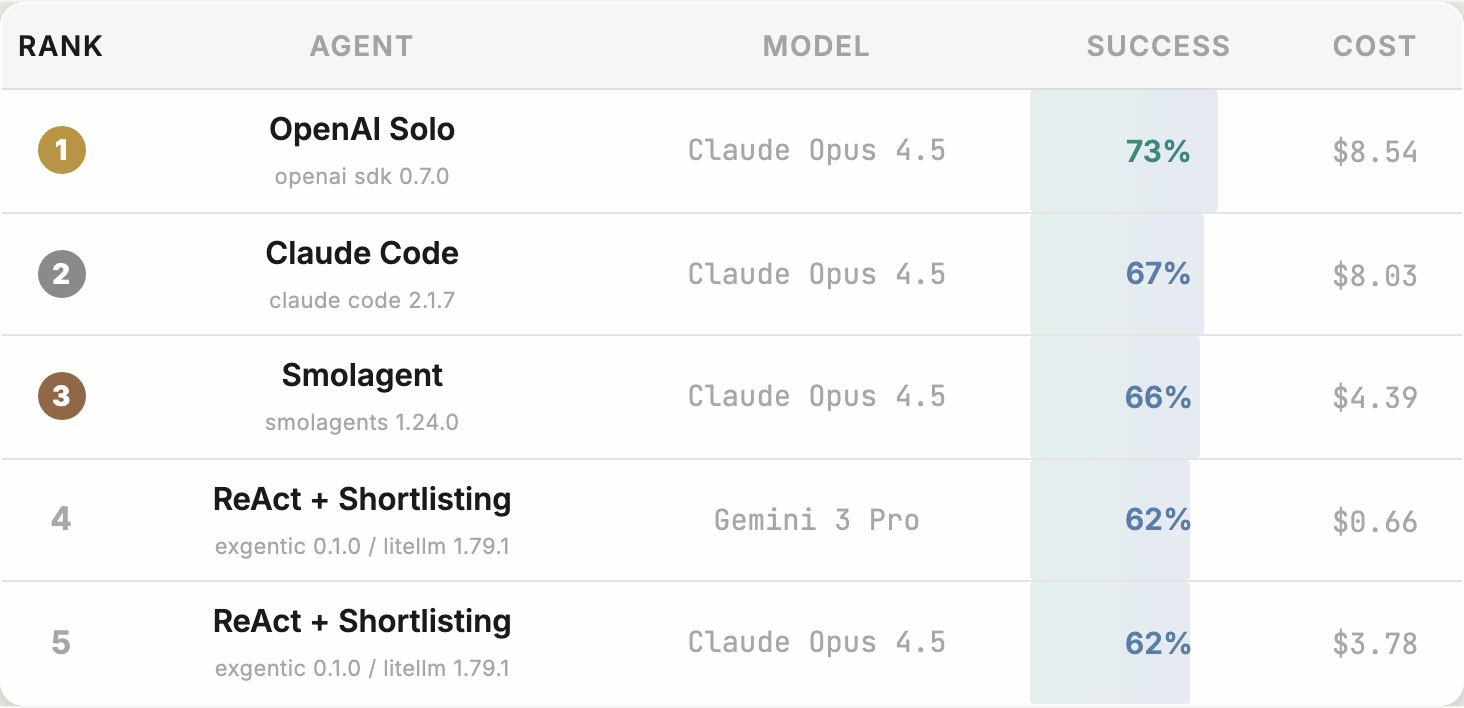
73% 에이전트 성적표, 모델만 보던 벤치마크의 끝
Open Agent Leaderboard는 모델 단독 점수 대신 에이전트 구현, 비용, 실패 패턴까지 묶어 평가하는 새 공개 기준입니다.

- 무슨 일: IBM Research와 Hugging Face가
Open Agent Leaderboard와Exgentic평가 프레임워크를 공개했습니다.- 2026년 5월 18일 발표이며, 논문은 5개 에이전트 구조와 5개 모델, 6개 benchmark 조합을 다룹니다.
