OpenAI도 붙인 SynthID, AI 이미지 신뢰의 새 최소선
OpenAI와 Google의 C2PA, SynthID 확장은 AI 이미지 출처 검증을 제품 기능이 아니라 웹 신뢰 인프라로 끌어올립니다.

- 무슨 일: OpenAI가
C2PA서명, GoogleSynthID워터마크, 공개 검증 도구를 한 묶음으로 발표했습니다.- Google은 I/O에서 SynthID 검증을 Search와 Chrome으로 넓히고 OpenAI, Kakao, ElevenLabs 채택을 함께 공개했습니다.
- 의미: AI 이미지 신뢰가 모델 성능 문제가 아니라 브라우저, 검색, API, 메타데이터 표준의 인프라 문제가 됐습니다.
- 주의점: 신호가 없다고 AI 생성물이 아니라고 볼 수는 없습니다. 메타데이터는 지워지고, 워터마크도 판정이 아니라 증거입니다.
OpenAI가 AI 생성 이미지에 붙는 출처 신호를 한 단계 더 두껍게 만들었습니다. OpenAI는 2026년 5월 19일 C2PA Content Credentials, Google DeepMind의 SynthID 워터마크, 그리고 공개 검증 도구 프리뷰를 함께 발표했습니다. 겉으로 보면 "AI 이미지에 워터마크를 붙인다"는 익숙한 이야기처럼 보입니다. 하지만 이번 변화는 조금 다릅니다. OpenAI만의 라벨이 아니라 Google Search, Chrome, Gemini 앱, C2PA 표준, Kakao와 ElevenLabs 같은 외부 채택자가 같은 신뢰 계층으로 묶이기 시작했기 때문입니다.
AI 이미지 생성이 제품 기능이었을 때 provenance는 부가 기능이었습니다. 이미지 아래에 작은 워터마크를 넣거나, 다운로드 파일의 메타데이터에 생성 정보를 적는 정도였습니다. 이제는 그 정도로 부족합니다. 이미지는 저장되고, 캡처되고, 리사이즈되고, 메신저와 소셜 네트워크를 지나고, 기사와 광고 소재와 쇼핑 이미지로 재배포됩니다. 