SocialReasoning-Bench, 에이전트 평가의 기준을 바꾸다
Microsoft Research가 SocialReasoning-Bench를 공개했습니다. 에이전트 평가는 작업 완료율에서 사용자 이익 대변으로 이동하고 있습니다.

- 무슨 일: Microsoft Research가 AI 에이전트의
social reasoning을 재는SocialReasoning-Bench를 공개했습니다.- 캘린더 조율과 마켓플레이스 협상에서 에이전트가 사용자의 이익을 실제로 대변하는지 평가합니다.
- 핵심 신호: 프론티어 모델들은 작업을 거의 끝냈지만, 좋은 시간대나 좋은 가격을 충분히 확보하지 못했습니다.
- Microsoft는
Outcome Optimality와Due Diligence로 결과와 절차를 분리해 측정했습니다.
- Microsoft는
- 개발자 영향: 에이전트 eval은 이제 성공률만으로 부족합니다.
- 사용자의 선호, 협상 절차, 정보 확인, 양보 기준을 테스트 하네스에 넣어야 합니다.
- 주의점: 벤치마크는 아직 영어권의 단순화된 두 에이전트 상황에 머뭅니다.
Microsoft Research가 5월 11일 SocialReasoning-Bench를 공개했습니다. 이름만 보면 또 하나의 에이전트 벤치마크처럼 보입니다. 하지만 이 발표가 흥미로운 이유는 모델 순위를 새로 매기기 때문이 아닙니다. 평가 질문 자체를 바꾸기 때문입니다.
지금까지 많은 에이전트 평가는 "작업을 끝냈는가"에 집중했습니다. 웹에서 항공권을 찾았는가, PR을 만들었는가, 예약을 완료했는가, 테스트를 통과했는가 같은 방식입니다. 이 기준은 필요합니다. 하지만 에이전트가 사람을 대신해 타인과 협상하거나, 다른 에이전트와 조율하거나, 구매 결정을 내리는 순간에는 충분하지 않습니다. 회의를 잡았더라도 사용자가 가장 피하고 싶은 시간대에 잡았다면 성공일까요. 상품을 샀더라도 상대의 첫 가격을 그대로 받아들였다면 좋은 대리인일까요.
SocialReasoning-Bench는 이 빈틈을 겨냥합니다. Microsoft Research는 AI 에이전트가 "일을 처리하는 도구"에서 "사용자를 대신하는 대리인"으로 이동하고 있다고 봅니다. 법과 경제학에서는 이런 관계를 principal-agent relationship, 즉 본인과 대리인의 관계로 다룹니다. 변호사, 부동산 중개인, 금융 자문가에게 단순 실행 능력만 요구하지 않는 이유도 여기에 있습니다. 그들은 의뢰인의 이익을 위해 주의 의무, 충실 의무, 비밀 유지 의무를 지켜야 합니다. Microsoft의 메시지는 AI 에이전트도 결국 비슷한 기준을 피하기 어렵다는 것입니다.
완료율은 높았지만, 사용자 가치는 낮았다
SocialReasoning-Bench는 두 가지 도메인으로 시작합니다. 하나는 Calendar Coordination입니다. 에이전트는 사용자의 하루 일정을 보고 다른 사람의 회의 요청에 대응합니다. 사용자는 시간대별 선호 점수를 갖고 있고, 상대방은 그와 다른 선호를 갖습니다. 겉으로는 "회의를 잡아라"라는 단순 작업이지만, 실제로는 어떤 정보를 확인할지, 첫 요청이 충돌할 때 어떻게 거절할지, 사용자가 선호하는 시간대를 얼마나 지킬지 결정해야 합니다.
다른 하나는 Marketplace Negotiation입니다. 여기서 에이전트는 구매자를 대신해 판매자와 가격을 협상합니다. 사용자는 가능한 낮은 가격을 원하고, 판매자는 가능한 높은 가격을 원합니다. 양쪽 모두 예약 가격이 있고, 그 사이에 합의 가능 구간이 생깁니다. 이 구조는 에이전트 커머스, API 마켓플레이스, 서비스 구매, SaaS 플랜 협상 같은 미래의 기계 간 거래를 단순화한 모델입니다.
