OpenAI가 Codex에 안전벨트를 채웠다, 에이전트 보안의 새 기준
OpenAI가 GPT-5.5-Cyber와 Codex 안전 운영 지침을 잇달아 공개했습니다. 코딩 에이전트 경쟁이 모델 성능에서 권한, 샌드박스, 감사로그로 이동하고 있습니다.

- 무슨 일: OpenAI가
GPT-5.5-Cyberlimited preview와 Codex 안전 운영 지침을 하루 간격으로 공개했습니다.- 5월 7일은 사이버 방어자를 위한 접근권한 계층, 5월 8일은 Codex를 조직 안에서 통제하는 샌드박스와 로그 체계가 핵심입니다.
- 의미: 코딩 에이전트의 병목이 "모델이 코드를 잘 쓰는가"에서 "어디까지 실행하게 할 것인가"로 이동하고 있습니다.
- 숫자: UK AISI는 GPT-5.5가 expert-level cyber task에서 71.4% pass rate를 기록했다고 평가했습니다.
- 주의점: OpenAI도
GPT-5.5-Cyber가 일반 GPT-5.5보다 항상 더 강한 모델은 아니며, 주로 더 permissive한 접근권한이라고 선을 그었습니다.
OpenAI가 2026년 5월 7일과 8일에 사이버와 코딩 에이전트 관련 발표를 연달아 냈습니다. 하나는 GPT-5.5-Cyber와 Trusted Access for Cyber 확대입니다. 다른 하나는 OpenAI 내부에서 Codex를 어떻게 안전하게 운영하는지 설명한 글입니다. 겉으로 보면 서로 다른 발표처럼 보입니다. 하나는 보안 모델 접근권한이고, 하나는 코딩 에이전트 운영 지침입니다.
하지만 두 글을 이어서 읽으면 같은 이야기를 하고 있습니다. AI 에이전트가 실제 조직에서 일하려면 모델 성능만으로는 부족합니다. 누가 어떤 권한으로 쓰는지, 어떤 시스템에 접근할 수 있는지, 네트워크는 어디까지 열어둘지, 위험한 명령은 언제 멈출지, 나중에 보안팀이 무엇을 확인할 수 있는지가 제품의 일부가 됩니다. OpenAI는 이번 주에 그 방향을 꽤 노골적으로 공개했습니다.
이 변화는 개발자에게도 중요합니다. 2025년의 코딩 에이전트 경쟁은 "Claude Code가 더 잘 고치나", "Codex가 더 오래 일하나", "Cursor 안에서 자연스럽나" 같은 사용감 중심이었습니다. 2026년에는 질문이 더 운영적으로 바뀝니다. 에이전트에게 git, gh, kubectl, 패키지 매니저, 브라우저, 내부 문서, 로그, 클라우드 콘솔을 주면 얼마나 빨라지는지는 이미 많은 팀이 보고 있습니다. 이제 남는 질문은 그 에이전트를 어디까지 믿고 실행시킬 수 있느냐입니다.
GPT-5.5-Cyber는 모델 출시보다 접근권한 뉴스에 가깝습니다
OpenAI의 5월 7일 발표는 제목만 보면 새 사이버 특화 모델 출시처럼 읽힙니다. Scaling Trusted Access for Cyber with GPT-5.5 and GPT-5.5-Cyber입니다. 하지만 글의 핵심은 "더 강한 해킹 모델을 모두에게 공개한다"가 아닙니다. OpenAI는 GPT-5.5-Cyber를 critical infrastructure defenders 대상 limited preview로 배포한다고 설명합니다. 그리고 대부분의 방어자에게는 GPT-5.5 with Trusted Access for Cyber가 출발점이라고 말합니다.