생성 순간의 라벨이 최종 소비자에게 도착하지 않으면 신뢰 체계는 끊어집니다. 그래서 OpenAI가 이번에 꺼낸 핵심은 하나의 표식이 아니라 "서명된 메타데이터와 보이지 않는 워터마크를 겹치고, 누구나 확인할 수 있는 표면을 제공한다"는 조합입니다.
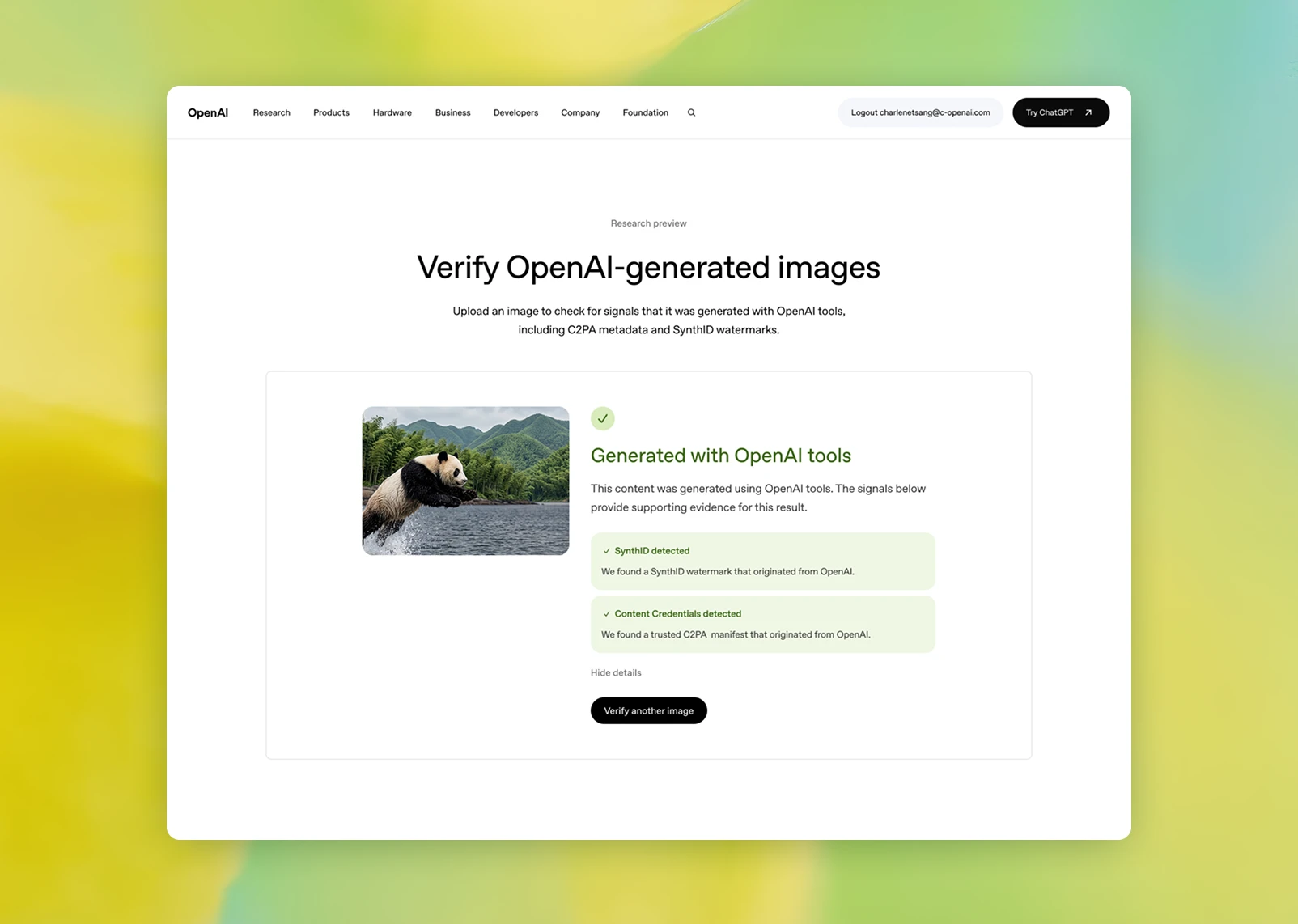
OpenAI가 겹친 두 신호
OpenAI 발표의 첫 축은 C2PA입니다. C2PA는 Coalition for Content Provenance and Authenticity의 약자로, 콘텐츠가 어디서 왔고 어떤 도구로 만들어졌거나 편집됐는지 파일 메타데이터와 암호 서명으로 전달하려는 표준입니다. OpenAI는 이미 2024년부터 DALL-E 3 이미지에 Content Credentials를 붙이기 시작했고, 이후 ImageGen과 Sora에도 확장했다고 설명합니다. 이번에는 OpenAI가 C2PA Conforming Generator Product가 됐다는 점을 강조했습니다. 플랫폼이 OpenAI가 붙인 provenance 정보를 읽고, 보존하고, 다음 단계로 전달할 수 있는 더 신뢰 가능한 방식에 들어섰다는 뜻입니다.
두 번째 축은 Google DeepMind의 SynthID입니다. OpenAI는 ChatGPT, Codex, OpenAI API를 통해 생성되는 이미지부터 SynthID를 적용한다고 밝혔습니다. C2PA가 "서명된 설명서"에 가깝다면 SynthID는 이미지 내부에 숨은 신호에 가깝습니다. 사람이 눈으로 보기 어렵지만 탐지기는 감지할 수 있는 형태의 워터마크입니다. OpenAI가 이 둘을 같이 쓰는 이유는 분명합니다. 메타데이터는 많은 정보를 담을 수 있지만 업로드, 다운로드, 파일 포맷 변환, 리사이즈, 스크린샷 과정에서 사라질 수 있습니다. 워터마크는 설명력이 약하지만 변형 뒤에도 남을 가능성이 더 높습니다.
