GLM-5.1이 SWE-Bench Pro 1위를 찍은 날, Meta는 오픈소스를 버렸다
중국 Z.ai가 744B MoE 모델 GLM-5.1을 MIT 라이선스로 공개하며 SWE-Bench Pro에서 Claude Opus 4.6과 GPT-5.4를 제치고 1위를 차지했습니다. 같은 주에 Meta가 클로즈드로 전환한 것과 극명한 대비를 이룹니다.
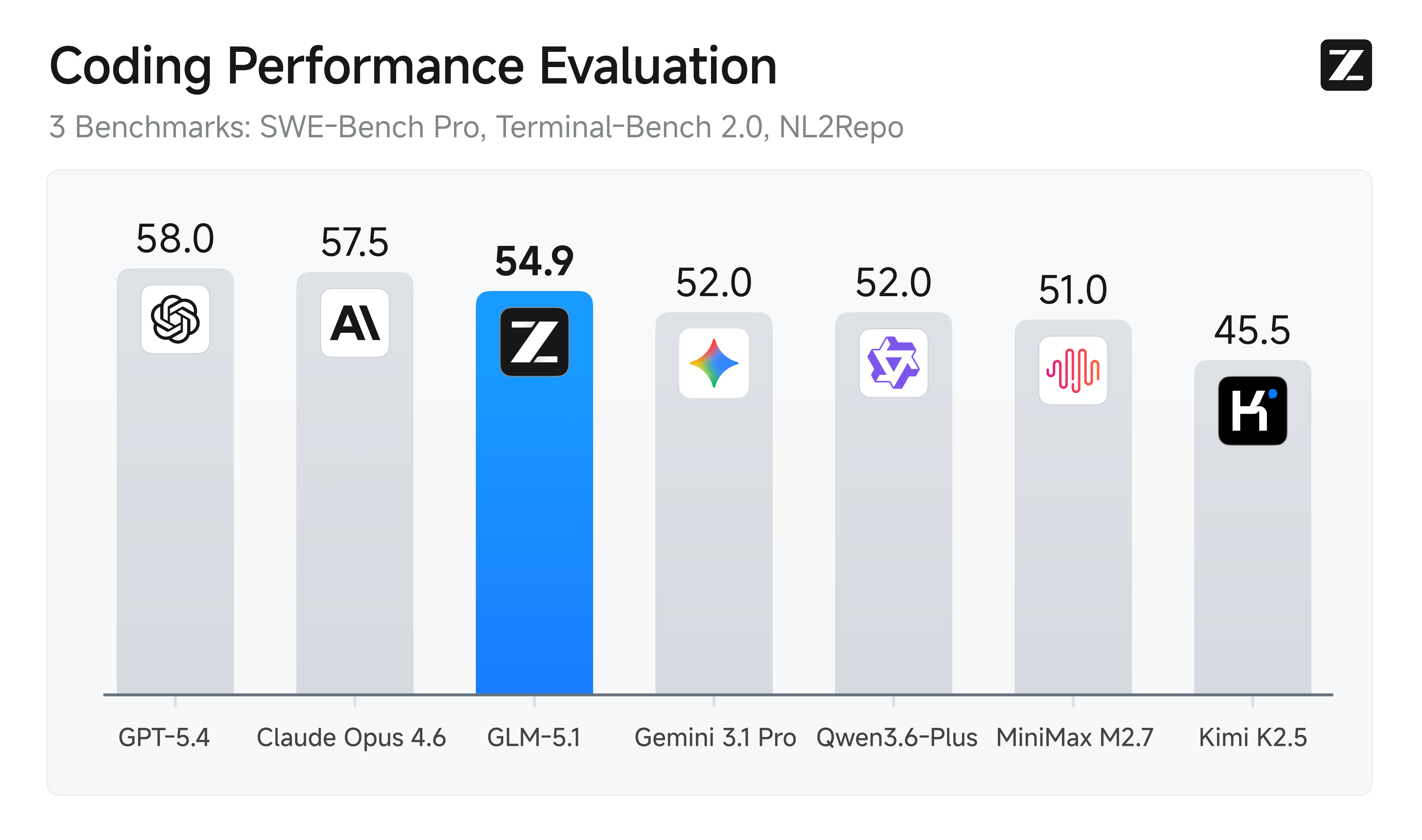
4월 7일, 오픈소스 모델 하나가 코딩 벤치마크의 정상에 올랐습니다. 중국 AI 기업 Z.ai(구 Zhipu AI)가 공개한 GLM-5.1이 SWE-Bench Pro에서 58.4점을 기록하며, Claude Opus 4.6(57.3)과 GPT-5.4(57.7)를 모두 제치고 글로벌 1위를 달성한 것입니다. 오픈소스 모델이 모든 클로즈드 모델을 실무 코딩 벤치마크에서 추월한 것은 이번이 처음입니다.
