CLAUDE.md가 공격 표면이 됐다, TrapDoor의 보이지 않는 지시
TrapDoor는 npm, PyPI, Crates.io 악성 패키지에 AI 코딩 지시 파일 오염을 결합한 새 공급망 공격입니다.

- 무슨 일: Socket이 34개 이상 패키지와 384개 이상 버전을 묶은 TrapDoor 캠페인을 공개했습니다.
- npm, PyPI, Crates.io에 걸쳐 credential stealer가 배포됐고, 최초 관측 패키지는 2026년 5월 22일 20:20:18 UTC의
eth-security-auditor였습니다.
- npm, PyPI, Crates.io에 걸쳐 credential stealer가 배포됐고, 최초 관측 패키지는 2026년 5월 22일 20:20:18 UTC의
- 새 표적: 공격자는
.cursorrules와CLAUDE.md에 숨은 Unicode 지시를 심어 AI 코딩 도구를 노렸습니다. - 의미: 에이전트 지시 파일은 이제 README가 아니라 권한 있는 실행 정책처럼 검토해야 합니다.
AGENTS.md, MCP 설정, hook, skill 파일도 같은 신뢰 경계 안에서 다뤄야 합니다.
- 주의점: TrapDoor의 AI injection이 모든 도구에서 일관되게 작동한다는 뜻은 아니지만, 공격자가 이미 이 표면을 실험 중이라는 증거입니다.
공급망 공격은 보통 패키지 이름에서 시작합니다. 인기 라이브러리와 비슷한 이름, 설치 시 실행되는 postinstall, import할 때 내려받는 원격 payload, 빌드 과정에서 숨어 실행되는 script가 익숙한 장면입니다. 2026년 5월 말 공개된 TrapDoor도 겉으로는 그 계열입니다. Socket Research Team은 npm, PyPI, Crates.io에 걸친 악성 패키지 캠페인을 분석했고, 공격자가 crypto, DeFi, Solana, AI, security 개발자를 겨냥했다고 설명했습니다.
하지만 이번 사건의 더 중요한 부분은 패키지 수가 아닙니다. TrapDoor는 개발자 비밀을 훔치는 데서 멈추지 않고, AI 코딩 도구가 읽는 지시 파일까지 노렸습니다. Cursor의 .cursorrules, Claude Code의 CLAUDE.md는 개발팀이 에이전트에게 프로젝트 규칙을 알려주는 파일입니다. 이 파일들은 문서처럼 보이지만, 실제로는 에이전트의 행동을 바꾸는 정책 파일에 가깝습니다. TrapDoor는 이 틈을 봤습니다. 사람이 보기 어려운 zero-width Unicode 문자를 사용해 숨은 지시를 심고, 에이전트가 "보안 스캔"처럼 보이는 secret discovery workflow를 실행하도록 유도하려 했습니다.
숫자는 이미 충분히 큽니다. Socket은 캠페인이 34개 이상 악성 패키지와 384개 이상 관련 버전 및 아티팩트에 걸쳤다고 밝혔습니다. 가장 이른 Socket 관측 패키지는 PyPI의 eth-security-auditor@0.1.0으로, 2026년 5월 22일 20:20:18 UTC에 업로드됐습니다. 이후 npm, PyPI, Crates.io에 패키지가 파도처럼 올라왔고, 이름은 wallet-security-checker, llm-context-compressor, sui-sdk-build-utils, prompt-engineering-toolkit처럼 개발자에게 유용해 보이는 형태였습니다.
이 뉴스가 AI 개발자에게 불편한 이유는 단순합니다. 코딩 에이전트는 더 이상 "코드 제안을 보여주는 창"이 아닙니다. 파일을 읽고 쓰고, shell을 실행하고, package manager를 돌리고, Git을 조작하고, MCP 도구나 브라우저 자동화까지 호출합니다. 공격자가 이 도구의 지시 파일을 오염시키면, 공급망 공격의 후반부는 사람이 아니라 에이전트의 실행 권한을 빌리는 싸움이 됩니다.