Trusted Access for Cyber는 신원과 신뢰에 기반한 접근권한 체계입니다. 검증된 방어자가 취약점 식별, triage, malware analysis, binary reverse engineering, detection engineering, patch validation 같은 업무를 할 때 classifier-based refusal을 줄입니다. 반대로 credential theft, stealth, persistence, malware deployment, third-party system exploitation처럼 실제 위해 가능성이 큰 요청은 계속 막습니다.
즉 변화의 중심은 모델 가중치가 아니라 policy surface입니다. 같은 기본 역량을 가진 모델이라도 누가, 어떤 목적으로, 어떤 환경에서 쓰는지에 따라 허용되는 작업의 폭이 달라집니다. 보안팀 입장에서는 익숙한 방식입니다. 사내 시스템도 읽기 권한, 배포 권한, production 접근 권한, break-glass 권한을 나눕니다. OpenAI는 사이버 모델 사용에도 비슷한 계층을 붙이고 있습니다.
| 접근 단계 | 무엇이 달라지나 | 주요 용도 |
|---|---|---|
| GPT-5.5 기본 | 일반 목적 safeguard가 적용됩니다. | 개발, 지식 작업, 일반 보안 설명 |
| GPT-5.5 with TAC | 검증된 방어 업무에서 거부가 더 정밀해집니다. | 코드 보안 리뷰, 취약점 triage, 악성코드 분석, 탐지 규칙, 패치 검증 |
| GPT-5.5-Cyber | 더 permissive한 동작을 강한 검증과 계정 통제에 묶습니다. | authorized red teaming, penetration testing, controlled validation |
이 구분이 중요한 이유는 사이버 작업이 이중용도이기 때문입니다. 취약점을 재현하는 PoC는 패치 검증에 필요할 수 있지만, 같은 기술은 공격에도 쓰일 수 있습니다. OpenAI 발표에는 React Server Components 취약점 CVE-2025-55182를 예로 든 비교가 나옵니다. 기본 GPT-5.5는 exploit 작성 요청을 거부하거나 안전한 대안으로 돌립니다. TAC가 붙은 경우에는 authorized environment에서 재현과 문서화를 수행할 수 있습니다. GPT-5.5-Cyber는 더 전문적인 authorized workflow에서 더 공격적인 검증까지 다룰 수 있도록 설계됐습니다.
여기서 흥미로운 점은 OpenAI가 GPT-5.5-Cyber를 성능 우위 모델로만 포장하지 않는다는 점입니다. 발표는 이 preview가 GPT-5.5보다 모든 cyber evaluation에서 앞서기 위한 것이 아니라, 보안 관련 작업에서 더 permissive하게 행동하도록 훈련된 접근권한 실험에 가깝다고 설명합니다. 모델 경쟁의 언어가 "더 똑똑하다"에서 "더 적절한 사람에게 더 적절한 마찰을 준다"로 바뀐 셈입니다.
AISI 평가는 왜 OpenAI가 접근권한을 강조하는지 보여줍니다
OpenAI 발표의 배경에는 UK AISI의 4월 30일 평가가 있습니다. AISI는 GPT-5.5가 자신들이 테스트한 cyber task에서 가장 강한 모델 중 하나이며, 다단계 사이버 공격 시뮬레이션을 end-to-end로 해결한 두 번째 모델이라고 썼습니다. 이 평가는 단순 벤치마크 표가 아니라, 왜 접근권한과 통제가 제품의 핵심이 되는지 보여주는 실험입니다.
