73% 성공률 뒤의 청구서, 에이전트 평가는 모델 밖
IBM Research와 Hugging Face의 Open Agent Leaderboard는 AI 에이전트를 모델이 아니라 하네스, 비용, 실패 방식까지 포함한 시스템으로 평가합니다.
- 무슨 일: IBM Research와 Hugging Face가
Open Agent Leaderboard를 공개했습니다.- SWE-Bench Verified, BrowseComp+, AppWorld, tau2-Bench를 묶어 범용 에이전트 시스템을 비교합니다.
- 핵심 변화: 점수표의 단위가 모델에서 에이전트 하네스+모델+비용 조합으로 바뀝니다.
- 실무 의미: 같은 모델도 agent architecture에 따라 성공률, 비용, 실패 방식이 달라질 수 있습니다.
- 논문은 같은 모델 안에서 에이전트 선택이 최대 12%p 수준의 차이를 만들 수 있다고 보고합니다.
- 주의점: 리더보드는 live surface입니다. 특정 순위보다 평가 프로토콜과 재현 가능성을 먼저 봐야 합니다.
AI 에이전트 시장은 오래도록 모델 이름으로 설명됐습니다. Claude가 더 잘하느냐, GPT가 더 싸냐, Gemini가 더 빠르냐 같은 질문이 먼저 나왔습니다. 코딩 에이전트도 크게 다르지 않았습니다. 사용자들은 SWE-Bench 점수, 컨텍스트 길이, 도구 호출 지원, 가격을 보고 제품을 비교했습니다. 하지만 실제 에이전트를 배포해 보면 곧 다른 문제가 드러납니다. 모델이 같아도 에이전트가 어떤 도구를 먼저 고르는지, 실패 후 재시도하는지, 긴 작업을 어디서 끊는지, 비용을 얼마나 태우는지가 모두 달라집니다.
IBM Research와 Hugging Face가 2026년 5월 18일 공개한 Open Agent Leaderboard는 이 지점을 정면으로 겨냥합니다. 발표의 표면은 새로운 리더보드입니다. 그러나 핵심은 "어떤 모델이 1위인가"가 아닙니다. 이 리더보드는 모델 단독 점수가 아니라 에이전트 시스템 전체를 비교하려고 합니다. 같은 backbone model을 쓰더라도 agent architecture, tool interface, planning loop, cost profile이 바뀌면 결과가 바뀐다는 사실을 공개 데이터와 재현 가능한 프레임워크로 드러내려는 시도입니다.
그래서 이번 뉴스는 단순한 벤치마크 추가가 아닙니다. 에이전트 평가의 단위가 바뀌는 사건입니다. 모델 제공사가 발표하는 점수표는 대개 모델이 특정 문제를 얼마나 잘 푸는지 보여줍니다. 반면 실제 에이전트 제품은 모델 호출보다 훨씬 넓습니다. 파일을 읽고, 코드를 고치고, 브라우저를 열고, 고객지원 정책을 따르고, API를 호출하고, 중간 상태를 기억하고, 실패하면 복구해야 합니다. Open Agent Leaderboard는 이 전체 묶음을 하나의 평가 대상으로 올려놓습니다.
