Mistral 3 675B, 오픈 모델 전쟁의 새 기준선
Mistral 3는 675B MoE와 3B·8B·14B 엣지 모델을 Apache 2.0으로 묶어 오픈 AI의 경쟁축을 성능에서 배포로 옮깁니다.

- 무슨 일: Mistral AI가
Mistral 3제품군을 공개했습니다.- 핵심은 675B total, 41B active MoE인 Mistral Large 3와 3B·8B·14B Ministral 3를 한 묶음으로 낸 점입니다.
- 의미: 오픈 모델 경쟁이 단일 벤치마크가 아니라 라이선스, 로컬 배포, 추론 비용, 엣지 실행으로 이동합니다.
- 개발자 영향: Apache 2.0, vLLM, Hugging Face, 256k 컨텍스트, function calling이 결합되며 사내 모델 운영 선택지가 넓어집니다.
- 단, 공개 벤치마크는 Mistral 측 자료가 중심이므로 독립 재현과 실제 워크로드 검증이 필요합니다.
Mistral AI가 Mistral 3를 공개했습니다. 표면적으로는 새 오픈 모델 발표입니다. 하지만 이번 발표의 뉴스 가치는 "또 하나의 모델이 나왔다"에 있지 않습니다. Mistral은 675B 총 파라미터의 대형 sparse MoE 모델과 3B, 8B, 14B 크기의 엣지 모델을 같은 제품군으로 묶었습니다. 그리고 모두 Apache 2.0 라이선스로 공개했습니다.
이 조합이 중요합니다. 2026년 모델 경쟁은 단순히 가장 큰 모델 하나가 벤치마크에서 몇 점을 받았는지로 설명하기 어렵습니다. 기업과 개발자는 모델을 어디서 실행할 수 있는지, 어떤 라이선스로 쓸 수 있는지, 사내 데이터와 함께 운영할 수 있는지, GPU 예산에 맞는지, 툴 호출과 JSON 출력이 안정적인지, 한국어 같은 비영어권 언어에서 충분히 쓸 만한지까지 함께 봅니다. Mistral 3는 이 질문들을 한 번에 겨냥합니다.
이번 발표에서 가장 눈에 띄는 숫자는 Mistral Large 3의 675B total parameters와 41B active parameters입니다. 전체 모델은 거대하지만 매 토큰에서 모든 파라미터를 쓰지 않는 MoE 구조입니다. Mistral은 Large 3를 Mixtral 계열 이후 다시 내놓은 대형 MoE 모델로 설명합니다. 동시에 이 모델을 폐쇄형 API가 아니라 오픈 웨이트, Apache 2.0 라이선스, 여러 배포 경로로 밀고 있습니다.
하지만 Mistral 3의 더 흥미로운 부분은 큰 모델 옆에 작은 모델을 같이 둔 점입니다. Ministral 3는 3B, 8B, 14B 크기로 나오며 base, instruct, reasoning 변형을 갖습니다. Mistral은 이 작은 모델들이 이미지 이해, 다국어, 에이전트식 툴 사용, JSON 출력, 긴 컨텍스트를 지원한다고 말합니다. Hugging Face의 Ministral 3 14B Instruct 모델 카드는 13.5B 언어 모델과 0.4B 비전 인코더 구성을 적고, FP8 instruct 버전이 24GB VRAM에 맞을 수 있다고 설명합니다.
이것은 개발자에게 꽤 현실적인 메시지입니다. 프론티어 모델은 여전히 클라우드와 대형 GPU 클러스터에서 돌아갑니다. 그러나 많은 기업 워크로드는 모든 요청을 가장 비싼 모델에 보낼 수 없습니다. 고객 데이터가 민감한 경우 외부 API로 보낼 수 없는 요청도 있습니다. 제품 내부에서 수천 번 반복 호출되는 분류, 추출, 문서 분석, 로컬 에이전트 작업은 작은 모델의 비용 구조가 중요합니다. Mistral은 Large 3로 프론티어급 존재감을 확보하고, Ministral 3로 실제 배포 면적을 넓히려는 전략을 택했습니다.