- 의미: 에이전트 평가는 이제 모델 단독 점수가 아니라
모델 + 하네스 + 도구 + 비용의 시스템 평가로 이동합니다. - 핵심 수치: 같은 모델 안에서도 에이전트 구조가 최대 12pp 차이를 만들고, 실패 실행은 성공 실행보다 20-54% 더 비쌌습니다.
- 공개 리더보드의 초기 상위 조합은 약 73% 성공률을 보였지만, live ranking이라 수치는 계속 바뀔 수 있습니다.
- 주의점: benchmark-specific tuning을 배제한 비교라서, 제품별 최적화 데모와 직접 비교하면 해석이 흔들립니다.
AI 에이전트 시장은 한동안 같은 질문을 반복했습니다. 어느 모델이 더 강한가. 어느 모델이 코딩 benchmark에서 몇 점을 냈는가. 어느 모델이 더 긴 context를 버티는가. 이 질문은 여전히 중요합니다. 하지만 실제 에이전트 제품을 운영해 본 팀이라면 곧 다른 질문에 부딪힙니다. 같은 모델을 써도 왜 어떤 에이전트는 일을 끝내고, 어떤 에이전트는 도구 목록 앞에서 길을 잃습니까. 성공률이 비슷해도 왜 한쪽은 비용을 몇 배 더 태웁니까. 실패했을 때는 빨리 멈추는 편이 낫습니까, 끝까지 시도하는 편이 낫습니까.
이번 뉴스는 이 질문을 정면으로 겨냥합니다. IBM Research와 Hugging Face가 2026년 5월 18일 Open Agent Leaderboard를 공개했습니다. 함께 공개된 것은 Exgentic이라는 오픈소스 평가 프레임워크와 General Agent Evaluation 논문입니다. 발표 문장의 핵심은 단순합니다. 에이전트를 평가할 때 모델만 보지 말고, 모델을 감싸는 agent architecture, tool interface, benchmark adaptation, cost, failure behavior까지 함께 보자는 것입니다.
이 접근이 중요한 이유는 에이전트가 이미 단일 모델 호출이 아니기 때문입니다. 코딩 에이전트는 repository를 읽고, 파일을 수정하고, 테스트를 실행하고, 실패 로그를 다시 해석합니다. 고객 지원 에이전트는 정책 문서를 읽고, 주문 상태를 확인하고, 환불 가능 여부를 판단합니다. 리서치 에이전트는 웹을 탐색하고, 근거를 모으고, 상충하는 정보를 정리합니다. 이 모든 과정에서 모델은 핵심 부품이지만, 전체 제품은 planner, tool router, memory, retry policy, prompt scaffold, sandbox, evaluator가 결합된 시스템입니다.
왜 모델 리더보드만으로 부족해졌나
LLM 리더보드는 원래 유용했습니다. MMLU, GPQA, SWE-Bench, HumanEval, MMMU 같은 점수는 모델의 대략적인 능력 지형을 보여줬습니다. 모델 제공자와 사용자 모두에게 공통 언어를 제공했고, 특정 모델이 추론, 코딩, 시각 이해, 수학에서 어디쯤 서 있는지 빠르게 파악할 수 있게 했습니다. 그러나 에이전트에서는 이 방식이 곧 한계에 닿습니다.
첫째, 에이전트는 문제를 한 번에 답하지 않습니다. 여러 단계로 움직입니다. 중간에 관찰하고, 도구를 호출하고, 실패하면 방향을 바꿉니다. 같은 모델이라도 도구 설명을 어떻게 보여주는지, 중간 관찰을 어떻게 압축하는지, 언제 멈추게 하는지에 따라 결과가 달라집니다. 모델 단독 benchmark는 이 차이를 거의 보지 못합니다.
