88코어 Vera, 에이전트 병목이 CPU로 내려온 날
NVIDIA Vera CPU 첫 인도는 AI 에이전트 경쟁의 병목이 GPU 추론뿐 아니라 샌드박스, 툴 호출, RL 평가를 떠받치는 CPU로 이동했음을 보여줍니다.

- 무슨 일: NVIDIA가 첫 Vera CPU 시스템을 Anthropic, OpenAI, SpaceXAI, OCI에 전달했습니다.
- Vera는 NVIDIA의 첫 custom data center CPU이며, 에이전트와 RL 실행 환경을 겨냥합니다.
- 핵심: 에이전트 품질은 모델만이 아니라
tool call, sandbox, orchestration, memory bandwidth가 좌우합니다. - 숫자: NVIDIA는 88 Olympus cores, 1.2 TB/s memory bandwidth, 50% faster per-core 성능을 내세웁니다.
- Vera CPU Rack은 최대 256개 CPU와 22,500개 이상 concurrent CPU environments를 제시합니다.
NVIDIA가 2026년 5월 18일 첫 Vera CPU 시스템을 Anthropic, OpenAI, SpaceXAI, Oracle Cloud Infrastructure에 전달했다고 밝혔습니다. 발표 장면 자체는 제품 홍보처럼 보입니다. NVIDIA 임원이 서버를 들고 AI 연구소와 클라우드 고객사를 순회했고, 각 회사의 compute 담당자에게 새 CPU를 설명했습니다. 그러나 이 뉴스의 핵심은 사진 속 하드웨어가 아닙니다. AI 에이전트 경쟁의 병목이 GPU 추론만으로 설명되지 않는다는 점입니다.
Vera는 NVIDIA가 2026년 3월 GTC에서 발표한 첫 custom data center CPU입니다. NVIDIA는 Vera를 "agentic AI와 reinforcement learning을 위해 만든 CPU"라고 설명합니다. 이 문장은 과장처럼 들릴 수 있지만, 최근 AI 시스템을 보면 꽤 실무적인 말입니다. 코딩 에이전트는 코드를 생성한 뒤 컴파일하고, 테스트를 실행하고, 브라우저를 열고, 로그를 읽고, 다시 코드를 고칩니다. 리서치 에이전트는 Python 코드를 만들고, 데이터를 가져오고, 시뮬레이션을 돌리고, 실패한 실행을 재시도합니다. 모델은 GPU에서 토큰을 만들지만, 그 토큰이 실제 행동으로 바뀌는 동안에는 CPU가 계속 움직입니다.
그래서 이번 사건은 "NVIDIA가 CPU도 판다"보다 조금 더 큰 의미가 있습니다. GPU가 AI 시대의 왕좌를 차지한 뒤에도, 에이전트가 행동하기 시작하면 시스템의 다른 부분이 다시 비싸지고 중요해집니다. 특히 tool calling, sandbox execution, data loading, KV cache 관리, 코드 실행, 파일 검색, orchestration, observability는 GPU 연산과 다른 성격의 병목을 만듭니다. Vera가 겨냥하는 곳은 바로 이 회색 지대입니다.
첫 고객 명단이 말하는 것
NVIDIA 공식 블로그에 따르면 첫 Vera CPU는 금요일 Anthropic의 샌프란시스코 사무실, OpenAI의 Mission Bay 본사, SpaceXAI의 Palo Alto 사무실에 전달됐고, 다음 월요일에는 Santa Clara의 Oracle AI Customer Excellence Center에 전달됐습니다. 단순한 고객 명단으로 보기에는 구성이 흥미롭습니다. Anthropic과 OpenAI는 frontier model과 coding agent 경쟁의 중심에 있고, SpaceXAI는 reinforcement learning과 simulation pipeline을 평가하는 곳으로 소개됐으며, OCI는 hyperscale cloud provider입니다.
이 조합은 Vera가 어디에 쓰일지를 보여줍니다. Anthropic과 OpenAI에는 더 빠르고 조밀한 agent runtime이 필요합니다. 사용자가 "테스트를 고쳐줘"라고 요청하면 모델은 텍스트만 내놓지 않습니다. 저장소를 이해하고, 테스트를 돌리고, dependency를 설치하고, 실패 메시지를 읽고, 다시 패치합니다. 수천 명이 동시에 이런 작업을 요청하면 CPU 환경은 단순한 보조 장치가 아닙니다. agent sandbox를 얼마나 빨리 만들고, 얼마나 조밀하게 유지하고, 실패한 실행을 얼마나 안정적으로 회수하느냐가 서비스 품질이 됩니다.