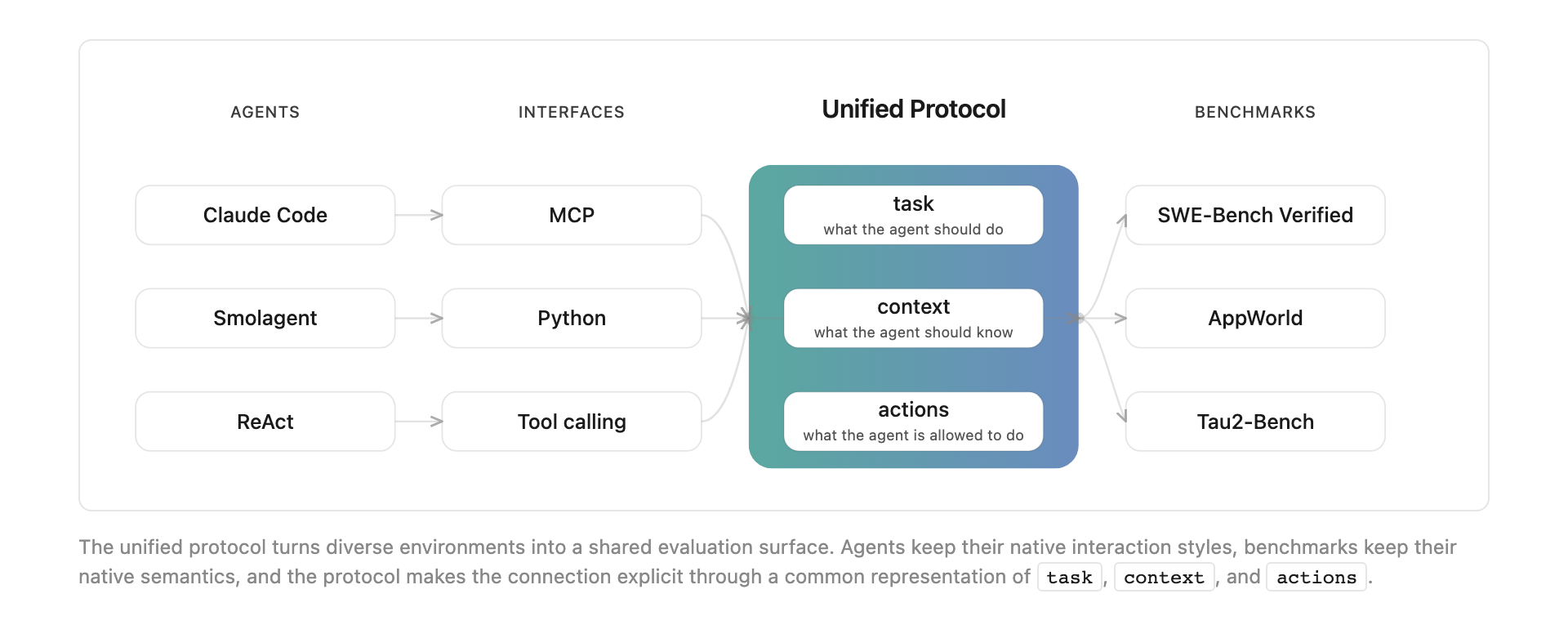
6개 벤치마크를 하나의 표면으로 묶었습니다
공식 블로그는 Open Agent Leaderboard가 여섯 가지 벤치마크를 묶는다고 설명합니다. SWE-Bench Verified는 실제 GitHub 저장소의 버그 수정 능력을 봅니다. BrowseComp+는 웹을 넘나드는 복잡한 리서치 질문을 다룹니다. AppWorld는 수백 개 앱과 액션이 있는 개인 업무 환경에서 작업 완료를 측정합니다. tau2-Bench Airline & Retail과 tau2-Bench Telecom은 회사 정책을 따라 고객지원이나 기술지원을 수행하는지를 봅니다.
이 조합이 중요한 이유는 에이전트의 실패가 영역마다 다르기 때문입니다. 코딩에서는 테스트를 통과해도 잘못된 파일을 건드릴 수 있습니다. 리서치에서는 답을 길게 쓸 수 있지만 근거가 빈약할 수 있습니다. 고객지원에서는 정책을 정확히 따라야 하고, 개인 비서 업무에서는 작은 API 호출 순서가 결과를 바꿀 수 있습니다. 하나의 벤치마크만 보면 에이전트가 특정 환경에 잘 맞는지 알 수는 있어도, 낯선 환경에서 어느 정도 일반화되는지 보기는 어렵습니다.
논문 General Agent Evaluation은 이 문제를 "general-purpose agents perform tasks in unfamiliar environments"라는 관점으로 정의합니다. 즉 범용 에이전트는 특정 업무에 손으로 맞춘 시스템이 아니라, 다른 도구와 규칙과 제약이 있는 환경으로 옮겨도 어느 정도 작동해야 합니다. 이것은 에이전트를 데모가 아니라 제품으로 보는 관점입니다. 개발자가 실제로 알고 싶은 것은 "이 에이전트가 유명한 코딩 벤치에서 몇 점인가"만이 아닙니다. "우리 업무와 다른 환경에 들어갔을 때 무너지지 않는가"입니다.