675B 모델보다 중요한 것은 묶음입니다
대형 모델 발표는 보통 하나의 주인공을 중심으로 돌아갑니다. 이번에는 조금 다릅니다. Mistral Large 3가 헤드라인을 가져가지만, 발표 구조는 "한 모델"보다 "제품군"에 가깝습니다. Large 3는 대형 오픈 모델 경쟁에 들어가고, Ministral 3는 로컬과 엣지, 사내 배포, 작은 에이전트 런타임을 겨냥합니다.
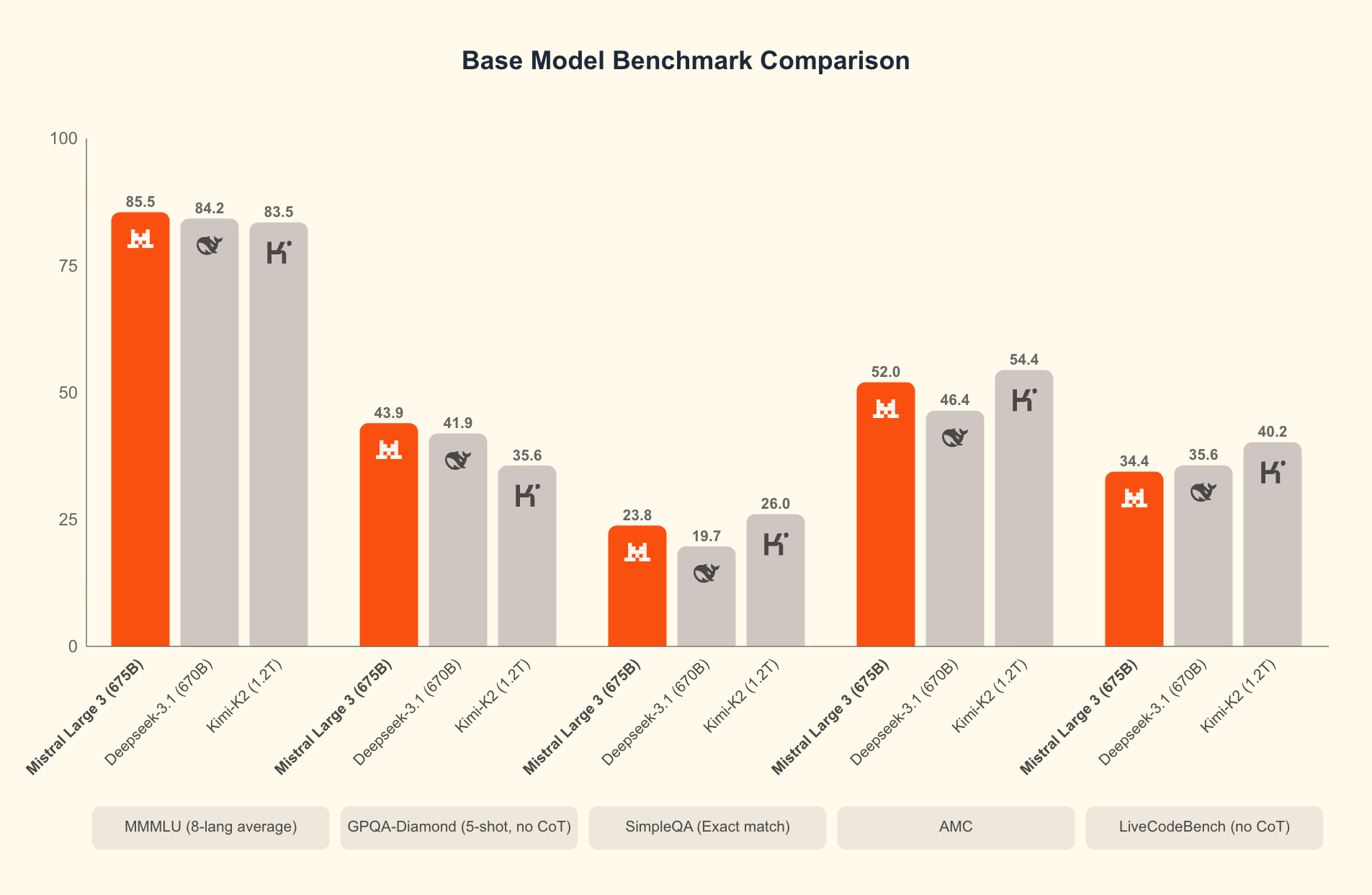
Mistral 공식 발표는 Large 3가 LMArena의 OSS non-reasoning models 카테고리에서 2위, 전체 OSS 모델 중 6위로 데뷔했다고 말합니다. 발표 페이지의 차트는 Mistral Large 3를 DeepSeek 3.1, Kimi K2 같은 대형 오픈 모델과 비교합니다. 이 비교는 신중히 읽어야 합니다. 벤치마크는 모델의 일부 성능을 보여주지만, 사용자가 실제로 겪는 품질은 프롬프트 유형, 언어, 도메인, 툴 사용, 지연 시간, 시스템 프롬프트 준수, 추론 비용에 따라 달라집니다.
