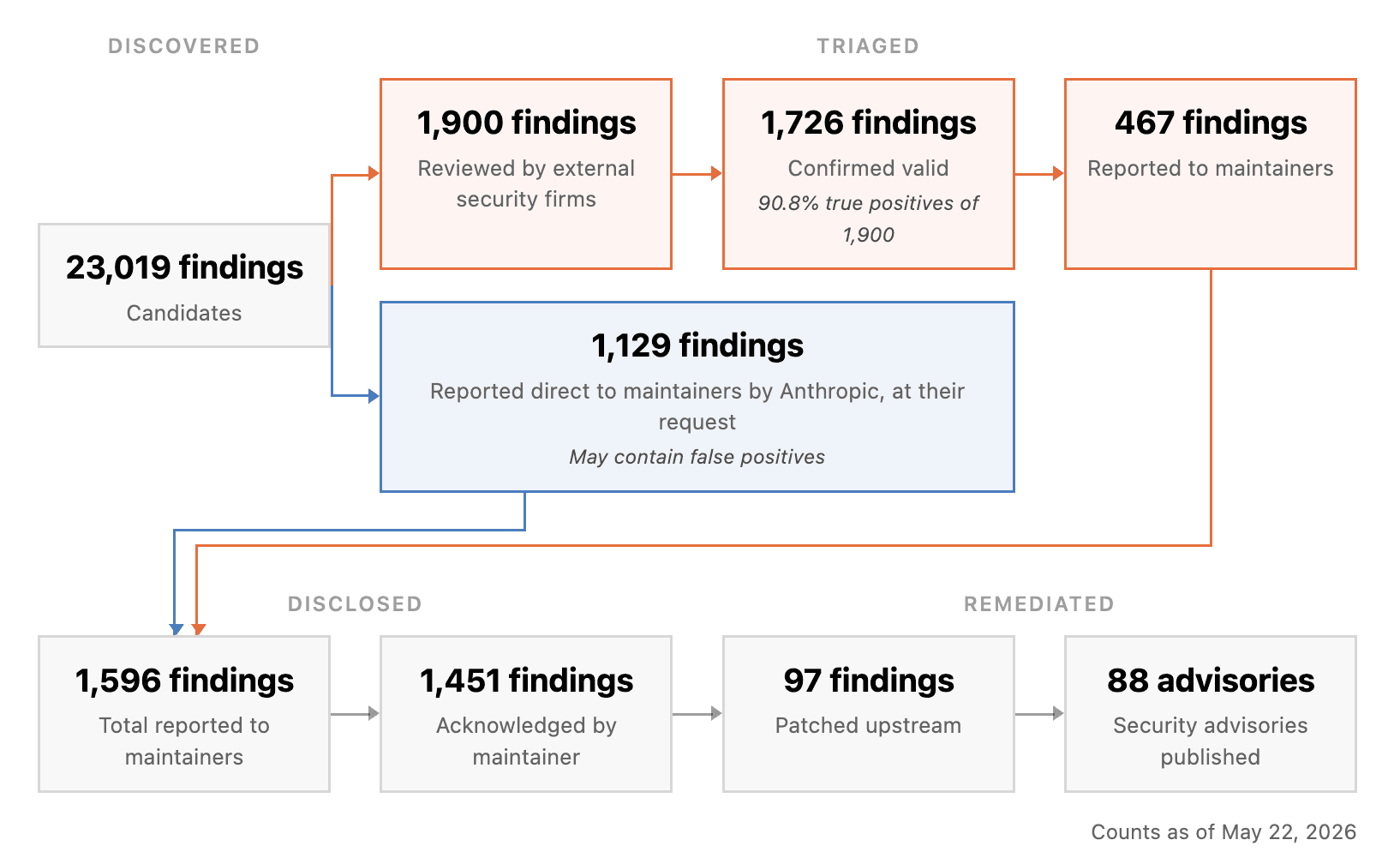
- The numbers: Mythos Preview produced 23,019 candidate findings, 1,596 disclosed findings, 97 upstream patches, and 88 advisories.
