1,000개 데스크톱 과제, 컴퓨터 사용 에이전트의 검증 공장
OpenComputer는 컴퓨터 사용 에이전트 평가를 LLM 심판이 아니라 앱 상태 검증기와 재현 가능한 데스크톱 과제로 옮깁니다.

- 무슨 일:
OpenComputer가 33개 데스크톱 앱과 1,000개 과제로 컴퓨터 사용 에이전트 평가를 다시 설계했습니다.- 논문은 2026년 5월 19일 arXiv에 공개됐고, GitHub 저장소에는 평가 하네스와 앱별 검증기 구조가 올라왔습니다.
- 핵심 숫자: GPT-5.4도 성공률 68.3%, Claude-Sonnet-4.6은 64.4%에 머물렀습니다.
- 의미: 화면을 보는 에이전트보다 결과를 검증하는 환경이 새 병목으로 떠올랐습니다.
- LLM judge는 120개 샘플 중 95개에서 인간 판정과 일치했지만, hard-coded verifier는 113개까지 올라갔습니다.
- 주의점: 공식 벤치마크는 시각·공간 판단이 필요한 17개 과제를 제외했습니다.
컴퓨터 사용 에이전트의 데모는 점점 그럴듯해지고 있습니다. 브라우저를 열고, 파일을 옮기고, 스프레드시트를 수정하고, IDE에서 코드를 바꾸는 장면은 이제 낯설지 않습니다. 문제는 그 다음입니다. 에이전트가 정말 과제를 끝냈는지 누가, 어떻게, 얼마나 재현 가능하게 확인할 수 있을까요?
5월 19일 arXiv에 올라온 OpenComputer 논문은 이 질문을 정면으로 다룹니다. Yale NLP Lab, University of Pennsylvania, University of North Carolina at Chapel Hill 연구진은 OpenComputer: Verifiable Software Worlds for Computer-Use Agents에서 컴퓨터 사용 에이전트를 위한 검증형 소프트웨어 월드를 제안했습니다. 핵심은 단순합니다. 에이전트가 화면상으로 그럴듯한 결과를 만들었는지 LLM에게 묻지 말고, 실제 애플리케이션 상태를 읽는 프로그램 검증기로 확인하자는 것입니다.
이 접근은 작은 구현 차이가 아니라 연구 인프라의 방향 전환에 가깝습니다. 지금까지 GUI 에이전트 평가는 화면 캡처, 행동 로그, 사람이 만든 과제, LLM-as-judge에 많이 의존했습니다. 그러나 데스크톱 업무의 성공 여부는 픽셀 위에만 남지 않습니다. 파일 내용, 저장된 설정, SQLite 프로필 DB, 문서 메타데이터, 브라우저 기록, 플러그인 상태, 터미널 로그, 프로젝트 구조처럼 화면 밖 상태에 숨어 있는 경우가 많습니다. OpenComputer는 이 숨은 상태를 평가의 중심으로 끌어옵니다.