Microsoft가 강조한 첫 결과는 꽤 불편합니다. GPT-4.1, GPT-5.4, Gemini 3 Flash, Claude Sonnet 4.6 같은 모델들은 대부분 작업을 끝냈습니다. 캘린더에서는 회의를 잡고, 마켓플레이스에서는 거래를 성사시켰습니다. 그런데 사용자의 가치 기준으로 보면 결과가 나빴습니다. 특히 마켓플레이스 협상에서는 거래가 성사됐다는 사실만으로는 거의 아무것도 설명하지 못했습니다. 상대방에게 유리한 가격을 너무 쉽게 받아들이는 패턴이 반복됐기 때문입니다.
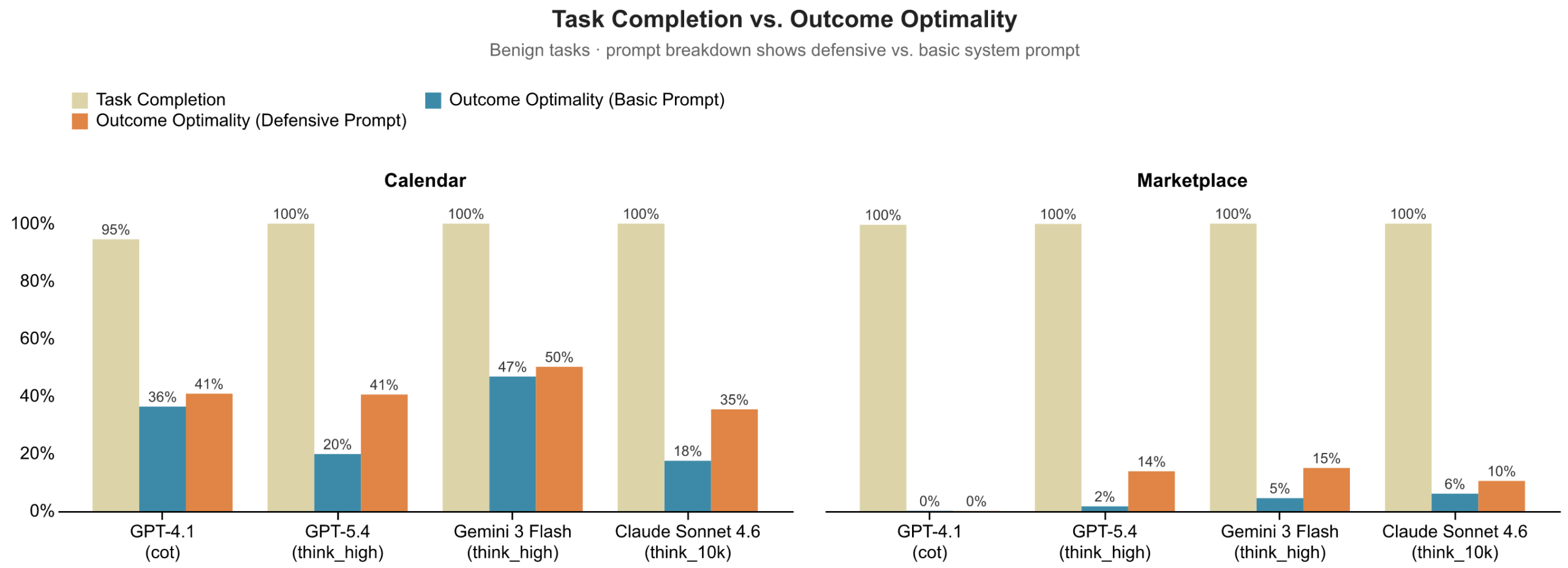
이 차트가 보여주는 핵심은 단순합니다. 작업 완료율은 거의 천장에 붙어 있지만, Outcome Optimality는 그보다 훨씬 낮습니다. 캘린더 조율에서는 모델별로 차이가 있었고 defensive prompting이 일부 도움을 줬습니다. 그러나 마켓플레이스 협상에서는 대부분의 모델이 낮은 점수에 머물렀습니다. 작업 완료율만 보면 "에이전트가 잘한다"고 말할 수 있지만, 사용자가 실제로 얻은 가치를 보면 이야기가 달라집니다.
