SkillOpt 52개 평가 셀 1위권, 에이전트 스킬은 학습 대상
Microsoft SkillOpt는 SKILL.md 같은 에이전트 스킬을 rollout과 검증 점수로 학습하는 배포 산출물로 다룹니다.
- 무슨 일: Microsoft가
SkillOpt논문, 프로젝트 페이지, GitHub 코드를 공개했습니다.- arXiv v2는 2026년 5월 25일 올라왔고, 스킬 문서를
best_skill.md로 학습해 배포하는 방식을 제안합니다.
- arXiv v2는 2026년 5월 25일 올라왔고, 스킬 문서를
- 숫자: 논문은 6개 benchmark, 7개 target model, 3개 harness의 52개 평가 셀에서 best 또는 tied-best라고 주장합니다.
- 의미:
SKILL.md는 단순 prompt 파일이 아니라 rollout, 검증, 전이, 배포 이력을 가진 운영 자산이 됩니다. - 주의점: 결과는 연구 benchmark 중심입니다. 실제 repo에서는 데이터 분할, 검증 gate, 권한 통제가 함께 필요합니다.
2026년 5월 25일 arXiv에 올라온 SkillOpt 논문은 에이전트 스킬을 다루는 방식을 한 단계 바꿔 놓습니다. 정식 제목은 SkillOpt: Executive Strategy for Self-Evolving Agent Skills입니다. 논문과 프로젝트 페이지의 주장은 간단합니다. SKILL.md 같은 자연어 절차 문서를 사람이 한 번 잘 써두는 것으로 끝내지 말고, 모델 rollout과 검증 점수를 이용해 학습 가능한 외부 상태로 다루자는 것입니다.
이 뉴스가 코딩 에이전트 사용자에게 중요한 이유는 SkillOpt가 새 모델을 훈련하지 않기 때문입니다. target model은 얼려 둡니다. 대신 별도 optimizer model이 성공과 실패 trajectory를 보고 스킬 문서에 add, delete, replace edit을 제안합니다. 후보 스킬은 held-out validation score가 좋아질 때만 채택됩니다. 배포 시점에는 optimizer memory를 들고 가지 않고, compact best_skill.md 하나만 target agent가 읽습니다.