둘째, 비용 구조가 다릅니다. 일반 chat completion에서는 입력과 출력 토큰을 세면 대략적인 비용이 보입니다. 에이전트는 한 task 안에서 여러 번 모델을 부르고, 검색과 브라우징과 코드 실행을 반복하며, 실패할수록 더 오래 돈을 씁니다. Hugging Face 발표는 실험에서 failed run이 successful run보다 20-54% 더 비쌌다고 설명합니다. 실패는 단순한 품질 문제가 아니라 청구서 문제입니다.
셋째, 도메인별 최적화가 비교를 어렵게 만듭니다. 어떤 팀은 SWE-Bench 하나에 맞춰 prompt와 tool flow를 정교하게 조정합니다. 어떤 팀은 고객 지원 benchmark에 맞춰 정책 검색을 최적화합니다. 이런 결과는 해당 도메인에서는 중요하지만, "범용 에이전트"라는 주장과는 다른 이야기입니다. Open Agent Leaderboard는 benchmark-specific tuning 없이 여러 환경을 동시에 통과하는 능력을 보려 합니다.
여섯 환경을 하나의 평가 표면으로 묶다
Open Agent Leaderboard가 선택한 benchmark 묶음은 꽤 의도적입니다. 발표 글은 SWE-Bench Verified, BrowseComp+, AppWorld, tau2-Bench Airline/Retail, tau2-Bench Telecom을 함께 묶었다고 설명합니다. 코딩, 웹 리서치, 개인 앱 조작, 항공/리테일 고객 지원, 통신 기술 지원이 한 표면에 들어옵니다. 이 조합은 "에이전트가 일반적이다"라는 주장을 한 종류의 문제로만 검증하지 않겠다는 뜻입니다.
논문은 이 과정을 위해 unified protocol을 둡니다. benchmark마다 원래의 인터페이스와 가정이 다르고, 에이전트마다 도구를 부르는 방식도 다릅니다. Claude Code는 CLI와 파일 시스템에 익숙하고, Smolagent는 Python 실행과 tool abstraction에 가깝고, ReAct 계열은 text reasoning과 tool call loop를 중심으로 움직입니다. Exgentic은 이 사이에 task, context, actions라는 공통 모양을 만들고, 각 benchmark와 agent를 같은 평가 파이프라인으로 연결합니다.
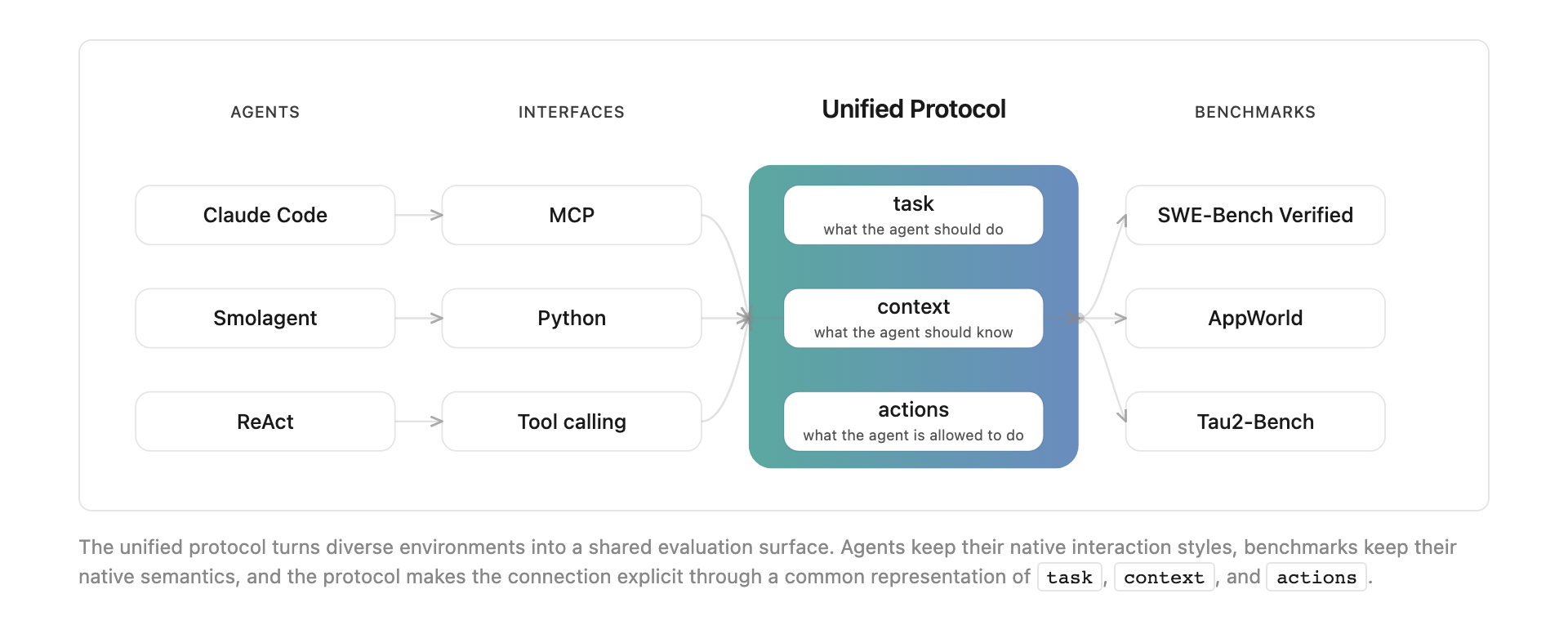
