SANA-WM 2.6B, 1분 월드 모델이 묻는 진짜 비용
NVIDIA SANA-WM은 2.6B 파라미터로 720p 60초 월드 모델을 주장합니다. 진짜 의미는 영상 품질보다 오픈 모델의 비용 구조입니다.

- 무슨 일: NVIDIA Research가
SANA-WM논문과 프로젝트 페이지를 공개했습니다.- 2.6B 파라미터 모델이 단일 이미지와 6-DoF 카메라 궤적으로 720p, 60초 비디오를 생성한다는 주장입니다.
- 핵심 숫자: 약 213K 공개 비디오, 64개 H100 15일 훈련, RTX 5090 증류 버전 34초 denoise입니다.
- 의미: 폐쇄형 AI 비디오 경쟁과 달리, 월드 모델을 연구자가 수정하고 검증하는 오픈 인프라로 끌어내립니다.
- 주의점:
open-source라는 표현은 코드, 모델, refiner, 가중치 공개 상태를 나눠 읽어야 합니다.
NVIDIA Research와 MIT Han Lab 계열 연구진이 2026년 5월 14일 arXiv에 SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer를 올렸습니다. 프로젝트 페이지의 한 줄 설명은 직관적입니다. SANA-WM은 "one image and a camera trajectory"를 받아 720p, 1분 길이의 controllable video를 만든다는 모델입니다. 숫자로만 보면 2.6B 파라미터입니다. 요즘 프론티어 모델 규모에 익숙한 독자에게는 작아 보일 수도 있습니다. 하지만 비교 대상이 텍스트 모델이 아니라 1분짜리 720p 비디오의 시간축과 공간축이라면 이야기가 달라집니다.
이번 소식이 흥미로운 이유는 단순히 "AI가 긴 영상을 더 잘 만든다"가 아닙니다. SANA-WM은 text-to-video 제품 발표가 아니라 월드 모델 발표입니다. 사용자가 텍스트로 장면을 지시하고 그럴듯한 클립을 얻는 흐름보다, 시작 이미지와 카메라 이동 경로를 주고 하나의 공간을 계속 둘러보게 하는 방향에 가깝습니다. 즉 영상 생성의 질문이 "무엇을 보여줄 것인가"에서 "이 세계가 계속 같은 세계로 남는가"로 이동합니다.
이 차이는 AI 개발자에게 중요합니다. 짧은 광고 영상이나 소셜 클립에서는 몇 초짜리 시각적 설득력이 우선입니다. 하지만 로보틱스, 게임, 시뮬레이션, synthetic data, embodied AI에서는 카메라가 뒤로 돌아왔을 때 문이 여전히 그 자리에 있는지, 비가 계속 같은 방향으로 내리는지, 물체가 시야 밖으로 나갔다가 돌아왔을 때 구조가 유지되는지가 중요합니다. SANA-WM이 던지는 질문은 바로 여기 있습니다. 오픈 모델이 이런 긴 시간축의 일관성을 어디까지 따라갈 수 있을까요?
SANA-WM이 실제로 주장한 것
공식 논문은 SANA-WM을 "2.6B-parameter open-source world model"로 소개합니다. 핵심 입력은 단일 첫 프레임 이미지와 metric 6-DoF camera trajectory입니다. 6-DoF는 카메라의 위치 이동 3축과 회전 3축을 포함하는 경로를 뜻합니다. 일반적인 prompt 기반 비디오 생성보다 제어가 좁고, 대신 평가 기준은 더 엄격합니다. 텍스트가 "숲속 길"이라고 말했을 때 그럴듯한 숲을 만드는 것과, 카메라가 실제 경로를 따라 움직이는 동안 같은 숲의 구조를 유지하는 것은 다른 문제입니다.
연구진이 제시한 설계는 네 가지입니다. 첫째, Hybrid Linear Attention입니다. 프레임 단위 Gated DeltaNet과 주기적인 softmax attention을 결합해 긴 문맥을 다루면서도 full attention의 메모리 비용을 피합니다. 둘째, Dual-Branch Camera Control입니다. coarse global pose branch와 fine pixel-aligned geometric branch를 함께 써서 카메라 궤적을 더 정확히 따르게 합니다. 셋째, Two-Stage Generation Pipeline입니다. 2.6B long-rollout backbone이 긴 비디오를 만들고, 그 위에 17B long-video refiner가 텍스처와 후반부 품질을 보강합니다. 넷째, Robust Annotation Pipeline입니다. 공개 비디오에서 metric-scale 6-DoF camera pose를 추출해 학습 라벨로 씁니다.