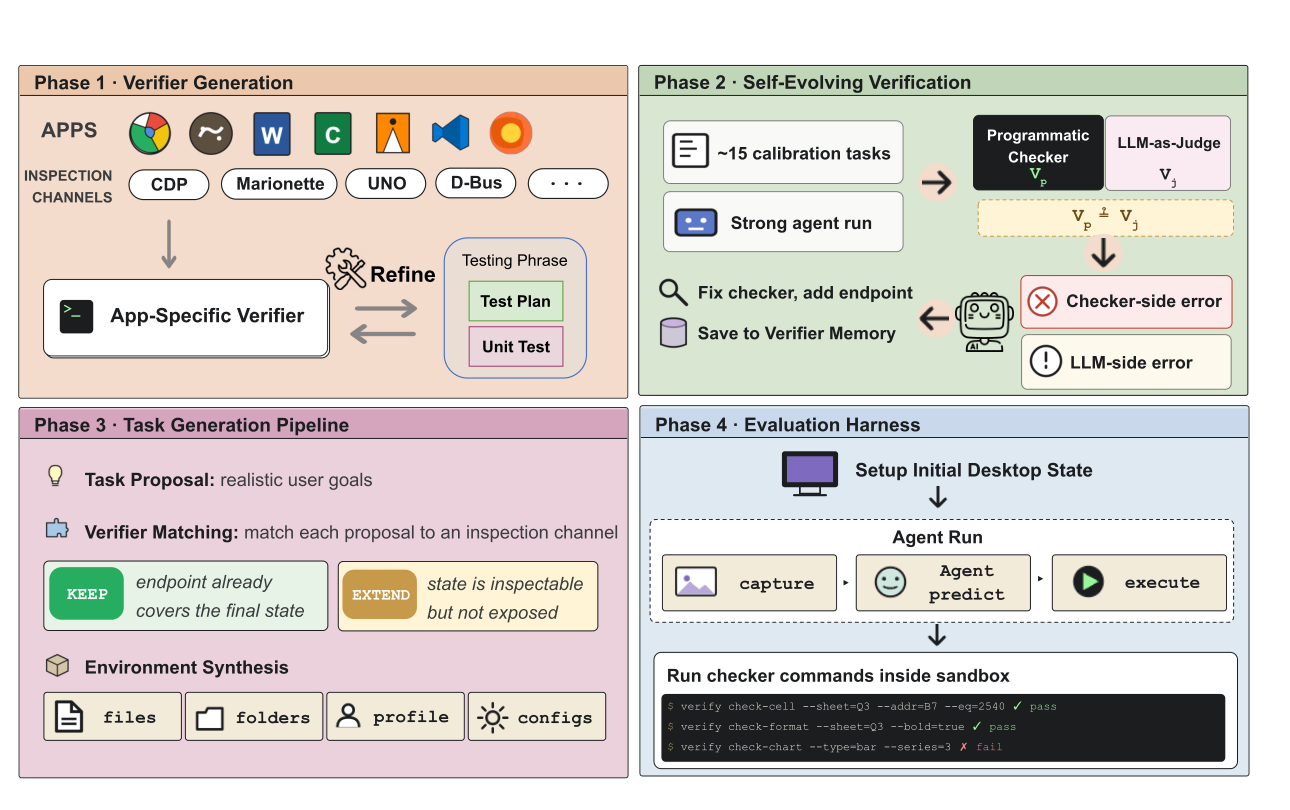
위 그림은 논문이 제시한 전체 파이프라인입니다. OpenComputer는 네 단계를 묶습니다. 먼저 애플리케이션별 verifier endpoint를 만듭니다. Chrome이나 Brave는 CDP, Firefox는 Marionette, LibreOffice 계열은 UNO, VS Code나 Slack 같은 Electron 앱은 CDP, 일부 앱은 D-Bus, SQLite, 파일 파싱, AT-SPI 같은 안정적인 검사 채널을 씁니다. 그 다음 calibration task로 실제 에이전트 실행을 돌리고, 프로그램 검증기와 LLM 평가자의 불일치를 분석해 checker나 endpoint를 고칩니다. 마지막으로 검증 가능한 과제를 합성하고, 에이전트 실행 후 sandbox 안에서 checker command를 실행해 reward를 계산합니다.
33개 앱과 1,000개 과제가 말하는 것
OpenComputer의 공개 버전은 33개 데스크톱 애플리케이션과 1,000개 최종 과제를 포함합니다. 논문 표 1에 따르면 앱별 verifier endpoint는 평균 17.7개, 과제당 평균 check는 6.9개, 과제당 seed file은 1.3개입니다. 브라우저, 오피스 도구, 크리에이티브 소프트웨어, 개발 환경, 파일 관리자, 커뮤니케이션 앱을 모두 포함한다는 점이 중요합니다.
이 숫자는 "과제가 많다"는 뜻만은 아닙니다. 데스크톱 에이전트 평가에서 과제 수를 늘리려면 초기 상태를 만들어야 합니다. 스프레드시트에는 실제처럼 보이는 데이터가 있어야 하고, 문서에는 구조가 있어야 하며, 브라우저 프로필에는 기록이나 북마크가 있을 수 있습니다. 파일 관리자 과제는 폴더 구조와 파일명을 준비해야 하고, 개발 환경 과제는 프로젝트 파일과 설정을 맞춰야 합니다. 여기에 채점 로직까지 붙어야 합니다.
OpenComputer가 흥미로운 이유는 이 과정을 "검증 가능한 상태"를 기준으로 역설계한다는 데 있습니다. 먼저 사용자의 현실적인 목표를 만들고, 너무 단순하거나 선형적인 과제는 걸러냅니다. 그 다음 해당 목표가 기존 verifier endpoint로 확인 가능한지 봅니다. 확인 가능하면 과제로 유지하고, 상태는 검사 가능하지만 endpoint가 없다면 verifier를 확장합니다. 마지막으로 필요한 파일, 폴더, 프로필, 설정을 생성해 task.json과 환경 초기화 절차로 포장합니다.