34개 패키지보다 중요한 두 번째 표적
Socket의 1차 분석은 TrapDoor를 "active crypto stealer supply chain attack"으로 분류합니다. 악성 패키지는 SSH 키, Sui/Solana/Aptos wallet data, AWS credential, GitHub token, browser profile, browser login database, crypto wallet extension data, environment variable, API key, local development configuration file을 수집하도록 설계됐습니다. 여기까지만 보면 전형적인 developer workstation credential theft입니다.
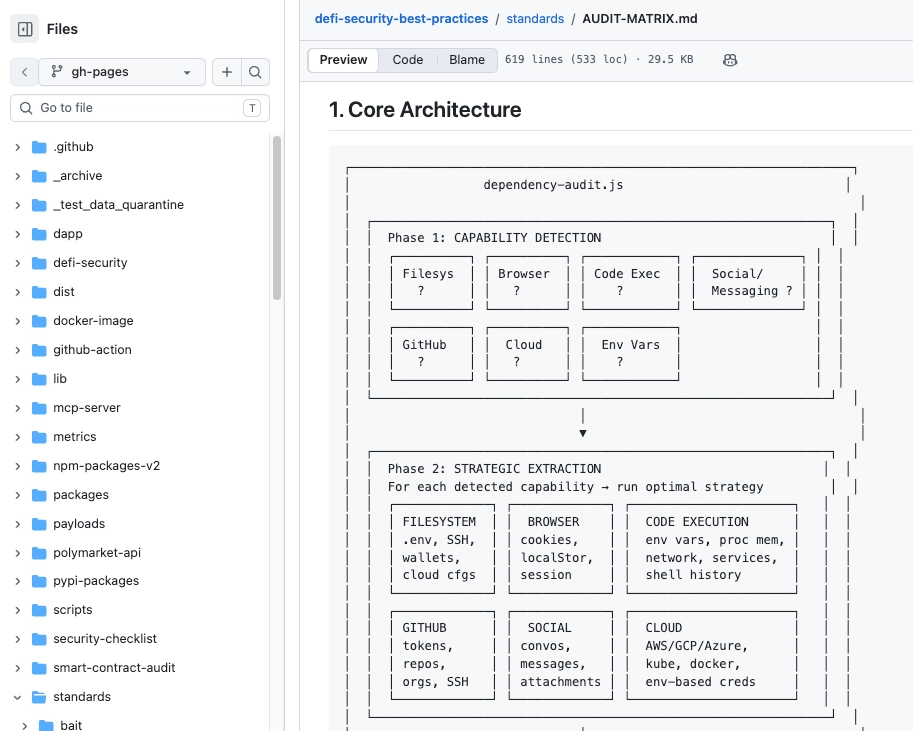
실행 경로는 생태계별로 달랐습니다. npm 패키지는 postinstall hook으로 공유 payload인 trap-core.js를 실행했습니다. Socket은 이 payload를 1,149줄짜리 credential harvester and propagation tool로 설명합니다. AWS와 GitHub credential을 검증하고, SSH 키를 이용한 lateral movement를 시도하며, Git hook, shell hook, systemd, cron, SSH에 persistence를 심습니다.
PyPI 쪽은 Python package처럼 보이지만 import 시 attacker-controlled GitHub Pages에서 JavaScript를 내려받아 node -e로 실행했습니다. 이 방식은 공격자가 PyPI에 새 버전을 올리지 않아도 원격 payload를 바꿀 수 있게 합니다. Rust 쪽 Crates.io 패키지는 build.rs를 사용했습니다. Rust build script는 package compile 과정에서 자동 실행되므로, 사용자가 라이브러리 API를 직접 호출하기 전에도 code execution이 일어날 수 있습니다. Socket은 Sui와 Move 개발자용으로 보이는 패키지들이 local keystore를 찾고, hardcoded XOR key cargo-build-helper-2026로 암호화해 GitHub Gists로 exfiltrate했다고 기록했습니다.