이를 위해 연구진은 unified protocol을 제안합니다. 각 벤치마크와 에이전트가 자기만의 인터페이스를 유지하되, 공통 표현으로 task, context, actions를 주고받게 만드는 방식입니다. 블로그의 설명처럼 벤치마크마다 언어가 다른 상태에서는 각 에이전트를 매번 새로 배선해야 합니다. 통합 프로토콜은 이 배선 비용을 줄이고, 서로 다른 에이전트 아키텍처를 같은 표면 위에 올립니다.
리더보드의 주인공은 모델이 아니라 조합입니다
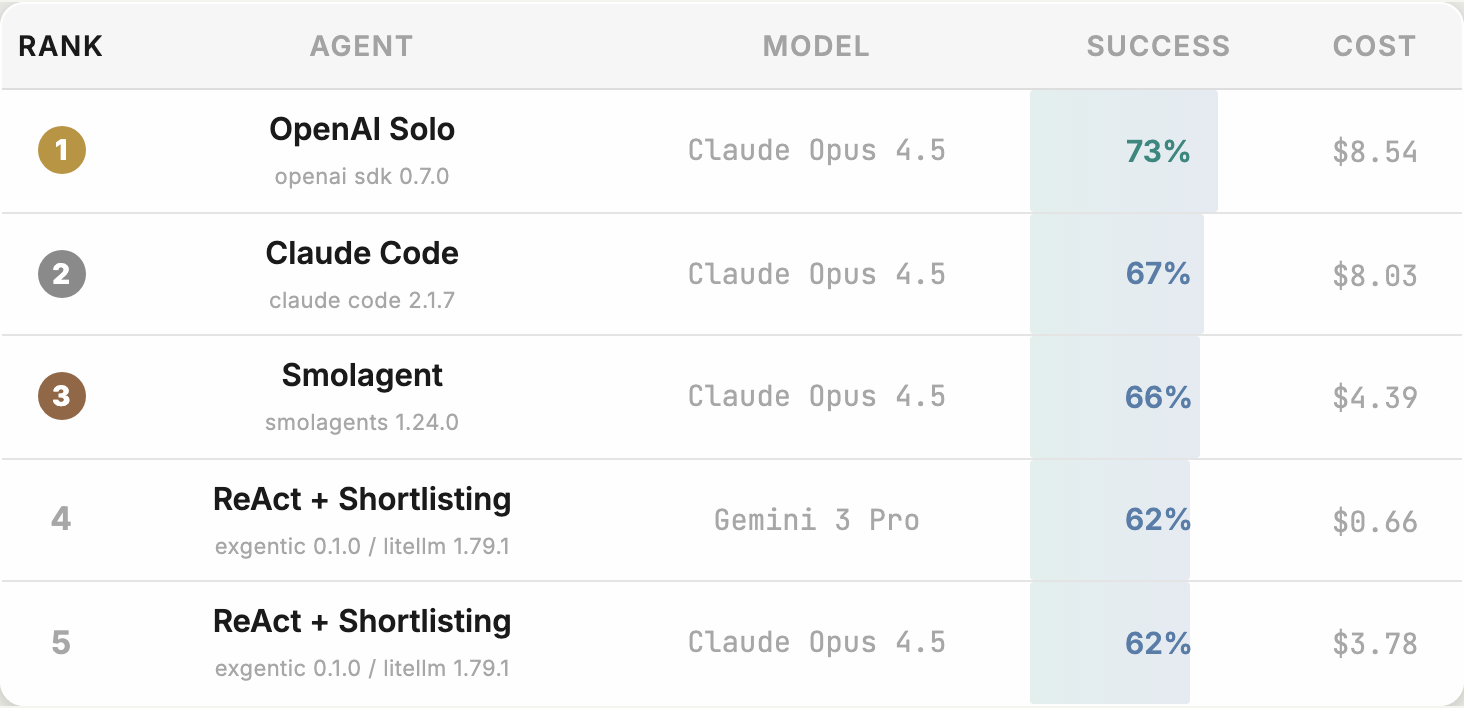
Open Agent Leaderboard의 각 행은 모델 하나가 아닙니다. 특정 에이전트 시스템과 특정 모델의 조합입니다. 예를 들어 블로그 이미지의 상위권에는 OpenAI Solo, Claude Code, Smolagent, ReAct + Shortlisting 같은 에이전트 구성이 나오고, 여기에 Claude Opus 4.5, Gemini 3 Pro 같은 모델이 붙습니다. 이 구조가 메시지의 핵심입니다. 에이전트는 모델을 감싼 실행 시스템이고, 점수는 그 결합의 결과입니다.
