3억5500만 달러 Modal, 에이전트 컴퓨트의 새 원가표
Modal의 Series C는 AI 에이전트 경쟁이 모델 밖 샌드박스, GPU 스냅샷, 실행 권한 인프라로 이동했음을 보여줍니다.

- 무슨 일: Modal이 3억5500만 달러 Series C와 46억5000만 달러 post-money valuation을 발표했습니다.
- 회사는 2025년 9월 이후 5배 성장했고 annualized revenue가 3억 달러를 넘었다고 밝혔습니다.
- 핵심: 이번 라운드는 GPU 임대보다
Sandboxes, RL, 저지연 추론, 에이전트 런타임의 가격표에 가깝습니다. - 주의점: serverless GPU는 만능이 아니며, 모델 weight와 CUDA state를 누가 얼마나 빨리 재사용하느냐가 실제 비용을 가릅니다.
- AI 팀은 모델 API 비용뿐 아니라 실행 환경, 권한, cold start, 관측성을 함께 계산해야 합니다.
Modal이 2026년 5월 21일 3억5500만 달러 규모의 Series C를 발표했습니다. 회사가 공개한 post-money valuation은 46억5000만 달러입니다. 라운드는 General Catalyst와 Redpoint가 주도했고, Menlo, Bain Capital Ventures, Accel이 신규 투자자로 참여했습니다. Modal은 2025년 9월 이후 5배 성장했으며 annualized revenue가 3억 달러를 넘었다고 밝혔습니다.
표면만 보면 또 하나의 AI 인프라 유니콘 투자 뉴스처럼 보입니다. 하지만 Modal이 발표문에서 강조한 단어를 보면 조금 다른 그림이 나옵니다. 회사는 자신을 단일 목적 GPU 클라우드가 아니라 AI 워크로드용 cloud라고 설명합니다. 그 안에는 low-latency elastic inference, dynamic agent runtimes, reinforcement learning, massive batch jobs가 함께 들어갑니다. 즉 이번 라운드의 핵심은 "GPU가 비싸니 GPU 회사를 산다"가 아니라 "AI 제품의 병목이 모델 호출 밖 실행 계층으로 이동하고 있다"에 가깝습니다.
이 차이는 개발자에게 중요합니다. 2023년과 2024년의 AI 앱은 대체로 frontier API를 호출하고, 프롬프트를 조정하고, 결과를 저장하는 구조였습니다. 2026년의 AI 앱은 더 복잡합니다. 코딩 에이전트는 untrusted code를 실행해야 하고, 연구 에이전트는 수천 개 실험 환경을 병렬로 돌려야 하며, 상품 추천이나 고객 응대 에이전트는 지연시간이 사용자 경험을 바로 망가뜨리지 않는 범위 안에서 도구를 호출해야 합니다. 모델 성능이 올라갈수록 모델 밖 인프라가 더 선명하게 드러나는 역설이 생깁니다.
숫자가 말하는 것
Modal의 공식 발표에서 가장 먼저 눈에 띄는 숫자는 3억5500만 달러와 46억5000만 달러입니다. 그러나 더 중요한 숫자는 revenue와 workload입니다. Modal은 2025년 9월 이후 5배 성장했고 annualized revenue가 3억 달러를 넘었다고 밝혔습니다. Reuters가 재게시된 보도에서 전한 CEO Erik Bernhardsson의 설명에 따르면, annualized revenue는 2025년 9월 약 6000만 달러에서 약 3억 달러로 늘었습니다. 같은 기사에서 Modal이 연결하는 cloud company 수는 지난해 5곳에서 13곳으로 늘었다고 설명됩니다.