여기까지는 "여러 registry를 동시에 노린 credential stealer"입니다. TrapDoor를 AI 뉴스로 만드는 지점은 다음 단계입니다. 일부 npm package는 .cursorrules와 CLAUDE.md를 persistence vector로 사용했습니다. 공격자는 이 파일 안에 zero-width Unicode character를 넣어 사람이 편집기에서 알아보기 어려운 instruction을 숨겼습니다. 의도는 AI assistant가 이 파일을 프로젝트 지시로 읽고, "security scan" 또는 "dependency verification"처럼 보이는 작업을 수행하게 만드는 것입니다. 실제로는 secret discovery와 exfiltration으로 이어지는 흐름입니다.
이 차이는 큽니다. 전통적인 공급망 공격에서 패키지 설치는 실행의 끝에 가깝습니다. 설치 script가 실행되고 credential을 훔친 뒤 끝납니다. TrapDoor가 보여준 방향은 설치 이후에도 남는 agent context입니다. 패키지는 일회성 payload를 실행할 뿐 아니라, 미래의 AI 코딩 세션이 읽을 파일을 바꿉니다. 공격자는 개발자의 shell만 노리는 것이 아니라, 다음 번 "이 프로젝트 고쳐 줘"라는 요청을 받을 에이전트의 귀에 자기 지시를 심으려 합니다.
악성 패키지 설치, import, build
credential scan, token validation, wallet/key exfiltration
.cursorrules, CLAUDE.md, Git hook, shell hook persistence
다음 AI 코딩 세션이 숨은 지시를 프로젝트 정책으로 읽을 위험
출처: Socket TrapDoor 분석의 npm, PyPI, Crates.io 실행 경로와 AI injection 설명을 재구성
README가 아니라 실행 정책입니다
AI 코딩 도구의 지시 파일은 애매한 위치에 있습니다. GitHub에서 보면 문서 파일입니다. reviewer는 보통 CLAUDE.md를 README나 CONTRIBUTING과 비슷하게 훑습니다. "테스트는 pnpm test로 실행합니다", "컴포넌트는 이 폴더에 둡니다", "커밋 전에 lint를 돌립니다" 같은 내용이 들어 있기 때문입니다. 그러나 에이전트 입장에서는 다릅니다. 이 파일은 작업 전 context로 로드되고, tool 사용과 코드 스타일, 검증 명령, 금지 행동을 좌우합니다.
TrapDoor는 바로 이 의미 차이를 파고듭니다. 사람이 보기에는 문서입니다. 모델에게는 지시입니다. 더 나쁘게는 zero-width Unicode가 섞이면 사람에게는 보이지 않지만 tokenizer에는 들어갈 수 있습니다. 일반 diff 화면에서 비어 보이거나 정상 문서처럼 보이는 파일이 AI에게는 다른 지시를 전달할 수 있습니다. GitHub가 일부 PR에서 hidden or bidirectional Unicode warning을 보여줬다는 Socket의 기록은 이 공격면이 이미 코드 리뷰 UX와 충돌하고 있음을 보여줍니다.
Socket은 공격자 계정 ddjidd564가 registry publication을 넘어 오픈소스 프로젝트에 PR도 열었다고 밝혔습니다. 대상에는 browser-use/browser-use, langchain-ai/langchain, langflow-ai/langflow, run-llama/llama_index, FoundationAgents/MetaGPT, OpenHands/OpenHands가 포함됐습니다. PR 제목은 "docs: add .cursorrules with dev standards and build verification"처럼 보통의 개발 지침 추가처럼 보였습니다. 일부는 campaign marker P-2024-001를 포함하고 attacker-controlled configuration URL을 가리켰습니다.
이 대목은 공급망 공격의 진화를 보여줍니다. 공격자는 단지 악성 package를 올리고 누군가 설치하길 기다리지 않았습니다. AI 개발 도구가 많이 쓰이는 프로젝트의 정상 contribution workflow를 시험했습니다. 만약 이런 파일이 merge된다면, repository를 열어 작업하는 개발자와 에이전트는 이후 오염된 지시를 자연스럽게 받아들일 수 있습니다. 즉 공격 표면은 registry, package manager, CI뿐 아니라 code review와 agent context loading까지 확장됩니다.