이 그림에서 중요한 것은 통일이 추상화만을 뜻하지 않는다는 점입니다. benchmark의 원래 의미를 망가뜨리지 않으면서, agent가 이해할 수 있는 형태로 task와 action space를 넘겨야 합니다. 예를 들어 SWE-Bench Verified는 실제 GitHub issue를 고치는 문제이고, tau2-Bench는 회사 정책을 따르는 고객 지원 대화입니다. 둘을 같은 "정답률"로만 밀어 넣으면 각 benchmark의 의미가 사라집니다. 반대로 각각을 완전히 별개로 두면 agent architecture를 가로질러 비교하기 어렵습니다. Exgentic의 가치는 이 중간 지대를 만들려는 시도에 있습니다.
같은 모델, 다른 에이전트, 다른 점수
가장 눈에 띄는 결과는 상위권 조합입니다. Hugging Face 글은 top 3가 모두 같은 모델을 쓰지만 agent system이 달라 성공률과 비용이 달라진다고 설명합니다. 공식 이미지와 검색 결과에서 보이는 초기 상위 조합은 OpenAI Solo + Claude Opus 4.5가 약 73% 성공률을 기록했고, Claude Code + Claude Opus 4.5와 Smolagent + Claude Opus 4.5가 뒤를 이었습니다. 숫자는 live leaderboard에서 바뀔 수 있지만, 메시지는 분명합니다. 모델을 고르는 일만으로 에이전트 품질이 끝나지 않습니다.
arXiv 논문도 같은 방향의 결론을 냅니다. 연구진은 agent architecture 선택이 같은 모델 안에서 최대 12 percentage points의 차이를 만들 수 있다고 보고합니다. 동시에 backbone model 선택이 전체 성능을 여전히 크게 좌우한다고 말합니다. 즉 "모델이 전부가 아니다"와 "모델은 여전히 매우 중요하다"가 동시에 참입니다. 이 균형이 흥미롭습니다.
개발팀에게 이 결론은 현실적입니다. 약한 모델 위에 아무리 좋은 harness를 얹어도 한계가 있습니다. 하지만 강한 모델을 쓴다고 해서 agent product가 자동으로 좋아지는 것도 아닙니다. 도구 목록이 너무 넓으면 agent가 엉뚱한 도구를 고르고, context 압축이 나쁘면 중요한 제약을 잃고, retry policy가 느슨하면 실패한 방향으로 비용만 늘어납니다. 평가해야 할 대상은 모델 호출이 아니라 실행 루프입니다.
