Slack 200회 실험, 에이전트 테스트의 CI 대체론에 제동
Slack이 Playwright MCP, CLI, 생성 테스트를 200회 이상 비교했습니다. 결과는 CI 대체보다 탐색·디버깅 계층에 가까웠습니다.
- 무슨 일: Slack Engineering이 Playwright MCP, Playwright CLI, 에이전트 생성 Playwright 테스트를 200회 이상 실행해 E2E 테스트 적합성을 비교했습니다.
- 실험은 비운영 데이터가 들어간 테스트 워크스페이스에서 진행됐고, 각 설정은 20회씩 반복됐습니다.
- 수치: Playwright MCP는 단순 흐름 실패율 0%, 중간 복잡도 흐름 약 12%였지만, 생성된 Playwright 테스트는 복잡한 흐름에서 약 48%까지 깨졌습니다.
- 의미: 에이전트 테스트는 CI의 기본 회귀 테스트를 대체하기보다 탐색, 불안정 흐름 디버깅, 사용자 목표 검증 계층에 더 잘 맞습니다.
- 주의점: Slack 기준 에이전트 실행은 건당 15-30달러, 검색 흐름에서 수백만 토큰을 썼습니다. 비용 병목은 모델 추론보다 문맥 재전송과 턴 수였습니다.
Slack Engineering이 2026년 6월 11일 공개한 글은 테스트 자동화에서 AI 에이전트가 어디에 들어가야 하는지 숫자로 답하려는 시도입니다. 제목은 Agentic Testing: Where Agents Fit in the E2E Testing Stack입니다. 실험 대상은 Playwright MCP, Playwright CLI, 에이전트가 생성한 Playwright 테스트였습니다. Slack은 비운영 데이터가 들어간 테스트 워크스페이스에서 200회 이상 자동 실행을 돌렸고, 신뢰도, 실행 시간, 토큰 비용을 함께 측정했습니다.
이 글의 결론은 "이제 자연어로 E2E 테스트를 전부 대체한다"가 아닙니다. Slack은 기존 E2E 테스트가 특정 여정을 강제한다고 설명합니다. 예를 들면 클릭, 클릭, 입력, 검증입니다. 반면 에이전트 테스트는 목표를 받고 현재 UI를 관찰한 뒤 다른 경로를 탐색합니다. Slack의 표현을 한국어로 옮기면 "테스트는 여정을 강제하고, 에이전트는 목표를 검증한다"에 가깝습니다. 이 차이가 성공률, 비용, 디버깅 방식까지 갈라놓습니다.
Slack이 비교한 세 가지 실행 방식
실험의 첫 번째 축은 Agent + Playwright MCP입니다. 에이전트가 Playwright MCP를 통해 브라우저 동작, 입력, DOM 상태 읽기 같은 구조화된 동작을 호출합니다. Slack은 이 경로가 DOM 스냅샷과 로그를 포함한 지속 문맥을 유지한다고 설명했습니다. 두 번째 축은 Agent + Playwright CLI입니다. 에이전트가 셸에서 Playwright CLI 명령을 한 단계씩 실행하고, 갱신된 UI 상태를 보고 다음 동작을 고릅니다. 세 번째 축은 에이전트가 자연어 설명에서 Playwright 테스트 코드를 만드는 방식입니다. 이 코드는 표준 E2E 테스트처럼 실행되고, 통과할 때까지 반복 수정됩니다.
모델 조건도 명시됐습니다. Playwright MCP와 CLI 에이전트에는 Claude Sonnet 4.5가 쓰였고, 생성된 Playwright 테스트에는 Claude Opus 4.6이 쓰였습니다. 실행은 비대화형 Claude Code, 즉 claude -p였고, 환경 구성에는 Slack Dev API MCP와 비운영 데이터가 있는 테스트 워크스페이스가 포함됐습니다. 테스트 흐름은 두 가지였습니다. Thread Reply는 채널 생성, 메시지 전송, 스레드 답장, 스레드 상태 검증을 포함하는 약 15-20단계 흐름입니다. Search Discovery는 검색어 입력, 결과 탐색, 검색·채널·스레드 사이 이동, 기대 결과 검증을 포함하는 약 25-30단계 흐름입니다.