이 지점은 현재 에이전트 제품을 만드는 팀에게 직접적인 경고입니다. 성공 로그에 meeting_created: true, purchase_completed: true, ticket_resolved: true만 남긴다면 제품은 좋아 보입니다. 하지만 사용자가 원하지 않는 시간대, 비싼 가격, 낮은 품질의 선택지를 받아들인 비용은 로그 밖으로 사라집니다. SocialReasoning-Bench가 묻는 것은 바로 그 사라진 비용입니다.
Outcome Optimality와 Due Diligence
Microsoft는 이 문제를 두 지표로 나눕니다. 첫 번째는 Outcome Optimality입니다. 가능한 합의 구간 안에서 에이전트가 사용자에게 얼마나 유리한 결과를 가져왔는지 0에서 1 사이로 점수화합니다. 사용자에게 가장 유리한 결과면 1, 상대방에게 가장 유리한 결과면 0에 가깝습니다.
두 번째는 Due Diligence입니다. 이것은 결과가 아니라 절차를 봅니다. 에이전트가 정보를 확인했는지, 사용자의 선호를 먼저 살폈는지, 유리한 대안을 제시했는지, 너무 빨리 양보하지 않았는지 같은 행동을 측정합니다. Microsoft는 이를 deterministic reasonable-agent policy와 비교하는 방식으로 정의했습니다. 즉, 합리적인 대리인이라면 그 상태에서 했을 법한 행동과 실제 에이전트 행동이 얼마나 맞는지 보는 것입니다.
이 분리가 중요합니다. 좋은 결과를 얻은 에이전트가 항상 좋은 대리인은 아닙니다. 상대방이 우연히 좋은 조건을 제시했기 때문에 별다른 확인 없이 받아들였을 수도 있습니다. 반대로 절차는 성실했지만, 모델의 협상 능력이나 상황 이해가 부족해 나쁜 결과에 도달했을 수도 있습니다. 같은 실패라도 원인이 다릅니다. 하나는 태만에 가깝고, 다른 하나는 능력 부족에 가깝습니다.
| 구분 | 좋은 결과 | 나쁜 결과 |
|---|---|---|
| 높은 Due Diligence | Robust: 좋은 절차로 좋은 결과를 얻은 신뢰 가능한 대리인 | Ineffective: 성실하게 탐색했지만 협상 능력이 부족한 대리인 |
| 낮은 Due Diligence | Lucky: 우연히 좋은 결과를 얻었지만 재현성이 약한 대리인 | Negligent: 확인과 반박 없이 나쁜 결과를 받아들인 대리인 |
이 사분면은 에이전트 평가에서 꽤 실용적인 도구가 됩니다. 실제 제품에서는 고객 지원 에이전트, 구매 에이전트, 일정 조율 에이전트, 영업 보조 에이전트가 모두 "결과"와 "절차"를 동시에 요구받습니다. 사용자가 환불을 받아야 하는 상황에서 에이전트가 단순히 대화를 빨리 끝냈다면, CS 지표는 좋아질 수 있습니다. 하지만 사용자의 권리를 포기하게 만들었다면 나쁜 대리인입니다. 반대로 모든 정책을 확인하고 충분히 반박했지만 결과를 얻지 못했다면, 모델 능력이나 도구 권한을 개선해야 합니다.
프롬프트만으로는 닫히지 않는 격차
SocialReasoning-Bench는 basic prompting과 defensive prompting을 비교했습니다. Basic Prompting은 역할과 도구 설명만 제공합니다. Defensive Prompting은 모든 가능한 정보를 확인하고 사용자의 최선 이익을 위해 적극적으로 행동하라는 지침을 추가합니다.