비용-성공률 그래프가 말하는 것
Open Agent Leaderboard가 특별히 유용한 지점은 cost를 같은 화면에 둔다는 점입니다. 성공률이 2-3 percentage points 높은 조합이 항상 좋은 선택은 아닙니다. 평균 task cost가 몇 배 높다면, 실무 배포에서는 다른 결론이 나올 수 있습니다. 특히 고객 지원, 코드 리뷰, 리서치 자동화처럼 task volume이 큰 영역에서는 성공률과 비용의 Pareto frontier가 곧 제품 전략입니다.
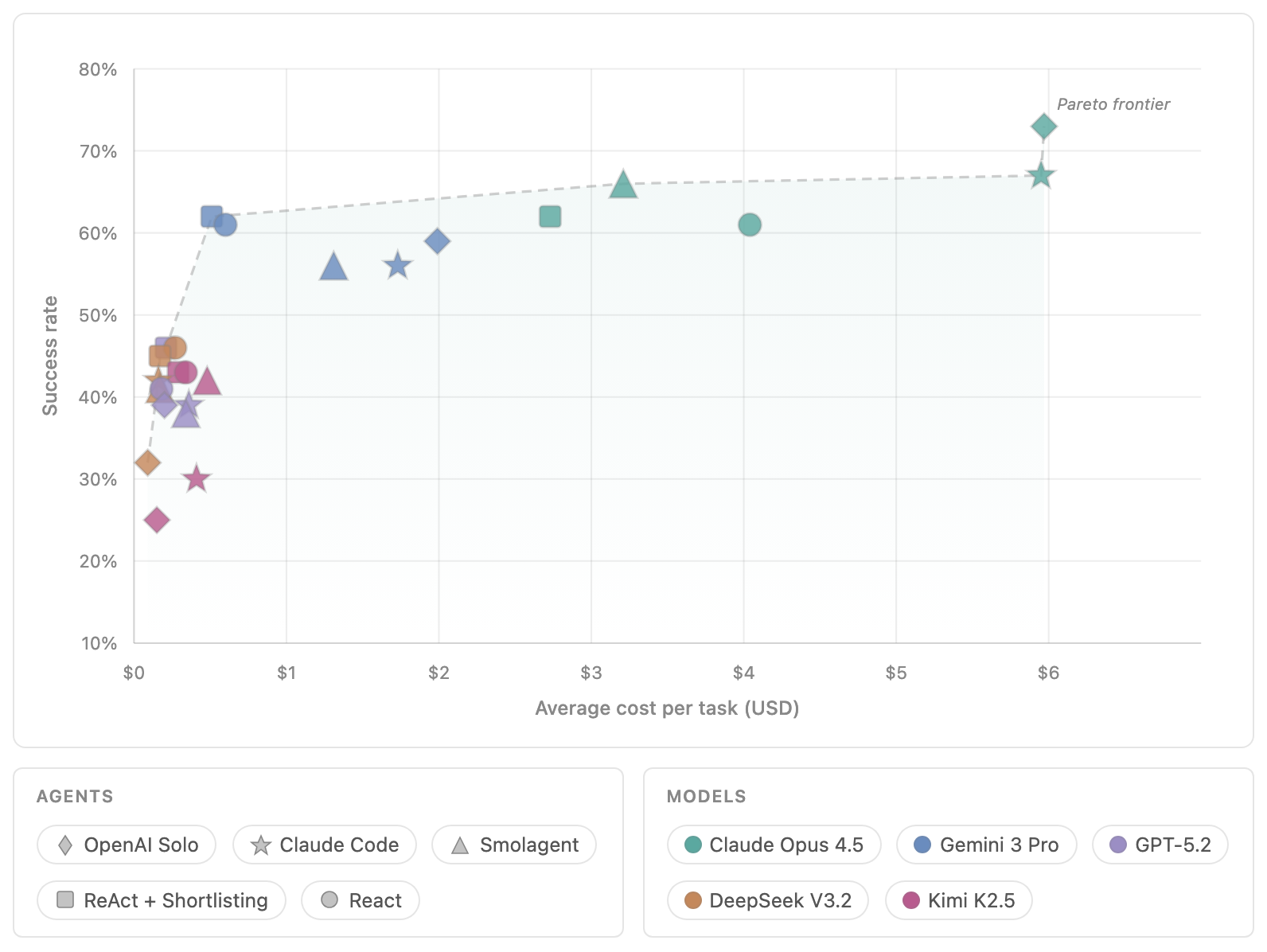
그래프의 오른쪽 위는 강하지만 비싼 조합입니다. 왼쪽 위는 더 매력적입니다. 적은 비용으로 높은 성공률을 내는 구간이기 때문입니다. 그러나 실제 선택은 단순하지 않습니다. 어떤 업무에서는 실패 비용이 너무 크기 때문에 비싼 모델을 써야 합니다. 보안 패치, 금융 거래, 법무 검토처럼 오류가 큰 손실로 이어지는 task가 그렇습니다. 반대로 초안 작성, 내부 리서치, 반복 triage처럼 사람이 후속 검토를 하는 task에서는 비용 효율이 더 중요할 수 있습니다.
이 관점은 에이전트 구매와 운영에도 영향을 줍니다. 기업이 에이전트 도구를 도입할 때 "SWE-Bench에서 몇 점입니까"만 물으면 부족합니다. "우리 task당 평균 비용은 얼마입니까", "실패한 session은 얼마나 오래 돌고 얼마를 태웁니까", "도구 호출이 많아질수록 비용이 어떻게 변합니까", "실패를 조기 중단하는 정책이 있습니까"를 함께 물어야 합니다. Open Agent Leaderboard는 이 질문을 공개 지표 쪽으로 끌어냅니다.
