99.82% 캐시 적중, 코딩 에이전트 비용표의 새 변수
Reasonix 논쟁은 코딩 에이전트 비용이 모델 가격뿐 아니라 prefix cache를 깨지 않는 하네스 설계에 달렸음을 보여줍니다.

- 무슨 일: 독립 오픈소스 코딩 에이전트
Reasonix가 DeepSeek prefix cache에 맞춘 하네스로 HN 논쟁을 만들었습니다.- 2026년 5월 24일 기준 npm
0.50.1, GitHub desktopv0.50.0이 공개됐습니다.
- 2026년 5월 24일 기준 npm
- 핵심 숫자: 프로젝트는 하루
435M입력 토큰에서99.82%cache hit, 약$12.34비용 사례를 제시합니다. - 의미: 코딩 에이전트 비용 경쟁은 모델 단가표에서
prefix를 흔들지 않는 세션 설계로 이동하고 있습니다.- 단, Reasonix는 DeepSeek 공식 제품이 아니라 독립 프로젝트이며, 벤치마크와 보안 가정은 따로 검증해야 합니다.
코딩 에이전트 시장의 다음 가격표는 모델 이름 옆에 붙은 100만 토큰당 단가만으로 읽히지 않습니다. 같은 모델을 쓰더라도 에이전트 하네스가 매 턴마다 system prompt, tool schema, 작업 로그를 어떤 순서와 바이트로 직렬화하느냐에 따라 캐시 적중률이 달라지고, 그 차이가 장시간 세션의 실제 비용을 갈라놓습니다. 이번에 Hacker News에서 뜨거운 논쟁을 만든 Reasonix는 바로 그 지점을 정면으로 밀고 들어온 독립 오픈소스 코딩 에이전트입니다.
Reasonix의 소개 문구는 간단합니다. DeepSeek 전용 터미널 코딩 에이전트이며, prefix-cache stability를 중심으로 설계됐다는 것입니다. 2026년 5월 24일 기준 npm 패키지 reasonix의 최신 버전은 0.50.1이고, 같은 날 GitHub에는 desktop-v0.50.0 릴리스가 올라왔습니다. GitHub API로 확인한 저장소 esengine/DeepSeek-Reasonix는 2026년 4월 21일 만들어졌고, MIT 라이선스, 6,443 stars, 366 forks를 기록했습니다. 성장 속도 자체도 빠르지만, 더 중요한 것은 이 프로젝트가 "더 똑똑한 에이전트"보다 "캐시가 깨지지 않는 에이전트"를 전면에 세웠다는 점입니다.
여기서 조심할 부분이 있습니다. Reasonix는 DeepSeek의 공식 제품이 아닙니다. 프로젝트가 DeepSeek API와 모델 가격 구조를 강하게 전제하고 있을 뿐, 독립 오픈소스 프로젝트입니다. 따라서 이 글은 "DeepSeek가 새 코딩 에이전트를 냈다"는 소식이 아닙니다. 더 정확한 뉴스는, 저가 모델과 캐시 과금이 결합되면서 코딩 에이전트 하네스 설계 자체가 비용 경쟁의 전장으로 떠올랐다는 것입니다.
왜 캐시가 뉴스가 됐나
LLM API의 prompt cache나 prefix cache는 새로운 개념이 아닙니다. 같은 앞부분을 반복해서 보내면 공급자는 이미 계산한 prefix를 재사용할 수 있고, 사용자는 더 낮은 입력 토큰 비용과 낮은 지연시간을 얻습니다. 문제는 코딩 에이전트의 실제 대화가 깔끔한 반복이 아니라는 점입니다. 에이전트는 매 턴 파일을 읽고, 셸을 실행하고, 도구 스키마를 나열하고, 현재 시간과 작업 디렉터리, git 상태, 승인 모드, 이전 도구 결과를 프롬프트에 넣습니다. 이 과정에서 앞부분 바이트가 조금이라도 바뀌면 prefix cache는 그 지점 이후를 재사용하지 못합니다.
Reasonix의 아키텍처 문서는 이 문제를 제품의 첫 번째 기둥으로 둡니다. 문서는 DeepSeek가 cached input을 miss rate의 약 10%로 과금한다고 설명하고, 자동 prefix caching은 이전 요청과 정확히 같은 byte prefix가 맞을 때만 작동한다고 전제합니다. 그래서 Reasonix는 컨텍스트를 세 영역으로 나눕니다. 세션 시작 때 고정되는 immutable prefix, 뒤에만 붙는 append-only log, 그리고 upstream으로 보내지 않는 volatile scratch입니다.