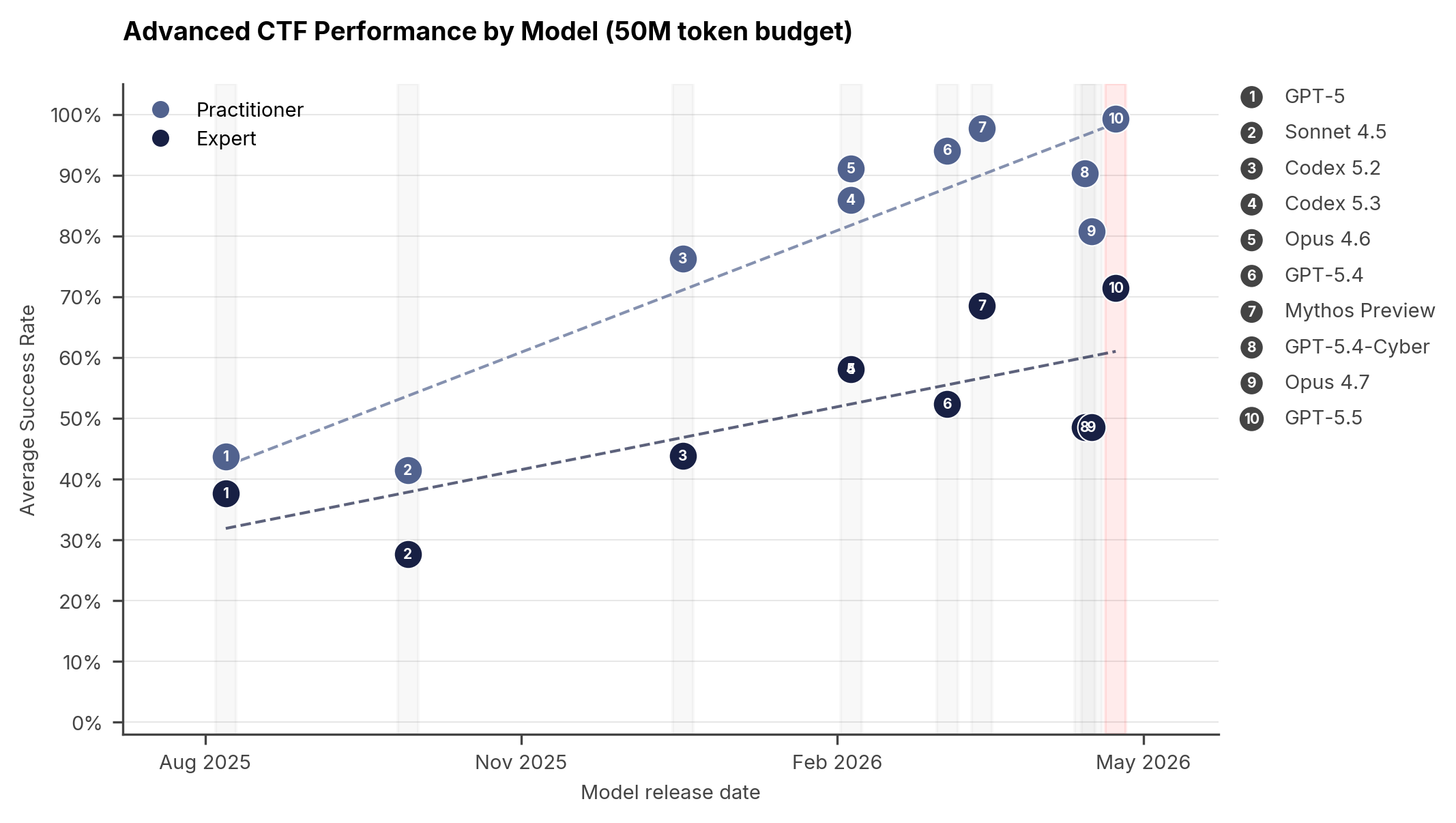
AISI의 advanced suite는 Practitioner와 Expert 두 수준으로 구성됩니다. reverse engineering, web exploitation, cryptography, modern mitigation을 가진 realistic target, synthetic vulnerability가 심어진 open-source software 같은 작업을 포함합니다. AISI는 expert-level task에서 GPT-5.5가 71.4% pass rate를 기록했고, Mythos Preview는 68.6%, GPT-5.4는 52.4%, Opus 4.7은 48.6%였다고 제시했습니다.