tool shortlisting이 보여주는 작은 구조의 힘
발표 글에서 실무적으로 중요한 대목은 tool shortlisting입니다. 연구진은 tool shortlisting, 즉 agent가 모든 도구를 매번 뒤지는 대신 관련 도구에 집중하도록 돕는 방식이 테스트한 모든 모델에서 성능을 개선했다고 설명합니다. 이 말은 에이전트 제품의 품질이 거대한 모델 교체만으로 바뀌는 것이 아니라, 도구 표면을 어떻게 설계하느냐로도 바뀐다는 뜻입니다.
이것은 최근 AI 개발팀이 겪는 문제와 맞닿아 있습니다. MCP 서버와 connector가 늘어나면서 agent가 사용할 수 있는 tool은 빠르게 많아지고 있습니다. 하지만 도구가 많아질수록 선택 비용도 커집니다. 이름이 비슷한 도구, 권한이 겹치는 도구, 부분적으로 실패하는 도구, 같은 데이터를 다른 방식으로 반환하는 도구가 한 context에 들어오면 agent는 더 똑똑해지는 것이 아니라 더 헷갈릴 수 있습니다.
따라서 agent architecture의 핵심은 "도구를 많이 붙이는 것"이 아니라 "필요한 도구를 좁혀 주는 것"입니다. 좋은 시스템은 task를 보고 관련 tool subset을 만들고, 권한과 비용을 고려해 실행 순서를 정하고, 실패하면 다른 path로 빠르게 전환합니다. 이 정도의 설계는 모델 benchmark 점수표에서는 보이지 않습니다. Open Agent Leaderboard가 agent wrapper를 분리해 보여주려는 이유가 여기에 있습니다.