그럼에도 이번 발표가 의미 있는 이유는 분명합니다. Mistral은 오픈 모델을 "싸지만 약한 대안"으로 포지셔닝하지 않습니다. Large 3는 대형 MoE로 프론티어 모델의 영역을 건드리고, Ministral 3는 작은 모델이 실제 제품 안에서 돌아갈 수 있는 경로를 제시합니다. 오픈 모델이 단순히 연구자용 체크포인트나 취미 프로젝트가 아니라, 기업의 배포 전략 안으로 들어가려면 이 두 축이 함께 필요합니다.
폐쇄형 모델은 API 경험이 단순합니다. 모델 제공사가 서빙, 업데이트, 안전 정책, 라우팅, 비용 청구를 모두 감춥니다. 반대로 오픈 모델은 자유도가 높지만 운영 부담도 큽니다. 어떤 양자화 포맷을 쓸지, 어떤 서빙 엔진을 쓸지, 컨텍스트 길이를 어디까지 열지, GPU 메모리를 어떻게 쪼갤지, 어떤 보안 경계 안에 둘지 직접 결정해야 합니다. Mistral 3 발표에서 NVIDIA, vLLM, Red Hat, Hugging Face, Bedrock, Azure Foundry, OpenRouter, Fireworks, Together AI 같은 배포 경로가 반복되는 이유가 여기에 있습니다.
Apache 2.0은 기능만큼 큰 제품 메시지입니다
Mistral 3 전체 제품군이 Apache 2.0 라이선스로 공개됐다는 점은 기술 사양과 같은 무게로 봐야 합니다. 오픈 모델이라는 말은 종종 애매하게 쓰입니다. 가중치는 공개됐지만 상업 이용 제약이 있거나, 특정 규모 이상 기업에는 별도 조건이 붙거나, 파생 모델 배포가 제한되거나, 학습 데이터와 평가 절차는 닫혀 있는 경우가 많습니다. Apache 2.0은 개발자와 기업 입장에서 훨씬 명확한 신호입니다.
물론 라이선스가 모든 문제를 해결하지는 않습니다. 모델을 실제로 운영하려면 여전히 안전성 평가, 개인정보 처리, 데이터 위치, 프롬프트 로깅, 출력 검수, 취약점 대응, 모델 업데이트 정책이 필요합니다. 하지만 라이선스가 명확하면 사내 승인 절차가 달라집니다. 법무와 보안팀은 "이 모델을 제품에 넣어도 되는가"라는 첫 질문을 더 빨리 통과시킬 수 있습니다. AI 인프라 팀은 API 종속성을 줄이고, 특정 리전이나 온프레미스 환경에 모델을 배치할 여지를 가집니다.
이 지점에서 Mistral 3는 최근 오픈 모델 경쟁과 연결됩니다. 중국의 Qwen, DeepSeek, Kimi, Z.ai GLM 계열은 성능과 비용에서 강한 압력을 만들고 있습니다. Meta의 Llama 생태계는 배포 범위와 파생 모델 수에서 영향력이 큽니다. Google Gemma 계열은 작은 모델과 엣지 배포에서 계속 존재감을 냅니다. Mistral은 여기에 유럽 기반 기업, Apache 2.0, 엔터프라이즈 커스텀 트레이닝, 다국어, 멀티모달, MoE라는 카드를 겹쳐 놓습니다.