숫자는 꽤 공격적입니다. 논문에 따르면 SANA-WM은 약 213K개의 공개 비디오 클립과 카메라 pose supervision으로 학습됐고, 64개 H100에서 15일 만에 훈련됐습니다. 60초 720p 클립은 단일 GPU에서 생성할 수 있으며, 증류된 변형은 RTX 5090에서 NVFP4 quantization으로 60초 720p 클립을 34초에 denoise할 수 있다고 설명합니다. 또한 one-minute world-model benchmark에서 기존 오픈소스 baseline보다 action-following accuracy가 강하고, 비슷한 시각 품질을 36배 높은 throughput으로 달성했다고 주장합니다.
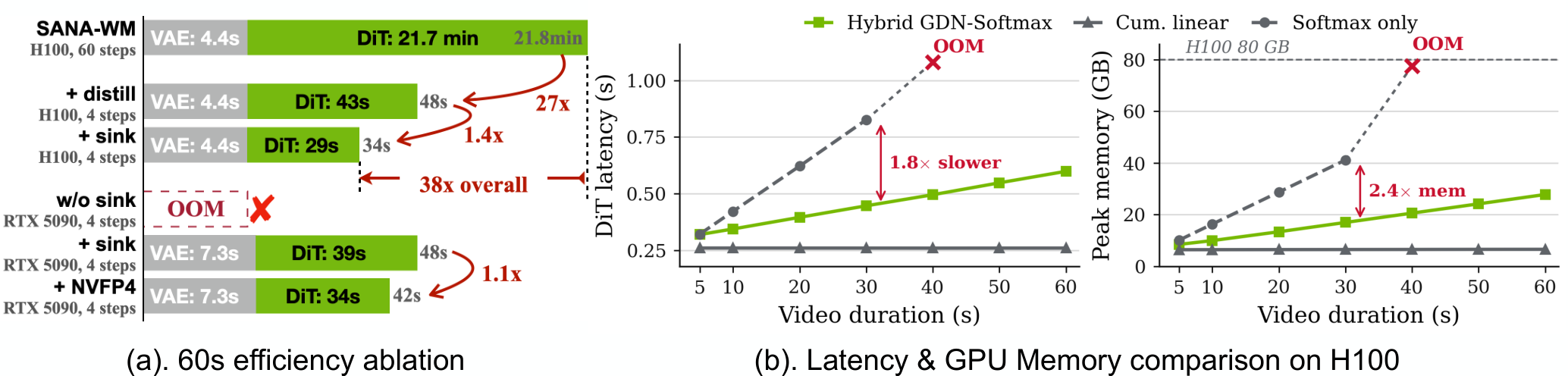
이 도표가 중요한 이유는 SANA-WM의 주장이 품질만이 아니라 비용에 걸려 있기 때문입니다. 폐쇄형 비디오 모델은 데모 영상의 미학으로 경쟁합니다. SANA-WM은 "이 정도 길이와 해상도를 연구자가 감당할 수 있는 비용으로 반복 실험할 수 있는가"를 전면에 놓습니다. 월드 모델이 로보틱스나 시뮬레이션의 도구가 되려면, 한 번의 멋진 샘플보다 수천 번의 생성과 평가가 더 중요합니다. 그 반복이 가능하려면 latency, memory, training compute가 뉴스의 중심이 됩니다.
왜 월드 모델인가
"월드 모델"이라는 말은 올해 들어 지나치게 넓게 쓰이고 있습니다. 원래 강화학습과 로보틱스에서 world model은 현재 상태와 행동을 바탕으로 다음 상태를 예측하는 모델에 가깝습니다. 시스템이 직접 세계를 만져보기 전에 머릿속에서 결과를 시뮬레이션하는 장치입니다. 하지만 최근 비디오 생성 분야에서는 의미가 조금 좁아졌습니다. 화면 속 세계가 사용자의 카메라 이동이나 조작을 따라가며 일관적으로 변화하면, 이를 world model이라고 부르는 경우가 많아졌습니다.