공개성과 재현성은 왜 중요할까
Hugging Face 발표는 "Everything is open from day one"이라고 강조합니다. 리더보드, Exgentic code, paper, results dataset이 함께 공개됐습니다. GitHub 저장소는 Apache-2.0 라이선스이며, README는 tau2, AppWorld, BrowseComp+, SWE-Bench, BFCL 같은 benchmark와 Claude Code, Codex CLI, Gemini CLI, OpenAI MCP, SmolAgents 같은 agent를 다루는 방향을 보여줍니다. 공개 leaderboard는 단순한 순위표가 아니라 평가 harness를 재현하고 확장하라는 초대입니다.
이 지점은 에이전트 시장에서 특히 중요합니다. 에이전트는 데모로 과장하기 쉽습니다. 잘 선택된 한 task, 미리 정리된 repository, 내부자가 설계한 prompt, 실패 장면을 제거한 영상은 제품의 실제 품질을 보여주지 못합니다. 반대로 공개 harness와 trace, cost report는 다른 팀이 같은 조건에서 재실험하고 반박할 수 있는 기반을 만듭니다.
물론 공개 평가가 만능은 아닙니다. benchmark는 항상 현실의 일부만 자릅니다. 어떤 회사의 레거시 monorepo, 사내 권한 시스템, 느린 CI, 보안 정책, private API는 공개 benchmark에 들어가기 어렵습니다. 따라서 Open Agent Leaderboard의 점수를 곧바로 "우리 회사에서 이 도구가 최고"라는 결론으로 바꾸면 안 됩니다. 더 좋은 해석은 "우리 내부 eval도 모델 단독이 아니라 agent system과 비용을 함께 봐야 한다"입니다.
오픈 웨이트 모델의 일반성 문제
발표 글의 다음 단계 부분도 눈여겨볼 만합니다. launch 이후 DeepSeek V3.2와 Kimi K2.5 같은 open-weight model을 추가했고, 이들이 특정 조합에서는 경쟁력을 보이지만 frontier closed-source model보다 평균 18-29 percentage points 뒤처진다고 설명합니다. arXiv 초록은 이를 "generality sinks"라고 표현합니다. 특정 agent architecture나 benchmark에서 일관되게 무너지는 패턴이 있다는 뜻입니다.
이 결과는 오픈 모델이 쓸모없다는 말이 아닙니다. 오히려 더 정확한 질문을 만듭니다. 오픈 웨이트 모델은 어느 도메인에서, 어떤 agent wrapper와, 어떤 tool set을 붙였을 때 충분히 안정적입니까. 비용과 데이터 통제의 이점이 성공률 하락을 상쇄하는 경우는 어디입니까. 특정 benchmark에서 잘하더라도 다른 환경으로 옮기면 급격히 무너지는지 어떻게 미리 알 수 있습니까.
AI 인프라 팀에게 이 질문은 중요합니다. 모델을 self-hosting하거나 private deployment로 가져가는 결정은 규제, 보안, 비용, latency 때문에 매력적일 수 있습니다. 하지만 agent workload는 일반 chat보다 실패 표면이 넓습니다. 오픈 모델을 agent에 쓰려면 단순 추론 benchmark보다 cross-environment eval과 failure trace가 더 필요합니다.
커뮤니티 반응은 아직 작지만 방향은 분명합니다
이번 발표는 대형 모델 출시처럼 즉각적인 대중 반응을 만들지는 않았습니다. Hacker News나 Reddit에서 큰 직접 토론은 확인하지 못했습니다. 대신 보조 매체와 AI agent 커뮤니티의 요약은 대체로 같은 지점을 짚었습니다. 에이전트 평가는 모델 점수표가 아니라 전체 실행 시스템의 비교로 가야 한다는 것입니다. Awesome Agents는 backbone model choice가 성능 분산을 크게 설명한다는 쪽을 강조했고, 중국어권과 일본어권 요약 글은 공개 에이전트 평가 표준의 출발점으로 해석했습니다.