OCI의 경우는 더 직접적입니다. NVIDIA 블로그는 OCI가 2026년부터 수십만 개 Vera CPU를 배포할 계획이라고 전했습니다. OCI 제품 담당자는 agentic AI가 대규모 sustained performance를 요구한다고 설명했습니다. 이 말은 클라우드 고객의 관점에서 중요합니다. AI 에이전트는 peak load만 큰 것이 아니라, 많은 작은 환경을 오래 붙잡고 있을 수 있습니다. 한 고객의 agent가 수십 개 tool call을 만들고, 다른 고객의 RL workflow가 수천 개 평가 환경을 만들면, 클라우드의 CPU fleet은 GPU를 먹여 살리는 배경이 아니라 과금과 품질을 결정하는 전면 계층이 됩니다.
GPU만으로는 에이전트가 움직이지 않습니다
NVIDIA는 Vera 소개에서 "AI agents don’t run on GPUs alone"이라는 취지의 설명을 반복합니다. 이 문장은 개발자에게 익숙한 현실을 하드웨어 회사의 언어로 다시 쓴 것입니다. LLM API 호출은 전체 workflow의 일부입니다. 에이전트 제품을 만들면 곧바로 다음 질문이 따라옵니다. 코드는 어디서 실행할 것인가. 파일 시스템은 어떻게 격리할 것인가. 외부 네트워크 접근은 누가 승인할 것인가. 테스트 프로세스가 멈추면 어떻게 회수할 것인가. 수천 개 병렬 실행의 로그와 artifact는 어디에 남길 것인가.
모델이 똑똑해질수록 이 질문은 줄어들지 않고 늘어납니다. 약한 모델은 애초에 많은 행동을 맡기기 어렵습니다. 강한 모델은 더 많은 행동을 맡길 수 있기 때문에 더 많은 실행 환경을 요구합니다. 코딩 에이전트가 한 번에 여러 파일을 고치고, 브라우저에서 결과를 확인하고, CI failure를 읽고, PR 설명까지 작성하면 성공 여부는 모델의 reasoning만으로 결정되지 않습니다. compile time, package install time, filesystem latency, sandbox startup, CPU scheduling이 사용자 경험에 들어옵니다.

NVIDIA technical blog의 CPU sandbox 다이어그램은 이 구조를 잘 보여줍니다. 모델이 코드를 만들고 GPU 병렬성이 출력 후보를 늘려도, 컴파일과 runtime check는 CPU sandbox에서 일어납니다. 에이전트형 AI의 실제 루프는 "모델이 답한다"가 아니라 "모델이 행동 후보를 만들고, 환경이 실행하고, 결과가 다시 모델을 고친다"에 가깝습니다. 여기서 CPU가 느리면 GPU가 놀고, sandbox가 부족하면 agent가 대기하고, memory bandwidth가 부족하면 상태 이동이 병목이 됩니다.
숫자는 CPU를 다시 전면에 세웁니다
Vera의 headline spec은 88개 NVIDIA-designed Olympus cores와 1.2 TB/s memory bandwidth입니다. NVIDIA는 full-load 기준 per-core 성능이 기존 CPU보다 50% 빠르다고 주장합니다. 제품 페이지는 Vera가 LPDDR5X memory bandwidth, low-latency Scalable Coherency Fabric, NVLink-C2C, confidential computing, Arm compatibility를 결합한다고 설명합니다. 이런 숫자는 일반 웹 서버보다 AI factory의 제어형 워크로드를 겨냥합니다.
더 눈에 띄는 숫자는 rack 단위입니다. NVIDIA는 Vera CPU Rack이 최대 256개 liquid-cooled Vera CPU를 통합해 22,500개 이상의 concurrent CPU environments를 구동할 수 있다고 설명합니다. "22,500개 환경"이라는 숫자는 에이전트 시대의 인프라 언어입니다. 과거에는 inference QPS나 GPU utilization이 중심 지표였습니다. 이제는 동시에 몇 개의 sandbox를 띄울 수 있는지, 각 환경이 독립적으로 full performance를 낼 수 있는지, 실패한 환경을 얼마나 빨리 버리고 다시 만들 수 있는지가 중요해집니다.
