AI Agent Index exposes the transparency gap behind 25 agents
The 2025 AI Agent Index finds that 25 of 30 deployed agents do not disclose internal safety results as autonomy moves faster than public evidence.

- What happened: The
2025 AI Agent Indexcompares 30 deployed AI agents across capability, autonomy, ecosystem behavior, and safety disclosure.- The May 6, 2026 arXiv v2 release is paired with an official interactive database that annotates each agent across 45 fields.
- Core numbers: 25 of 30 agents do not disclose internal safety results, and 23 of 30 provide no public third-party testing information.
- Why it matters: Agent adoption is shifting from model performance toward procurement evidence around
permissions,logs, andevaluation scope. - Watch: The Index is a public-information snapshot. Missing documentation does not prove missing safeguards, but it does make external verification harder.
The easiest way to describe the AI agent market is still capability. Agents browse websites, edit code, update CRM records, classify tickets, prepare payments, draft reports, and call internal APIs. Most product announcements in the last few months have followed that same track: longer tasks, more tools, more connectors, and higher autonomy.
The harder question appears only when a company tries to deploy one of these systems. What authority does the agent use when it acts? Can it be stopped in the middle of execution? Can a security team reconstruct which tools it called and which observations it used? Did the vendor publish internal safety results? Was the full agentic system tested by an outside party? When the agent touches external websites, does it identify itself as an agent? If something goes wrong, where does responsibility sit: the model provider, the agent vendor, the MCP server, or the deploying organization?
The revised May 6, 2026 release of The 2025 AI Agent Index puts those questions at the center. The project includes researchers from MIT CSAIL, the University of Cambridge, Harvard Law School, Stanford University, Concordia AI, the University of Pennsylvania, and the Hebrew University of Jerusalem. Its official AI Agent Index site documents 30 deployed AI agents across 45 fields and presents the result as an interactive database.
The point is not to crown the best agent. The more important finding is that agent functionality is expanding faster than public safety and accountability evidence. It is notable that 24 of the 30 agents were launched or received major agentic updates in 2024 or 2025. It is more important that 25 do not disclose internal safety results, and 23 disclose no third-party testing information.
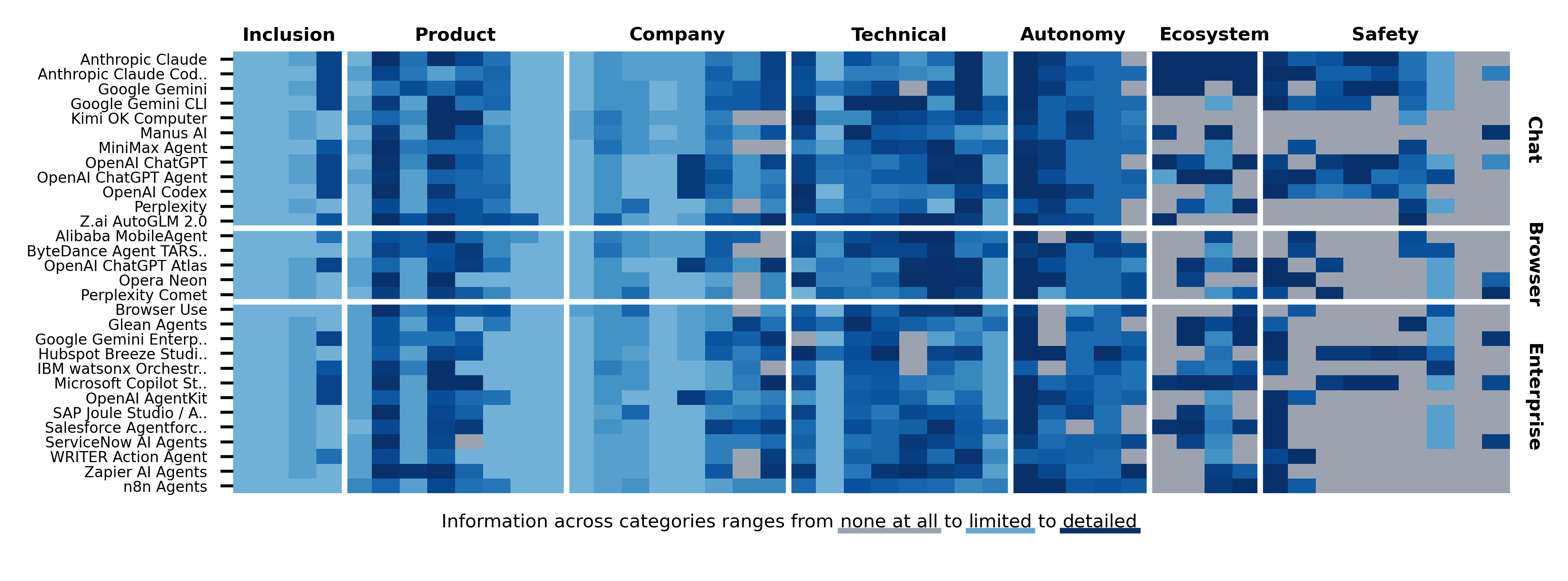
Why the Index uses 45 fields
The AI Agent Index does not treat an agent as just a model name or a product category. The researchers reviewed 95 candidates and selected 30 that met criteria around agency, impact, and practicality. The snapshot date is December 31, 2025.