- Why it matters: The bottleneck is moving from discovery models to human triage, maintainer response, and patch delivery.
- Anthropic says independent validation and review are now the rate-limiting steps.
- Watch: More vulnerability reports can also mean more verification work for open-source maintainers.
On May 22, 2026, Anthropic published an initial Project Glasswing update and a separate Coordinated Vulnerability Disclosure dashboard. The news is easy to flatten into a headline about Claude Mythos Preview finding many vulnerabilities. That misses the more useful signal. The dashboard puts numbers around what happens after discovery, and those numbers show where the new bottleneck is forming.
The dashboard snapshot is dated May 22, 2026 at 10:27 PT. Anthropic says it began using an early snapshot of Claude Mythos Preview in February 2026 to search for security vulnerabilities in open-source software. The company then worked with external security research firms to validate candidate findings before reporting them to maintainers. The headline counts are stark: 23,019 candidate findings, 1,596 disclosed findings, 281 affected open-source projects, 97 upstream patches, and 88 CVE or GitHub Security Advisory entries.
The shape of those numbers matters more than any single count. AI-generated candidates are already above 20,000, while public advisories and upstream patches are still in double digits. Anthropic does not frame that gap only as a failure. It argues that once the cost of vulnerability discovery falls, independent validation, responsible disclosure, maintainer communication, patch design, and user rollout become the new limiting factors. For developers and security teams, the practical question becomes less "can a model find bugs?" and more "who verifies the findings, and how do we turn them into safe patches?"

Glasswing's first public scorecard
Project Glasswing is Anthropic's cyber-defense initiative announced in April 2026. Its core premise is controlled access to Claude Mythos Preview for infrastructure companies, security organizations, and the open-source ecosystem, with the goal of finding and fixing vulnerabilities before attackers can exploit them. Anthropic did not release Mythos Preview broadly. The stated reason is straightforward: a model this capable can help defenders, but it can also make flawed software cheaper and faster to exploit.
The May 22 update shows both sides of that tradeoff. Anthropic says roughly 50 partners used Claude Mythos Preview for a month and found more than 10,000 high or critical severity vulnerabilities across important software. Some partners reported a bug-finding rate increase of more than 10x. Anthropic also cites Cloudflare, saying the company found 2,000 bugs in critical-path systems, with 400 of them rated high or critical.
Mozilla is another notable example. Anthropic says Mozilla tested Firefox 150 with Mythos Preview and found and fixed 271 vulnerabilities, more than 10x the count found in Firefox 148 with Claude Opus 4.6. The point is not that AI has replaced security researchers. The point is that the throughput of security testing is changing. Models can repeatedly inspect code paths that previously sat outside the practical budget of expert time, and the resulting input volume now has to fit into existing patch cadences.
Most partner results remain aggregated. Vulnerability details are not all public, and Anthropic explains that through responsible disclosure norms. Publishing exploit details before patches and user updates are available can help attackers. That is why the useful artifact here is not an exploit write-up, but a pipeline: candidates, validation, disclosure, maintainer acknowledgement, patch, and advisory. The process numbers are the story.
From 23,019 candidates to 97 patches
The CVD dashboard splits the open-source process into two visible paths. The first path is externally reviewed. Claude Mythos Preview produced 23,019 candidate findings. Of those, 1,900 were sent for review by external security firms, and the dashboard marks 1,726 as confirmed valid. It also reports a 90.8% true-positive rate against that reviewed set.
The second path is direct maintainer reporting by Anthropic at maintainer request. The dashboard lists 1,129 findings reported directly to maintainers through this route. It also notes that false positives may appear in that direct path. This is the important operational tradeoff. If every finding waits for full independent validation, precision improves but the pipeline slows down. If more findings go directly to maintainers, response can start sooner, but maintainers inherit more verification work.
The public output count is 1,596 disclosed findings. Of those, 1,451 received maintainer acknowledgement, 97 reached upstream patch status, and 88 became CVE or GitHub Security Advisory entries. The dashboard also includes public examples, including a heap-buffer-overflow in jq, a heap buffer overflow in MapServer, broken access control in temporalio/temporal, crypto failure and signature bypass issues in wolfSSL, and a path traversal issue in nomad.