세 번째 축은 검증 도구입니다. OpenAI는 사용자가 이미지를 업로드해 ChatGPT, OpenAI API, Codex에서 만들어진 이미지인지 확인할 수 있는 공개 도구를 프리뷰로 제공한다고 밝혔습니다. 도구는 Content Credentials와 SynthID 신호를 함께 확인합니다. 중요한 단서도 있습니다. OpenAI는 신호가 없을 때 "OpenAI 생성물이 아니다"라고 단정하지 않습니다. 신호는 사라질 수 있고, 출시 시점의 도구는 OpenAI 생성물만 대상으로 합니다. 이 신중함이 오히려 이번 발표의 핵심입니다. provenance는 마법 같은 진실 판정기가 아니라, 여러 신호를 모아 신뢰도를 높이는 증거 체계입니다.
| 신호 | 강점 | 깨지는 지점 | 개발자 의미 |
|---|---|---|---|
| C2PA | 도구, 발행자, 편집 이력을 풍부하게 설명합니다. | 플랫폼 업로드나 이미지 변환 과정에서 메타데이터가 제거될 수 있습니다. | 원본 파일 보관, 서명 검증, provenance 로그가 중요해집니다. |
| SynthID | 리사이즈, 캡처 같은 변형 뒤에도 신호가 남을 가능성을 노립니다. | 신호만으로 생성 맥락 전체를 설명하지는 못합니다. | 탐지 결과를 moderation, 리뷰, 감사 흐름에 연결해야 합니다. |
| 검증 UI | 일반 사용자와 운영자가 신호를 읽을 수 있는 진입점입니다. | 초기에는 특정 생성사나 콘텐츠 유형으로 범위가 제한됩니다. | "검출 안 됨"을 "안전함"으로 처리하지 않는 UX가 필요합니다. |
Google 발표에서 더 커진 이야기
하루 뒤 Google은 I/O 2026 발표 정리에서 SynthID를 별도 항목으로 다뤘습니다. Google은 SynthID가 3년 전 시작된 기술이며, Gemini 앱의 이미지, 영상, 오디오 검증에 이미 전 세계 5,000만 회 사용됐다고 밝혔습니다. 또 이 검증 기능을 Search에는 바로, Chrome에는 앞으로 몇 주 안에 확대한다고 설명했습니다. 사용자는 Lens, AI Mode, Circle to Search, Gemini in Chrome 같은 표면에서 이미지의 출처를 물어볼 수 있게 됩니다.
여기서 중요한 변화는 provenance가 생성 앱 내부에 머물지 않는다는 점입니다. 지금까지 AI 이미지 라벨은 대체로 생성 도구 안에서만 보였습니다. ChatGPT에서 만든 이미지, Gemini에서 만든 이미지, 특정 디자인 도구에서 만든 이미지를 그 도구 안에서 다룰 때는 어느 정도 출처를 추적할 수 있었습니다. 하지만 실제 웹은 그렇게 움직이지 않습니다. 이미지는 검색 결과에 나타나고, 브라우저 탭에서 열리고, 메신저로 전송되고, 커머스 페이지와 뉴스 기사에 삽입됩니다. Google이 Search와 Chrome을 검증 표면으로 삼는다는 것은 provenance를 "생성 기능"이 아니라 "웹 탐색 기능"으로 보겠다는 선언에 가깝습니다.