공식 블로그는 상위 세 구성이 같은 모델을 쓰지만 성공률과 비용이 다르다고 지적합니다. 같은 모델이더라도 어떤 agent harness가 도구를 노출하고, 어떤 방식으로 계획하고, 어떤 단계에서 답을 확정하는지에 따라 결과가 달라집니다. 이것은 코딩 에이전트 사용자에게 익숙한 경험입니다. 같은 모델을 써도 Claude Code, Codex CLI, Gemini CLI, Cursor, 자체 LangGraph harness의 행동은 같지 않습니다. 파일 탐색 방식, shell 사용 방식, 멈춤 기준, 로그가 다릅니다.
논문 초록은 이 차이를 더 구체적으로 말합니다. 연구진은 5개 agent architecture, 5개 backbone LLM, 6개 benchmark의 full factorial 구성을 비교했고, 같은 모델 안에서도 agent architecture 선택이 최대 12%p 수준으로 결과를 흔들 수 있다고 보고합니다. 동시에 backbone model choice가 전체 성능을 지배하는 요인이라는 점도 함께 적습니다. 즉 "모델은 중요하지 않다"가 아니라 "모델만 보면 부족하다"가 정확한 해석입니다.
이 균형이 중요합니다. 에이전트 시장에서는 두 가지 과장이 자주 반복됩니다. 하나는 모든 것이 모델 성능으로 결정된다는 주장입니다. 다른 하나는 좋은 오케스트레이션만 있으면 어떤 모델도 충분하다는 주장입니다. Open Agent Leaderboard의 메시지는 둘 중 하나로 기울지 않습니다. 모델 선택은 여전히 강력한 변수입니다. 하지만 에이전트가 실제 업무를 수행하는 순간, 도구 shortlisting, context management, memory, error recovery, interface design이 별도 변수로 떠오릅니다.
비용을 같이 보여주는 이유
이번 리더보드에서 특히 눈에 띄는 것은 비용입니다. 공식 블로그는 평균 성공률과 평균 task 비용을 함께 보여준다고 설명합니다. 에이전트를 실제로 운영하는 팀에게 이것은 부가 지표가 아닙니다. 에이전트는 한 번의 답변을 생성하는 챗봇보다 비용 구조가 훨씬 복잡합니다. 계획을 세우고, 도구를 여러 번 호출하고, 실패하면 다시 시도하고, 중간 정보를 요약하고, 마지막 검증까지 수행할 수 있기 때문입니다.
블로그는 실패 실행이 성공 실행보다 20~54% 더 비쌌다고 적습니다. 이 수치는 에이전트 운영에서 자주 놓치는 비용을 드러냅니다. 실패는 단순히 점수 0점이 아닙니다. 실패한 에이전트는 종종 더 오래 맴돌고, 더 많은 도구를 호출하고, 더 많은 토큰을 쓰고, 결국 답을 내지 못합니다. 즉 실패율이 낮아도 실패 방식이 길고 비싸면 실제 운영 비용은 빠르게 커질 수 있습니다.
개발자 관점에서는 이 지표가 더 현실적입니다. 어떤 에이전트가 2%p 더 높은 성공률을 내지만 task당 비용이 몇 배라면, 그것이 항상 좋은 선택은 아닙니다. 반대로 낮은 비용으로 빠르게 실패하는 시스템은 batch evaluation이나 초안 생성에는 유용할 수 있지만, 고객 앞에서 자동 실행되는 업무에는 위험할 수 있습니다. 따라서 에이전트 평가는 성공률, 비용, 실패 시간, 재시도 정책, tool-call 수를 함께 봐야 합니다.
Open Agent Leaderboard가 비용을 공개 표면에 올린 것은 에이전트 제품의 구매 기준도 바꿉니다. 기업이 "이 모델이 더 똑똑하다"는 설명만으로 도입을 결정하기 어려워집니다. 실제 질문은 더 구체적입니다. 같은 업무를 처리할 때 평균 비용은 얼마인가. 실패한 작업은 얼마나 오래 실행되는가. 잘못된 tool call이 몇 번 발생하는가. 사람이 검토해야 하는 중간 산출물이 남는가. 에이전트가 멈춘 이유를 나중에 설명할 수 있는가.