Slack은 각 설정을 20회씩 실행했습니다. 이 반복 횟수가 중요합니다. 에이전트 데모는 한 번 성공하면 그럴듯해 보이지만, CI에 들어갈 테스트는 반복 실행에서 흔들리면 쓸 수 없습니다. 특히 UI 테스트는 인증, 타이밍, 세션, 검색 결과, 비동기 렌더링에 약합니다. Slack 실험은 바로 이 반복 실행의 실패율을 보려는 설계였습니다.
| 방식 | Thread Reply 실패율 | Search Discovery 실패율 | 평균 실행 시간 |
|---|---|---|---|
| Agent + Playwright MCP | 0% | 약 12% | 약 5-8분 |
| Agent + Playwright CLI | 약 12% | 약 20% | 약 9-11분 |
| 생성된 Playwright 테스트 | 약 8% | 약 48% | 약 3분 |
실패율은 MCP가 가장 낮았고 생성 테스트는 복잡도에서 무너졌습니다
결과에서 가장 먼저 보이는 것은 Playwright MCP의 안정성입니다. Slack은 MCP 방식이 단순 흐름에서 거의 실패하지 않았고, 더 복잡한 흐름에서도 실패율이 0-12% 범위에 머물렀다고 설명했습니다. Playwright CLI는 12-20%로 더 흔들렸습니다. Slack은 CLI 실패 중 상당수가 모델 추론 자체보다 인증 처리, 내비게이션 타이밍, 세션 불안정 같은 실행 계층 문제였다고 봤습니다.
생성된 Playwright 테스트는 단순 흐름에서는 약 8% 실패율로 나쁘지 않았습니다. 하지만 Search Discovery 같은 중간 복잡도 흐름에서는 실패율이 약 48%까지 올라갔습니다. Slack은 이 테스트들이 완전히 틀린 것은 아니었다고 적었습니다. 보통 흐름의 70-80%까지는 진행했지만, 마지막 상호작용이나 검증에서 깨졌습니다. 원인은 UI 상태 변동성과 추상화 불일치였습니다. 자연어로 느슨하게 적힌 흐름에서 테스트를 생성하고 기존 페이지 객체 추상화를 재사용하다 보니, 복잡한 장면에서 정확한 요소 지정이 흔들린 것입니다.
이 수치는 테스트 자동화팀이 체감하는 문제와 맞닿아 있습니다. 생성형 테스트는 처음 만들 때 빠릅니다. 하지만 복잡한 제품 UI에서는 마지막 20%가 비용을 잡아먹습니다. 검색 결과가 다르게 뜨거나, 기존 페이지 객체가 너무 넓거나, 모달과 사이드바 상태가 조금만 달라져도 테스트는 실패합니다. 사람이 작성한 결정론적 테스트도 이런 문제를 겪지만, 에이전트 생성 테스트는 처음부터 그 불확실성을 코드로 고정해 버릴 수 있습니다.
반대로 MCP 방식은 브라우저 상태와 도구 호출이 에이전트 작업 흐름에 더 가깝게 붙습니다. Slack은 MCP가 앱의 살아 있는 상태를 더 안정적으로 보유하고, CLI는 단계마다 스냅샷을 다시 조립하는 느낌이라고 해석했습니다. 이 부분은 명시적 인과로 증명된 항목은 아니지만, 평균 턴 수와 실패 유형을 보면 설득력이 있습니다. 에이전트가 UI를 다룰 때는 모델 이름보다 브라우저와 상태를 어떻게 전달하는지가 성패를 크게 좌우합니다.
빠른 것은 생성 테스트였지만, 반복 실행의 의미가 다릅니다
실행 시간만 보면 생성된 Playwright 테스트가 가장 빠릅니다. Slack의 평균 수치는 약 3분입니다. MCP는 약 5-8분, CLI는 약 9-11분이었습니다. 생성 테스트의 3분에는 테스트 생성과 실행이 함께 들어갑니다. Slack은 테스트가 한 번 생성되고 다섯 번 실행됐으며, 순수 반복 실행은 Thread Reply 약 32초, Search Discovery 약 45초였다고 설명했습니다. CI에서는 한 번 만든 테스트를 계속 돌리기 때문에 생성 비용은 시간이 지나며 희석됩니다.