이 조용함은 오히려 자연스럽습니다. 리더보드는 제품처럼 바로 써 보는 도구가 아니라, 제품과 연구를 평가하는 기반입니다. 하지만 장기적으로는 이런 기반이 더 오래 남을 수 있습니다. 모델 이름은 몇 주마다 바뀌고, 제품 UI도 빠르게 변합니다. 반면 평가 방식은 조직의 구매 기준과 개발 프로세스에 스며듭니다. "에이전트가 좋다"는 말을 들었을 때 무엇을 요구할지 정하는 언어가 되기 때문입니다.
개발팀은 무엇을 바꿔야 하나
첫째, 내부 eval을 agent 단위로 재설계해야 합니다. 모델 A와 모델 B의 답변 품질만 비교하지 말고, 실제 tool set, 권한, sandbox, retry, memory, logging을 붙인 상태에서 task를 돌려야 합니다. 에이전트는 모델이 아니라 배포된 실행 시스템입니다.
둘째, cost를 성공률과 같은 표에 둬야 합니다. 평균 비용, p95 비용, 실패한 task의 비용, 조기 중단율, 재시도 횟수, tool call 수를 함께 기록해야 합니다. 특히 자동화가 많아질수록 "실패했지만 열심히 시도한 agent"는 운영비를 크게 키울 수 있습니다.
셋째, 실패 패턴을 분류해야 합니다. aggregate score는 편합니다. 하지만 같은 60% 성공률이라도 실패 이유는 다를 수 있습니다. 어떤 에이전트는 evidence를 건너뛰고, 어떤 에이전트는 tool을 잘못 고르고, 어떤 에이전트는 문제를 이해했지만 실행 환경을 망칩니다. remediation은 실패 유형을 알아야 가능합니다.
넷째, benchmark-specific tuning과 generality를 구분해야 합니다. 특정 고객 지원 workflow만 잘하면 되는 제품과, 여러 도메인에 배포될 internal agent platform은 평가 방식이 달라야 합니다. Open Agent Leaderboard는 후자에 가까운 질문을 던집니다. 모든 팀이 이 방식을 그대로 써야 한다는 뜻은 아니지만, "일반성"을 주장하려면 여러 환경에서의 evidence가 필요합니다.
모델 경쟁 다음의 평가 경쟁
Open Agent Leaderboard는 화려한 제품 발표가 아닙니다. 새 채팅창도 아니고, 새 foundation model도 아닙니다. 하지만 에이전트 시장에는 꽤 중요한 신호입니다. 이제 경쟁은 "우리 모델이 더 똑똑하다"에서 "우리 에이전트 시스템이 여러 환경에서, 합리적인 비용으로, 재현 가능하게 일을 끝낸다"로 이동하고 있습니다.
이 변화는 AI 개발자에게도 좋은 압력입니다. 데모 영상보다 trace가 중요해지고, benchmark 점수보다 cost-success frontier가 중요해지며, 모델 이름보다 tool interface와 failure policy가 중요해집니다. 에이전트가 실제 업무로 들어갈수록 이런 질문은 더 피하기 어려워집니다. Open Agent Leaderboard의 가장 큰 의미는 순위 자체가 아니라, 우리가 에이전트를 무엇으로 평가해야 하는지 한 단계 더 구체적인 언어를 제공했다는 점입니다.
결국 73%라는 숫자는 headline일 뿐입니다. 더 중요한 것은 그 숫자가 모델 하나의 점수가 아니라는 사실입니다. 같은 모델도 agent wrapper에 따라 달라지고, 같은 성공률도 비용에 따라 달라지며, 같은 실패도 원인에 따라 전혀 다른 개선 과제를 남깁니다. 모델만 보던 벤치마크의 시대가 끝났다고 말하기에는 아직 이르지만, 적어도 에이전트의 성적표는 더 이상 모델 이름 한 줄로 끝나지 않게 됐습니다.