SANA-WM도 후자에 가깝습니다. 모델이 숨겨진 물리 엔진을 가지고 있다고 단정하기는 어렵습니다. 출력은 여전히 비디오입니다. 다만 카메라 경로와 장면 구조를 1분 동안 유지하려고 훈련된 비디오 모델이라는 점에서, 단순한 짧은 클립 생성기와는 다릅니다. Hacker News 토론에서도 이 지점이 갈렸습니다. 어떤 댓글은 로보틱스 planning에 유용할 수 있다고 봤고, 어떤 댓글은 "video world model"이 실제 planning stack의 정답인지 아직 증거가 약하다고 봤습니다.
게임 개발 관점의 회의도 나왔습니다. 한 사용자는 훌륭한 게임 세계에는 물건 하나하나의 intentionality가 있고, 생성형 월드 모델이 이런 인간적 설계를 대체하기 어렵다고 지적했습니다. 이 비판은 중요합니다. 월드 모델이 만든 공간은 일관적일 수 있지만, 그 일관성이 곧 좋은 경험을 뜻하지는 않습니다. 길이 계속 이어지고 건물이 무너지지 않는 것과, 그 공간이 플레이어에게 의미 있는 선택과 기억을 제공하는 것은 별개의 문제입니다.
그럼에도 SANA-WM은 AI 개발자에게 실용적인 기준점을 제공합니다. 첫째, 긴 비디오의 데이터 라벨링 문제를 공개적으로 다룹니다. 둘째, full attention이 아니라 hybrid linear attention으로 60초라는 길이를 다룹니다. 셋째, 모델이 텍스트만이 아니라 카메라 궤적이라는 행동 신호를 받습니다. 이 세 가지는 향후 브라우저 에이전트, 로봇 학습, 디지털 트윈, 게임 프로토타이핑 도구가 공유할 수 있는 기술적 언어입니다.
오픈 모델 경쟁에서 다른 점
SANA-WM의 가장 큰 차별점은 "오픈"이라는 단어입니다. Sora, Veo, Runway, Kling 같은 서비스는 대부분 API나 제품 표면으로 경험됩니다. 사용자는 결과물을 만들 수 있지만, 아키텍처와 학습 파이프라인, 평가 방식, 가중치, 실패 사례를 충분히 들여다보기 어렵습니다. 반대로 SANA 저장소는 Apache-2.0 라이선스의 공개 코드베이스이며, README는 SANA, SANA-1.5, SANA-Sprint, SANA-Video, SANA-WM, Sol-RL을 하나의 효율 지향 생성 모델 패밀리로 묶어 설명합니다.
하지만 여기서 바로 조심해야 합니다. 프로젝트 페이지의 Models 버튼은 확인 시점 기준 soon 상태였습니다. HN에서도 모델 가중치가 즉시 열려 있는지에 대한 회의가 있었습니다. 또 SANA-WM의 핵심 데모는 2.6B backbone만으로 끝나지 않습니다. 공식 페이지는 모든 비디오가 SANA-WM의 bidirectional variant 뒤에 second-stage long-video refiner를 거쳤다고 밝힙니다. 논문과 페이지의 feature card도 "dedicated 17B long-video refiner"를 명시합니다. 따라서 "2.6B 모델 하나가 모든 품질을 만들었다"로 읽으면 과장입니다.
또 하나 흥미로운 고백이 있습니다. 공식 페이지는 갤러리 데모의 first-frame images가 OpenAI GPT Image 2와 Google Nano Banana Pro로 생성됐고, SANA-WM은 그 정지 이미지를 1분 비디오로 animate한다고 적습니다. 이것은 약점이라기보다 정확히 읽어야 할 범위입니다. SANA-WM은 이미지 생성 전체 파이프라인을 처음부터 끝까지 대체했다기보다, 좋은 시작 이미지와 카메라 경로가 있을 때 긴 시간축의 세계를 굴리는 모델입니다.