이 설계의 요지는 "프롬프트를 잘 압축하자"가 아닙니다. 오히려 이전 prefix를 다시 쓰거나 재정렬하지 않는 것입니다. system prompt와 tool specs를 세션 시작 때 한 번 계산해 고정하고, 이후 대화 로그는 append-only로만 늘립니다. 임시 사고 과정이나 계획 상태는 다음 요청의 cached prefix를 오염시키지 않도록 별도 scratch로 다룹니다. 큰 도구 결과는 다음 턴 이후에 요약되지만, 그 요약도 기존 prefix를 고쳐 쓰는 방식이 아니라 뒤에 추가되는 방식으로 설계됐다고 문서는 설명합니다.
이런 구조는 단순한 최적화처럼 보일 수 있습니다. 하지만 코딩 에이전트에서는 자주 깨집니다. 모드가 바뀌며 tool list가 달라지고, 현재 시간이 system prompt 앞부분에 들어가고, compaction이 이전 대화 전체를 다시 쓰고, 여러 provider를 추상화하는 SDK가 tool schema를 매번 다른 공백으로 직렬화하면 캐시는 이론상의 혜택으로 남습니다. Reasonix가 Hacker News에서 받은 반응도 바로 이 지점에 걸렸습니다. 어떤 사용자는 "이건 모든 좋은 하네스가 해야 하는 기본 원칙"이라고 봤고, 다른 사용자는 "그 기본 원칙을 실제 제품 루프에서 유지하는 것이 비용 차이를 만든다"고 반박했습니다.
435M 토큰 하루 비용 사례
Reasonix가 가장 강하게 내세우는 숫자는 real-world cache hit benchmark에 있습니다. 프로젝트는 한 사용자가 2026년 5월 1일 공유한 DeepSeek 대시보드를 익명화해 공개했다고 설명합니다. 해당 사례에서 input cache hit은 435,033,856 tokens, input cache miss는 767,616 tokens, output은 179,763 tokens입니다. 입력 기준 cache hit ratio는 99.82%입니다.
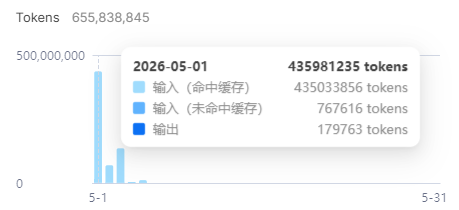
프로젝트가 사용하는 deepseek-v4-flash 가격 가정에서는 이 하루 작업이 약 $12.34였고, 같은 입력이 0% cache hit이었다면 약 $60.63으로 계산됩니다. 즉 하루에 약 $48.29, 대략 80% 절감이라는 주장입니다. v4-pro 가정에서는 절감률이 더 커진다고 문서는 덧붙입니다. 숫자가 사실이라면, 개발자가 코딩 에이전트를 "잠깐 묻고 끄는 챗봇"이 아니라 하루 종일 켜 두는 작업 루프로 쓰는 순간 캐시 적중률은 부가 기능이 아니라 운영 비용의 핵심 변수가 됩니다.
다만 이 숫자는 제품 벤치마크라기보다 프로젝트가 공개한 사례 연구에 가깝습니다. 사용자의 작업 종류, 세션 길이, 읽은 파일 수, 실패율, 사람이 실제로 얻은 산출물 품질까지 함께 비교한 것은 아닙니다. 또한 같은 DeepSeek API를 다른 하네스에 연결했을 때, 성숙한 코딩 에이전트들이 어느 정도 cache hit을 유지하는지도 공개적으로 표준화된 비교가 충분하지 않습니다. HN 댓글에서도 "다른 하네스 대비 벤치마크가 보고 싶다"는 반응이 나왔습니다.
그럼에도 이 사례가 중요한 이유는 있습니다. 코딩 에이전트의 비용 논쟁을 "어떤 모델이 싸냐"에서 "어떤 루프가 cacheable bytes를 보존하느냐"로 옮겼기 때문입니다. 모델 가격은 공급자가 정하지만, 하네스가 prefix를 깨뜨리는 방식은 클라이언트가 결정합니다. 이 결정이 반복 작업에서는 모델 품질만큼이나 체감 비용을 바꿀 수 있습니다.
Reasonix가 말하는 세 가지 하네스 원칙
첫 번째 원칙은 immutable prefix입니다. system prompt와 tool specifications는 세션 시작 때 계산하고 고정합니다. "현재 시간", "현재 브랜치", "작업 디렉터리"처럼 자주 바뀌는 정보를 prefix 앞쪽에 넣으면, 실제 내용이 조금만 바뀌어도 그 뒤의 긴 로그 전체가 cache miss가 될 수 있습니다. Dockerfile에서 변하는 단계는 가능한 뒤로 보내야 빌드 캐시가 살아남는 것과 비슷합니다. 코딩 에이전트에서도 변하는 데이터를 어디에 놓느냐가 비용의 문제로 바뀝니다.