Google은 C2PA Content Credentials 검증도 Gemini 앱에서 시작하고, Search와 Chrome으로 확대하겠다고 밝혔습니다. 그리고 OpenAI, Kakao, ElevenLabs가 SynthID를 더 많은 AI 생성 콘텐츠에 적용한다고 언급했습니다. 이 부분이 시장적으로 큽니다. OpenAI와 Google은 AI 생성 모델 시장에서 경쟁자입니다. 그런데 생성 콘텐츠의 출처 확인에서는 같은 워터마크 기술과 같은 검증 표면을 공유하는 방향으로 움직이고 있습니다. 경쟁은 모델과 제품 경험에서 계속되지만, 최소한의 provenance 신호는 상호 운용되는 공공재에 가까워지고 있습니다.
카카오가 붙은 이유
Kakao는 2026년 5월 20일 Google DeepMind와 협력해 자체 AI 모델 Kanana에 SynthID를 적용한다고 발표했습니다. Kakao 설명에 따르면 Kanana-Kollage 이미지 모델과 Kanana-Kinema 영상 모델에 하반기부터 SynthID를 적용하고, KakaoTalk의 Kanana Template 기능에도 먼저 적용할 계획입니다. Kakao는 자신들이 아시아 최초의 SynthID 통합 사례라고 밝혔습니다.
한국 독자에게 이 대목은 단순한 해외 기술 채택보다 더 직접적입니다. 한국은 2026년에 AI 기본법 시행과 AI 생성물 표시 제도 도입을 앞두고 있습니다. Kakao는 이 맥락을 명시하면서, 법적 의무를 넘어 보이지 않는 워터마킹을 적용해 투명성과 신뢰성을 강화하겠다고 설명했습니다. 즉 SynthID는 글로벌 빅테크의 정책 도구이면서, 동시에 지역 플랫폼의 규제 대응 도구가 되고 있습니다.
개발팀 관점에서는 여기서 중요한 질문이 나옵니다. AI 생성물을 표시해야 하는 규제 환경에서 단순히 UI에 "AI로 생성됨" 문구를 넣는 것으로 충분할까요. 사용자가 이미지를 저장하고, 편집하고, 다시 업로드하면 UI 라벨은 사라집니다. 반대로 파일 메타데이터와 워터마크, 생성 로그, 검증 API가 함께 설계되어 있으면 나중에 감사와 분쟁 대응이 가능합니다. Kakao 사례는 AI 생성물 표시가 프론트엔드 뱃지 문제가 아니라 제품 인프라 문제라는 점을 잘 보여줍니다.
개발자가 봐야 할 실무 변화
첫째, 이미지 생성 API를 쓰는 제품은 "생성"과 "게시"를 분리해서 기록해야 합니다. 이미지가 모델에서 나오는 순간에는 출처 신호가 붙어 있을 수 있습니다. 그러나 서비스 안에서 리사이즈하고, CDN에 올리고, 포맷을 바꾸고, 썸네일을 만들고, 사용자가 다시 편집하면 신호가 유지되는지 달라집니다. C2PA는 특히 이 경로에 취약할 수 있습니다. 파일 처리 파이프라인이 메타데이터를 제거하지 않는지, CDN이 어떤 헤더와 파일 변환을 수행하는지, 원본과 변환본을 어떻게 연결할지 확인해야 합니다.
둘째, moderation은 "AI 여부" 하나로 끝나지 않습니다. 어떤 이미지는 AI 생성물이지만 허용될 수 있고, 어떤 이미지는 실제 사진이지만 조작된 맥락으로 악용될 수 있습니다. provenance 신호는 하나의 feature입니다. 모델 출력 검토, 사용자 신고, perceptual hash, EXIF, C2PA 검증, SynthID 검출, 계정 신뢰도, 게시 맥락이 함께 들어가야 합니다. OpenAI가 검증 도구에서 신호 부재를 확정 판정으로 다루지 않는 것도 같은 이유입니다.