Those numbers need careful reading. A 97-patch count does not mean the other 1,499 disclosed findings were ignored. Anthropic says the process is still early in a 90-day disclosure window, and some fixes can land quietly without a public advisory. The patch count may therefore understate remediation. Still, the bottleneck is real. The official update explicitly points to the gap between relatively easy vulnerability discovery and difficult vulnerability fixing as a central cybersecurity challenge.
Discovery is no longer the only hard part
For the last few years, AI security coverage has often revolved around two questions. Can a model find vulnerabilities? Can it write exploits? Mythos Preview and Glasswing push that discussion forward. The harder question now is: what operating system can handle a flood of plausible findings?
Anthropic says it scanned more than 1,000 open-source projects, and that Mythos Preview estimated 6,202 high or critical candidate vulnerabilities. The company evaluated 1,752 of them, found 1,587 to be true positives, and confirmed 1,094 as high or critical. That is a 90.6% true-positive rate for the evaluated set, with 62.4% confirmed as high or critical. Anthropic further estimates that, if current true-positive rates hold, the existing candidate pool could surface roughly 3,900 high or critical open-source vulnerabilities.
Those are strong claims. But the next sentence is the more operationally important one: Anthropic says a high or critical bug found by Mythos Preview takes an average of two weeks to patch. It also says some maintainers asked the company to slow the disclosure rate. The reason is practical. Open-source maintainers are already dealing with low-quality AI-generated bug reports. Adding a stream of higher-quality Mythos findings can still create a throughput problem.
This is the paradox of AI-assisted security. Better tools find more real problems. Real problems still need people to read them, reproduce them, reassess severity, design patches, run regression tests, write advisories, and ship releases. As finding volume rises, security teams may become more effective, while maintainer queues become more strained. The value of an AI security product therefore cannot stop at "we found it." It has to extend to "we supplied evidence, a patch path, tests, and a disclosure flow that maintainers can actually use."
Mythos capability and the limits of disclosure
Anthropic's Claude Mythos Preview technical post makes a stronger case about the model's capability. It describes Mythos Preview autonomously finding and exploiting a 17-year-old remote code execution vulnerability in FreeBSD. It also describes a Linux kernel local privilege escalation built by chaining multiple vulnerabilities, along with examples in browser JIT heap spraying, cryptography library weaknesses, and web application logic flaws.
Most of the details are still withheld because many vulnerabilities are unpatched or only recently patched. Anthropic says it has made cryptographic commitments and will disclose more details after disclosure windows close. The CVD dashboard also includes a hash commitment ledger for findings that cannot yet be public. This is not full transparency, but it is a compromise: Anthropic can later show that it possessed a specific finding at a specific time without immediately releasing exploit material.
For developers, that compromise is uncomfortable but realistic. Vulnerability information is research output and, potentially, an attack manual. If AI can also assist exploit writing, timing and disclosure granularity become more sensitive. The dashboard is therefore closer to process transparency than technical transparency. It tracks which projects are affected, which stage a finding has reached, whether an advisory exists, and whether a patch has landed.
The limitation is also clear. Aggregate numbers can be persuasive, but outside readers cannot independently evaluate every finding's exploitability or severity. That is one reason some security communities remain skeptical about Mythos hype. More public examples should reduce that uncertainty over time, but for now the tension between private disclosure and public verification remains part of the story.
A new burden for open-source maintainers
The most grounded part of the update is about maintainer capacity. Anthropic says maintainers are already facing a flood of low-quality AI-generated bug reports, and that some asked for a slower disclosure pace. This sentence captures the hard side of the AI security race. AI becoming better at finding vulnerabilities is not the same thing as the whole security ecosystem becoming healthier.
Open-source maintainers are usually not full-time security teams. Even popular libraries can depend on a small group of maintainers who handle issues, pull requests, releases, documentation, and user support. When a large number of reports arrive labeled high or critical, maintainers first have to ask whether each one is real. They need to recreate the environment, identify affected versions, evaluate exploitability, add regression coverage, release a fix, and communicate with downstream users.