이것은 AI 컴퓨트 시장의 수요가 단순히 "더 많은 GPU"로만 설명되지 않는다는 뜻입니다. GPU가 부족하고 비싼 것은 맞습니다. 하지만 AI 제품을 운영하는 팀이 실제로 사려는 것은 H100 몇 장이 아니라 "내 워크로드가 튈 때 얼마나 빨리 뜨는가", "실패한 에이전트를 격리할 수 있는가", "RL 실험과 production inference를 같은 운영 문법으로 다룰 수 있는가", "개발자가 Kubernetes와 이미지 캐시, 모델 weight 로딩을 직접 붙잡지 않아도 되는가"입니다.
Modal은 이 요구를 "AI era의 새 infrastructure layer"라고 부릅니다. 표현은 다소 크지만, 방향은 분명합니다. Open-weight 모델이 production quality에 도달하고, vLLM과 SGLang 같은 inference engine이 성숙하면, 팀들은 frontier API만 쓰는 구조에서 벗어나 자기 모델을 fine-tune하고, latency와 throughput을 직접 조정하고, 비용을 자신들의 제품 곡선에 맞추려 합니다. Modal은 이 흐름을 "frontier APIs to model ownership"이라고 정리했습니다.
샌드박스가 투자 설명서의 중심에 들어온 이유
이번 발표에서 특히 흥미로운 부분은 Sandboxes입니다. Modal은 2023년부터 사용자가 AI-generated code를 Modal에서 실행하는 흐름을 보기 시작했고, 그래서 untrusted code를 위한 isolated environment를 first-class primitive로 만들었다고 설명합니다. 그리고 최근 6개월 동안 에이전트는 runtime이 있을 때 훨씬 강력해진다는 점이 명확해졌다고 말합니다.
이 대목은 코딩 에이전트와 업무 에이전트의 공통 병목을 짚습니다. 에이전트가 단순히 텍스트를 반환하는 수준이면 일반 API 호출이면 충분합니다. 하지만 에이전트가 파일을 읽고, 코드를 실행하고, 패키지를 설치하고, 웹 요청을 보내고, 테스트를 돌리고, 결과물을 다시 수정하려면 실행 환경이 필요합니다. 그 실행 환경은 빠르게 떠야 하고, 격리되어야 하며, 비용이 과도하게 튀지 않아야 하고, 실패했을 때 추적 가능해야 합니다.
이 요구는 개발자 도구에서 먼저 보입니다. 코딩 에이전트가 PR을 만들려면 저장소와 의존성을 갖춘 작업 공간이 있어야 합니다. 보안 팀은 그 공간에서 어떤 네트워크 요청과 파일 접근이 일어났는지 알고 싶어 합니다. 제품 팀은 사용자가 "고쳐줘"라고 눌렀을 때 몇 분씩 기다리지 않기를 바랍니다. 결국 에이전트의 품질은 모델만으로 결정되지 않습니다. 모델이 행동할 수 있는 환경의 latency, 권한 모델, 스냅샷, 로그, 재현성이 품질의 일부가 됩니다.
Modal이 공식 발표에서 인용한 고객 사례도 이 방향을 가리킵니다. Cognition은 reinforcement learning infrastructure와 production inference가 같은 플랫폼에서 돌아간다고 말했고, DoorDash는 local business를 위한 agentic commerce를 scale하려면 harness control, scale, reliability가 필요하다고 설명했습니다. 여기서 "harness"라는 단어가 중요합니다. 에이전트가 스스로 행동하는 것처럼 보여도, 실제 제품에서는 그 행동을 감싸는 실행 하네스가 있어야 합니다. 테스트, 제한, 승인, 관측, 롤백이 모두 하네스의 일부입니다.
GPU 클라우드가 아니라 cold start와 state의 문제
Modal이 투자 발표 며칠 전 공개한 기술 글은 이번 라운드를 읽는 데 좋은 배경입니다. 글의 제목은 "How we achieved truly serverless GPUs"입니다. Modal은 inference workload가 training보다 훨씬 변동성이 크다고 설명합니다. 훈련은 대체로 계획된 대규모 작업이지만, 추론 수요는 사용자의 행동, 시장 이벤트, 소셜 트래픽, 제품 캠페인에 따라 갑자기 튑니다. 그래서 serverless 모델이 잘 맞아 보입니다. 문제는 GPU에서 serverless가 CPU 웹 함수처럼 쉽지 않다는 점입니다.