Agency means the system can operate with limited human supervision, pursue longer goals and subgoals, interact with an environment through tools or APIs, and generalize across tasks. Impact means the product has meaningful public or market attention, measured through signals such as search interest, GitHub stars, valuation, or participation in safety commitments. Practicality means the system is accessible, deployable, and not locked to a single narrow industry use case.
The selected systems fall into three groups: 12 chat agents, 5 browser agents, and 13 enterprise agents. The list includes names that developers and platform teams already evaluate in practice, such as Claude, Claude Code, Gemini, Gemini CLI, ChatGPT, ChatGPT Agent, Codex, Perplexity, Comet, Manus, Copilot Agents, Agentforce, Joule Agents, ServiceNow AI Agents, and Zapier Agents.
The 45 annotation fields are grouped into six categories: product overview, company and accountability, technical capabilities and architecture, autonomy and control, ecosystem interaction, and safety, evaluation, and impact. Seven subject-matter experts annotated by field rather than by agent, and each annotation was reviewed by at least one other annotator. The paper says disagreements in 37 of 1,350 fields were resolved through discussion.
That methodology matters because it changes the comparison frame. The usual market question is whether an agent can browse, code, use MCP, or connect to business systems. The Index adds a second question: what public evidence comes with those capabilities? This reads less like a product review and more like the first draft of an agent procurement questionnaire.
The numbers show a disclosure gap
The official key findings show both sides of the market. On the deployment side, agents are moving quickly. Twenty-four of the 30 agents launched or received major agentic updates in 2024 or 2025, and the site notes that Google Scholar results mentioning "AI agent" or "agentic AI" had already passed the prior full-year total.
On the disclosure side, the public record is thin. The Index found no public information for 227 of 1,350 fields. The gaps concentrate in ecosystem interaction and safety, which are precisely the areas that matter when an agent moves beyond a chat box and starts touching websites, APIs, files, workflow tools, or enterprise records.
The sharpest number is 4 of 13. The Index says that among 13 agents with frontier-level autonomy, only four publicly disclose agentic safety evaluations. The site's further details identify those as ChatGPT Agent, OpenAI Codex, Claude Code, and Gemini 2.5 Computer Use. In other words, public evaluations of full agentic setups are still concentrated among a small set of large lab products.
The phrase "agentic safety evaluation" matters. Model safety evaluation is now familiar: harmful output, cyber capability, biosecurity risk, persuasion, autonomy, hallucination, and other model-level tests. But an agent is not a model alone. It is a model plus prompts, planner, tool router, browser, memory, file access, connectors, policy layer, approval state, and deployment environment. A model evaluation does not automatically prove that the whole agent harness is safe.
Autonomy rises differently by product type
The Index's autonomy taxonomy is also practical. Chat agents mostly sit around L1 to L3. A user gives turn-by-turn instructions, and the system replies or performs bounded tool calls. Some products with a chat surface, such as Claude Code or Codex, can run longer and more complex tasks, but the user often remains inside the conversational loop.
Browser agents are different. The Index places them around L4 to L5, with limited human intervention during execution. They can navigate web pages, fill forms, click buttons, and change state in external systems. A failure is no longer just a bad answer. It can become a bad web action. That brings questions about origin isolation, user-agent identity, robots.txt, anti-bot protections, payment confirmation, credential handling, and consent.
Enterprise agents follow a third pattern. At design time they can look like L1 or L2 systems: an administrator describes a workflow, attaches tools, and defines data access. After deployment, the same system can operate at L3 to L5 when triggered by business events. A ticket appears, the agent classifies it, queries customer records, reads policy documents, advances a workflow, and asks for approval only at specific points.