스킬 파일은 프롬프트가 아니라 외부 상태가 됩니다
최근 코딩 에이전트 제품은 저장소 안의 지시 파일을 빠르게 흡수하고 있습니다. Claude Code, Codex, GitHub Copilot app, Google Managed Agents, Android agent skills, NVIDIA Verified Skills가 같은 방향입니다. 이 제품들은 AGENTS.md, SKILL.md, MCP, hooks, plugin, connector를 제품 표면에 올리고 있습니다. 이 파일들은 처음에는 "에이전트에게 우리 팀 규칙을 알려주는 문서"처럼 보였습니다. 하지만 에이전트가 파일을 수정하고, 테스트를 실행하고, 외부 도구를 부르면 이 문서는 실행 전 조건에 가까워집니다.
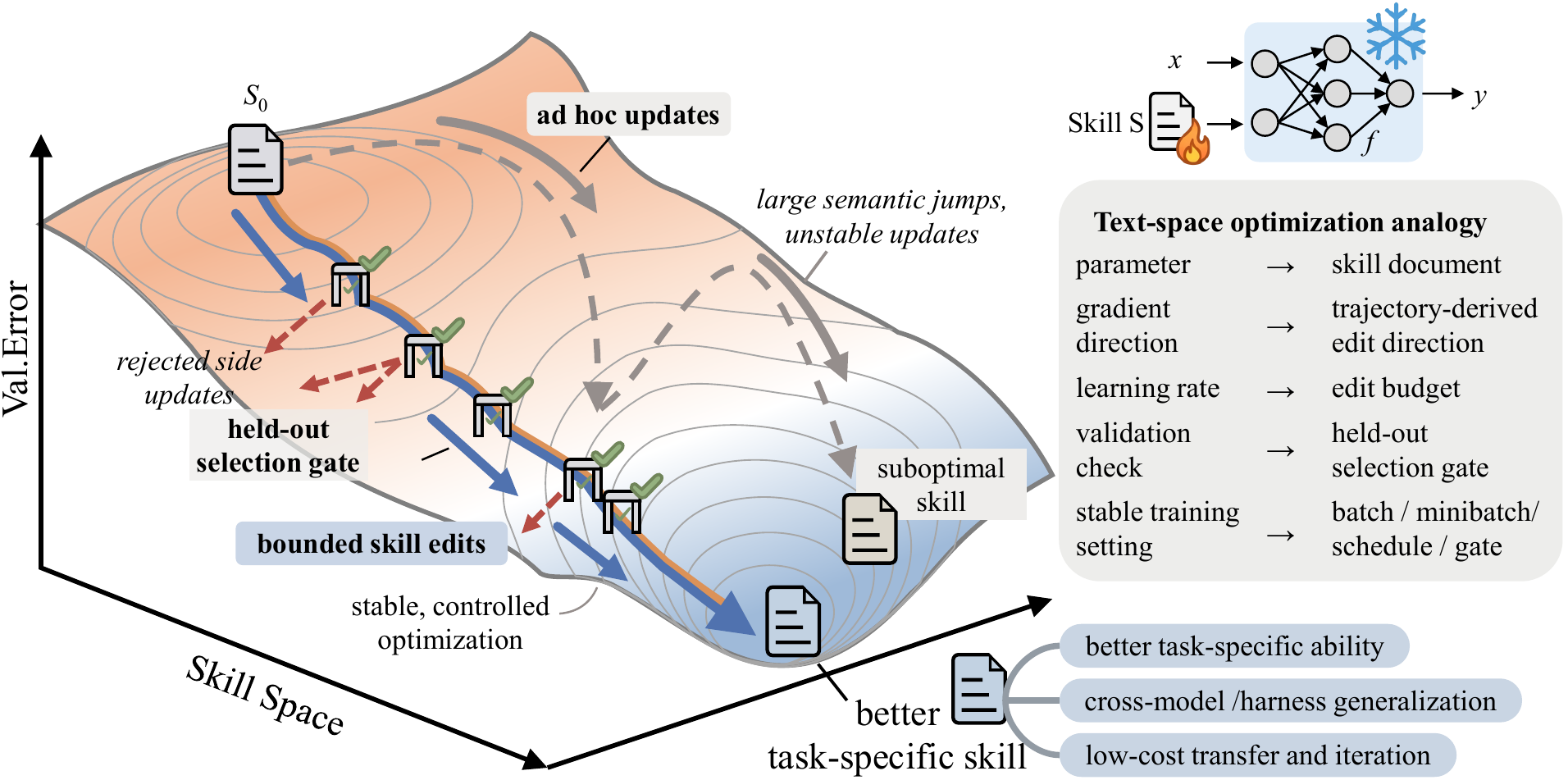
SkillOpt가 건드리는 지점은 바로 그 문서의 품질 관리입니다. 사람이 작성한 스킬은 처음에는 잘 맞아도 실패 패턴이 쌓이면 낡습니다. LLM이 한 번 생성한 스킬도 benchmark나 실제 업무에서 반복되는 실패를 자동으로 흡수하지 못합니다. SkillOpt 논문은 기존 방식이 hand-crafted, one-shot generated, loosely controlled self-revision에 머문다고 보고, 스킬 문서를 neural network weight처럼 직접 최적화하지는 않되, 학습 루프의 규율을 문서 편집에 가져옵니다.
프로젝트 README는 이를 "skill document를 frozen agent의 trainable state로 다룬다"고 설명합니다. 중요한 표현은 frozen agent입니다. SkillOpt는 target model의 weights를 바꾸지 않습니다. model provider API, Codex CLI, Claude Code CLI처럼 이미 배포된 실행 환경 위에서 스킬 문서만 바꿉니다. 기업 입장에서는 fine-tuning 권한이나 모델 내부 접근 없이도 반복 task에서 성능을 올리는 경로가 열립니다.