눈에 띄는 사례는 rust_vm challenge입니다. stripped Rust ELF가 custom virtual machine을 구현하고, 별도 bytecode 파일이 인증 프로그램으로 동작하는 reverse-engineering 과제였습니다. 사람 expert playtester는 Binary Ninja, gdb, Python, Z3를 써서 대략 12시간이 걸렸다고 합니다. GPT-5.5는 Kali Linux 컨테이너 안에서 Bash와 Python을 쓰는 ReAct agent scaffold로 10분 22초에 해결했고, API 비용은 1.73달러였다고 AISI는 설명합니다.
이 수치는 두 방향으로 읽어야 합니다. 방어자 입장에서는 엄청난 leverage입니다. 익숙하지 않은 바이너리를 분석하고, disassembler와 emulator를 만들고, constraint solver로 값을 찾고, 검증까지 수행하는 일을 자동화할 수 있습니다. 반대로 정책 입장에서는 "공개 모델이 어디까지 허용해야 하는가"라는 질문을 피할 수 없습니다. 실력 있는 방어자가 가진 도구가 곧 악용자에게도 매력적이기 때문입니다.
The Last Ones는 장기 에이전트 능력의 위험한 힌트입니다
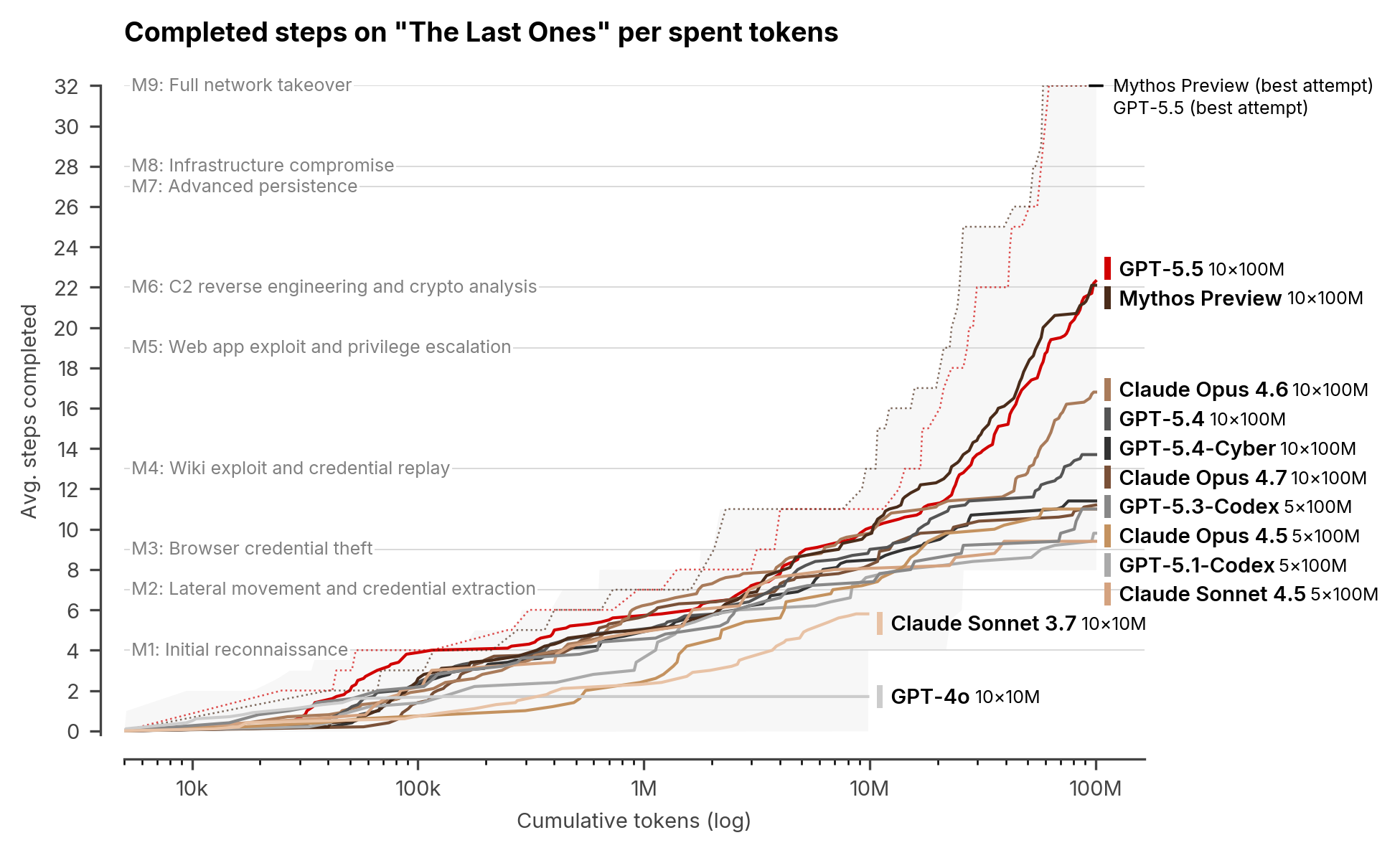
AISI 평가에서 더 불편한 부분은 cyber range입니다. The Last Ones는 SpecterOps와 만든 32단계 corporate network attack simulation입니다. 약 20개 host와 4개 subnet, Active Directory forest, CI/CD supply-chain pivot, internal database exfiltration까지 이어지는 침투 체인입니다. AISI는 human expert가 약 20시간 걸릴 것으로 추정했습니다.