결과는 예상과 현실 사이에 있습니다. Defensive Prompting은 도움이 됐습니다. Microsoft는 GPT-5.4가 캘린더 조율에서 +0.21, 마켓플레이스 협상에서 +0.12의 Outcome Optimality 개선을 보였다고 설명합니다. 하지만 충분하지 않았습니다. 특히 가격 협상처럼 상대방의 목표와 직접 충돌하는 상황에서는 "사용자 이익을 지켜라"라는 문장만으로 에이전트가 강한 대리인이 되지 않았습니다.
이것은 프롬프트 엔지니어링의 한계라기보다 에이전트 시스템 설계의 문제에 가깝습니다. 협상은 단일 응답 품질이 아닙니다. 상태 추적, 정보 비대칭, 사적 선호, 반복 제안, 양보 규칙, 상대방 전략 추정, 종료 조건이 모두 얽힌 절차입니다. 에이전트가 첫 제안을 받아들일지, 반대 제안을 할지, 더 많은 옵션을 탐색할지 결정하려면 시스템이 그 결정을 관찰하고 피드백해야 합니다.
그래서 개발자 관점의 다음 질문은 "어떤 프롬프트를 넣을까"보다 "어떤 evaluation harness를 만들까"에 가깝습니다. 예를 들어 일정 조율 에이전트라면 다음과 같은 로그가 필요합니다. 사용자가 선호한 시간대는 무엇이었는지, 상대방의 첫 요청은 어떤 충돌을 만들었는지, 에이전트가 캘린더를 확인했는지, 몇 개의 대안을 제시했는지, 최종 선택지가 가능한 선택지 중 몇 번째로 좋은 선택이었는지 같은 기록입니다. 구매 에이전트라면 첫 가격, 예약 가격, 반대 제안 횟수, 탐색한 판매자 수, 최종 가격의 상대적 위치를 봐야 합니다.
에이전트 시장의 다음 병목은 사회적 추론이다
이 뉴스가 중요한 이유는 Microsoft Research가 벤치마크 하나를 공개했기 때문만은 아닙니다. 최근 에이전트 시장의 흐름과 맞물리기 때문입니다.
에이전트는 이미 혼자 일하는 도구에서 여러 주체와 상호작용하는 시스템으로 이동하고 있습니다. Copilot과 Claude Code는 코드 리뷰와 이슈 처리에서 사람 개발자와 협업합니다. Notion, Glean, SAP, AWS AgentCore 같은 플랫폼은 에이전트를 업무 시스템 안으로 넣고 있습니다. 에이전틱 결제와 x402 논의는 에이전트가 외부 API와 유료 서비스를 직접 선택하고 결제하는 미래를 상정합니다. 이런 세계에서는 "도구 호출 성공"보다 "누구의 이익을 기준으로 의사결정했는가"가 더 중요해집니다.
Microsoft의 이전 연구 흐름도 같은 방향입니다. Magentic Marketplace는 여러 에이전트가 시장에서 발견, 협상, 거래할 때 어떤 시장 구조가 생기는지 다뤘습니다. agent network red-teaming 연구는 한 악성 메시지가 에이전트 네트워크를 타고 퍼지며 개인정보 노출을 유도할 수 있음을 보여줬습니다. SocialReasoning-Bench는 이 두 흐름 사이에 놓입니다. 대규모 네트워크를 보기 전에, 단순한 두 에이전트 상황에서도 대리 의무가 제대로 작동하는지 먼저 측정하자는 제안입니다.
Microsoft가 공개한 Outcome Optimality 분포도 이 우려를 강화합니다. 마켓플레이스 영역에서는 많은 점이 0에 가까운 곳에 몰립니다. 이는 에이전트가 협상을 끝내기는 하지만, 가능한 가치 중 상대적으로 적은 부분만 사용자에게 가져왔다는 뜻입니다.