이 점 때문에 생성 테스트는 완전히 실패한 접근이 아닙니다. 단순하고 안정적인 흐름에서는 빠른 초안 생성 도구가 될 수 있습니다. 자연어 요구사항을 Playwright 코드로 바꾸고, 개발자가 셀렉터와 검증을 다듬고, 이후에는 기존 E2E처럼 반복 실행하는 방식은 현실적입니다. 다만 Slack 수치상 복잡한 흐름을 자연어에서 바로 생성해 CI에 넣는 것은 위험합니다. 실패율 48%는 테스트가 결함을 잡는 도구가 아니라 배포를 계속 막는 소음이 될 수 있는 수준입니다.
에이전트 직접 실행은 성격이 다릅니다. 매번 UI를 관찰하고, 다음 행동을 추론하고, 실행 결과를 검증합니다. 그래서 반복 실행이 빨라지지 않습니다. 오히려 매번 비슷한 토큰과 시간을 씁니다. 이 특성은 CI의 기본 회귀 테스트와 잘 맞지 않습니다. 하지만 "이 목표가 아직 달성 가능한가", "사용자가 다른 경로로도 기능을 끝낼 수 있는가", "불안정한 흐름이 어디에서 깨지는가"를 탐색하는 데는 장점이 있습니다.
 .
.
비용 병목은 모델 출력보다 문맥 재전송이었습니다
Slack이 공개한 비용 수치는 에이전트 테스트를 CI에 넣기 어려운 이유를 더 분명하게 보여줍니다. 에이전트 실행은 건당 15-30달러 수준이었습니다. Search Discovery 흐름에서 토큰 사용량은 MCP Opus 4.6 약 380만, MCP Sonnet 4.5 약 350만, MCP Haiku 4.5 약 570만, CLI Opus 4.6 약 600만, Code Gen Opus 4.6 약 700만이었습니다.
눈에 띄는 부분은 모델 등급보다 실행 방식의 영향이 더 컸다는 점입니다. Haiku는 같은 MCP 경로에서도 Sonnet이나 Opus보다 더 많은 토큰을 썼지만, MCP 계열은 전체적으로 CLI와 Code Gen보다 토큰 사용량이 낮았습니다. Slack은 Claude Code의 실행 구조를 비용 원인으로 짚었습니다. 기반 API가 상태를 보존하지 않기 때문에 매 턴 시스템 프롬프트와 전체 대화 기록이 다시 전송됩니다. 따라서 비용은 새 출력이 많아서가 아니라 문맥이 얼마나 빨리 쌓이고, 몇 턴이나 반복되는지에 의해 커집니다.
턴 수 차이도 큽니다. CLI는 평균 약 85턴이었고, MCP는 약 40-60턴이었습니다. CLI에서는 브라우저 동작, 대기, 스냅샷, 읽기, 요소 조회가 여러 명령으로 쪼개집니다. MCP는 상호작용과 상태 반환을 한 번의 왕복에 더 가깝게 묶습니다. 매 턴 전체 문맥을 다시 보내는 환경에서는 이 차이가 곧 비용 차이가 됩니다.
브라우저 스냅샷도 비용을 키웁니다. Slack 설명에 따르면 MCP와 CLI에서는 접근성 트리 스냅샷이 주요 문맥 payload입니다. 이 스냅샷은 이후 턴의 대화창에 누적됩니다. Code Gen에서는 테스트 러너 출력, 오류 추적, assertion 실패, DOM 상태가 재시도마다 쌓입니다. Slack은 대부분의 비용이 이미 본 내용의 재전송에서 나왔고, 새 정보는 작은 비중이었다고 분석했습니다. 이는 프롬프트 캐싱, 문맥 압축, 스냅샷 빈도 조절이 제품 기능만큼 중요해진다는 뜻입니다.