루프는 rollout, reflection, bounded edit, validation gate입니다
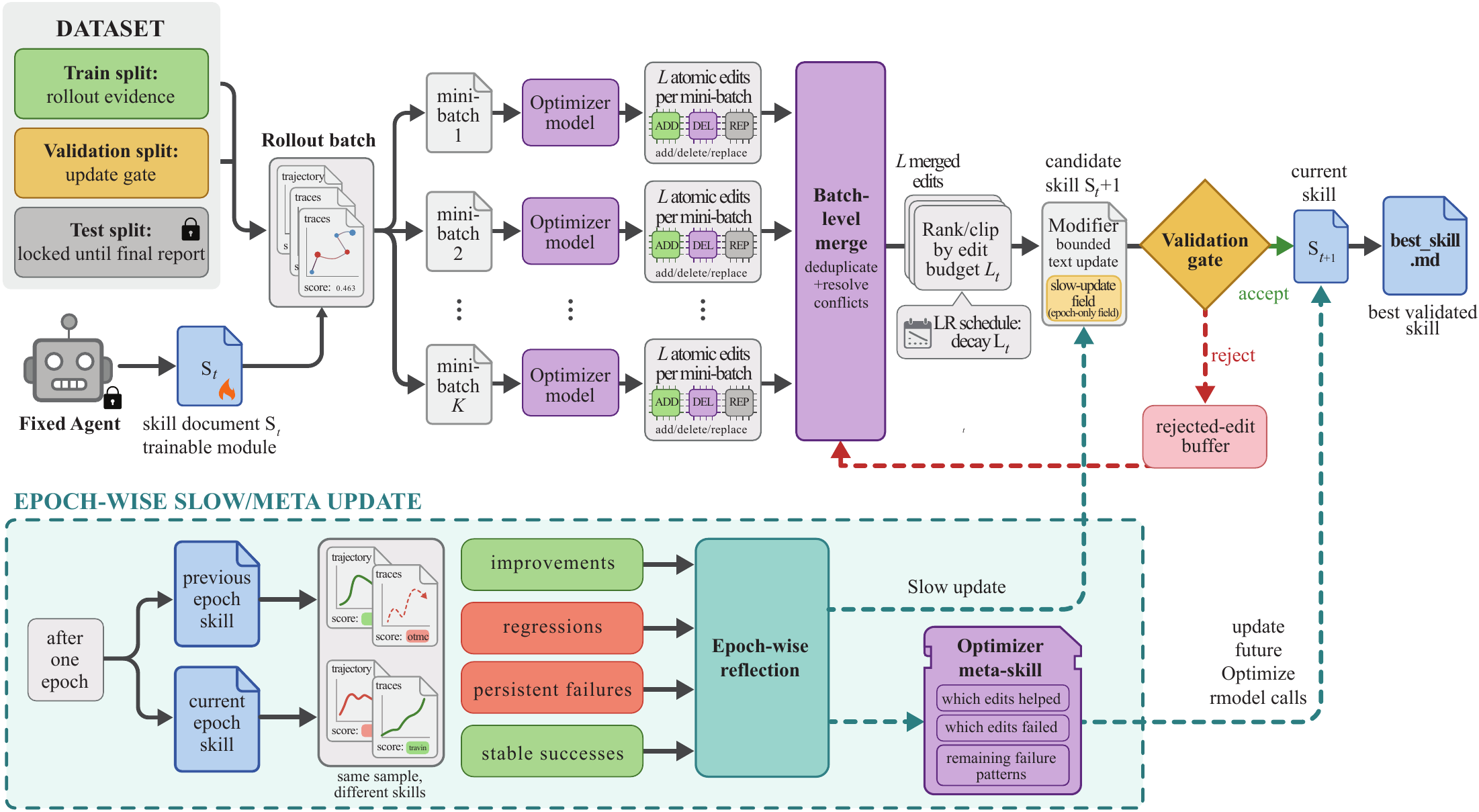
SkillOpt의 학습 루프는 네 단계로 요약됩니다. 첫째, target model이 현재 스킬을 읽고 task batch를 실행합니다. 이때 messages, tool calls, verifier feedback, task metadata, final scores가 rollout evidence로 남습니다. 둘째, optimizer model이 성공 minibatch와 실패 minibatch를 따로 보고 어떤 절차가 유지되어야 하고 어떤 오류가 반복되는지 reflection을 수행합니다. 셋째, optimizer는 스킬 문서에 bounded add/delete/replace edit을 제안합니다. 넷째, 후보 스킬은 held-out selection set에서 현재 best skill보다 좋아질 때만 채택됩니다.