Modal은 naive한 방식으로 B200에서 billion-parameter LLM inference server를 새로 띄우면 수십 분이 걸리거나 GPU availability 때문에 더 오래 멈출 수 있다고 설명합니다. 이 비용의 상당 부분은 애플리케이션 이미지, 모델 weight, CPU 초기화, GPU-side initialization, CUDA graph, compiler artifact 같은 상태를 만드는 데서 나옵니다. 사용자는 "요청이 들어오면 GPU를 붙이면 되지"라고 생각하지만, 실제 시스템은 "이미 필요한 상태가 어디까지 준비되어 있는가"에 의해 지연시간이 갈립니다.
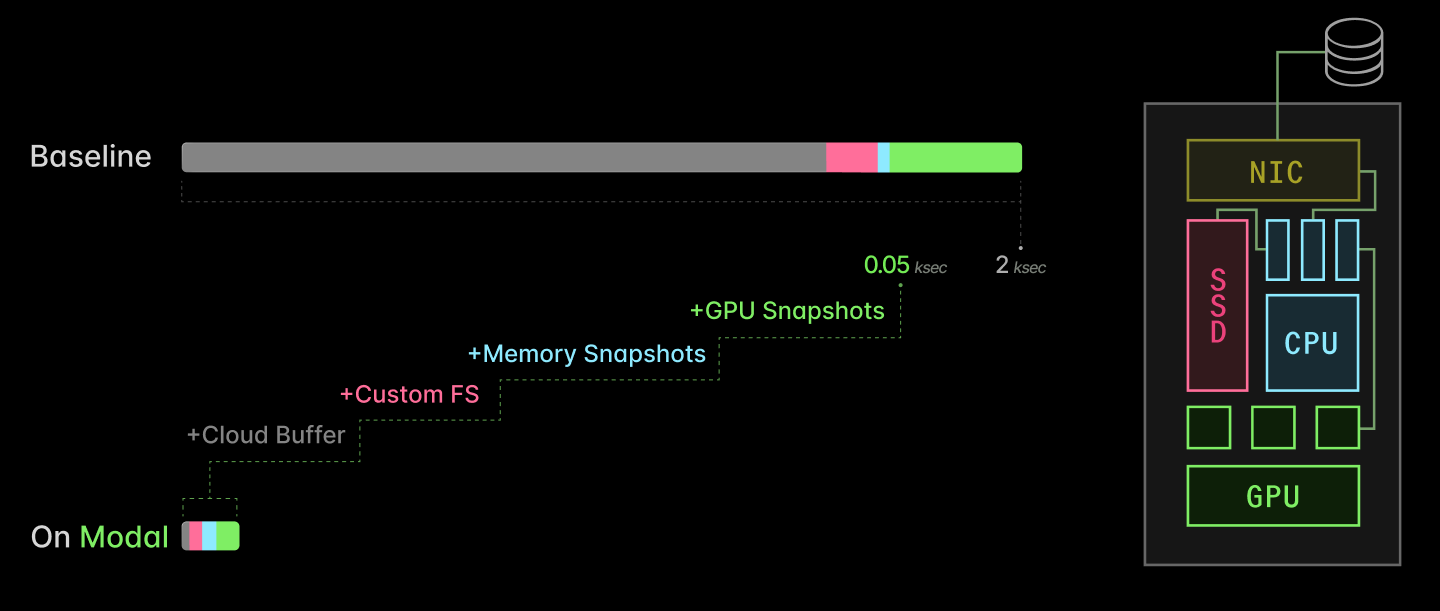
Modal은 이 문제를 네 가지 재료로 나눕니다. cloud buffers는 건강한 idle GPU를 작은 버퍼로 유지합니다. custom filesystem은 container image를 content-addressed cache에서 lazy하게 제공합니다. process checkpoint/restore는 CPU-side initialization을 memory restore로 건너뜁니다. CUDA checkpoint/restore는 GPU device memory와 CUDA context 쪽 초기화를 줄입니다. Modal은 이 조합으로 AI inference server replica scaling을 여러 kiloseconds에서 tens of seconds로 낮춘다고 주장합니다. 같은 글에서는 baseline 2k seconds에 가까운 시작을 약 50초로 줄이는 도표도 제시합니다.