더 주목할 만한 것은 타이밍입니다. 바로 다음 날인 4월 8일, Meta는 수년간 유지해온 오픈소스 전략을 뒤집고 Muse Spark을 클로즈드 모델로 출시했습니다. 같은 주에 벌어진 정반대 행보. AI 업계의 오픈소스 논쟁이 새로운 국면에 진입했습니다.
Z.ai는 어떤 회사인가
GLM-5.1의 의미를 이해하려면 먼저 Z.ai의 궤적을 살펴볼 필요가 있습니다. 이 회사는 2019년 칭화대학교 Knowledge Engineering Group(KEG) 연구실에서 스핀오프되었습니다. 설립자인 Tang Jie와 Li Juanzi 교수가 이끌었고, 이후 Alibaba, Tencent, Ant Group, Xiaomi 등 중국 빅테크 기업과 사우디아라비아 Aramco 산하 Prosperity7 Ventures 등으로부터 12라운드에 걸쳐 총 14억 달러 이상을 조달했습니다.
2026년 1월에는 중국 주요 LLM 기업 최초로 홍콩증권거래소(HKEX) IPO에 성공했습니다. 4월 현재 시가총액은 약 443억 달러. 학교 연구실에서 시작한 스타트업이 7년 만에 글로벌 AI 기업으로 올라선 셈입니다.
모델 계보도 주목할 만합니다. 2021년 GLM-10B으로 시작해, 2022년 GPT-3급 성능의 GLM-130B, 2023년 중국 내 소형 모델 대중화를 이끈 ChatGLM-6B, 2024년 GPT-4 Turbo급 GLM-4 All Tools를 거쳐 꾸준히 스케일업해왔습니다. GLM-5.1은 이 궤적의 최신 정점입니다.
오픈소스 코딩 모델 경쟁의 흐름
GLM-5.1이 등장한 맥락을 이해하려면 오픈소스 AI 코딩 모델 경쟁의 큰 그림을 봐야 합니다. 지난 1년간 이 분야에서는 뚜렷한 패턴이 형성되었습니다. 중국 기업들이 오픈소스를 주도하고, 미국 기업들이 클로즈드를 고수하는 구도입니다.
DeepSeek, Qwen, Kimi 등 중국 모델이 오픈소스 분야를 잇달아 석권하는 가운데, VentureBeat는 이를 두고 "오픈소스 모델은 중국 모델이 지배하는 전장"이라고 평가했습니다. 반면 OpenAI, Anthropic, Google은 자사 모델을 독점적으로 운영하며 API를 통한 접근만 허용하고 있습니다.
이 구도에서 특히 주목할 점은 미국의 수출 통제가 역설적 효과를 낳고 있다는 것입니다. Z.ai는 2025년 1월부터 미국 Entity List에 등재되어 Nvidia 데이터센터 GPU에 합법적으로 접근할 수 없습니다. GLM-5.1은 Huawei Ascend 910B 약 10만 장과 MindSpore 프레임워크만으로 학습되었습니다. Nvidia 칩 없이 프론티어 모델을 만들어 낸 것입니다. 봉쇄가 오히려 자체 역량 구축의 촉매가 된 또 하나의 사례입니다.