셋째, "검출 안 됨" UX를 조심해야 합니다. 사용자가 이미지를 업로드했는데 C2PA도 SynthID도 감지되지 않았다고 합시다. 이때 UI가 "AI 생성 아님"이라고 말하면 위험합니다. 신호가 원래 없었을 수도 있고, 변환 과정에서 사라졌을 수도 있고, 지원하지 않는 생성기에서 만들었을 수도 있습니다. 더 정확한 표현은 "지원되는 provenance 신호를 찾지 못했습니다"입니다. 별 차이 없어 보이지만 법무, 뉴스룸, 마켓플레이스, 선거 콘텐츠 moderation에서는 큰 차이입니다.
넷째, API 설계는 원본 증거를 보존해야 합니다. 사용자가 이미지를 올리면 파일 자체, 검증 시점, 검증 도구 버전, 감지된 C2PA manifest, SynthID 결과, 해시, 변환 여부를 함께 저장해야 나중에 재현할 수 있습니다. 특히 기업 고객에게 "이 이미지는 AI 생성물이었는가"라는 질문은 실시간 판정만으로 끝나지 않습니다. 감사, 이의 제기, 법적 보존, 파트너 API 연동까지 이어집니다.
C2PA에 대한 불편한 반론
이번 발표를 곧장 "진위 판정 문제가 해결됐다"로 읽으면 안 됩니다. 2026년 4월 말 arXiv에는 provenance의 한계를 짚는 연구가 연달아 나왔습니다. GPT-Image-2 in the Wild 논문은 GPT-image-2 출시 첫 주 Twitter/X에서 수집한 10,217개의 자기 보고 AI 이미지 데이터셋을 분석했습니다. 이 논문의 중요한 부정적 결과는 Twitter/X CDN 업로드 과정에서 C2PA Content Credentials가 체계적으로 제거되어, 소셜 미디어에서 가져온 AI 이미지의 암호학적 provenance 검증이 사실상 불가능해졌다는 점입니다.
또 다른 C2PA 분석 논문은 C2PA가 유망한 아이디어이지만 현재 사양을 고위험 영역의 증거로 성급하게 의존해서는 안 된다고 주장합니다. 이 논문은 금융 공시, 저널리즘, 법적 증거 같은 분야에서 C2PA를 과신하면 사용자와 플랫폼, 정책 결정자를 오도할 수 있다고 경고합니다. 이 주장을 그대로 받아들이든 일부만 받아들이든, 개발자가 얻어야 할 교훈은 명확합니다. provenance 표준은 필요하지만 충분하지 않습니다.
OpenAI의 이번 다층 접근은 바로 이 반론에 대한 현실적 답에 가깝습니다. 메타데이터만으로 부족하니 워터마크를 겹칩니다. 워터마크만으로 부족하니 검증 UI를 둡니다. 검증 UI만으로 부족하니 신호 부재를 확정 판정으로 다루지 않습니다. 완벽한 진실 기계는 없고, 대신 서로 다른 실패 모드를 가진 신호를 조합합니다.
AI 미디어 신뢰는 누가 운영하나
이번 뉴스에서 가장 흥미로운 지점은 기술보다 운영 주체입니다. AI 생성물 신뢰 체계는 한 회사가 독점적으로 풀기 어렵습니다. 생성사는 신호를 붙일 수 있습니다. 검색 엔진과 브라우저는 신호를 읽을 수 있습니다. 소셜 플랫폼은 업로드 과정에서 신호를 보존하거나 제거할 수 있습니다. 뉴스룸과 기업은 검증 결과를 업무 흐름에 넣을 수 있습니다. 규제기관은 어떤 표시와 로그가 충분한지 기준을 만들 수 있습니다. 한 곳이라도 끊기면 사용자는 최종 이미지 앞에서 다시 혼자가 됩니다.