이 기술적 세부가 왜 뉴스 가치가 있을까요. AI 에이전트는 종종 긴 대화보다 짧고 많은 실행을 만듭니다. 코드 한 줄을 고치기 위해 테스트 환경을 띄우고, 실패하면 다시 띄우고, 다른 브랜치에서 또 띄웁니다. RL은 수천 개 환경을 병렬로 돌립니다. 문서 처리와 멀티모달 추론은 고객이 큰 파일 묶음을 올리는 순간 갑자기 peak load를 만듭니다. 이 모든 워크로드에서 cold start는 단순한 UX 문제가 아니라 unit economics 문제입니다.
"상태를 어디에 둘 것인가"가 새 경쟁축입니다
개발자 커뮤니티의 serverless GPU 논의에서도 비슷한 지적이 반복됩니다. hosted inference provider를 비교하는 LocalLLaMA 토론에서 한 사용자는 대부분의 serverless GPU setup이 worker가 회전하거나 traffic spike가 올 때 model weights를 다시 로드하거나 warm 상태를 유지해야 한다고 지적했습니다. 또 다른 댓글은 state-aware scheduling이 빠져 있으면 autoscaling pod와 loaded model scheduling은 같지 않다고 말합니다. VRAM에 올라간 weight, 초기화된 CUDA kernel, compiled graph, KV cache, memory residency가 모두 상태라는 설명입니다.
이 반응은 Modal의 주장을 그대로 받아들이라는 뜻이 아닙니다. 오히려 검증해야 할 질문을 명확히 해 줍니다. "serverless GPU"라는 말만으로는 부족합니다. 어떤 상태를 스냅샷으로 보존하는지, 어떤 상태는 다시 만들어야 하는지, snapshot restore가 모델 크기와 GPU 세대에 따라 어떻게 달라지는지, multi-GPU와 long-running stateful agent에서 제약은 무엇인지 봐야 합니다. Modal의 기술 글도 현재 GPU snapshot이 single GPU restriction을 갖는다고 밝히며, 주로 few GB에서 few tens of GB 모델 크기의 use case에 맞는다고 설명합니다.
따라서 실무 팀이 이번 뉴스를 보고 얻을 교훈은 "Modal을 쓰라"가 아닙니다. 더 정확한 교훈은 "AI 앱의 cost model을 모델 토큰 가격표만으로 계산하면 안 된다"입니다. agent runtime 비용, sandbox isolation, startup latency, loaded state reuse, GPU allocation utilization, 실패한 실행의 재시도 비용, observability까지 포함해야 합니다. 특히 고객-facing 에이전트라면 p90 latency와 tail latency가 제품 신뢰를 결정합니다.
| 계층 | 과거의 기본 질문 | 에이전트 시대의 질문 |
|---|---|---|
| 모델 | 어떤 API가 가장 똑똑하고 저렴한가 | 언제 API를 쓰고 언제 자체 모델을 운영할 것인가 |
| 추론 | GPU를 몇 장 예약할 것인가 | spike를 tail latency 없이 흡수할 수 있는가 |
| 실행 | 컨테이너에서 코드를 실행할 수 있는가 | untrusted agent code를 빠르고 안전하게 격리하는가 |
| 상태 | 이미지와 의존성을 캐시하는가 | weight, CUDA graph, memory state를 재사용하는가 |
| 권한 | 사용자별 API key를 분리하는가 | 에이전트에게 필요한 capability만 줄 수 있는가 |
왜 지금 투자금이 몰리는가
AI 인프라 투자는 2024년과 2025년에 이미 과열돼 보였습니다. 그런데 2026년에 다시 Modal 같은 회사가 큰 valuation을 받는 이유는 수요의 모양이 바뀌었기 때문입니다. 초기 생성형 AI 수요는 주로 API token과 training compute로 설명됐습니다. 지금은 agentic coding, document automation, multimodal extraction, RL post-training, synthetic data generation, robotics inference처럼 서로 다른 모양의 workload가 늘고 있습니다.