744B MoE 아키텍처, 무엇이 다른가
GLM-5.1의 기술적 세부사항을 들여다보겠습니다. 총 파라미터는 744B(일부 출처 754B)이며, Mixture-of-Experts(MoE) 아키텍처를 사용합니다. 256개 전문가 서브네트워크 중 토큰당 8개만 선택하여 활성 파라미터는 약 40B 수준입니다. 이 설계 덕분에 거대한 모델 규모에도 추론 비용을 합리적으로 유지할 수 있습니다.
| 벤치마크 | GLM-5.1 | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
| SWE-Bench Pro | 58.4 🥇 | 57.3 | 57.7 |
| SWE-Bench Verified | 77.8 | 80.8 🥇 | 79.2 |
| Terminal-Bench 2.0 | 63.5 | 69.4 | 75.1 🥇 |
| GPQA-Diamond | 86.2 | 91.3 🥇 | 89.7 |
| CyberGym | 68.7 🥇 | 66.6 | 65.1 |
| MCP-Atlas | 71.8 🥇 | 68.2 | 67.9 |
컨텍스트 윈도우는 200K 토큰, 최대 출력 토큰은 128K에 달합니다. 여기에 두 가지 핵심 기술이 적용되었습니다. DeepSeek Sparse Attention(DSA)은 배포 비용을 절감하면서 긴 컨텍스트를 유지하고, Multi-head Latent Attention(MLA)은 표준 Multi-head Attention 대비 메모리 오버헤드를 33% 줄입니다.
프리트레이닝에는 28.5조 토큰이 사용되었습니다. 이전 버전 GLM-4.5의 23조 토큰에서 상당히 증가한 규모입니다. 하지만 GLM-5.1의 진정한 차별점은 프리트레이닝이 아니라 포스트트레이닝에 있습니다.
"slime" 비동기 RL, 포스트트레이닝의 혁신
GLM-5.1은 GLM-5와 동일한 프리트레이닝 기반 위에, 에이전트 코딩과 장기 자율 실행에 특화된 포스트트레이닝을 추가한 버전입니다. 핵심은 "slime"이라 불리는 비동기 강화학습(RL) 인프라입니다. 이 시스템은 학습 처리량과 효율성을 대폭 개선하여, 더 세밀한 포스트트레이닝 반복을 가능하게 합니다.
Hacker News의 한 댓글이 이 점을 정확히 짚었습니다.
"프론티어와 비프론티어의 실제 격차는 프리트레이닝 컴퓨트가 아니라 RL 인프라에 있다." — @jfaganel99
이 관점에서 보면, GLM-5.1의 SWE-Bench Pro 1위는 단순히 모델을 크게 만든 결과가 아닙니다. 포스트트레이닝 단계에서 에이전트 행동 패턴을 얼마나 정교하게 학습시켰느냐의 승리입니다.
SWE-Bench Pro 1위, 하지만 종합은 다른 이야기
벤치마크 결과를 자세히 살펴보면, GLM-5.1의 강점과 한계가 동시에 드러납니다. SWE-Bench Pro에서 58.4점으로 1위를 차지한 것은 분명히 인상적입니다. 하지만 SWE-Bench Verified에서는 77.8점으로 Claude Opus 4.6(80.8)에 뒤처지고, Terminal-Bench 2.0에서는 GPT-5.4(75.1)가 크게 앞섭니다. 순수 추론 벤치마크인 GPQA-Diamond에서도 86.2점으로 Claude Opus 4.6(91.3)에 5점 이상 차이가 납니다.
반면 GLM-5.1이 압도적인 영역이 있습니다. 사이버보안 벤치마크 CyberGym에서 68.7점(Claude 66.6), 에이전트 도구 사용 벤치마크 MCP-Atlas에서 71.8점으로 최고점을 기록했습니다.