이 구분은 실무에서 중요합니다. 만약 팀이 AI 비디오 제품을 만들려 한다면, SANA-WM은 "텍스트를 넣으면 완성 영상이 나온다"는 엔드유저 제품보다 낮은 계층의 연구 도구에 가깝습니다. 반대로 로보틱스나 시뮬레이션 팀이라면 바로 이 낮은 계층이 더 중요할 수 있습니다. 시작 상태, 카메라 또는 행동 궤적, refiner, 평가 루프를 분리해서 실험할 수 있기 때문입니다.
효율성의 의미는 단순한 속도가 아닙니다
SANA-WM이 내세우는 효율성은 세 층으로 나뉩니다. 첫 번째는 데이터 효율입니다. 논문은 약 213K 공개 비디오 클립을 사용했다고 말합니다. NVIDIA Cosmos 같은 대규모 world foundation model 계열이 수천만 시간의 비디오를 말해온 것과 비교하면 작습니다. 물론 데이터 규모가 작다는 말이 곧 더 좋다는 뜻은 아닙니다. 오히려 질문은 "어떤 annotation pipeline과 pose supervision이 긴 시간축 학습에 충분한 신호를 주는가"입니다.
두 번째는 훈련 효율입니다. 64개 H100에서 15일은 개인 연구자에게 가벼운 비용이 아닙니다. 하지만 대형 비디오 foundation model의 산업적 훈련 비용과 비교하면, 대학 연구실과 기업 연구팀이 재현 가능성을 논의할 수 있는 범위에 가까워집니다. AI 인프라 관점에서 중요한 것은 절대 비용보다 비용의 기울기입니다. 모델이 조금 길어질 때 메모리와 시간이 폭발하면 연구 루프가 막힙니다. SANA-WM은 hybrid linear attention으로 그 기울기를 낮추려 합니다.
세 번째는 추론 효율입니다. 60초 720p 클립을 단일 GPU에서 생성할 수 있다는 주장은 월드 모델을 제품 안의 반복 작업으로 넣을 수 있는지와 연결됩니다. 예를 들어 로봇이 여러 행동 후보를 상상하고 그 결과를 비교하려면, 한 번의 생성이 몇십 분 걸리는 구조는 곤란합니다. 게임 프로토타입에서 여러 카메라 경로를 비교하려 해도 마찬가지입니다. RTX 5090에서 34초 denoise라는 숫자가 관심을 끄는 이유는 이 때문입니다. "멋진 데모"가 아니라 "반복 가능한 작업 단위"가 보이기 시작합니다.
다만 이 숫자들은 독립 벤치마크가 아닙니다. 논문과 프로젝트 페이지의 주장입니다. 실제 연구자가 같은 설정, 같은 품질 기준, 같은 refiner 조건으로 재현할 수 있는지는 공개 가중치와 코드, evaluation script가 얼마나 빨리 정리되는지에 달려 있습니다. 오픈 모델의 신뢰는 발표문이 아니라 재현 커밋에서 생깁니다.
Sora 이후 오픈 비디오의 다른 길
폐쇄형 AI 비디오 서비스는 대체로 창작자 도구로 포장됩니다. 프롬프트, 스타일, 샷, 편집, 안전 필터, 저작권 정책이 중심입니다. 반면 SANA-WM은 로보틱스와 embodied AI를 직접 언급합니다. 이는 NVIDIA다운 방향입니다. NVIDIA는 GPU 공급자이면서 동시에 Cosmos 같은 physical AI 플랫폼을 밀고 있습니다. 월드 모델은 영상 앱의 기능일 뿐 아니라, 물리 세계를 학습하고 검증하는 인프라가 될 수 있습니다.
여기서 SANA-WM은 폐쇄형 서비스와 정면 경쟁하기보다 다른 질문을 냅니다. 좋은 AI 비디오 제품이 되려면 사용자 경험, 저작권, 편집 도구, 배포 채널이 필요합니다. 좋은 월드 모델 연구 기반이 되려면 카메라 제어, 장기 일관성, 반복 가능한 평가, 낮은 추론 비용, 가중치와 코드 접근성이 필요합니다. SANA-WM의 의미는 후자에 있습니다.