이 변화는 reinforcement learning에서도 나타납니다. RL post-training은 모델을 한 번 학습시키고 끝나는 작업이 아닙니다. 많은 후보 행동을 만들고, 환경에서 평가하고, 점수를 계산하고, 다시 정책을 업데이트합니다. 에이전트가 코드를 작성한다면 평가는 test run과 lint, benchmark, 실제 tool execution일 수 있습니다. 로봇이나 simulation agent라면 환경 rollout이 됩니다. 어떤 경우든 GPU는 모델 계산을 담당하지만, CPU는 환경과 검증을 떠받칩니다.
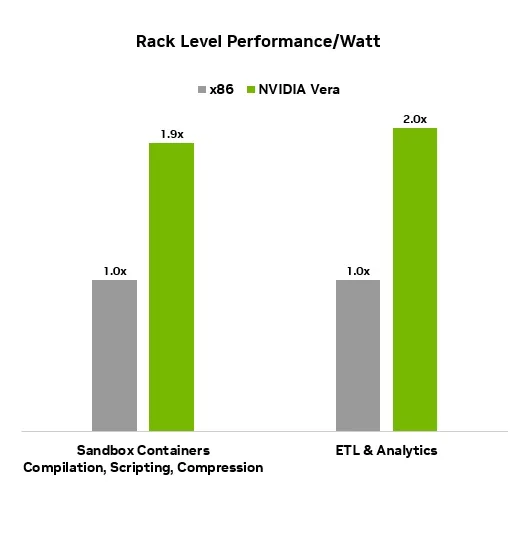
NVIDIA가 제시한 rack-level efficiency chart는 이 메시지를 더 노골적으로 밀어붙입니다. 회사는 Vera LC CPU Rack이 RL sandbox evaluation, ETL, analytics 같은 workload에서 전통적 air-cooled x86 rack 대비 2배 performance efficiency benefit을 제공한다고 주장합니다. 물론 공급사 benchmark는 독립 검증이 필요합니다. 하지만 주장 자체가 가리키는 방향은 분명합니다. 에이전트와 RL의 비용 경쟁은 GPU token throughput만이 아니라 CPU rack efficiency로도 벌어집니다.
왜 지금 CPU인가
AI 개발자 입장에서 "CPU가 중요하다"는 말은 새롭지 않습니다. 데이터 전처리, feature pipeline, embedding indexing, vector search, API 서버, queue worker는 늘 CPU를 썼습니다. 그러나 에이전트 시대의 CPU 문제는 조금 다릅니다. 단순한 backend traffic이 아니라 모델이 만든 행동을 실행하는 runtime이기 때문입니다. 이 runtime은 latency-sensitive하고, concurrency가 높고, 격리가 필요하며, 실패가 정상적인 일부입니다.
예를 들어 코딩 에이전트는 성공할 때보다 실패할 때 더 많은 CPU를 쓸 수 있습니다. 테스트가 실패하면 로그를 읽고, 다시 고치고, 다시 실행합니다. dependency 충돌이 나면 설치를 반복합니다. browser automation이 실패하면 스크린샷과 console log를 수집합니다. 이 과정은 하나의 긴 GPU inference보다 수많은 작은 CPU 작업의 묶음입니다. 사용자는 "AI가 일한다"고 느끼지만, 시스템은 shell process, compiler, test runner, filesystem, network namespace, artifact store를 계속 조정합니다.
기업 업무 에이전트도 비슷합니다. 스프레드시트를 분석하는 에이전트는 계산 엔진과 파일 파서를 사용합니다. 계약서를 읽는 에이전트는 OCR, PDF parsing, policy lookup, approval workflow를 호출합니다. 고객 지원 에이전트는 CRM, billing, knowledge base, ticketing system을 오갑니다. 모델 호출 사이사이에서 CPU는 데이터를 꺼내고, 변환하고, 권한을 확인하고, 결과를 기록합니다. agentic AI가 "답변"에서 "행동"으로 이동할수록 CPU의 역할은 보조가 아니라 제어가 됩니다.
NVIDIA의 숨은 계산
NVIDIA가 Vera를 첫 custom CPU로 밀어붙이는 이유도 여기에서 읽을 수 있습니다. GPU 판매만으로도 충분히 큰 회사가 왜 CPU를 전면에 세울까요. 첫째, GPU utilization을 높이려면 CPU 병목을 줄여야 합니다. GPU가 아무리 빨라도 데이터 이동과 orchestration이 느리면 전체 AI factory의 효율은 떨어집니다. 둘째, rack-scale system을 팔려면 CPU, GPU, DPU, NIC, switch를 한 설계로 묶는 편이 유리합니다. Vera Rubin NVL72 같은 구성은 chip이 아니라 data center를 compute unit으로 보는 전략입니다.