패턴이 보이시나요? GLM-5.1은 에이전트적 실행(장시간 자율 코딩, 도구 사용, 보안 태스크)에서 강하고, 순수 추론과 일반 코딩 종합에서는 클로즈드 모델에 뒤처집니다. "특정 벤치마크 1위"와 "종합 최강"은 다른 이야기입니다. SWE-Bench Pro 1위는 상징적으로 의미 있지만, 오픈소스가 클로즈드를 완전히 추월했다고 말하기에는 이릅니다.
8시간 자율 코딩, 에이전트의 새로운 기준
GLM-5.1에서 가장 주목할 만한 기능은 최대 8시간 동안 인간 개입 없이 자율적으로 코딩 작업을 수행하는 능력입니다. plan → execute → test → fix → optimize 루프를 수백 라운드에 걸쳐 반복하며, 수천 번의 도구 호출을 안정적으로 처리합니다.
처음부터 완전 구축
178라운드 자율 반복
2.6× → 35.7× 자율 개선
Z.ai가 공개한 데모 사례들은 이 능력의 범위를 보여줍니다.
Linux 데스크톱 환경 구축: 8시간 동안 655회 반복하여 완전한 Linux 스타일 데스크톱 환경을 처음부터 구축했습니다. 단순한 코드 생성이 아니라, 설계-구현-테스트-수정의 전체 사이클을 자율적으로 수행한 것입니다.
벡터 데이터베이스 최적화: 178라운드의 자율 반복을 통해 쿼리 처리량을 초기 대비 6.9배로 향상시켰습니다. 최적화의 방향을 스스로 판단하고, 반복적으로 개선한 결과입니다.
CUDA 커널 최적화: 지속적 튜닝을 통해 속도 향상을 2.6배에서 35.7배로 끌어올렸습니다. 13배 이상의 추가 개선을 자율적으로 달성한 셈입니다.
200K 토큰의 컨텍스트 윈도우와 128K 토큰의 출력 한도가 이런 장시간 작업을 가능하게 합니다. 기존 코딩 에이전트들이 한 번의 요청에 응답하는 방식이었다면, GLM-5.1은 "8시간 근무"를 소화하는 에이전트라는 새로운 패러다임을 제시합니다. VentureBeat는 이를 두고 "AI가 8시간 근무제에 합류했다"고 표현했습니다.
MIT 라이선스, 완전한 자유
기술 못지않게 중요한 것이 라이선스 전략입니다. GLM-5.1은 MIT 라이선스로 공개되었습니다. 가장 허용적인 오픈소스 라이선스 중 하나로, 다운로드, 검사, 수정, 파인튜닝, 상업적 사용 모두 제한이 없습니다.
이것은 Meta의 Llama 시리즈가 사용하는 커스텀 라이선스(사용자 수 제한, 일부 상업적 제약)나 Google Gemma의 사용 제한 조건과 확연히 다릅니다. 기업이 자체 시스템에서 규제 준수, IP 보호, 플랫폼 통제를 유지하면서 모델을 자유롭게 운영할 수 있다는 뜻입니다.
Meta의 클로즈드 전환과 극명한 대비
같은 주에 벌어진 Meta의 행보가 이 결정의 의미를 더욱 부각시킵니다. 4월 8일, Meta는 새로운 모델 Muse Spark을 클로즈드 모델로 출시했습니다. Llama 시리즈로 수년간 오픈소스 AI의 대표 주자였던 Meta가, 전략을 정반대로 전환한 것입니다.