개발자에게는 이 차이가 선택지를 만듭니다. 제품에 바로 넣을 고품질 홍보 영상을 원한다면 여전히 폐쇄형 서비스가 더 쉬울 수 있습니다. 하지만 에이전트가 브라우저나 데스크톱을 조작하는 동안 화면 변화를 예측하거나, 로봇이 특정 이동 경로의 시각 결과를 상상하거나, 게임 엔진 밖에서 빠른 장면 후보를 탐색하려면 API 제품보다 모델과 파이프라인의 분해 가능성이 중요합니다.
물론 당장 실무에 넣기에는 제약이 많습니다. 첫 프레임 생성은 다른 모델에 의존할 수 있습니다. 17B refiner가 필요하면 전체 시스템 비용은 2.6B라는 숫자보다 큽니다. 물리적으로 그럴듯한 비디오가 실제 planning에 충분한 causal model인지도 검증되어야 합니다. HN의 회의적인 반응처럼, 월드 모델이라는 이름이 과도한 기대를 부를 위험도 있습니다.
과장 없이 읽는 체크리스트
SANA-WM을 볼 때 가장 먼저 나눠야 할 것은 세 가지입니다. 첫째, 코드베이스가 열려 있는가. NVlabs/Sana 저장소는 공개되어 있고 Apache-2.0 라이선스를 표시합니다. 둘째, SANA-WM 가중치와 문서가 실제로 내려받고 재현 가능한가. 프로젝트 페이지의 Models는 soon 상태였으므로 이 부분은 계속 확인해야 합니다. 셋째, 발표 수치가 어떤 pipeline 조건에서 나온 것인가. 2.6B backbone, bidirectional variant, 17B refiner, NVFP4 distillation을 분리해야 합니다.
두 번째 체크리스트는 용도입니다. SANA-WM을 일반 영상 생성기로 보면 불만이 생길 수 있습니다. 반대로 장기 카메라 제어 모델로 보면 의미가 선명합니다. 한 장면을 60초 동안 둘러보며 구조를 유지하는 능력은 짧은 text-to-video 모델과 다른 벤치마크를 요구합니다. 그래서 논문도 visual quality뿐 아니라 action-following accuracy와 throughput을 함께 말합니다.
세 번째는 데이터입니다. 공개 비디오에서 metric 6-DoF pose를 추출하는 annotation pipeline은 이번 논문의 숨은 핵심입니다. 비디오 모델의 경쟁력은 모델 크기만으로 나오지 않습니다. 어떤 영상에서 어떤 행동 라벨을 뽑아내고, 그 라벨이 실제 카메라 제어를 얼마나 잘 설명하는지가 중요합니다. 이 파이프라인이 공개되고 검증되면, SANA-WM의 가치는 모델 하나를 넘어 데이터 제작 방법론으로 확장됩니다.
지금의 결론
SANA-WM은 "오픈소스가 Sora를 이겼다" 같은 단순한 이야기가 아닙니다. 오히려 그런 제목은 이번 발표를 흐립니다. 더 정확한 뉴스는 오픈 비디오 연구가 5초짜리 품질 경쟁에서 60초짜리 제어 가능 세계와 비용 구조의 경쟁으로 이동했다는 점입니다. 2.6B라는 숫자는 작아 보이지만, 1분 720p라는 시간축과 카메라 제어를 붙이면 다른 의미를 갖습니다.
동시에 SANA-WM은 조심해서 읽어야 합니다. 모델 가중치 공개 상태, 17B refiner, 외부 이미지 생성 모델로 만든 first frame, 독립 재현 전의 benchmark 수치까지 모두 괄호 안에 넣어야 합니다. 오픈 모델은 발표 당일의 claims가 아니라, 누군가 같은 환경이 아닌 곳에서 실패와 성공을 반복하며 검증할 때 힘을 얻습니다.
그래도 방향은 분명합니다. AI 비디오는 더 이상 영상 앱만의 문제가 아닙니다. 에이전트가 행동을 계획하고, 로봇이 시뮬레이션을 돌리고, 개발자가 synthetic environment를 만들고, 연구자가 긴 시간축의 일관성을 재는 인프라 문제입니다. SANA-WM은 그 인프라가 폐쇄형 API 밖에서도 만들어질 수 있다는 신호입니다. 이번 발표의 진짜 비용은 GPU 시간이 아니라, 우리가 "월드 모델"이라는 단어에 요구할 검증 기준을 어디까지 높일 것인가에 있습니다.