그래서 OpenAI와 Google의 이번 교차점은 중요합니다. OpenAI는 가장 널리 쓰이는 생성 이미지 표면 중 하나입니다. Google은 검색과 브라우저라는 발견 표면을 갖고 있습니다. Kakao는 한국과 아시아의 메신저, 콘텐츠, 생활 플랫폼과 연결됩니다. ElevenLabs는 음성 생성 영역의 대표 주자입니다. 이들이 같은 워터마크와 검증 방향을 공유하면, 적어도 일부 AI 생성물은 생성부터 발견까지 이어지는 provenance 경로를 갖게 됩니다.
물론 이것은 아직 "최소선"입니다. 악의적 생성자는 신호를 붙이지 않는 도구를 쓸 수 있습니다. 오픈 모델이나 로컬 모델에서 나온 이미지는 다른 경로를 탑니다. 플랫폼이 메타데이터를 지우면 C2PA는 끊깁니다. 워터마크 검출기는 오탐과 미탐을 관리해야 합니다. 카메라에서 촬영 순간을 서명하는 camera-side provenance와도 연결되어야 합니다. 합성물과 실제 촬영물이 섞인 편집 이미지에서는 어떤 부분이 생성됐고 어떤 부분이 촬영됐는지 더 세밀한 표현이 필요합니다.
그럼에도 이번 발표가 실무적으로 의미 있는 이유는, AI 미디어 신뢰의 기본 설계가 조금씩 제품 요구사항으로 내려오고 있기 때문입니다. 이미지 생성 기능을 붙이는 팀은 이제 모델 API 선택만 보지 않습니다. 생성물이 어디에서 만들어졌는지, 어떤 신호가 붙는지, 리사이즈 후에도 남는지, 사용자에게 어떻게 설명되는지, Search와 Chrome 같은 외부 표면에서 어떻게 읽히는지를 봐야 합니다. 콘텐츠 플랫폼은 업로드 최적화 과정에서 메타데이터를 무심코 제거해도 되는지 다시 물어야 합니다.
앞으로의 기준
앞으로 몇 달 동안 볼 지점은 세 가지입니다. 첫째, OpenAI 검증 도구가 OpenAI 생성물 밖으로 얼마나 빨리 확장되는가입니다. 공개 도구가 특정 생성사 전용이면 유용하지만 제한적입니다. 여러 생성사, 여러 워터마크, 여러 C2PA issuer를 함께 다룰 때 비로소 일반 사용자의 검증 입구가 됩니다.
둘째, Search와 Chrome의 표현 방식입니다. "AI 생성 가능성"을 어떤 문구와 색상, 근거, 불확실성으로 보여줄지가 중요합니다. 너무 강하게 말하면 오판의 위험이 커지고, 너무 약하게 말하면 사용자가 무시합니다. provenance UX는 보안 경고 UX와 닮았습니다. 정확도만큼이나 설명 방식이 중요합니다.
셋째, 플랫폼 보존 정책입니다. 이미지가 이동할 때 C2PA가 얼마나 살아남는지, SynthID 검출이 어떤 변형까지 견디는지, CDN과 편집 도구가 provenance 정보를 어떻게 다루는지에 따라 실제 효과가 달라집니다. 이 부분은 생성사 발표만으로 해결되지 않습니다. 웹 플랫폼, 브라우저, OS, 카메라, 편집 도구, 뉴스룸 CMS가 함께 바뀌어야 합니다.
이번 발표를 과장하면 "AI 이미지 판별 문제 해결"이 됩니다. 하지만 더 정확한 표현은 "AI 이미지 신뢰의 새 최소선"입니다. OpenAI와 Google, Kakao의 움직임은 완벽한 판정기를 만든 것이 아니라, 생성물에 남겨야 할 기본 증거와 그것을 읽는 기본 표면을 정하기 시작했다는 뜻입니다. AI가 만든 이미지를 웹 어디서나 보게 되는 시대에는 이 최소선이 꽤 중요합니다. 신뢰는 모델이 혼자 만들어내는 기능이 아니라, 생성부터 배포, 검색, 검증, 보존까지 이어지는 운영 체계이기 때문입니다.