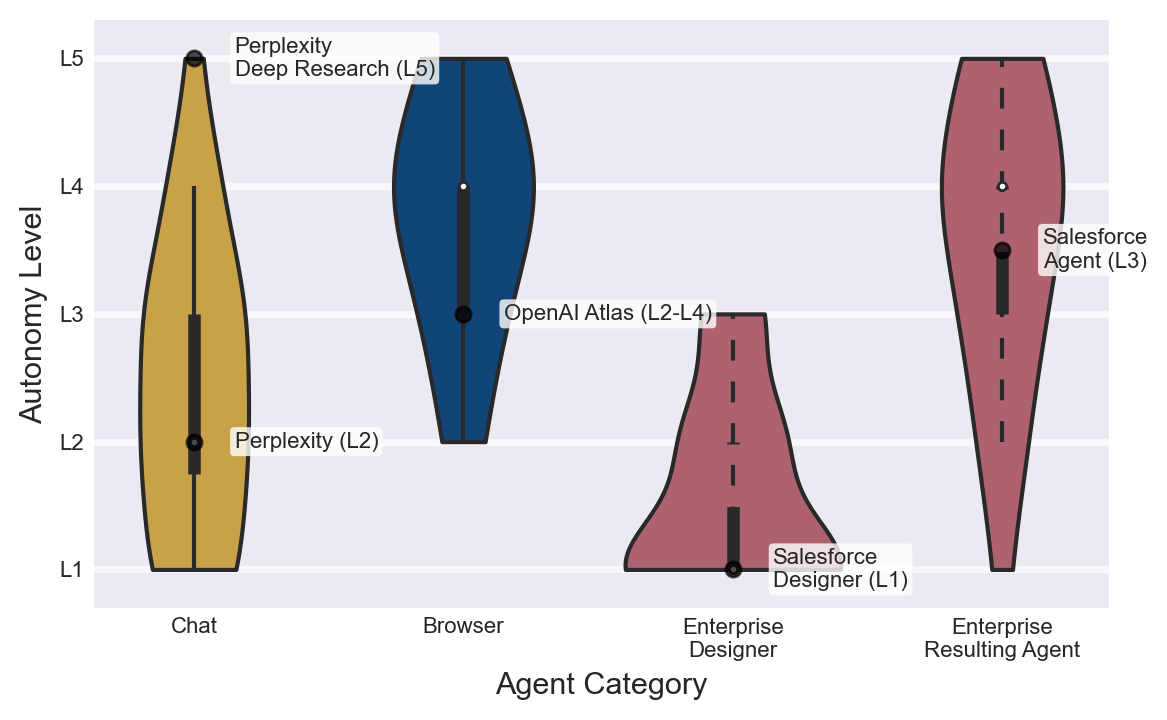
This distinction matters for builders. The same label, "AI agent," hides different safety requirements. A chat agent may need clear context display and tool confirmation. A browser agent may need origin isolation, request signing, web-conduct policy, and credential scoping. An enterprise agent may need RBAC, audit logs, approval state machines, rollback paths, and data retention policies.
Agent safety should therefore not be a single checkbox. The failure modes change with product category and autonomy level. The Index is useful because it puts those differences into one comparable map.
Web conduct is still unsettled
One of the Index's sharper observations concerns web conduct. The official site says there is no established standard for how agents should behave on the web. It also notes that some browser agents are designed to bypass anti-bot protection and mimic human browsing.
This resembles the crawler debate, but it is more difficult. Traditional crawlers are usually visible through robots.txt behavior, user-agent strings, rate limits, and known IP ranges. Browser agents can operate inside a user's real browsing context. From a website operator's perspective, it can be hard to tell whether an action came from a human, an agent following a human instruction, or automation at scale.
Vendors often say the agent is acting on behalf of the user. That argument is not empty. If a user can visit a site, read information, and fill a form, delegating that work to an agent can improve accessibility and productivity. But the site operator still needs a way to distinguish personal delegation from bulk automation, policy evasion, or unauthorized state changes.
The Index further details say only ChatGPT Agent uses cryptographic request signing. That should not be read as the only acceptable design. It does point toward a broader requirement: agents that act on the web need a technical way to prove who they represent and under what authority they are acting. A plain user-agent string is not enough.
MCP makes control more important
The Index says 20 of the 30 agents support MCP. Among enterprise agents, the number is 12 of 13. That is a signal that the agent ecosystem is quickly converging around tool-calling standards. It also expands the control problem.
MCP opens data and action surfaces to agents. GitHub, Slack, Notion, databases, browsers, payment systems, and internal APIs can become part of the agent's toolset. That is a better direction than brittle scraping or informal UI automation. Explicit tool interfaces are easier to document, permission, and audit.
The problem is that every added tool changes the evaluation boundary. The same base model can be low-risk in one harness and high-risk in another. Risk depends on which MCP servers are attached, which credentials they hold, which approval policy governs each call, and whether the deployment logs enough context to reconstruct decisions later. A coding agent that can only edit files in a sandbox is different from an enterprise agent that can view customer data, update CRM records, create cloud resources, or initiate payment workflows.