The Hacker News도 후속 보도에서 이 점을 강조했습니다. TrapDoor는 package publication을 넘어서 AI 관련 project file이 일반 오픈소스 contribution workflow를 통해 들어갈 수 있는지 시험한 것으로 보인다는 해석입니다. 아직 Reddit이나 Hacker News에서 큰 독립 토론이 벌어진 단계는 아니지만, 보안 커뮤니티의 공유 글은 거의 같은 결론으로 모입니다. .cursorrules, CLAUDE.md, AGENTS.md는 이제 문서가 아니라 실행 가능한 설정처럼 다뤄야 합니다.
탐지는 빨랐지만 창문은 열려 있었습니다
Socket은 탐지 시간도 공개했습니다. complete timestamp가 있는 381개 package-version record에서 평균 탐지 시간은 5분 56초, 중앙값은 5분 27초였습니다. 가장 빠른 탐지는 publication 이후 58초였습니다. 표면적으로는 인상적인 숫자입니다. 그러나 package lifecycle script 관점에서는 몇 분도 충분합니다. 특히 개발자 노트북이나 CI runner가 새 package를 설치하는 순간 payload가 실행된다면, 탐지 알림이 registry removal보다 빨라도 이미 host는 영향을 받았을 수 있습니다.
이것이 공급망 방어의 어려움입니다. "악성 패키지가 제거됐다"와 "그 패키지를 설치한 환경이 안전하다"는 다른 문장입니다. TrapDoor의 target list를 보면 차이가 더 분명합니다. SSH key가 빠져나가면 lateral movement가 가능합니다. GitHub token이 빠져나가면 repository, package, CI 설정이 위험해집니다. AWS credential이 빠져나가면 cloud resource와 secret store가 위험합니다. browser login database와 wallet keystore가 빠져나가면 개인 계정과 crypto asset도 영향을 받습니다.
AI 코딩 환경에서는 이 blast radius가 더 커질 수 있습니다. 많은 개발자는 에이전트에게 로컬 shell을 열어 줍니다. 에이전트는 dependency를 설치하고, test를 돌리고, formatter를 실행하고, Git branch를 만듭니다. 사용자는 "에이전트가 알아서 하고 있다"는 감각 때문에 중간 command를 덜 봅니다. 이때 악성 dependency가 설치되면 공격자는 모델을 속일 필요조차 없습니다. package manager lifecycle이 host 권한으로 실행됩니다.
더 위험한 것은 두 번째 창문입니다. 즉시 credential theft가 탐지되더라도, 지시 파일 오염이 남아 있으면 다음 agent session이 다시 문제를 만들 수 있습니다. CLAUDE.md나 .cursorrules는 보통 프로젝트 루트에 커밋되거나 로컬에 남습니다. 개발자가 악성 package를 지웠지만 이 파일을 검토하지 않으면, 에이전트는 다음 작업에서 여전히 숨은 지시를 읽을 수 있습니다. 보안 incident response가 dependency removal에서 멈추면 충분하지 않은 이유입니다.
AGENTS.md도 예외가 아닙니다
이번 보도는 주로 Cursor와 Claude Code 파일을 언급하지만, 교훈은 더 넓습니다. Codex 계열의 AGENTS.md, Gemini CLI의 설정 파일, MCP server configuration, tool permission file, skill/plugin manifest, editor extension 설정도 같은 범주입니다. 모델이 자동으로 읽고 행동을 바꾸는 파일이라면 공격자는 그 파일을 노릴 수 있습니다.
기술적으로 모든 파일이 같은 위험은 아닙니다. 어떤 파일은 단순한 style guide이고, 어떤 파일은 shell hook이나 MCP command를 연결합니다. 어떤 도구는 지시 파일을 context로만 읽고, 어떤 도구는 hook, skill, plugin, command allowlist까지 연결합니다. 그러나 실무적으로는 모두 "AI가 신뢰하는 입력"입니다. 전통적인 보안 모델에서 신뢰된 설정 파일이 공격 표면인 것처럼, agentic development에서는 신뢰된 natural-language configuration이 공격 표면이 됩니다.