Exgentic은 평가를 실행 가능한 프레임워크로 만듭니다
리더보드만 있었다면 이번 발표의 의미는 제한적이었을 것입니다. 더 중요한 부분은 Exgentic입니다. GitHub 저장소는 Exgentic을 다양한 benchmark와 domain에서 AI agent를 표준화해 평가하는 universal evaluation framework로 설명합니다. 설치 후 benchmark와 agent 목록을 보고, 특정 조합을 실행하고, 결과를 비교할 수 있는 CLI를 제공합니다.
README에 따르면 현재 사용 가능한 agent에는 LiteLLM Tool Calling, SmolAgents, OpenAI MCP, Claude Code, Codex CLI, Gemini CLI가 포함됩니다. 사용 가능한 benchmark에는 tau2, AppWorld, BrowseCompPlus, SWE-bench, HotpotQA, GSM8K, BFCL 등이 보입니다. 이것은 리더보드가 단순 웹 페이지가 아니라 평가 실행 계층으로 확장될 수 있음을 보여줍니다.
출력 구조도 중요합니다. Exgentic은 각 run을 outputs/<run_id>/ 아래에 저장하고, overall score와 cost, benchmark별 결과, runtime context, session별 trajectory, OpenTelemetry span log를 남기는 구조를 제시합니다. 에이전트 평가에서 이 로그는 단순 디버깅 보조물이 아닙니다. 왜 실패했는지, 어디서 도구 선택이 틀렸는지, 어떤 컨텍스트가 누락됐는지, 비용이 어느 단계에서 커졌는지를 볼 수 있는 증거입니다.
최근 에이전트 관측성 제품들이 늘어나는 이유도 같습니다. Honeycomb은 agent timeline을 trace로 되감으려 하고, LangSmith와 Langfuse는 LLM call과 tool call을 추적합니다. Open Agent Leaderboard와 Exgentic은 그 흐름을 evaluation 쪽으로 가져옵니다. 운영 중인 에이전트를 관측하는 것만큼, 출시 전에 여러 환경에서 표준화해 깨뜨려 보는 일이 중요해졌기 때문입니다.
범용 에이전트라는 말의 함정
Open Agent Leaderboard는 "general-purpose agent"를 평가한다고 말합니다. 이 표현은 매력적이지만 위험합니다. 범용이라는 말은 자칫 모든 업무를 잘한다는 뜻으로 들릴 수 있습니다. 그러나 논문과 블로그의 실제 톤은 더 조심스럽습니다. 범용성은 이진값이 아니라 스펙트럼이며, 비용을 감당할 수 있을 때에만 의미가 있습니다.
이 관점은 실무적으로 유용합니다. 많은 팀이 에이전트를 도입할 때 특정 업무 하나에 맞춘 prompt와 tool chain을 만듭니다. 그러면 그 업무에서는 높은 성능을 낼 수 있습니다. 하지만 새 업무가 들어올 때마다 별도 prompt, 별도 tool wrapper, 별도 evaluator를 만들어야 한다면 확장성이 떨어집니다. 반대로 완전 범용 에이전트 하나에 모든 일을 맡기면 비용과 실패 모드가 통제되지 않을 수 있습니다.
따라서 실제 제품 설계는 중간 지대를 찾게 됩니다. 공통 agent harness를 두고, 도메인별 tool set과 policy, evaluator를 붙이는 방식입니다. Open Agent Leaderboard가 유용한 이유는 이 중간 지대를 측정하려 하기 때문입니다. "이 에이전트가 coding에서 좋다"가 아니라 "coding, research, customer support, personal assistance처럼 서로 다른 환경에서 어떤 패턴으로 버티는가"를 보게 합니다.
공식 블로그는 일반 에이전트가 이미 일부 benchmark에서 전문 시스템과 경쟁 가능하다고 말합니다. 하지만 이 문장은 신중히 읽어야 합니다. 모든 업무에서 전문 시스템을 대체한다는 뜻이 아닙니다. 오히려 평가 범위를 넓히면 어떤 영역에서는 일반 에이전트가 충분히 강하고, 어떤 영역에서는 특화 시스템이 여전히 필요하며, 어떤 실패는 점수만으로 보이지 않는다는 뜻에 가깝습니다.