이 방식은 에이전트 벤치마크를 사람이 손으로 쓰는 문제집에서, 실행 가능한 환경 공급망으로 바꿉니다. 앞으로 컴퓨터 사용 에이전트가 강화학습이나 rejection sampling으로 좋아진다면, 중요한 데이터는 "정답 문장"이 아니라 성공과 실패를 기계적으로 판정할 수 있는 software world가 될 가능성이 큽니다.
GPT-5.4도 완주율은 68.3%
논문의 가장 눈에 띄는 표는 모델별 성능 비교입니다. OpenComputer에서 GPT-5.4는 68.3% 성공률과 88.4% 평균 reward를 기록했습니다. Claude-Sonnet-4.6은 64.4%, Kimi-K2.6은 58.8%입니다. GPT-5.4가 가장 높지만, 여전히 약 3분의 1 과제를 완전히 끝내지 못했다는 뜻입니다.
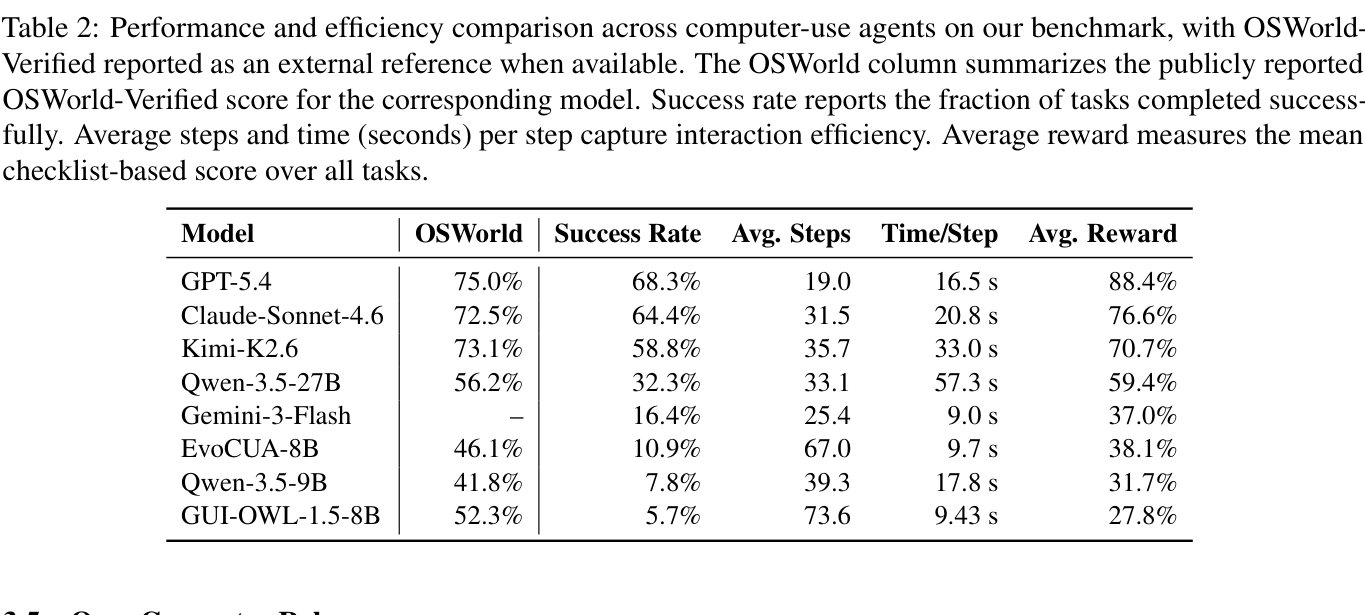
여기서 평균 reward와 성공률을 구분해야 합니다. 평균 reward는 체크리스트 중 몇 개를 통과했는지 보는 부분 점수입니다. 성공률은 필요한 기준을 모두 만족한 과제 비율입니다. GPT-5.4의 평균 reward 88.4%와 성공률 68.3% 사이의 간격은 현재 프런티어 에이전트의 상태를 잘 보여줍니다. 많은 과제에서 상당히 가까이 가지만, 마지막 저장, 정확한 셀 위치, 숨은 설정, 잘못 선택된 객체, 파일 메타데이터 같은 작은 조건에서 실패합니다.
오픈소스 모델의 하락은 더 큽니다. GUI-OWL-1.5-8B는 OSWorld-Verified에서 52.3%로 보고됐지만 OpenComputer에서는 5.7%에 그쳤습니다. EvoCUA-8B도 OSWorld 46.1%에서 OpenComputer 10.9%로 떨어졌습니다. 논문은 이 차이를 기존 데스크톱 벤치마크 점수가 더 넓고 이질적인 소프트웨어 환경으로 잘 전이되지 않는 신호로 해석합니다.