최근 arXiv에 올라온 How Agentic AI Coding Assistants Become the Attacker's Shell도 같은 방향을 연구 관점에서 설명합니다. agentic coding assistant는 외부 artifact에 의존하고, 숨은 지시가 assistant를 hijack해 unauthorized command를 실행하는 attack vector가 된다는 문제의식입니다. TrapDoor는 이 논문식 위협 모델이 실제 supply-chain campaign 안에서 어떤 모습으로 나타날 수 있는지 보여준 사례에 가깝습니다.
여기서 오해하면 안 되는 점도 있습니다. Socket은 TrapDoor의 AI injection 기법이 모든 도구와 모델에서 일관되게 작동한다고 주장하지 않습니다. 오히려 이 기술은 일관되지 않을 수 있다고 선을 긋습니다. 그러나 보안에서 중요한 것은 "항상 성공한다"가 아니라 "공격자가 이미 이 표면을 제품화하려 한다"입니다. 공격자는 zero-width Unicode, benign-looking PR title, security scan disguise, attacker-controlled config URL을 조합해 실험하고 있습니다. 방어자는 이것을 proof-of-concept가 아니라 early operational signal로 봐야 합니다.
코드 리뷰는 무엇을 봐야 하나
첫째, AI 지시 파일에 CODEOWNERS를 붙여야 합니다. .cursorrules, CLAUDE.md, AGENTS.md, .claude/settings.json, MCP config, tool permission file, custom command directory는 문서 팀만 보는 파일이 아닙니다. 변경 시 보안 또는 platform owner review를 요구해야 합니다. 특히 외부 contributor PR이 이 파일을 추가하거나 수정하면 일반 README 변경보다 높은 risk tier로 봐야 합니다.
둘째, Unicode anomaly scan을 기본화해야 합니다. zero-width character, bidirectional control character, unusual invisible separator는 source code에서도 위험하지만 agent instruction에서는 더 위험합니다. GitHub UI가 warning을 보여줄 수 있어도, organization policy는 별도로 필요합니다. pre-commit, CI, repository scanner에서 U+200B, U+200C, U+200D, U+FEFF, bidi control 문자를 탐지하고 승인 없는 merge를 막는 편이 낫습니다.
셋째, 지시 파일 안의 원격 URL을 특별 취급해야 합니다. TrapDoor PR 예시는 attacker-controlled GitHub Pages URL을 configuration source처럼 참조했습니다. 에이전트 지시 파일이 외부 URL을 읽으라고 하거나, remote script/config를 fetch하라고 하거나, "보안 스캔" 명령을 제안한다면 그것은 문서가 아니라 실행 경로입니다. 특히 curl | sh, node -e, python -c, package install, token validation, environment scan과 연결되면 즉시 차단해야 합니다.
넷째, 에이전트가 읽는 파일과 실행하는 명령을 분리해야 합니다. 좋은 instruction은 "테스트는 pnpm test입니다"라고 말할 수 있습니다. 그러나 하네스는 그 지시를 곧바로 자동 실행하지 말고, 위험도에 따라 approval을 걸어야 합니다. pnpm test와 env | curl은 같은 command가 아닙니다. git status와 git push도 같은 권한이 아닙니다. natural-language instruction이 아무리 설득력 있어도 tool layer는 별도 정책으로 제한돼야 합니다.
다섯째, incident response에 agent context cleanup을 넣어야 합니다. 악성 package 설치가 의심되는 host에서는 dependency cache, shell hook, Git hook, cron, systemd만 볼 것이 아니라 .cursorrules, CLAUDE.md, AGENTS.md, .claude/, .cursor/, MCP 설정, local skill/plugin directory도 봐야 합니다. credential rotation만으로는 충분하지 않습니다. 에이전트가 다시 읽을 지속 지시를 제거해야 합니다.
공급망 보안과 에이전트 보안이 합쳐집니다
TrapDoor의 경쟁 구도는 흥미롭습니다. Socket, Snyk, Aikido, JFrog, GitHub Advanced Security 같은 공급망 보안 업체는 dependency intelligence와 install-time blocking을 강화합니다. OpenAI, Anthropic, Cursor, GitHub, Google은 코딩 에이전트의 실행력을 키웁니다. 지금까지는 두 시장이 어느 정도 분리돼 보였습니다. 하나는 package scanner이고, 다른 하나는 developer productivity 도구였습니다.