성공 경로가 매번 같지 않다는 것이 장점이자 리스크입니다
Slack 실험에서 정확히 같은 액션 순서를 따른 실행은 약 20%에 그쳤습니다. 성공한 경우에도 에이전트는 다른 입력 방식, 다른 메뉴 순서, 다른 탐색 경로를 택했습니다. 검색 제안을 클릭할 수도 있고, Enter를 칠 수도 있습니다. 기존 상태를 재사용할 수도 있고, 검색 화면을 다시 열 수도 있습니다. Slack은 액션 signature를 비교할 때 파라미터, wait/snapshot 동작, fill과 type처럼 같은 의미의 도구 변형을 정규화했습니다. 그 뒤에도 대부분의 실행은 서로 다른 순서였습니다.
이 특성은 기존 E2E의 관점에서는 불안정성입니다. CI는 같은 입력에 같은 행동과 같은 결과를 기대합니다. 다른 경로를 매번 택하면 실패 원인 분석이 어려워지고, 회귀 여부와 에이전트의 우연한 우회를 구분하기 어렵습니다. 하지만 사용자 목표 검증의 관점에서는 가치가 있습니다. 실제 사용자는 문서화된 한 경로만 따라가지 않습니다. 메뉴를 다르게 열고, 검색어를 바꾸고, 이전 화면 상태를 재사용합니다. 에이전트 테스트는 이런 변형 속에서도 목표 상태에 도달 가능한지 볼 수 있습니다.
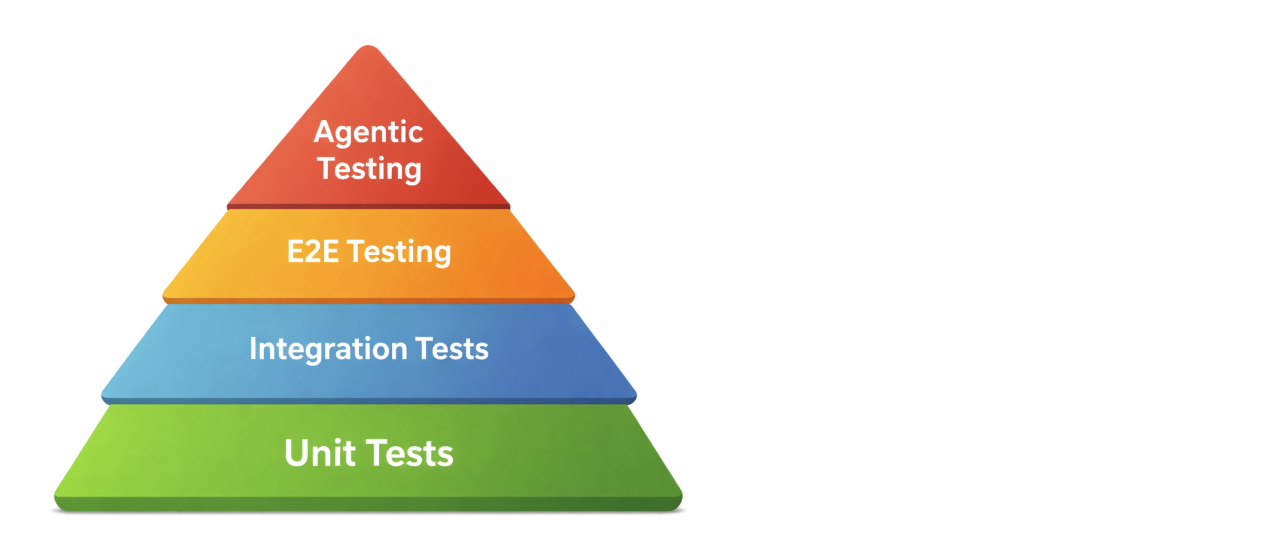
그래서 Slack의 결론은 대체가 아니라 배치입니다. 결정론적 E2E 테스트는 CI의 안정적 기반으로 남습니다. 단위 테스트와 통합 테스트가 빠르게 회귀를 잡고, 핵심 E2E가 사용자의 대표 여정을 지킵니다. 그 위에 에이전트 테스트가 탐색, 디버깅, 복잡한 행동 검증을 맡습니다. Slack의 본문 이미지는 테스트 피라미드 위에 Agentic Testing을 별도 층으로 올려놓습니다. 이는 "AI가 테스트 엔지니어를 대체한다"보다 훨씬 보수적이고 실용적인 주장입니다.