여기서 bounded edit은 단순한 구현 세부가 아닙니다. 프로젝트 페이지는 textual learning rate라는 표현을 씁니다. 스킬 문서를 통째로 다시 쓰면 좋은 규칙까지 사라질 수 있습니다. 반대로 너무 작은 수정만 허용하면 새 실패 패턴을 반영하지 못합니다. SkillOpt는 edit budget으로 한 번에 움직일 수 있는 폭을 제한하고, rejected-edit buffer로 이전에 실패한 수정 방향을 optimizer가 다시 반복하지 않게 합니다.
논문 abstract는 slow/meta update도 안정화 요소로 제시합니다. epoch 단위로 더 긴 feedback을 반영하되, deployment artifact는 늘리지 않는 방식입니다. 배포되는 것은 optimizer의 긴 추론 기록이 아니라 best_skill.md입니다. README는 보통 300-2,000 token 크기의 compact skill이라고 설명합니다. 이 설계는 실무에서 중요합니다. inference 때마다 별도 optimizer call을 추가하면 latency와 비용, 보안 검토 대상이 늘어납니다. SkillOpt는 training phase와 deployment phase를 분리합니다.
| 단계 | SkillOpt 역할 | 실무 해석 |
|---|---|---|
| Rollout | 현재 skill로 task batch 실행 | 성공과 실패를 말이 아니라 trace로 남김 |
| Reflection | 성공/실패 minibatch를 분리 분석 | 고쳐야 할 규칙과 보존할 규칙을 구분 |
| Bounded edit | add/delete/replace 후보 생성 | 스킬 전체 재작성으로 인한 회귀를 줄임 |
| Gate | held-out score 개선 시에만 채택 | 그럴듯한 자기수정을 검증 산출물로 바꿈 |
52개 평가 셀과 세 가지 실행 환경
SkillOpt가 내세우는 가장 큰 숫자는 52입니다. arXiv abstract는 6개 benchmarks, 7개 target models, 3개 execution harnesses에서 평가한 52개 (model, benchmark, harness) cell 모두에서 SkillOpt가 best 또는 tied-best였다고 씁니다. 비교 대상에는 human skill, one-shot LLM skill, Trace2Skill, TextGrad, GEPA, EvoSkill 계열이 포함됩니다.
논문이 강조하는 harness도 눈에 띕니다. direct chat만 보는 것이 아니라 Codex agentic loop와 Claude Code 실행 환경을 함께 봅니다. 최근 에이전트 제품에서 성능은 모델 이름만으로 결정되지 않습니다. 같은 모델이라도 어떤 harness가 tool call을 어떻게 감싸고, 파일 시스템과 shell을 어떻게 열고, 실패를 어떻게 요약하는지에 따라 결과가 달라집니다. SkillOpt가 Codex와 Claude Code를 별도 harness로 둔 것은 이 차이를 연구 설계에 넣었다는 뜻입니다.
수치도 큽니다. abstract 기준으로 GPT-5.5에서 no-skill accuracy 대비 평균 상승폭은 direct chat +23.5 points, Codex agentic loop +24.8 points, Claude Code +19.1 points입니다. 프로젝트 페이지의 main results 표는 GPT-5.5 Codex 평균 gain을 +21.8, Claude Code 평균 gain을 +18.6으로 표시합니다. 표와 abstract의 집계 방식이 완전히 같지 않을 수 있으므로, 이 글에서는 둘을 같은 숫자로 합치지 않습니다. 분명한 부분은 SkillOpt가 direct chat보다 agent harness에서도 효과를 보였다고 주장한다는 점입니다.
벤치마크 범위는 SearchQA, Sheet/Spreadsheet, Office, DocVQA, LiveMath, ALFWorld처럼 서로 다른 task family를 포함합니다. 이것은 코딩 에이전트 전용 SWE-Bench 점수와 성격이 다릅니다. SkillOpt의 질문은 "코드를 얼마나 잘 고치는가"보다 넓습니다. 자연어 스킬이 search, spreadsheet, office automation, visual document QA, math, embodied task 같은 반복 절차에서 얼마나 재사용 가능한가를 봅니다.
전이 실험이 실무적으로 더 중요합니다
SkillOpt에서 개발팀이 특히 볼 부분은 transfer입니다. 프로젝트 페이지는 세 가지 전이 숫자를 강조합니다. GPT-5.4 LiveMath skill을 GPT-5.4-nano로 옮긴 실험은 +15.2를 보였습니다. Codex-trained SpreadsheetBench skill을 Claude Code로 옮긴 실험은 +31.8입니다. target model이 자기 자신을 optimizer로 쓴 설정은 +10.4입니다. 이 숫자가 의미하는 것은 "한 harness에서 배운 자연어 절차가 다른 실행 환경에서도 남는가"입니다.