두 번째 원칙은 append-only log입니다. 에이전트가 이전 대화를 요약하거나 tool result를 정리해야 할 때도 이전 prefix 자체를 덮어쓰지 않고 뒤에 추가하는 방식을 택합니다. 일반적인 compaction은 컨텍스트 길이를 줄이는 데 유리하지만, 기존 history를 다시 쓰는 순간 캐시 관점에서는 큰 prefix가 사라질 수 있습니다. Reasonix는 turn-end auto-compaction을 비용 제어 장치로 두면서도, 캐시가 깨지는 형태의 재직렬화를 피하려 합니다.
세 번째 원칙은 volatile scratch입니다. 에이전트가 내부적으로 plan state나 reasoning scratch를 다룰 수는 있지만, 그 임시 상태가 다음 요청의 cached prefix를 흔들지 않아야 합니다. 이 대목은 특히 reasoning 모델에서 중요합니다. 긴 사고 과정과 도구 결과를 그대로 다음 턴에 끌고 가면 모델이 더 많은 맥락을 보는 것처럼 보이지만, 비용과 지연시간은 빠르게 불어납니다. Reasonix는 scratch를 upstream log와 분리하는 방식으로 이 문제를 다루겠다고 설명합니다.
이 설계는 DeepSeek 전용이라는 선택과 연결됩니다. Reasonix는 provider abstraction을 넓히는 대신 DeepSeek의 prefix cache와 가격 구조에 맞춥니다. 범용성은 줄지만, 한 provider의 경제적 특성에 맞춘 하네스 최적화는 더 공격적으로 할 수 있습니다. 이것이 앞으로 다른 에이전트에도 반복될 가능성이 있습니다. OpenAI, Anthropic, Google, DeepSeek, Moonshot, Qwen 계열이 각각 다른 캐시 정책과 가격표를 제공한다면, "모든 모델을 같은 루프로 호출하는 범용 하네스"와 "특정 provider의 캐시 문법에 맞춘 하네스" 사이의 선택이 생깁니다.
HN의 회의론이 중요한 이유
HN 토론에서 흥미로운 점은 반응이 일방적이지 않았다는 것입니다. 일부 사용자는 DeepSeek v4 계열을 Claude Code나 OpenCode류 하네스에 연결해도 높은 cache hit을 얻을 수 있다고 말했습니다. 다른 사용자는 Reasonix의 페이지가 cache-first를 과하게 마케팅한다고 봤습니다. "모든 모델과 코딩 하네스가 이렇게 동작하는 것 아니냐"는 댓글도 있었습니다.
이 회의론은 기사에서 빼면 안 됩니다. prefix cache를 보존하는 원칙 자체는 새로운 컴퓨터 과학이 아닙니다. 바이트가 같으면 캐시가 맞고, 중간이 바뀌면 깨집니다. 문제는 제품 루프가 실제로 그 원칙을 얼마나 엄격히 지키느냐입니다. 특히 코딩 에이전트는 권한 모드, tool schema, MCP 서버, subagent, memory, approval UI, background job, file diff, checkpoint 같은 기능이 계속 늘어납니다. 기능이 늘수록 prompt serialization은 흔들리기 쉽습니다. 따라서 Reasonix의 주장은 "캐시라는 새로운 발명"이 아니라 "캐시를 깨는 기능 확장을 얼마나 거부하거나 뒤로 밀 수 있느냐"에 가깝습니다.
보안 반응도 중요합니다. Reasonix는 DeepSeek API 키를 사용하고, 코딩 에이전트 특성상 프로젝트 파일, 오류 로그, 명령 출력, 설계 메모가 모델 호출에 들어갈 수 있습니다. HN에서는 개인 오픈소스 작업이라면 큰 문제가 아니라고 보는 의견과, 기업 비밀 코드나 사용자 개인정보가 섞인 저장소라면 위험하다는 의견이 나뉘었습니다. 이 논쟁은 특정 국가나 특정 회사에만 국한되지 않습니다. 코딩 에이전트는 어떤 provider를 쓰든 로컬 개발 환경의 민감한 컨텍스트를 외부 모델 호출로 보낼 수 있기 때문에, 비용 절감보다 데이터 경계가 먼저인 팀도 많습니다.
개발팀이 읽어야 할 실무 신호
첫째, 에이전트 비용을 측정할 때 output tokens만 보지 말아야 합니다. 코딩 에이전트는 파일 읽기와 도구 결과 때문에 input tokens가 압도적으로 커질 수 있습니다. 장시간 세션에서 input cache hit tokens, cache miss tokens, output tokens를 분리해 봐야 합니다. Reasonix 사례의 핵심도 output이 아니라 435M input 중 대부분이 cached였다는 데 있습니다.