셋째, agent workload는 NVIDIA가 "AI factory"라는 표현을 확장하기 좋은 영역입니다. training cluster는 소수 frontier lab과 hyperscaler의 영역처럼 보일 수 있습니다. 하지만 agent sandbox, coding assistant, enterprise workflow, RL evaluation은 더 넓은 고객층으로 퍼집니다. NVIDIA가 Vera를 "coding assistants, consumer and enterprise agents"에도 맞는 CPU라고 설명하는 이유입니다. 모델을 직접 만들지 않는 회사도 에이전트 실행 계층은 필요합니다.
넷째, CPU 시장의 경쟁 구도도 바뀝니다. AMD EPYC과 Intel Xeon은 여전히 데이터센터의 중심입니다. AWS Graviton, Google Axion 같은 hyperscaler custom Arm CPU도 이미 강한 흐름입니다. NVIDIA는 GPU와 네트워크, 소프트웨어 생태계를 가진 상태에서 CPU를 끼워 넣습니다. 이는 범용 CPU 시장에 정면으로 들어간다는 뜻이면서, 동시에 AI workload 전용 rack을 더 강하게 묶겠다는 뜻입니다.
| 계층 | GPU 중심 질문 | 에이전트 시대 질문 |
|---|---|---|
| 추론 | 토큰을 얼마나 빨리 생성하는가 | tool call 사이의 대기와 상태 이동을 줄이는가 |
| 샌드박스 | 실행 환경을 별도 시스템으로 둔다 | 수천 개 환경을 빠르게 만들고 격리하는가 |
| RL 평가 | 모델 학습 throughput을 본다 | 환경 실행과 평가 루프 throughput을 함께 본다 |
| 운영 | GPU utilization과 QPS를 본다 | CPU density, memory bandwidth, failure recovery를 본다 |
개발팀이 실제로 확인할 것
이 뉴스가 곧 "모든 AI 팀은 Vera를 써야 한다"는 뜻은 아닙니다. 공급사 성능 수치는 실제 workload로 검증해야 합니다. 특히 에이전트 시스템의 병목은 제품마다 다릅니다. 어떤 팀은 LLM latency가 전부이고, 어떤 팀은 vector database가 느리며, 어떤 팀은 browser automation과 test runner가 대부분의 시간을 씁니다. Vera가 겨냥하는 문제를 이해하려면 먼저 자신의 trace를 봐야 합니다.
첫 번째 질문은 agent step의 시간 분해입니다. 전체 실행 시간 중 모델 inference, tool execution, sandbox startup, dependency install, file IO, network IO, post-processing이 각각 얼마인지 측정해야 합니다. 두 번째 질문은 concurrency입니다. peak 시간에 agent가 동시에 몇 개 환경을 만들고, 각 환경이 얼마나 오래 살아 있는지 봐야 합니다. 세 번째 질문은 failure path입니다. 에이전트는 실패를 많이 합니다. 실패한 실행이 CPU를 얼마나 붙잡고, retry가 얼마나 자주 일어나는지 모르면 비용을 계산할 수 없습니다.
네 번째 질문은 격리와 권한입니다. CPU 환경을 많이 만들 수 있어도, 그 환경이 안전하지 않으면 제품으로 쓰기 어렵습니다. 코딩 에이전트가 임의 코드를 실행한다면 filesystem, network, secret access, package install, artifact upload를 모두 제한해야 합니다. enterprise agent가 내부 시스템을 호출한다면 사용자 권한과 agent 권한을 분리해야 합니다. CPU 인프라가 강해질수록 보안 모델도 같이 따라와야 합니다.
다섯 번째 질문은 lock-in입니다. Vera는 NVIDIA의 GPU, NVLink-C2C, DPU, networking, MGX rack architecture와 함께 묶일수록 강한 이야기가 됩니다. 그만큼 특정 vendor stack에 깊이 들어갈 가능성도 커집니다. hyperscaler custom CPU, AMD/Intel 기반 rack, 독립 GPU cloud, serverless sandbox 플랫폼과 비교할 때 무엇을 얻고 무엇을 맡기는지 봐야 합니다.