Some of that work is model-friendly. A model can trace code paths, draft a proof of concept, suggest a patch, and generate a test. Other parts depend on project context. Maintainers know compatibility constraints, release policy, API stability, distribution channels, and downstream ecosystems. A security patch is not just a code edit. It is release engineering. A rushed fix can break users, while a delayed fix leaves an attack window open.
That is why Anthropic's broader references to Claude Security public beta, skills, harnesses, a threat model builder, and the Cyber Verification Program matter. Vulnerability discovery alone will not clear the maintainer bottleneck. The needed tools convert findings into reproducible evidence, minimal patches, regression tests, advisory drafts, and release checklists. The best AI security workflow should not throw 100 candidate vulnerabilities over the wall. It should reduce the steps needed to verify and fix them.
The same question as OpenAI Daybreak
This arc connects to OpenAI's Daybreak direction as well. OpenAI has been positioning GPT-5.5-Cyber, Trusted Access for Cyber, and Codex Security around vulnerability discovery, threat modeling, patch validation, and detection engineering as one security flywheel. Anthropic is surfacing a partner and open-source CVD pipeline through Mythos Preview and Project Glasswing. The products differ, but the question is the same: who gets access to powerful cyber models, under what controls, and inside what workflow?
Anthropic's distinctive move is controlled access plus a public dashboard for disclosure status. OpenAI's direction is closer to putting models inside trusted defensive teams and Codex Security workflows. Add AWS Security Agent and Microsoft's AI application misconfiguration research, and the AI security race has three axes: model capability, execution harness, and operating governance.
The CVD dashboard makes the third axis visible. Model capability can be shown through benchmarks and case studies. Governance shows up in pipeline flow: how many candidates, how many independent reviews, how many maintainer acknowledgements, how many patches, how many advisories. Without that flow, "AI improved security" remains a claim. With it, the industry can start checking whether discovery is actually turning into remediation.
What engineering teams should watch now
First, revisit dependency patch cycles. If Mythos-class systems can find vulnerabilities faster, attackers will eventually have similar capabilities. Anthropic says this explicitly. When discovery and exploitation costs fall, leaving old dependencies unpatched for weeks becomes riskier. Teams should move beyond simply watching Dependabot alerts and measure how quickly they can test and deploy critical fixes.
Second, if teams adopt AI security review for internal code, they need to design triage capacity at the same time. Turning on a scanner increases reports. More reports mean more validation work for security and engineering teams. Without finding quality controls, reproduction evidence, severity criteria, duplicate removal, patch suggestions, and test generation, the tool can amplify alert fatigue.
Third, the responsibility split between open-source maintainers and corporate consumers needs to change. Companies cannot assume every maintainer of a critical dependency has the capacity to absorb a surge of AI-generated vulnerability reports. For important dependencies, users may need to help with patch testing, backports, funding, and security review.
Fourth, vulnerability disclosure dashboards may become a product feature. AI security tools will need to show more than "we found N issues." The useful metrics are how many findings were validated, how many were patched, how many reached production, and where the queue is stuck. Security KPIs are moving from finding count to remediation flow.
The gap between finding and fixing
The main significance of this update is not that AI can find vulnerabilities. Benchmarks and earlier case studies had already pointed in that direction. What Anthropic's CVD dashboard makes visible is the gap between discovery speed and patch speed. Between 23,019 candidates and 97 upstream patches sits an older software operations problem.
That gap will not disappear quickly. A vulnerability is not just a code finding. It becomes resolved only after maintainers understand it, users update, downstream distributions reflect the fix, enterprise security teams test it, and production systems deploy it without breaking. AI can help many parts of that path, but accountability, approval, and user impact still sit with people.
Glasswing's first scorecard therefore contains both optimism and warning. The optimistic read is real: AI can surface many more hidden vulnerabilities, and some can be connected to patches quickly. The warning is just as real: if the security ecosystem stays unchanged, a flood of findings may create bottlenecks and fatigue before it creates stronger defenses. The next competition will be less about who finds the most vulnerabilities and more about who builds the best verified patch flow.