이 대목은 AI 제품 팀에게 불편하지만 실용적인 메시지를 줍니다. 컴퓨터 사용 에이전트의 데모 성공은 실제 업무 성공과 다를 수 있습니다. 특히 "화면에서 볼 때 맞아 보이는 결과"와 "앱 내부 상태가 정확한 결과" 사이에는 간격이 있습니다. 자동화 제품이 고객 업무에 들어가려면 모델 선택보다 검증 가능한 완료 조건을 먼저 정의해야 할 수 있습니다.
LLM 심판은 왜 부족한가
LLM-as-judge는 편합니다. 에이전트의 행동 로그와 마지막 스크린샷을 보여주고, 과제를 달성했는지 판단하게 만들면 됩니다. OpenComputer 연구진도 완전히 배제하지는 않습니다. 합성 과정의 진단이나 자동 검사로 표현하기 어려운 일부 시각 기준에는 LLM judge가 보조적으로 필요합니다.
하지만 논문이 보여준 격차는 큽니다. 120개 과제의 완료 trajectory를 사람에게 판정하게 한 뒤, LLM judge와 hard-coded verifier를 비교했습니다. task-level에서 hard-coded verifier는 120개 중 113개가 인간 판정과 일치했습니다. LLM judge는 95개였습니다. checklist-level agreement도 hard-coded verifier 97.3%, LLM judge 92.2%로 차이가 났습니다.
이 차이는 데스크톱 UI의 본질에서 나옵니다. 스프레드시트에서 두 토큰을 한 셀에 넣었는지, 옆 셀에 나눠 넣었는지는 화면만 보면 놓치기 쉽습니다. 접힌 패널 안의 필드가 바뀌었는지, Blender나 개발 도구의 중간 산출물이 남았는지, 파일 포맷 내부의 객체 속성이 맞는지는 마지막 이미지 한 장으로 판단하기 어렵습니다. 반면 프로그램 검증기는 저장된 문서, DB, 설정, 로그, 앱 내부 API를 직접 읽습니다.
여기서 OpenComputer의 메시지는 "LLM judge를 쓰지 말라"가 아닙니다. 더 정확히는 "LLM judge만으로 컴퓨터 사용 에이전트를 평가한다고 착각하지 말라"입니다. 모델이 화면을 보고 행동하는 시대에는 평가자도 화면 밖을 볼 수 있어야 합니다.
자기 개선하는 검증기라는 조심스러운 아이디어
OpenComputer의 self-evolving verification layer도 주목할 만합니다. 연구진은 각 앱에 대해 약 15개의 쉬운 또는 중간 난도 calibration task를 만들고, 강한 에이전트를 실제 sandbox에서 실행합니다. 그 결과 trajectory와 최종 상태를 고정한 뒤, LLM evaluator의 기준별 판정과 프로그램 verifier의 판정을 비교합니다.
불일치가 생기면 두 가지 가능성이 있습니다. 에이전트가 실제로 실패했거나, verifier가 잘못 검사했거나입니다. OpenComputer는 verifier-side 오류로 분류된 경우에 한해 checker code, endpoint 구현, verifier 문서를 수정합니다. 중요한 제한은 있습니다. 이미 기록된 trajectory, sandbox state, task objective, expected outcome은 바꾸지 않습니다. 검증 계층만 고칩니다.
실험에서는 450개 calibration 실행 중 159개에서 불일치가 있었고, 이 중 76건이 checker-side 오류로 분류됐습니다. self-evolution 절차는 76건 중 68건을 고쳐 89.4% repair rate를 기록했습니다. 47건은 한 번의 반복으로, 15건은 두 번, 6건은 세 번 만에 고쳐졌습니다. 인간-checker agreement는 85.2%에서 94.1%로 올라갔습니다.
이 구조는 에이전트 평가 인프라에서도 "AI가 만든 것을 AI가 고친다"는 흐름이 들어오고 있음을 보여줍니다. 다만 논문은 이를 무제한 자동 수정으로 제시하지 않습니다. 고정된 실행 결과 위에서 verifier의 가정이 틀렸는지 확인하고, 제한된 범위의 checker를 고치는 디버깅 루프로 다룹니다. 자동화의 대상이 모델 출력이 아니라 평가 도구라는 점이 더 현실적입니다.
GUI와 CLI의 다른 병목
논문은 GUI 에이전트와 CLI 에이전트도 비교합니다. OpenComputer는 최종 앱 상태를 검증하므로, 같은 목표를 GUI 클릭으로 달성하든 CLI나 스크립트로 달성하든 평가할 수 있습니다. 연구진은 CLI로도 풀 수 있는 14개 앱, 343개 과제를 골라 비교했습니다.