개발자 관점에서 이 경쟁은 좋은 일입니다. 단일 API 사업자에 종속되지 않아도 되고, 비용과 통제권을 기준으로 모델을 고를 수 있습니다. 동시에 선택의 복잡성도 커집니다. "가장 똑똑한 모델 하나"를 고르는 시대에서 "이 작업은 어떤 모델, 어떤 크기, 어떤 배포 위치, 어떤 라이선스가 맞는가"를 설계하는 시대로 이동하고 있습니다.
작은 모델은 더 이상 보조 배역이 아닙니다
Ministral 3가 중요한 이유는 작은 모델이 더 이상 단순한 fallback이 아니기 때문입니다. 3B, 8B, 14B 모델은 과거라면 "큰 모델을 못 쓸 때 쓰는 타협안"에 가까웠습니다. 지금은 다릅니다. 제품 안에서 매일 수천만 번 호출되는 작업, 개인정보가 포함된 내부 문서 처리, 로컬 장치에서 돌아가는 음성·비전·에이전트 흐름, 네트워크가 불안정한 현장 환경에서는 작은 모델이 주 모델이 될 수 있습니다.
Hugging Face 모델 카드 기준 Ministral 3 14B Instruct는 256k 컨텍스트를 지원합니다. 또한 영어, 프랑스어, 스페인어, 독일어, 이탈리아어, 포르투갈어, 네덜란드어, 중국어, 일본어, 한국어, 아랍어를 포함한 다국어를 명시합니다. native function calling과 JSON output도 주요 기능으로 적혀 있습니다. 이 조합은 단순 채팅보다 에이전트와 구조화된 업무 자동화에 가깝습니다.
여기서 24GB VRAM 언급이 눈에 띕니다. Mistral은 FP8 instruct 버전이 24GB VRAM에 맞을 수 있고, 더 양자화하면 더 적은 메모리도 가능하다고 설명합니다. 24GB는 모든 개발자가 가진 환경은 아니지만, 고급 소비자 GPU나 워크스테이션, 일부 사내 서버에서 현실적인 선입니다. 로컬에서 비전과 툴 호출을 갖춘 14B 모델을 돌릴 수 있다면, 기업은 모든 실험을 외부 API 비용으로 계산하지 않아도 됩니다.