이 워크로드는 공통적으로 "계산을 어디에서 얼마나 오래 붙잡고 있을 것인가"라는 질문을 어렵게 만듭니다. 예를 들어 코딩 에이전트는 대부분의 시간에 idle일 수 있지만, 한 번 실행되면 repo clone, dependency install, test, browser automation, artifact upload를 해야 합니다. 문서 처리 서비스는 평소에는 조용하다가 고객이 대량 문서를 업로드하는 순간 수백 개 GPU를 요구할 수 있습니다. RL 실험은 품질 개선을 위해 training, evaluation, inference, sandboxed environment가 한 루프로 묶입니다.
Modal은 이 모든 것을 같은 primitive 위에서 다룰 수 있다고 주장합니다. 회사의 표현을 빌리면 elastic compute, safe isolation, programmatic control입니다. 이 세 단어는 AI 에이전트 인프라의 최소 요건처럼 보입니다. 에이전트가 실제 업무를 수행하려면 compute가 탄력적으로 붙어야 하고, 잘못된 행동을 격리해야 하며, 사람이 만든 UI가 아니라 코드로 제어할 수 있어야 합니다.
hyperscaler와 다른 지점
그렇다면 AWS, Google Cloud, Azure가 이미 GPU와 container, serverless를 제공하는데 Modal 같은 독립 인프라 회사가 왜 필요할까요. 답은 "primitive의 조합"에 있습니다. hyperscaler는 원재료가 많습니다. GPU instance, object storage, container orchestration, IAM, logging, network를 제공합니다. 하지만 AI 팀이 원하는 것은 종종 이 원재료를 조합해 만든 더 높은 수준의 실행 문법입니다.
Modal은 Python function decorator나 sandbox API 같은 개발자 경험으로 이 조합을 감춥니다. 물론 이것은 tradeoff를 만듭니다. 특정 provider의 abstraction에 올라타면 세밀한 제어와 비용 최적화의 일부를 맡기는 셈입니다. 반대로 자체 Kubernetes와 GPU pool을 운영하면 제어권은 높아지지만 팀이 infrastructure tax를 직접 냅니다. Modal이 말하는 "mental overhead가 사라진다"는 고객 인용은 바로 이 tradeoff의 한쪽을 보여줍니다.
AI 팀이 선택해야 할 기준은 명확합니다. 일정한 대규모 수요가 있고 GPU를 장기간 포화시킬 수 있다면 자체 cluster나 committed capacity가 더 나을 수 있습니다. 반대로 workload가 spiky하고, 다양한 모델과 실행 환경을 빠르게 바꿔야 하며, 에이전트나 RL처럼 sandbox 수요가 많다면 Modal류의 platform이 비용을 줄일 가능성이 있습니다. 여기서 비용은 청구서뿐 아니라 팀의 운영 복잡도와 출시 속도를 포함합니다.
권한 모델이 다음 관문입니다
Modal은 앞으로의 계획에서 granular RBAC를 언급했습니다. 고객이 에이전트에게 risk 없이 capability를 줄 수 있도록 하겠다는 설명입니다. 이 지점은 중요합니다. 에이전트 인프라가 실제 기업 환경으로 들어가면 "코드를 실행할 수 있다"보다 "무엇을 실행할 수 있고 무엇은 못 하는가"가 더 큰 문제가 됩니다.