코딩 에이전트 도입팀은 이미 이 문제를 겪고 있습니다. 한 팀은 Claude Code에서 SKILL.md를 만들고, 다른 팀은 Codex나 GitHub Copilot app에서 비슷한 지시 파일을 씁니다. 조직이 모델 provider나 agent CLI를 바꾸면 기존 스킬이 얼마나 살아남는지 알기 어렵습니다. SkillOpt의 transfer 결과는 최소한 연구 환경에서는 optimized skill artifact가 특정 모델 세션에만 갇히지 않을 수 있음을 보여줍니다.
하지만 transfer를 곧바로 운영 보증으로 읽으면 안 됩니다. 실제 회사 repo의 스킬은 내부 패키지명, 배포 절차, 보안 정책, 권한 승인, 고객 데이터 처리 규칙을 포함합니다. 한 harness에서 안전했던 명령이 다른 harness에서는 위험할 수 있습니다. 따라서 전이가 가능하다는 사실은 "복사해도 된다"가 아니라 "검증 가능한 이식 절차가 필요하다"에 가깝습니다.
자기수정이 아니라 검증된 편집입니다
에이전트 스킬을 스스로 고치게 한다는 표현은 위험하게 들릴 수 있습니다. 실제 제품에서 agent가 자기 지시문을 마음대로 고치면 prompt injection, 권한 상승, 테스트 회피, 조직 규칙 약화가 생길 수 있습니다. SkillOpt가 흥미로운 이유는 무제한 자기수정을 제안하지 않는다는 점입니다. optimizer는 후보 edit을 만들지만, 채택은 held-out validation gate가 결정합니다.
프로젝트 페이지의 ALFWorld 예시는 이 구조를 잘 보여줍니다. 한 run에서 selection score는 68.6%에서 81.4%로 올라갔고, final ALFWorld test hard score는 70.9%에서 85.8%로 개선됐다고 설명됩니다. 이 과정에서 step 4처럼 train score는 좋아도 selection gate를 통과하지 못한 후보가 있습니다. 연구 결과가 맞다면, SkillOpt는 "자기반성 문장을 더 붙이는 방식"보다 더 엄격합니다. 후보가 실제 unseen selection set에서 현재 best를 이겨야 합니다.
이 차이는 AI 팀의 운영 설계로 이어집니다. 앞으로 스킬 파일을 자동 개선하려면 최소한 세 가지가 필요합니다. 첫째, task split입니다. training rollout과 validation gate가 같은 데이터면 스킬은 benchmark 문장을 외울 수 있습니다. 둘째, rollback 가능한 artifact입니다. best_skill.md, rejected edits, score history, prompt version을 남겨야 회귀를 조사할 수 있습니다. 셋째, 권한 경계입니다. 스킬 optimizer가 조직 보안 규칙을 삭제하거나 우회하는 edit을 만들 수 없도록 policy lint와 human review가 붙어야 합니다.
GitHub 저장소와 공개 산출물
Microsoft의 SkillOpt GitHub 저장소는 2026년 5월 8일 생성됐습니다. 취재 시점인 2026년 6월 1일 04:04 UTC 기준 GitHub API에서 3,767 stars를 보였습니다. 저장소는 Python 프로젝트이며 MIT license를 둡니다. README는 Python 3.10 이상, pip install -e ., Azure OpenAI, OpenAI-compatible endpoint, Anthropic, Qwen local vLLM, MiniMax 환경변수 설정을 안내합니다.
공개 코드가 있다는 점은 중요합니다. 많은 에이전트 연구가 결과표만 남기고 실제 harness를 재현하기 어렵습니다. SkillOpt 저장소는 scripts/train.py, scripts/eval_only.py, benchmark config, outputs/<run_name>/best_skill.md 구조, 일부 pretrained skill artifact를 설명합니다. 물론 저장소 공개가 논문 수치를 자동으로 보증하지는 않습니다. 사용자는 데이터 split, 모델 버전, provider endpoint, benchmark license, API 비용을 직접 확인해야 합니다.