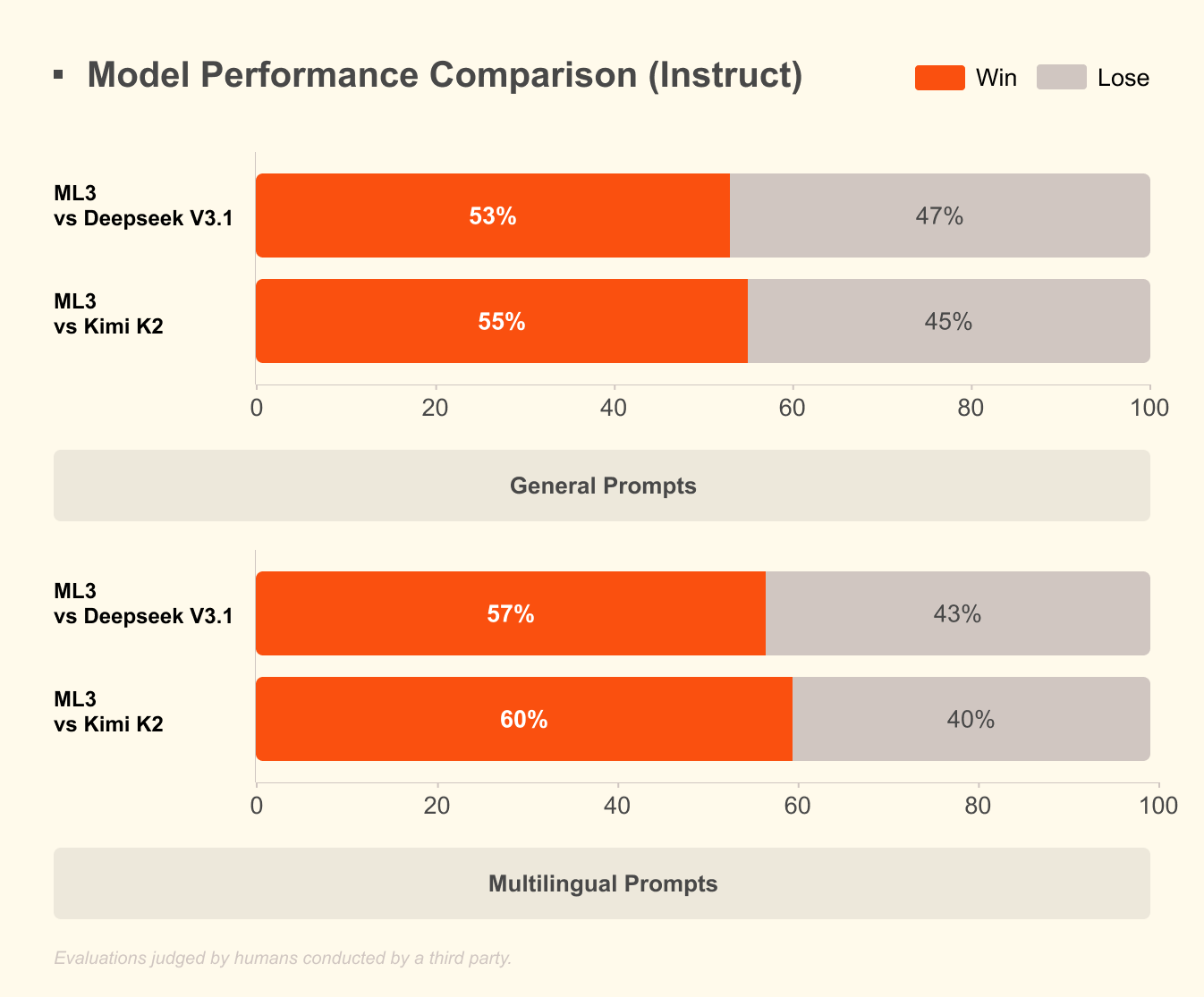
하지만 작은 모델 전략에는 주의할 점도 있습니다. 모델 카드의 벤치마크는 특정 조건에서의 비교입니다. 실제 제품에서는 문서 길이, 도메인 용어, 툴 스키마 품질, 다국어 혼합 입력, 이미지 품질, 지연 시간 목표, GPU 동시성, 캐싱 전략이 결과를 바꿉니다. 작은 모델은 비용이 낮지만, 작업을 잘못 나누면 오히려 큰 모델보다 더 많은 재시도와 검수 비용을 만들 수 있습니다.
따라서 Ministral 3의 실전 가치는 "14B가 어떤 벤치마크에서 누구를 이겼다"보다 "어떤 작업을 작은 모델로 내려보낼 수 있는가"에서 갈립니다. 예를 들어 문서 분류, 고객 문의 라우팅, 내부 코드베이스 요약, 짧은 도구 호출 계획, 이미지 기반 검사, 로컬 RAG 전처리, 구조화 JSON 추출은 작은 모델의 영역이 될 수 있습니다. 반대로 긴 추론, 높은 정확도가 필요한 법률·의료 판단, 복잡한 코드 수정, 불확실성이 큰 연구 질문은 여전히 더 큰 모델이나 인간 검토가 필요합니다.
vLLM과 NVFP4가 말하는 운영 현실
Mistral 3 발표에서 모델 성능만큼 눈에 띄는 것은 서빙 경로입니다. Mistral은 vLLM, Red Hat, NVIDIA와의 협업을 강조합니다. Large 3에는 NVFP4 포맷 체크포인트와 vLLM 실행 경로가 제시됩니다. 발표는 Large 3를 Blackwell NVL72 시스템이나 단일 8×A100 또는 8×H100 노드에서 효율적으로 실행할 수 있는 방향을 언급합니다. NVIDIA는 TensorRT-LLM과 SGLang 지원, Blackwell attention과 MoE 커널, prefill/decode 분리 서빙, speculative decoding 협업도 포함됩니다.