코딩 에이전트는 dependency 설치를 위해 네트워크가 필요할 수 있습니다. 하지만 같은 네트워크 권한이 외부로 secret을 유출하는 통로가 될 수도 있습니다. 문서 처리 에이전트는 object storage를 읽어야 하지만, 고객 간 데이터 경계를 넘어가면 안 됩니다. RL agent는 수천 개 sandbox를 만들 수 있어야 하지만, 예산과 quota를 통제하지 않으면 비용 사고가 납니다. 결국 agent runtime은 compute 제품이면서 security product가 됩니다.
이 관점에서 Modal의 Series C는 최근 AI 업계의 여러 흐름과 연결됩니다. 코딩 에이전트는 더 많은 코드를 작성하고, enterprise agent는 더 많은 내부 시스템을 호출하며, AI 연구 자동화는 더 많은 실험을 스스로 실행합니다. 이때 공통으로 필요한 것은 모델이 아니라 실행 통제면입니다. 누가 어떤 capability를 갖고, 어느 sandbox에서, 어떤 data plane으로, 얼마나 오래 실행했는지를 추적해야 합니다.
한국 개발팀이 볼 포인트
한국의 AI 스타트업과 사내 AI 플랫폼 팀에도 이 뉴스는 실용적인 질문을 던집니다. 첫째, 우리 제품의 AI 비용을 token 단가로만 보고 있지 않은지 점검해야 합니다. 사용자가 느끼는 지연시간은 LLM 응답 시간만이 아니라 pre-processing, tool execution, sandbox startup, post-processing, retry까지 합쳐집니다. 둘째, 에이전트가 코드를 실행하거나 외부 서비스를 호출한다면 sandbox와 권한 모델을 제품 초기부터 설계해야 합니다.
셋째, open-weight 모델을 운영하려는 팀은 "모델을 다운로드해 vLLM으로 띄운다" 이후의 비용을 봐야 합니다. model weight loading, graph compilation, autoscaling, idle capacity, region placement, observability, rollback이 모두 운영 비용입니다. 넷째, provider를 고를 때는 public benchmark보다 자신의 workload trace를 넣어 봐야 합니다. 문서 처리, 음성 변환, 이미지 생성, 코딩 에이전트, RL은 peak-to-average ratio와 state reuse 패턴이 서로 다릅니다.
Modal이 모든 답이라는 뜻은 아닙니다. 오히려 이번 투자는 답이 하나로 정리되지 않았다는 신호입니다. RunPod, Baseten, Replicate, Together AI, Fireworks AI, CoreWeave, hyperscaler ML platform, Vercel Sandbox, E2B 같은 실행 환경이 서로 다른 지점에서 경쟁합니다. 어떤 곳은 hosted inference에 강하고, 어떤 곳은 sandbox developer experience에 강하며, 어떤 곳은 raw GPU capacity와 enterprise 계약에 강합니다.
결론은 모델 밖에 있습니다
AI 뉴스는 보통 새 모델과 benchmark를 중심으로 움직입니다. 그러나 실제 제품의 병목은 점점 모델 밖으로 이동합니다. Modal의 3억5500만 달러 Series C는 이 이동을 숫자로 보여줍니다. 투자자들이 산 것은 GPU 자체라기보다 GPU를 에이전트와 RL, 추론, 샌드박스가 쓸 수 있는 실행 계층으로 바꾸는 능력입니다.
개발자 입장에서 이번 뉴스의 핵심 질문은 단순합니다. "우리 AI 시스템에서 비싼 것은 모델인가, 실행인가?" 초기에는 모델이 전부처럼 보입니다. 시간이 지나면 데이터 이동, cold start, sandbox 격리, 권한, 관측성, retry, human approval이 비용표에 올라옵니다. Modal은 바로 그 비용표를 제품화하고 있습니다. 그래서 이번 라운드는 AI 인프라 시장의 또 다른 funding headline이 아니라, 에이전트 시대의 컴퓨트가 어디에서 과금되고 어디에서 차별화되는지를 보여주는 사건입니다.