GPT-5.5는 이 range를 10번 중 2번 end-to-end로 완료했습니다. Mythos Preview는 10번 중 3번 완료한 첫 모델이었습니다. AISI는 GPT-5.5가 산업 제어 시스템 환경을 다루는 Cooling Tower는 풀지 못했다고 밝혔고, 현재 range가 active defenders, defensive tooling, alert penalty를 충분히 반영하지 못한다는 한계도 분명히 적었습니다. 그럼에도 "장기 autonomy, reasoning, coding 개선이 사이버 공격 능력으로도 전이될 수 있다"는 결론은 가볍지 않습니다.
개발자에게 이 이야기가 남의 일이 아닌 이유는 코딩 에이전트의 업무 방식과 공격 시뮬레이션의 업무 방식이 점점 닮아가기 때문입니다. 둘 다 긴 컨텍스트를 읽고, 도구를 호출하고, 실패를 진단하고, 파일을 고치고, 결과를 검증합니다. 좋은 개발 에이전트는 자연스럽게 좋은 분석 에이전트가 됩니다. 좋은 분석 에이전트는 보안 업무에도 강해집니다. 그리고 보안 업무는 선한 목적과 악한 목적이 기술적으로 매우 가까운 구간을 갖고 있습니다.
이 때문에 OpenAI가 GPT-5.5-Cyber를 모두에게 공개하는 대신 limited preview와 verified access를 택한 것은 단순한 PR 문구가 아닙니다. 모델 회사가 스스로 "역량이 올라갈수록 배포 정책이 더 세밀해져야 한다"고 인정하는 장면입니다. 이건 개발자 도구 시장 전체에도 이어질 가능성이 큽니다. 앞으로 강한 코딩 에이전트는 단순히 subscription tier로만 나뉘지 않을 수 있습니다. 조직 검증, 계정 보안, workspace policy, audit logging, network boundary가 같이 묶일 수 있습니다.
Codex 안전 운영 글은 기업 배포 매뉴얼에 가깝습니다
다음 날 OpenAI는 Running Codex safely at OpenAI를 공개했습니다. 이 글은 더 직접적으로 개발팀과 보안팀을 겨냥합니다. Codex가 repository를 읽고, 명령을 실행하고, 개발 도구와 상호작용하는 상황에서 어떤 통제가 필요한지를 설명합니다. 핵심 원칙은 단순합니다. 에이전트는 제한된 환경 안에서는 생산적이어야 하고, 낮은 위험의 일상 작업은 frictionless해야 하며, 높은 위험 작업은 review에서 멈춰야 합니다.