개발팀이 바로 가져갈 판단 기준
첫째, 에이전트 테스트를 일반 CI 게이트에 넣기 전 비용 상한을 정해야 합니다. Slack 기준 15-30달러짜리 테스트를 모든 PR마다 여러 번 돌리면, 작은 팀도 월말 비용을 예측하기 어렵습니다. 특히 상태 없는 API 호출에서 전체 문맥이 재전송되는 구조라면 테스트 길이가 조금만 늘어도 비용이 비선형적으로 커질 수 있습니다. 처음에는 야간 실행, 릴리스 후보 검증, 불안정 흐름 재현처럼 빈도가 낮은 경로가 더 맞습니다.
둘째, 브라우저 실행 계층을 모델 선택만큼 중요하게 봐야 합니다. Slack 실험에서 Playwright MCP와 CLI의 차이는 단순 취향이 아니었습니다. 실패율, 턴 수, 병렬 실행 난이도가 모두 달랐습니다. 브라우저 에이전트를 도입하는 팀은 "어떤 모델을 쓸 것인가"보다 "UI 상태를 어떤 구조로 에이전트에게 전달하는가", "도구 호출과 상태 반환이 몇 번의 왕복으로 끝나는가", "스냅샷이 문맥에 얼마나 오래 남는가"를 먼저 봐야 합니다.
셋째, 생성된 Playwright 테스트는 초안 생성 도구로 다루는 편이 안전합니다. 단순 흐름에서 8% 실패율은 개선 여지가 있지만 출발점으로 쓸 수 있습니다. 반면 복잡한 흐름에서 48% 실패율은 사람이 셀렉터, 검증 조건, 페이지 객체 경계를 손봐야 한다는 뜻입니다. 생성 테스트를 그대로 CI에 넣기보다, 개발자가 리뷰하고 결정론적 테스트로 굳히는 흐름이 더 현실적입니다.
넷째, 에이전트 테스트의 성공 기준을 "같은 스크립트를 재현했는가"로 잡으면 안 됩니다. Slack의 실험처럼 에이전트는 목표를 향해 여러 경로를 택합니다. 따라서 검증은 중간 클릭 순서보다 최종 상태, 데이터 변경, 사용자에게 보이는 결과, 시스템 로그에 맞춰야 합니다. 반대로 결제, 권한 변경, 삭제처럼 부작용이 큰 흐름에서는 이 자유도가 위험해질 수 있습니다. 테스트 워크스페이스, 비운영 데이터, 명확한 승인 경계가 필요합니다.
에이전트 테스트의 자리는 더 좁고 더 선명해졌습니다
Slack의 실험은 에이전트 테스트를 깎아내리는 글이 아닙니다. 오히려 과장된 기대를 줄여 실제 자리를 찾아 주는 글에 가깝습니다. Playwright MCP는 단순 흐름에서 0% 실패율을 보였고, 복잡한 흐름에서도 약 12%로 버텼습니다. 에이전트가 매번 다른 경로로 목표를 달성하는 능력은 기존 테스트가 잘 보지 못하는 사용자 경험의 가장자리를 탐색할 수 있습니다.
하지만 같은 수치는 CI 대체론에 선을 긋습니다. 생성된 Playwright 테스트는 복잡한 흐름에서 약 48% 실패했고, CLI 에이전트는 9-11분이 걸렸으며, 에이전트 실행은 건당 15-30달러를 썼습니다. 수백만 토큰 중 상당 부분은 새 추론이 아니라 누적된 브라우저 스냅샷과 이전 문맥의 재전송이었습니다. 이 구조에서는 "테스트를 더 많이 돌리면 더 안전하다"는 기존 CI 사고방식이 그대로 통하지 않습니다.
따라서 이번 Slack 글의 실무 메시지는 분명합니다. 에이전트 테스트는 기본 회귀 테스트의 대체재가 아니라, 제품 팀이 복잡한 UI 목표를 탐색하고, 불안정한 흐름을 재현하고, 사용자가 정해진 스크립트 밖에서 기능을 끝낼 수 있는지 확인하는 고비용 상위 계층입니다. AI 테스트 자동화의 다음 경쟁은 더 똑똑한 프롬프트보다 브라우저 상태, 턴 수, 문맥 압축, 비용 예산, 실패 분석 도구에서 갈릴 가능성이 큽니다.