오픈 웨이트 모델에는 다른 질문이 붙습니다
블로그는 공개 이후 DeepSeek V3.2와 Kimi K2.5 같은 open-weight 모델 결과가 추가됐다고 설명합니다. 이 결과는 특정 조합에서는 경쟁력이 있지만, frontier closed-source 모델보다 평균 18~29%p 뒤처졌다는 메시지로 요약됩니다. 여기서도 결론은 단순하지 않습니다. 오픈 웨이트 모델이 무조건 뒤처진다는 선언이 아니라, 에이전트 workload에서 일반화 안정성을 별도 평가해야 한다는 경고에 가깝습니다.
오픈 모델은 비용, 데이터 통제, 온프레미스 배포, 커스터마이징에서 강점이 있습니다. 하지만 에이전트 작업은 단일 프롬프트 답변보다 어렵습니다. 긴 컨텍스트를 관리하고, 도구 호출 형식을 안정적으로 지키고, 실패 후 복구하고, 모호한 지시를 되묻고, 여러 단계의 상태를 유지해야 합니다. 일반 채팅 벤치마크에서 좋은 모델이 에이전트 벤치마크에서도 똑같이 좋은 성능을 내리라고 가정하면 위험합니다.
한국의 AI 팀에게도 이 부분은 중요합니다. 사내 코드, 고객 데이터, 운영 로그를 외부 API에 보내기 어렵다면 오픈 모델이나 프라이빗 배포는 매력적입니다. 그러나 비용과 데이터 경계를 이유로 모델을 바꾸는 순간, 기존 에이전트 하네스가 같은 품질로 동작하는지 다시 봐야 합니다. tool calling schema, JSON 안정성, function selection, multi-step recovery, latency tail이 모두 재평가 대상입니다.
리더보드를 어떻게 읽어야 하나
리더보드는 쉽게 오해됩니다. 순위표는 빠르게 공유되고, 1위 이름은 제목이 됩니다. 하지만 Open Agent Leaderboard를 그렇게만 읽으면 핵심을 놓칩니다. 이 리더보드의 가장 중요한 가치는 특정 agent-model 조합의 현재 순위가 아니라, 결과를 cost와 trace와 protocol로 재현하려는 구조입니다.
첫째, live leaderboard라는 점을 전제로 봐야 합니다. Hugging Face 데이터셋과 Space는 업데이트됩니다. 모델 버전도 바뀌고, agent implementation도 바뀌며, 제출 결과도 늘어날 수 있습니다. 따라서 글을 쓰는 시점의 top five 이미지나 점수는 고정된 진실이 아니라 snapshot입니다.
둘째, benchmark adaptation을 확인해야 합니다. 공식 FAQ는 benchmark 자체를 수정하지 않지만 unified protocol에 맞추기 위해 인터페이스 적응이 필요하다고 설명합니다. 예를 들어 benchmark 안에 박혀 있던 prompt를 외부화하거나, SWE-Bench Verified처럼 task instruction을 명시하는 조정이 있을 수 있습니다. 이런 조정은 공정한 비교를 위해 필요하지만, 개별 benchmark의 원래 leaderboard와 점수가 달라질 수 있는 이유이기도 합니다.
셋째, prompt optimization을 배제한 결과라는 점을 봐야 합니다. 많은 모델 또는 agent whitepaper는 특정 benchmark에서 최고 성능을 내기 위해 prompt와 환경을 많이 최적화합니다. Exgentic은 더 중립적인 비교를 위해 이를 피하려고 합니다. 이 선택은 장점과 단점이 있습니다. 장점은 같은 표면에서 비교하기 쉽다는 점입니다. 단점은 실제 팀이 자기 업무에 맞춰 충분히 최적화한 agent 성능과는 차이가 날 수 있다는 점입니다.
개발팀이 가져갈 체크리스트
Open Agent Leaderboard가 당장 모든 팀의 내부 평가를 대체하지는 않습니다. 하지만 평가 체크리스트는 분명히 바꿉니다. AI 에이전트를 제품에 넣는 팀이라면 이제 모델 점수표만 보고 의사결정하기 어렵습니다.