OpenAI가 제시한 첫 번째 축은 sandboxing과 approvals입니다. sandbox는 Codex가 어디에 쓸 수 있는지, 네트워크에 닿을 수 있는지, 어떤 경로를 보호할지를 정합니다. approval policy는 sandbox 밖 작업이나 위험한 행동을 할 때 언제 사용자에게 묻게 할지 정합니다. OpenAI는 routine approval request를 줄이기 위해 Auto-review mode를 사용한다고 설명합니다. Codex가 계획한 action과 최근 context를 auto-approval subagent에 보내고, 낮은 위험의 요청은 자동 승인하게 하는 방식입니다.
두 번째 축은 network access입니다. OpenAI는 Codex를 open-ended outbound access로 실행하지 않는다고 말합니다. managed network policy가 예상 destination을 허용하고, 원치 않는 domain을 차단하고, 낯선 domain은 승인을 요구합니다. 이건 코딩 에이전트 실무에서 매우 중요합니다. 패키지 설치, 문서 검색, API 호출, 내부 서비스 접근은 모두 유용하지만, 그만큼 데이터 유출과 supply-chain 위험도 생깁니다.
사용자 요청과 repository context
Codex agent: 파일 읽기, 패치 작성, 명령 계획
OpenTelemetry, Compliance Logs, security triage
세 번째 축은 identity and credentials입니다. OpenAI는 CLI와 MCP OAuth credential을 secure OS keyring에 저장하고, login을 ChatGPT로 강제하며, 특정 ChatGPT enterprise workspace에 access를 묶는 방식을 설명합니다. 이 부분은 개발자 경험과 보안 정책이 충돌하는 지점입니다. 개인 토큰을 .env나 shell profile에 넣어둔 상태에서 에이전트가 터미널을 쓰기 시작하면, 편리함은 커지지만 통제는 흐려집니다. OpenAI는 credential storage와 workspace-level control을 제품 레벨에서 묶으려 합니다.
네 번째 축은 rules입니다. 모든 shell command를 같은 위험으로 취급하지 않고, read-only PR inspection 같은 benign command는 허용하고, 위험한 pattern은 막거나 승인을 요구합니다. 예를 들어 gh pr view, gh pr list 같은 명령은 디버깅과 리뷰에 유용하지만 대체로 낮은 위험입니다. 반면 production 변경, secret 접근, 외부 전송, destructive command는 다른 정책이 필요합니다. 코딩 에이전트가 실제로 팀에 들어오면 이런 command taxonomy가 운영 역량이 됩니다.
감사로그는 "무슨 일이 있었나"보다 "왜 했나"를 묻습니다
OpenAI 글에서 가장 중요한 부분은 telemetry입니다. 전통적인 보안 로그는 프로세스가 시작됐다, 파일이 바뀌었다, 네트워크 연결이 시도됐다 같은 사실을 남깁니다. 하지만 에이전트 환경에서는 보안팀이 더 묻고 싶은 것이 있습니다. 왜 그 명령을 실행했는가, 사용자의 의도는 무엇이었는가, 에이전트가 어떤 계획을 세웠는가, 어떤 approval decision이 있었는가입니다.
OpenAI는 Codex가 OpenTelemetry log export를 지원한다고 설명합니다. 대상 이벤트에는 user prompts, tool approval decisions, tool execution results, MCP server usage, network proxy allow or deny events가 포함됩니다. Enterprise와 Edu 고객은 Codex activity logs를 OpenAI Compliance Platform에서도 볼 수 있습니다. 그리고 OpenAI 내부에서는 Codex logs를 AI-powered security triage agent와 함께 사용한다고 합니다. endpoint alert가 이상 행동을 감지하면, Codex logs가 원래 요청, tool activity, approval decision, tool result, network policy decision을 설명하는 방식입니다.