결과는 미묘합니다. GUI GPT-5.4는 75.2%, GUI Claude Sonnet 4.6은 73.0% 성공률을 보였습니다. Claude Code v2.1.129를 사용한 CLI agent는 67.2%였습니다. 하지만 시간은 반대입니다. CLI agent는 과제당 평균 141초, GUI GPT-5.4는 288초, GUI Claude는 622초였습니다.
즉 CLI는 빠르고 직접적입니다. 파일을 조작하고, 스크립트를 실행하고, 앱별 도구를 호출할 수 있습니다. 그러나 시각적 grounding이 필요한 데스크톱 업무에서는 GUI가 여전히 더 높은 성공률을 보입니다. 이 결과는 실무 설계에도 힌트를 줍니다. 에이전트를 "화면 조작형" 또는 "터미널형"으로 나누기보다, 최종 상태 검증기를 공유하고 여러 action space를 허용하는 구조가 더 강할 수 있습니다.
왜 개발자에게 중요한가
OpenComputer는 당장 제품으로 쓰는 앱보다 연구 인프라에 가깝습니다. GitHub 저장소도 초기 상태이며, 확인 시점 기준 스타 수는 15개 수준입니다. 그러나 방향성은 중요합니다. 컴퓨터 사용 에이전트의 경쟁은 모델 API 성능만으로 끝나지 않습니다. 에이전트가 조작할 수 있는 환경, 그 환경을 초기화하는 절차, 결과를 검증하는 endpoint, 실패 trajectory를 수집하는 하네스가 함께 필요합니다.
개발자와 AI 팀에게는 세 가지 실무적 함의가 있습니다.
첫째, 업무 자동화 과제를 만들 때 성공 조건을 자연어로만 두면 안 됩니다. "보고서를 정리해 줘"보다 "이 파일의 특정 sheet에 값이 들어갔는지", "메일 초안이 어떤 필드와 첨부파일을 갖는지", "설정 DB에서 플래그가 어떤 상태인지"를 검사할 수 있어야 합니다.
둘째, 에이전트 평가는 최종 스크린샷 리뷰를 넘어야 합니다. 사람이 볼 수 있는 결과와 시스템이 저장한 상태가 다르면, 실제 업무에서는 저장된 상태가 더 중요할 때가 많습니다. OpenComputer가 강조한 CDP, D-Bus, UNO, SQLite, 파일 파싱 같은 검사 채널은 제품 QA에도 그대로 연결됩니다.
셋째, 강화학습이나 SFT 데이터 수집에서 reward의 품질이 더 중요해질 수 있습니다. OpenComputer는 성공 trajectory와 부분 성공 trajectory를 모아 SFT, RL, rejection sampling에 쓸 수 있다고 설명합니다. 이는 컴퓨터 사용 에이전트의 학습 데이터가 단순한 화면-행동 로그가 아니라, 검증 가능한 상태 변화와 묶여야 한다는 뜻입니다.
남은 한계
논문도 한계를 분명히 인정합니다. 모든 데스크톱 과제를 hard-coded verifier로 표현할 수는 없습니다. Draw.io에서 화살표가 두 박스를 시각적·의미적으로 제대로 연결했는지, 디자인 도구에서 요소가 정확히 정렬됐는지 같은 문제는 파일 포맷이나 앱 API만으로 확정하기 어렵습니다. 연구진은 hard-coded checker로 완전히 검증할 수 없는 성공 기준이 포함된 17개 생성 과제를 공식 벤치마크에서 제외했습니다.
이 결정은 오히려 신뢰도를 높입니다. OpenComputer가 "모든 것을 프로그램으로 채점한다"고 과장하지 않기 때문입니다. 앞으로는 실행 가능한 상태 검사와 시각 판단을 결합한 hybrid verification이 필요할 것입니다. 다만 그 경우에도 LLM judge는 보조 채널이어야 하고, 어떤 기준이 프로그램으로 검증됐고 어떤 기준이 시각 판단인지 분리해 기록해야 합니다.
OpenComputer의 진짜 신호는 하나입니다. 컴퓨터 사용 에이전트의 다음 병목은 더 화려한 클릭 데모가 아니라, 재현 가능한 환경과 검증 가능한 완료 조건입니다. 모델은 점점 더 많은 일을 할 수 있게 됩니다. 하지만 AI 팀이 실제 업무 자동화를 배포하려면 "했는가"를 물을 수 있는 기계적 언어를 먼저 만들어야 합니다. OpenComputer는 그 언어를 데스크톱 앱 세계로 확장하려는 초기 설계도입니다.