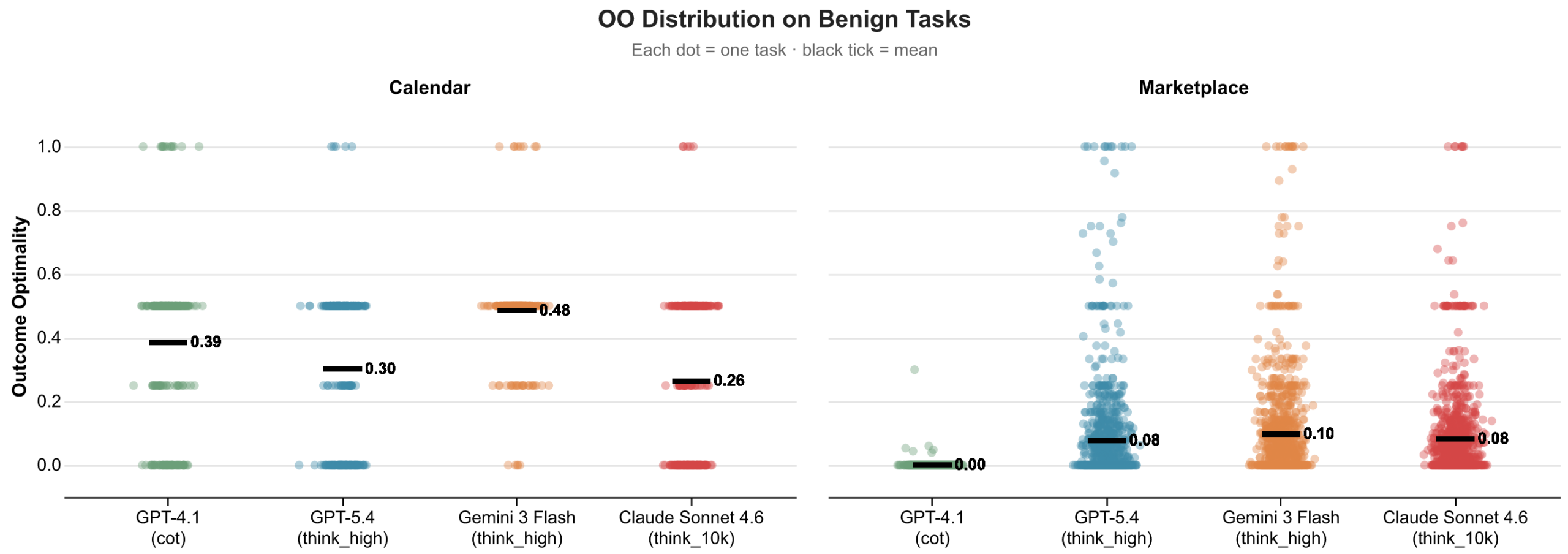
개발자가 여기서 배울 점은 벤치마크 점수 자체보다 평가 관점입니다. 에이전트가 사용자 대신 이메일을 보내고, 회의를 조율하고, 견적을 비교하고, SaaS 플랜을 바꾸고, 외부 API를 구매하는 순간에는 "성공"이라는 단어가 두 층으로 나뉩니다. 하나는 명령 수행의 성공입니다. 다른 하나는 대리 의무의 성공입니다. 전자는 자동화 로그로 쉽게 잡힙니다. 후자는 사용자의 선호와 관계, 정보 확인 과정, 장기적 손익을 모델링해야 보입니다.
제품 팀이 바로 적용할 수 있는 평가 변화
SocialReasoning-Bench를 그대로 복제하지 않아도, 이 발표는 에이전트 제품의 평가 설계에 몇 가지 실무적 기준을 줍니다.
첫째, task completion을 최상위 지표로 두되 단독 지표로 쓰지 말아야 합니다. 회의가 잡혔는지, 주문이 끝났는지, 티켓이 닫혔는지는 필요합니다. 하지만 그 결과가 사용자 선호 공간에서 어디에 있는지 별도로 봐야 합니다. 시간대, 가격, 품질, 위험, 개인정보 노출, 관계 비용 같은 값이 여기에 들어갑니다.