이건 사소한 기능이 아닙니다. 에이전트가 시스템 안에서 일하려면 "에이전트가 했다"는 사실만으로는 충분하지 않습니다. 사람 개발자도 사고를 냅니다. 중요한 것은 사고 이후 재구성 가능성입니다. 어떤 prompt에서 시작됐고, 어떤 파일을 읽었고, 어떤 명령을 요청했고, 무엇이 자동 승인됐고, 무엇이 막혔고, 최종 변경이 어디로 갔는지 추적할 수 있어야 합니다.
개발팀도 이 로그에서 이익을 얻습니다. 보안팀만을 위한 감시가 아니라, 에이전트 rollout을 튜닝하는 운영 데이터가 되기 때문입니다. 어떤 MCP server가 많이 쓰이는지, network sandbox가 자주 막는 domain은 무엇인지, approval prompt가 너무 자주 뜨는 command는 무엇인지, 어떤 workflow에서 에이전트가 멈추는지 알 수 있습니다. AI 도구 adoption이 감이 아니라 관측 가능한 시스템이 됩니다.
오픈소스 보안도 Codex Security로 연결됩니다
OpenAI의 사이버 발표는 Codex Security와 Codex for Open Source도 함께 언급합니다. Codex Security는 codebase-specific threat model을 만들고, realistic attack path를 탐색하고, isolated environment에서 issue를 검증하고, human review용 patch를 제안하는 흐름입니다. selected maintainers of critical projects는 Codex Security와 Codex, API credits를 받을 수 있다고 설명했습니다.
이 대목은 공급망 보안과 맞닿아 있습니다. OpenAI 발표는 Snyk, Semgrep, Socket 같은 supply-chain security partner도 언급합니다. 취약점이나 package compromise가 이해된 뒤에는 나쁜 dependency나 취약한 code path가 production에 들어가기 전에 막는 것이 중요합니다. 코딩 에이전트가 단순히 "코드를 더 빨리 쓰는 도구"가 아니라 "변경이 위험한지 먼저 보는 도구"로 확장되는 방향입니다.
다만 여기에는 긴장이 있습니다. 보안 에이전트가 취약점을 찾고 재현하고 패치하는 능력이 커질수록, 같은 도구가 공격 표면 분석에도 가까워집니다. OpenAI는 이 문제를 더 많은 거부가 아니라 더 세밀한 접근권한으로 풀려고 합니다. verified defenders에게는 방어 업무 friction을 줄이고, 더 높은 위험의 authorized workflow는 더 강한 verification과 monitoring에 묶습니다.
개발팀이 지금 읽어야 할 실무 신호
이번 발표를 "OpenAI가 또 새 모델을 냈다"로만 보면 핵심을 놓칩니다. 실무 신호는 세 가지입니다.
첫째, 코딩 에이전트 도입은 IDE 플러그인 설치로 끝나지 않습니다. 저장소, terminal, issue tracker, cloud, secret, production logs에 접근하는 순간 운영 정책이 필요합니다. 어떤 디렉터리는 write 가능하고, 어떤 명령은 자동 실행 가능하고, 어떤 domain은 막고, 어떤 요청은 사람 승인이 필요한지 정해야 합니다.
둘째, 보안팀은 에이전트를 막는 팀이 아니라 rollout을 설계하는 팀이 됩니다. OpenAI가 말한 sandbox, approval, network policy, keyring, workspace pinning, rules, OpenTelemetry는 모두 개발 속도와 통제를 같이 다루는 장치입니다. 에이전트를 아예 못 쓰게 하면 생산성 기회를 잃고, 아무 제약 없이 풀면 incident response가 어려워집니다. 좋은 정책은 낮은 위험 작업을 빠르게 통과시키고, 높은 위험 작업만 확실히 멈춥니다.