프로젝트 페이지에는 YouTube overview도 있고, teaser figure와 pipeline figure가 공개되어 있습니다. 이 글의 본문 이미지는 그중 pipeline figure를 사용했습니다. 썸네일은 별도 teaser figure를 사용해 카드 이미지와 본문 이미지를 분리했습니다.
에이전트 스킬 운영의 다음 기준
SkillOpt가 당장 모든 팀에 필요한 도구라고 말하기는 이릅니다. 논문은 27쪽 연구 preprint이고, 결과는 정해진 benchmark와 특정 모델·harness 조합 위에서 나온 것입니다. 실제 업무에서는 비용과 보안도 큽니다. optimizer model로 rollout을 돌리고 validation을 반복하면 API 비용이 늘고, 실패 trajectory에는 민감한 코드와 로그가 들어갈 수 있습니다. 사내 repo에 적용하려면 데이터 익명화, secret redaction, sandbox, audit log가 먼저입니다.
그럼에도 이번 발표는 에이전트 스킬을 보는 기준을 바꿉니다. 지금까지 많은 팀은 AGENTS.md나 SKILL.md를 문서 관리 문제로 다뤘습니다. 누가 작성하고, 어디에 두고, 어떤 agent가 읽는지 정도를 정했습니다. SkillOpt식 접근이 넓어지면 질문이 달라집니다. 이 스킬은 어떤 rollout evidence로 만들어졌는가. 어떤 validation set을 통과했는가. 어느 harness에서 측정됐는가. 다른 모델로 옮기면 점수가 유지되는가. 실패한 edit은 무엇이었고 왜 버렸는가.
이 질문들은 코드 리뷰와 비슷합니다. 사람이 보기에 그럴듯한 문장만으로는 부족합니다. 테스트를 통과해야 하고, 회귀를 막아야 하며, 배포 이력을 남겨야 합니다. 에이전트가 더 많은 업무를 맡을수록 스킬 파일은 README보다 release artifact에 가까워집니다.
개발팀이 지금 확인할 것
첫째, 팀이 이미 쓰는 에이전트 지시 파일을 목록화해야 합니다. AGENTS.md, CLAUDE.md, .agents/skills/*/SKILL.md, Copilot instructions, Cursor rules, MCP config가 어디에 있는지 모르면 학습이나 검증 이전에 변경 통제가 불가능합니다.
둘째, 반복 업무를 benchmark처럼 쪼개야 합니다. "우리 repo를 잘 이해한다"는 추상 목표로는 SkillOpt 같은 루프를 적용하기 어렵습니다. 예를 들어 dependency update, flaky test triage, API 문서 갱신, migration PR 작성처럼 입력과 검증 기준이 있는 task가 필요합니다. 검증은 unit test, lint, snapshot, reviewer checklist, static policy check를 조합할 수 있습니다.
셋째, 자동 개선과 자동 배포를 분리해야 합니다. SkillOpt는 candidate edit을 validation gate로 걸러내지만, 회사의 production skill에 바로 반영할지는 별도 결정입니다. 최소한 PR 형태로 best_skill.md diff를 열고, 어떤 rollout에서 어떤 점수가 좋아졌는지 붙이는 방식이 필요합니다. NVIDIA Verified Skills 같은 서명·카탈로그 흐름과도 연결될 수 있습니다.
넷째, 모델 전이를 낙관만 해서는 안 됩니다. SkillOpt는 Codex와 Claude Code 간 transfer 가능성을 보여줬지만, 실제 harness는 권한 모델과 tool semantics가 다릅니다. 같은 "run tests" 문장도 로컬 shell, remote sandbox, CI job, managed agent API에서 의미가 다릅니다. 전이된 스킬은 새 harness에서 다시 validation을 통과해야 합니다.
SkillOpt의 메시지는 모델 경쟁의 반대편에 있습니다. 새 모델을 기다리는 대신, 이미 쓰는 agent가 반복 실패에서 배운 절차를 문서로 남기고 검증할 수 있는가를 묻습니다. 답이 예라면 SKILL.md는 더 이상 정적인 운영 문서가 아닙니다. 에이전트가 경험을 압축해 들고 다니는 학습 산출물이 됩니다. 이번 논문과 공개 코드는 그 변화를 숫자와 실행 루프로 보여준 사례입니다.