첫 번째 질문은 "우리 업무의 벤치마크 표면은 무엇인가"입니다. 코딩 에이전트라면 SWE-Bench류 issue 해결뿐 아니라 repository-specific migration, test repair, dependency update, security fix, rollback까지 봐야 합니다. 고객지원 에이전트라면 정책 준수, escalation, refund, identity verification을 별도 task로 만들어야 합니다. 리서치 에이전트라면 출처 추적과 반례 탐색을 함께 평가해야 합니다.
두 번째 질문은 "실패를 어떻게 기록하는가"입니다. 에이전트가 실패했을 때 최종 답변만 남으면 원인을 알 수 없습니다. 어떤 tool call이 있었는지, 어떤 관찰을 받았는지, 어떤 context가 빠졌는지, 어떤 retry가 비용을 키웠는지 trajectory가 필요합니다. Exgentic이 session별 trajectory.jsonl과 OpenTelemetry span을 남기는 이유가 여기에 있습니다.
세 번째 질문은 "성공률과 비용의 균형을 어떻게 정할 것인가"입니다. 모든 업무가 최고 성능 모델을 요구하지 않습니다. 반대로 민감한 업무에서는 저렴한 모델로 빠르게 실패하는 전략이 위험할 수 있습니다. task별로 허용 가능한 실패율, 평균 비용, 최대 step, human review 기준을 정해야 합니다. 에이전트 평가는 제품 정책과 비용 정책을 동시에 요구합니다.
네 번째 질문은 "에이전트 하네스를 버전 관리하는가"입니다. 모델 버전만 바뀌는 것이 아닙니다. tool description, system prompt, memory policy, tool shortlisting, MCP server permission, CLI wrapper가 모두 성능을 바꿉니다. 리더보드가 agent configuration을 하나의 평가 단위로 삼는 이유는 이 모든 변화가 결과에 영향을 주기 때문입니다.
에이전트 평가는 더 공개되어야 합니다
Open Agent Leaderboard의 가장 좋은 점은 "에이전트 평가는 닫힌 벤더 발표로 충분하지 않다"는 입장입니다. 공식 블로그는 일반 에이전트가 너무 중요해서 닫힌 문 뒤에서 평가돼서는 안 된다고 말합니다. 이 표현은 다소 선언적이지만 방향은 맞습니다. 에이전트가 업무 시스템에 들어가면 실패는 사용자의 시간과 비용, 때로는 보안과 규정 준수 문제로 이어집니다. 그러면 평가 방법도 더 투명해야 합니다.
물론 공개 리더보드에는 한계가 있습니다. 모든 실제 업무를 대표할 수 없고, 민감한 기업 데이터를 포함할 수 없으며, live service의 비결정성도 있습니다. 하지만 공개 평가가 없으면 비교는 더 나빠집니다. 벤더는 자기에게 유리한 benchmark만 보여주고, 사용자는 서로 다른 조건의 숫자를 같은 것처럼 비교하게 됩니다. Open Agent Leaderboard는 이 혼란을 완전히 해결하지는 못해도, 비교의 단위를 더 정확하게 만들려는 시도입니다.
이번 발표를 에이전트 시장의 다음 기준선으로 볼 수 있는 이유가 여기에 있습니다. 모델 리더보드는 여전히 필요합니다. 하지만 에이전트 시대에는 모델 리더보드만으로 부족합니다. 같은 모델도 harness가 다르면 다른 제품이 됩니다. 같은 성공률도 비용과 실패 방식이 다르면 다른 운영 계약이 됩니다. 같은 tool set도 권한과 로그가 다르면 다른 위험 표면이 됩니다.
결국 Open Agent Leaderboard가 던지는 질문은 간단합니다. 당신의 에이전트는 어떤 모델을 쓰느냐가 아니라, 어떤 시스템으로 행동하고 실패하고 비용을 쓰는가입니다. 에이전트가 실제 업무를 맡는 순간, 평가는 모델 밖에서 시작됩니다. 그리고 그 밖의 영역, 즉 하네스, 도구, 프로토콜, 로그, 비용, 실패 모드를 공개적으로 비교하는 일이 이제 AI 개발 인프라의 일부가 되고 있습니다.