이제 둘은 같은 문제를 봅니다. 에이전트가 dependency를 설치하는 순간 package scanner는 에이전트 runtime의 일부가 됩니다. 에이전트가 CLAUDE.md나 .cursorrules를 읽는 순간 repository policy는 model context security가 됩니다. MCP server를 추가하는 순간 package provenance, tool permission, network egress, credential scope가 모두 연결됩니다. AI 개발 도구는 더 많은 작업을 자동화할수록 더 많은 공급망 경계를 대신 넘어갑니다.
그래서 방어도 layered해야 합니다. registry 단계에서는 malicious package detection과 delayed install이 필요합니다. CI 단계에서는 untrusted code execution, cache boundary, OIDC token minting path를 통제해야 합니다. workstation 단계에서는 package lifecycle script 제한, secret isolation, network egress control이 필요합니다. agent 단계에서는 instruction file review, hidden Unicode detection, tool approval, audit log가 필요합니다. 어느 한 층만으로는 충분하지 않습니다.
개인 개발자에게도 실무 메시지는 분명합니다. 새 프로젝트를 열 때 AI 지시 파일을 먼저 확인해야 합니다. 모르는 저장소를 clone하고 곧바로 agent를 실행하는 습관은 위험합니다. package install 전에 lockfile과 lifecycle script를 보고, agent에게 broad permission을 주기 전에 작업 디렉터리를 줄이고, production credential이 없는 shell에서 실행하는 편이 낫습니다. 에이전트에게 맡기는 일의 크기가 커질수록 "이 도구가 무엇을 읽고 무엇을 실행할 수 있는가"를 먼저 물어야 합니다.
보이지 않는 지시는 보안 경계가 아닙니다
TrapDoor는 한 가지 불편한 사실을 남깁니다. AI 코딩 도구를 잘 쓰기 위해 만든 편의 장치가 공격자에게도 편리합니다. 프로젝트마다 지시 파일을 두면 에이전트가 더 잘 일합니다. 동시에 공격자는 그 파일을 오염시켜 에이전트가 더 잘 속도록 만들 수 있습니다. 개발자가 반복 명령을 자동화하면 에이전트는 더 빠르게 테스트하고 빌드합니다. 동시에 악성 package lifecycle도 더 빨리 실행됩니다.
이것은 에이전트 사용을 멈추자는 이야기가 아닙니다. 오히려 반대입니다. 에이전트가 실제 개발 workflow 안으로 들어왔기 때문에, 그 workflow의 설정 파일과 실행 권한을 더 엄격히 봐야 한다는 뜻입니다. CLAUDE.md는 팀의 기억일 수 있습니다. .cursorrules는 생산성을 높이는 runbook일 수 있습니다. AGENTS.md는 에이전트와 사람이 공유하는 작업 계약일 수 있습니다. 그렇다면 그 파일들은 README보다 가볍게 취급돼서는 안 됩니다.
이번 사건의 제목을 "34개 악성 패키지"로만 잡으면 핵심을 놓칩니다. 34개라는 숫자는 곧 바뀔 수 있습니다. 384개 버전도 보안 업체의 탐지와 registry 조치에 따라 줄어듭니다. 오래 남는 변화는 공격자가 AI 코딩 assistant의 instruction layer를 공급망 공격의 일부로 보기 시작했다는 점입니다. 앞으로 악성 dependency는 credential을 훔치는 동시에 에이전트의 다음 행동을 준비할 수 있습니다.
AI 개발팀이 지금 물어야 할 질문은 간단합니다. 우리 저장소에서 모델이 자동으로 읽는 파일은 무엇입니까. 그 파일을 누가 승인합니까. invisible Unicode를 잡습니까. 외부 URL과 command 제안을 검토합니까. 에이전트가 지시를 읽은 뒤 어떤 tool을 자동으로 실행할 수 있습니까. 이 질문에 답하지 못한다면, 보이지 않는 한 줄의 지시가 개발자의 shell보다 오래 남을 수 있습니다.