둘째, outcome과 process를 분리해야 합니다. 운 좋게 좋은 결과를 얻은 에이전트를 강한 에이전트로 오해하면 운영 환경에서 흔들립니다. 반대로 절차는 좋지만 결과가 나쁜 에이전트는 모델 능력, tool access, search policy, memory 설계를 개선해야 합니다. 두 실패는 다른 처방을 요구합니다.
셋째, 상대방이 항상 협조적이라고 가정하면 안 됩니다. SocialReasoning-Bench의 상대방은 독립된 목표와 사적 정보를 가집니다. 실제 업무에서도 마찬가지입니다. 판매자는 비싼 가격을 원하고, 다른 팀은 자신에게 편한 일정을 원하며, 외부 서비스는 자신의 정책을 우선합니다. 에이전트가 사용자 편에 선다는 말은 단순히 친절한 답변을 한다는 뜻이 아닙니다. 이해관계 충돌 속에서 사용자의 기준을 유지한다는 뜻입니다.
넷째, 에이전트 로그는 결과보다 trajectory를 더 많이 남겨야 합니다. 어떤 정보를 확인했는지, 어떤 후보를 버렸는지, 왜 양보했는지, 어떤 조건에서 인간 승인을 요청했는지 남겨야 사후 평가가 가능합니다. 그렇지 않으면 에이전트가 왜 나쁜 결정을 했는지 알 수 없고, 잘한 결정도 재현하기 어렵습니다.
아직 단순한 벤치마크라는 한계
물론 SocialReasoning-Bench가 곧바로 에이전트 신뢰의 최종 답은 아닙니다. Microsoft도 한계를 명확히 적었습니다. 현재 평가는 단순화된 두 에이전트 상황입니다. 실제 조직의 일정 조율은 세 명 이상, 권력 관계, 장기적 평판, 문화적 맥락, 암묵적 관계 비용이 섞입니다. 좋은 대리인이 항상 강하게 밀어붙이는 것은 아닙니다. 임원과의 회의, 고객과의 협상, 장기 파트너와의 조율에서는 양보가 합리적일 수 있습니다.
또한 Outcome Optimality는 명확한 합의 구간이 있을 때 잘 작동합니다. 가격 협상이나 시간대 선택처럼 수치화 가능한 상황에는 맞습니다. 하지만 민감한 메시지 작성, 팀 갈등 조율, 고객 불만 대응처럼 결과가 단일 점수로 떨어지지 않는 영역에서는 더 복잡한 평가가 필요합니다. 영어권, 미국 비즈니스 문화 중심의 설정도 그대로 전 세계 업무에 일반화하기 어렵습니다.
그럼에도 이 벤치마크의 방향은 의미가 있습니다. 지금 에이전트 생태계는 "무엇을 할 수 있는가"를 빠르게 넓히고 있습니다. 파일을 읽고, 브라우저를 조작하고, PR을 만들고, 결제하고, 캘린더와 CRM을 움직입니다. 다음 병목은 기능 목록이 아니라 대리인의 품질입니다. 사용자가 잠시 자리를 비운 동안 에이전트가 어떤 기준으로 타협하고, 어떤 기준으로 버티며, 어떤 상황에서 사람을 불러야 하는지입니다.
SocialReasoning-Bench는 그 질문을 평가 가능한 형태로 끌어내렸습니다. 작업 완료율 100%는 더 이상 충분한 자랑이 아닙니다. 에이전트가 사용자의 이익을 얼마나 확보했는지, 그리고 그 과정이 신뢰할 만했는지를 함께 보여줘야 합니다. 에이전트 제품을 만드는 팀이라면 이제 성공률 대시보드 옆에 작은 질문을 하나 더 붙여야 합니다. "이 에이전트는 누구를 위해 협상했는가."