한국 AI 팀에게 주는 신호
한국의 AI 스타트업과 사내 플랫폼 팀은 종종 모델 API 비용을 중심으로 예산을 짭니다. 하지만 에이전트를 제품에 넣는 순간 비용표는 달라집니다. 사용자가 한 번 요청할 때 모델 호출이 세 번, tool call이 열 번, 테스트 실행이 다섯 번, 파일 파싱이 수십 번 일어날 수 있습니다. 여기서 model token price만 보면 실제 원가를 놓칩니다.
특히 AI 코딩 도구나 업무 자동화 서비스를 만드는 팀은 CPU 계층을 조기에 설계해야 합니다. 처음에는 단일 컨테이너와 queue worker로 충분해 보일 수 있습니다. 사용자가 늘면 sandbox density, warm environment, package cache, observability, quota, cancellation, artifact retention이 모두 제품 기능이 됩니다. 그 단계에서 CPU와 memory bandwidth, filesystem 성능, network isolation은 "인프라팀의 세부 사항"이 아니라 사용자 경험의 일부입니다.
또 하나의 포인트는 on-prem과 private cloud입니다. 기업 고객은 코드와 데이터를 외부 agent runtime에 맡기기 어려울 수 있습니다. 이 경우 모델 자체보다 실행 환경을 어디에 둘지가 더 큰 판매 조건이 됩니다. OpenAI와 Dell의 on-prem Codex 협력, Anthropic의 enterprise agent 흐름, Vercel Sandbox 같은 isolated execution 제품들이 같은 질문을 다른 방식으로 풉니다. Vera는 그중 hardware foundation 쪽의 답입니다.
커뮤니티의 회의론도 필요합니다
Reddit r/hardware에서는 Vera를 두고 NVIDIA가 CPU 시장에서도 큰 매출을 만들 수 있다는 기대와, Intel/AMD CPU와의 실제 경쟁은 가격과 공급, benchmark transparency를 봐야 한다는 회의론이 함께 나왔습니다. 이 반응은 중요합니다. NVIDIA의 발표는 강한 서사를 제공합니다. 하지만 개발자가 구매 결정을 내릴 때 필요한 것은 발표 서사가 아니라 자신의 workload에서의 재현 가능한 지표입니다.
예를 들어 50% faster per-core라는 수치가 어떤 codebase compile workload, 어떤 Python sandbox, 어떤 data pipeline, 어떤 RL environment에서 같은 의미인지 확인해야 합니다. 1.2 TB/s memory bandwidth가 병목을 실제로 줄이는지도 workload에 따라 다릅니다. 22,500개 concurrent CPU environments도 환경의 크기, isolation level, storage IO, network policy에 따라 체감 가치가 달라집니다. 숫자는 방향을 보여주지만, 최종 판단은 trace와 benchmark가 해야 합니다.
결론은 CPU가 돌아왔다는 말이 아닙니다
이번 뉴스의 결론을 "CPU가 다시 중요해졌다"로 끝내면 너무 평평합니다. CPU는 항상 중요했습니다. 달라진 것은 CPU가 맡는 일이 AI 제품의 핵심 행동 루프 안으로 들어왔다는 점입니다. 모델이 계획하고, 도구를 호출하고, 코드를 실행하고, 실패를 읽고, 다시 계획하는 구조에서는 CPU가 사용자에게 보이지 않는 agent runtime이 됩니다.
Vera의 첫 인도는 그래서 상징적입니다. Anthropic과 OpenAI가 받은 것은 단순한 서버가 아니라, 에이전트 경쟁이 어디로 내려오고 있는지를 보여주는 단서입니다. 모델은 더 강해질수록 더 많은 행동을 요구합니다. 더 많은 행동은 더 많은 sandbox와 orchestration, memory movement, CPU scheduling을 요구합니다. 결국 AI 인프라의 다음 원가표는 GPU token price 옆에 CPU environment price를 적게 될 가능성이 큽니다.
개발자에게 남는 질문은 명확합니다. 우리 에이전트의 병목은 모델입니까, 실행입니까. 모델이 답을 잘하는데도 제품이 느리다면, 문제는 prompt가 아니라 sandbox일 수 있습니다. GPU 사용률이 낮은데 청구서가 높다면, 문제는 GPU가 아니라 CPU와 상태 이동일 수 있습니다. Vera가 보여준 것은 새로운 CPU 한 장이 아니라, 에이전트 시대의 성능 논쟁이 모델 밖으로 확장됐다는 사실입니다.