둘째, 하네스 선택 기준에 prompt stability를 넣어야 합니다. 팀이 자체 에이전트를 만들거나 기존 오픈소스 하네스를 커스터마이즈한다면, system prompt에 변하는 값을 넣는지, tool schema 순서가 결정적인지, compaction이 history를 rewrite하는지, subagent나 mode switch가 tool list를 앞쪽에서 바꾸는지 확인해야 합니다. 이 항목들은 모델 품질 평가표에는 잘 보이지 않지만, 월말 청구서에는 보입니다.
셋째, "저가 모델 + 높은 캐시 적중률"이 항상 "좋은 개발 경험"을 뜻하지는 않습니다. 캐시를 지키기 위해 context pruning이나 compaction을 보수적으로 하면 모델이 너무 많은 오래된 맥락을 보거나, 반대로 필요한 세부 정보를 잃을 수 있습니다. Reasonix는 flash-first, /pro one-shot, failure-signal auto-escalation 같은 비용 제어 장치를 설명하지만, 실제 품질은 작업 유형별로 봐야 합니다. 프론트엔드 단순 수정, 문서 정리, 테스트 보강, 대규모 리팩터링, 보안 패치가 모두 같은 비용/품질 곡선을 갖지는 않습니다.
넷째, 기업 환경에서는 provider와 데이터 정책이 비용보다 앞설 수 있습니다. DeepSeek API를 쓸 수 없는 조직도 있고, 외부 API 자체가 금지된 저장소도 있습니다. 이 경우 Reasonix의 직접 채택보다 중요한 것은 원리입니다. 온프레미스 모델, 사내 gateway, VPC inference, self-hosted endpoint를 쓰더라도 cache-friendly harness 원칙은 그대로 적용될 수 있습니다. 실제로 HN 댓글에서도 self-hosted/private DeepSeek endpoint나 OpenRouter 경유 시 cache hit 이점이 유지되는지 묻는 질문이 나왔습니다.
시장 관점: 모델보다 하네스가 싸움을 만든다
지난 몇 달의 코딩 에이전트 뉴스는 주로 모델 성능, IDE 통합, 원격 제어, 브라우저 실행, 보안 권한, 평가 벤치마크에 집중됐습니다. Reasonix는 조금 다른 방향의 신호입니다. 모델이 충분히 좋아지고 가격 차이가 커지면, 에이전트 시장의 차별화는 "모델을 호출한다"가 아니라 "같은 모델을 덜 낭비하면서 오래 굴린다"로 이동합니다.
이 변화는 클라우드 인프라에서 익숙한 패턴입니다. 데이터베이스 쿼리가 느리면 엔진을 바꾸기 전에 인덱스와 쿼리 플랜을 봅니다. 컨테이너 빌드가 느리면 CPU만 늘리기보다 캐시 레이어 순서를 봅니다. LLM 에이전트도 비슷한 단계로 들어가고 있습니다. 더 큰 모델, 더 긴 컨텍스트, 더 많은 도구가 항상 정답이 아니라, 반복되는 prefix를 얼마나 안정적으로 보존하느냐가 제품 경험과 비용을 동시에 좌우합니다.
Reasonix가 장기적으로 Claude Code, Codex, Cursor 같은 대형 제품의 대체재가 될지는 아직 별개의 질문입니다. 독립 프로젝트는 릴리스 속도가 빠른 만큼 안정성, 보안 검토, 엔터프라이즈 지원, 데이터 처리 약관, 장기 유지보수에서 검증할 것이 많습니다. 하지만 이 프로젝트가 던진 질문은 오래 남을 가능성이 큽니다. 코딩 에이전트를 하루 종일 켜 두는 시대에는, "얼마나 똑똑한가"만큼 "얼마나 같은 prefix를 유지하는가"가 중요해집니다.
지금 개발팀이 가져갈 결론은 간단합니다. 새 코딩 에이전트를 평가할 때 모델 이름과 데모 영상만 보지 말고, 세션 telemetry에 cache hit/miss가 보이는지, 긴 작업에서 비용이 어떻게 누적되는지, compaction과 tool schema 직렬화가 결정적인지 확인해야 합니다. Reasonix의 99.82%라는 숫자는 검증이 필요한 프로젝트 주장입니다. 그러나 그 숫자가 가리키는 방향, 즉 코딩 에이전트의 비용표가 모델 가격표 바깥에서 다시 쓰이고 있다는 신호는 무시하기 어렵습니다.