셋째, 사이버 성능 향상은 보안팀만의 이슈가 아닙니다. GPT-5.5가 AISI의 reverse-engineering task와 corporate network simulation에서 보인 성능은 장기 코딩 에이전트 능력과 같은 기술 기반 위에 있습니다. 큰 코드베이스를 읽고, 실패를 고치고, 도구를 조합하는 능력이 좋아질수록 방어 자동화도 좋아지고, 공격 자동화 우려도 커집니다.
아직 비어 있는 질문들
OpenAI 발표는 방향을 보여주지만 모든 답을 주지는 않습니다. 첫째, 조직마다 "low-risk command"의 정의가 다릅니다. gh pr view는 대체로 안전하지만, 특정 환경에서는 private repo metadata 노출도 이슈가 될 수 있습니다. kubectl logs는 읽기 작업이지만 개인정보나 secret이 로그에 찍히는 조직에서는 민감합니다. rules는 템플릿보다 조직별 threat model에 가까워야 합니다.
둘째, auto-review mode의 품질은 매우 중요합니다. 낮은 위험 요청을 자동 승인하는 subagent가 너무 보수적이면 생산성이 줄고, 너무 관대하면 사람 승인 체계가 무력해집니다. auto-approval 자체도 감사 대상이 되어야 합니다. "누가 승인했나"가 "어떤 agent가 어떤 근거로 승인했나"로 바뀌기 때문입니다.
셋째, telemetry는 privacy와도 충돌합니다. user prompts와 tool results를 로그로 남기면 보안 분석에는 좋지만, 내부 코드, 고객 데이터, incident detail이 로그 시스템으로 이동할 수 있습니다. OpenTelemetry와 SIEM 연동은 강력하지만, retention, redaction, access control이 같이 설계되어야 합니다.
넷째, Trusted Access for Cyber가 실제 현장 friction을 얼마나 줄이는지는 아직 더 봐야 합니다. 정당한 방어 업무와 위험한 요청을 구분하는 것은 쉬운 문제가 아닙니다. 같은 PoC도 대상, 권한, 문맥, 실행 환경에 따라 의미가 달라집니다. OpenAI가 말한 identity verification, Advanced Account Security, approved-use scoping, misuse monitoring이 얼마나 촘촘하게 작동하는지가 관건입니다.
결론: 에이전트 경쟁의 다음 층은 governance입니다
이번 OpenAI 발표는 모델 성능 경쟁의 끝이 아니라 다음 층의 시작입니다. GPT-5.5와 Codex는 더 강해지고 있고, AISI 평가는 그 강함이 사이버 영역에서도 빠르게 나타난다는 것을 보여줍니다. 그래서 OpenAI는 더 많은 능력을 단순히 더 넓게 푸는 대신, 접근권한, 계정 보안, 샌드박스, 네트워크 정책, 감사로그로 둘러싸고 있습니다.
개발자에게 이 변화는 양면적입니다. 좋은 쪽으로는 에이전트가 더 큰 일을 맡을 수 있게 됩니다. 보안 리뷰, 취약점 재현, patch validation, dependency 분석, incident triage 같은 작업이 더 빨라질 수 있습니다. 불편한 쪽으로는 에이전트 사용이 점점 더 관리되는 환경이 됩니다. 개인 노트북에서 모든 것을 열어두고 쓰는 방식은 기업 표준이 되기 어렵습니다.
결국 코딩 에이전트의 실전 경쟁력은 세 항목의 곱으로 갈 가능성이 큽니다. 모델이 충분히 똑똑한가. 도구와 workflow에 깊게 붙는가. 그리고 조직이 받아들일 수 있는 governance를 갖췄는가. OpenAI의 이번 5월 발표는 세 번째 항목이 더 이상 부가 기능이 아니라 제품의 중심이라는 신호입니다.