That is why "the model provider performed a safety evaluation" is not enough. Teams need to know what tools the deployed agent can use, what permissions each tool receives, when human approval is required, which calls are logged, and whether state changes can be rolled back. The multi-layered ecosystem is the safety problem.
Responsibility is split across layers
The Index observes that most agents rely on GPT, Claude, or Gemini families, while only a smaller set of frontier labs and Chinese developers use their own models. At the same time, 23 of 30 products are fully closed source at the product level. Many deployed agents therefore combine a closed model, a closed agent scaffold, external tools, and enterprise data.
When an incident happens in that stack, attribution is hard. The model may have made a bad judgment. The planner may have decomposed the task poorly. The tool schema may have been ambiguous. An MCP server may have exposed dangerous permissions. The deploying organization may have configured approval policy too loosely. Logs may be too sparse to reconstruct the path.
One contribution of the Index is that it turns that blurry responsibility problem into concrete fields. Component accessibility, model specification, observation space, action space, memory architecture, user approval requirements, execution monitoring, emergency stop, web conduct, sandboxing, internal safety evaluations, third-party testing, and vulnerability disclosure all sound less like marketing copy and more like security review questions.
A developer platform team can convert those fields directly into a procurement checklist. "Do you have SOC 2?" is no longer enough. The better questions are whether the vendor has agent-level internal safety evaluations, whether the full agentic setup was tested, whether customers can retain and export tool-call logs, whether agent identity is separated from human identity, and what emergency stop actually rolls back during execution.
Missing disclosure is not proof of missing controls
There is an important caution. Lack of public information does not mean a company has no safety controls. Enterprise platforms may put important details behind customer contracts, security portals, private audits, or compliance documentation. Lower public disclosure by some companies or regions may reflect disclosure norms rather than the absence of internal controls.
The Index itself is careful about this. It is based on public information, demos, documentation, papers, governance documents, and developer correspondence. It did not run its own experimental tests of the products. Companies had four weeks to request annotation changes, but the further details say the response rate was 23 percent, and only four of 30 companies provided substantive comments by publication.
So the right reading is not "these products are unsafe." The better reading is "this is a map of safety information that outsiders can verify." The large number of blank spaces is itself the news. Enterprise buyers, policymakers, developers, and security teams should turn those blank spaces into direct vendor questions.
The questions developers should ask now
AI agent adoption still often begins with model performance. Which model scores better on SWE-bench? Which browser agent completes more tasks? Which coding tool is faster? Those questions are useful, but they are no longer sufficient once agents enter production systems.
First, teams need to ask about identity and permissions. Does the agent borrow a human account, or does it have a separate machine identity? Can permissions be scoped by tool and session? Can a sensitive action require a different approval path than a read-only lookup?
Second, teams need logs and reproducibility. A serious incident review needs to know what observations the agent saw, which tool calls it made, which approvals it passed, and what state changed. "The AI did it" is not an operational answer.
Third, evaluation scope has to be precise. Base model evaluation and agentic system evaluation are different. Teams should ask what failure modes were tested with browser control, file access, code execution, internal APIs, payment flows, CRM access, or long-term memory attached.
Fourth, browser conduct needs explicit policy. If an agent explores the public web, teams need rules for identification, rate limits, robots.txt, anti-bot protections, user consent, payment confirmation, and sensitive form input.
Fifth, human-in-the-loop needs to become a state machine, not a slogan. Who approves what, when does approval expire, what happens on timeout, how are approver changes logged, and what can be reversed after an external system has already changed?
Procurement may become the next agent battleground
The AI Agent Index is not as flashy as a new model release. It may matter longer for developers and platform teams. Model rankings change every few weeks. Procurement requirements, audit schemas, approval policies, web-conduct norms, and third-party evaluation expectations become organizational infrastructure.
The market direction is clear. Coding agents are moving into pull requests and CI. Enterprise agents are moving into CRM, ERP, and ticket systems. Browser agents are acting directly on web surfaces. That does not mean every deployment is ready. It means the question shifts from whether agents will be used to what evidence and authority they should require.
The 25 of 30 number is best read as a warning. It does not prove the agents are unsafe. It shows that public evidence is not keeping pace with autonomy. That gap matters because a chatbot's wrong answer can often be corrected after the fact, while an agent's wrong action can change system state.
The next phase of agent competition may be decided less by demo videos and more by documentation. It will matter which vendors can explain permissions, audits, evaluations, web behavior, incident response, and responsibility boundaries. Developers and enterprise buyers should adjust their questions accordingly. Asking what an agent can do is no longer enough. The operational question is what accountability structure surrounds that ability.