| 항목 | Z.ai GLM-5.1 | Meta Muse Spark |
|---|---|---|
| 출시일 | 2026년 4월 7일 | 2026년 4월 8일 |
| 라이선스 | MIT (완전 개방) | 클로즈드 |
| 전략 방향 | 오픈소스 확대 | 오픈소스 → 클로즈드 전환 |
| 수익화 모델 | 오픈소스 생태계 + 프리미엄 API | 독점 서비스·API |
| 로컬 배포 | 가능 (llama.cpp, GGUF) | 불가 |
| 핵심 베팅 | 개발자 생태계 선점 | 독점적 경쟁 우위 |
두 회사의 전략을 나란히 놓으면 AI 업계의 분기점이 보입니다. Z.ai는 오픈소스를 확대하여 개발자 생태계를 구축하려 하고, Meta는 독점적 경쟁 우위 확보로 선회했습니다. "오픈소스가 미래"라는 명제에 대해 같은 주에 정반대의 베팅이 이루어진 셈입니다.
다만 Z.ai의 전략도 순수한 개방만은 아닙니다. GLM-5 Turbo는 독점 비공개로 유지하고 있으며, GLM-5.1 출시와 함께 API 가격을 8-17% 인상했습니다. "오픈소스로 생태계를 키우고, 프리미엄 제품으로 수익화"하는 이중 전략입니다. 순수한 이타주의가 아니라 계산된 비즈니스 전략이라는 점에서, 오히려 지속가능한 모델일 수 있습니다.
개발자에게 어떤 의미인가
GLM-5.1이 실제로 개발자 워크플로우에 미치는 영향을 살펴보겠습니다.
API 접근: 프론티어 성능, 1/10 가격
가장 직접적인 영향은 비용입니다. Z.ai 공식 API 가격은 입력 $1.40, 출력 $4.40(백만 토큰당)입니다. OpenRouter를 통하면 입력 $0.95, 출력 $3.15까지 내려갑니다. Claude Opus 4.6의 API 가격($15/$75)과 비교하면 10분의 1 이하입니다.
SWE-Bench Pro 1위 모델을 이 가격에 사용할 수 있다면, 코딩 에이전트의 비용 구조가 근본적으로 달라집니다. Claude Code, Cursor, Cline, Kilo Code 등 주요 AI 코딩 도구들이 이미 GLM-5.1 API와 호환됩니다.
로컬 배포: 가능하지만 도전적
MIT 라이선스 덕분에 로컬 배포도 가능합니다. llama.cpp 지원으로 양자화 실행이 가능하고, Unsloth에서 양자화 가이드를 제공합니다. 하지만 현실적인 한계가 있습니다.
풀 정밀도(FP16)로는 약 1.5TB 디스크 용량에 다수의 GPU가 필요합니다. 가장 공격적인 2-bit 양자화(IQ2_M)로도 약 236GB 디스크에 256GB 이상의 시스템 RAM이 필요합니다. 개인 개발자의 로컬 배포는 현실적으로 어렵고, 엔터프라이즈나 클라우드 환경이 주요 타겟입니다.
실무 시나리오
그렇다면 GLM-5.1을 실제로 어떻게 활용할 수 있을까요?
야간 배치 코딩 작업: 8시간 자율 에이전트를 활용해, 퇴근 후 레거시 코드 리팩토링이나 테스트 커버리지 확대 작업을 맡길 수 있습니다. 아침에 출근하면 PR이 올라와 있는 워크플로우입니다.
에어갭 환경의 코딩 에이전트: MIT 라이선스와 로컬 배포의 조합으로, 인터넷이 격리된 보안 환경에서도 프론티어급 코딩 모델을 사용할 수 있습니다. 금융, 국방, 의료 등 규제 산업에서 의미 있는 옵션입니다.
비용 효율적 CI/CD 통합: 풀리퀘스트마다 Claude나 GPT를 호출하는 것이 비용 부담이었다면, GLM-5.1 API로 전환하면 같은 파이프라인을 10분의 1 비용으로 운영할 수 있습니다.
커뮤니티는 어떻게 반응했나
Hacker News에서 GLM-5.1 스레드는 287포인트, 90댓글을 기록했고, 이전 GLM-5 스레드는 373포인트, 452댓글로 매우 활발한 토론이 이뤄졌습니다.
긍정적 반응의 핵심은 세 가지였습니다. 첫째, MIT 라이선스의 완전한 자유도. 둘째, Huawei 칩만으로 프론티어 모델 학습에 성공한 점에 대한 놀라움. 셋째, slime 비동기 RL 인프라에 대한 기술적 관심. 특히 로봇공학이나 전략 시뮬레이션 등 장기 자율 실행이 필요한 분야에서의 활용 가능성에 기대가 모였습니다.
회의적 반응도 적지 않았습니다. 한 사용자는 이렇게 지적했습니다.
"GLM-5 출시하면서 Pro 플랜에서 플래그십 모델 업데이트를 제거하고 가격까지 대폭 인상했다." — @usb_type_d
오픈소스라는 명분과 실제 접근성 사이의 괴리를 꼬집은 것입니다. 벤치마크의 실제 의미에 대한 회의론도 있었습니다. "더 표준화된 통제 테스트가 필요하다"는 의견과 함께, SWE-Bench Pro 1위이나 종합 코딩에서는 Claude가 앞선다는 점이 반복적으로 지적되었습니다.
r/LocalLLaMA 커뮤니티에서는 GGUF 양자화 버전 배포와 로컬 실행 가이드가 활발히 공유되고 있습니다. 하지만 744B 모델의 실질적 로컬 배포 가능성에 대해서는, 기대보다 현실적 한계를 인정하는 분위기가 우세합니다.
오픈소스 vs 클로즈드, 같은 주의 두 가지 미래
GLM-5.1과 Meta Muse Spark의 동시 등장은 AI 업계의 근본적 질문을 다시 수면 위로 끌어올립니다. 프론티어 AI 모델의 미래는 오픈소스인가, 클로즈드인가?
Z.ai의 베팅은 명확합니다. 프론티어급 모델을 MIT 라이선스로 공개하여 개발자 생태계를 확보하고, 프리미엄 서비스(GLM-5 Turbo, API)로 수익을 만듭니다. 중국 AI 기업들, DeepSeek, Qwen, Kimi가 모두 비슷한 전략을 취하고 있어, 이 접근법이 중국 AI 산업의 표준 전략으로 자리잡고 있습니다.
Meta의 전환은 반대 방향을 가리킵니다. 오픈소스의 가장 강력한 옹호자 중 하나였던 Meta가 Muse Spark에서 클로즈드를 선택했다는 것은, 오픈소스만으로는 충분한 경쟁 우위를 확보할 수 없다는 판단을 의미합니다.
두 전략 모두 합리적인 논리를 갖고 있습니다. 하지만 개발자 입장에서 중요한 것은 전략의 옳고 그름이 아니라 실질적 결과입니다. GLM-5.1의 존재로 인해, 오픈소스 진영에도 SWE-Bench Pro 1위 모델이 생겼습니다. 이것은 선택지가 늘어났다는 것이고, 선택지가 늘어나면 경쟁이 심화되고, 경쟁이 심화되면 결국 사용자에게 이득입니다.
AI 코딩 에이전트 시장은 이제 단순한 성능 경쟁을 넘어, 접근 방식의 경쟁으로 진화하고 있습니다. 클로즈드 모델의 안정적 성능과 통합 생태계, 오픈소스 모델의 자유도와 비용 효율. 어느 한쪽이 압도하기보다는, 두 접근법이 서로 다른 니즈를 충족하며 공존하는 방향으로 갈 가능성이 높습니다.
확실한 것은 하나입니다. Nvidia 칩 없이, MIT 라이선스로, 8시간 자율 코딩이 가능한 모델이 SWE-Bench Pro 정상에 올랐다는 사실은, 1년 전에는 상상하기 어려웠을 것입니다. AI 코딩의 판도는 빠르게 변하고 있고, 그 변화의 속도는 앞으로 더 빨라질 것입니다.