이 대목은 일반 독자에게는 세부 구현처럼 보일 수 있습니다. 그러나 AI 인프라 팀에게는 발표의 핵심입니다. 오픈 모델을 받는 것과 안정적으로 서빙하는 것은 다른 문제입니다. 대형 MoE는 메모리, 네트워크, 토큰 배칭, 라우팅, 커널 최적화, 장애 복구가 모두 어렵습니다. 작은 모델도 마찬가지입니다. 로컬에서는 GPU 메모리와 드라이버, 컨텍스트 길이, 동시 요청, 프롬프트 템플릿 호환성이 문제로 떠오릅니다.
Mistral이 vLLM을 전면에 세운 것은 우연이 아닙니다. vLLM은 오픈 모델 서빙에서 사실상 표준에 가까운 위치를 차지하고 있습니다. 개발자는 Hugging Face에서 모델을 내려받아 OpenAI 호환 API 형태로 서빙할 수 있고, 기존 애플리케이션의 모델 클라이언트를 크게 바꾸지 않고도 실험할 수 있습니다. 모델 카드의 예시도 vLLM serve 명령과 OpenAI 스타일 클라이언트를 보여줍니다.
이런 흐름은 모델 제공사의 경쟁 방식을 바꿉니다. 예전에는 "우리 API를 쓰세요"가 중심이었습니다. 지금은 "우리 모델은 당신의 인프라에서도 돌아갑니다"가 중요해집니다. 특히 금융, 공공, 헬스케어, 제조, 국방, 대기업 내부 업무처럼 데이터 경계가 민감한 영역에서는 모델의 지능보다 배포 가능성이 먼저 문턱이 됩니다. Mistral 3는 이 문턱을 낮추려는 발표입니다.
한국어와 다국어 모델의 현실적인 질문
Mistral은 Ministral 3 모델 카드에서 한국어를 포함한 다국어 지원을 명시합니다. 이것은 한국 개발자에게 반가운 신호입니다. 하지만 다국어 지원 문구만으로 충분하다고 볼 수는 없습니다. 한국어 제품에서는 존댓말, 도메인 용어, 영어·한국어 혼합 문서, 코드 주석, 법률·금융 표현, 검색 문서의 품질, OCR 결과의 오류가 모두 모델 품질을 흔듭니다.
따라서 한국어 팀이 Mistral 3를 검토한다면 먼저 자체 평가셋을 만들어야 합니다. 공개 벤치마크의 평균 점수보다 중요한 것은 실제 고객 문의, 내부 문서, 코드베이스, 상품명, 정책 문서, 규제 표현에서 모델이 어떤 실수를 하는지입니다. 특히 작은 모델을 에이전트에 붙일 경우 function calling과 JSON output의 안정성을 따로 봐야 합니다. 한국어 자연어 이해는 괜찮아도 툴 스키마를 잘못 채우면 운영 사고가 됩니다.
이것은 Mistral 3만의 문제가 아닙니다. 모든 오픈 모델이 제품으로 들어갈 때 같은 질문을 받습니다. 모델이 한 번 좋은 답을 하는가보다, 같은 작업을 만 번 반복할 때 실패가 어떤 형태로 나타나는지가 중요합니다. 작은 모델은 특히 실패 양상이 조용할 수 있습니다. 그럴듯한 JSON을 만들지만 필드 의미를 바꾸거나, 이미지에서 보이지 않는 내용을 추론하거나, 긴 컨텍스트 뒤쪽 지시를 놓치는 식입니다.
그렇기 때문에 Mistral 3의 실제 채택은 벤치마크보다 eval과 관측 가능성에 달려 있습니다. 팀은 모델별로 허용 가능한 작업 범위를 정하고, 실패 비용이 큰 작업은 큰 모델이나 인간 검토로 넘겨야 합니다. 오픈 모델을 쓰면 통제권은 늘어나지만, 책임도 함께 늘어납니다.
오픈 모델 경쟁의 다음 전선
Mistral 3는 오픈 모델 경쟁의 다음 전선이 세 갈래로 나뉘고 있음을 보여줍니다. 첫째는 프론티어급 오픈 웨이트입니다. Large 3처럼 거대한 모델이 폐쇄형 API의 품질을 압박합니다. 둘째는 로컬·엣지 모델입니다. Ministral 3처럼 작은 모델이 제품 내부의 반복 작업과 민감한 워크로드를 맡습니다. 셋째는 운영 생태계입니다. vLLM, NVIDIA 커널, Hugging Face, 클라우드 마켓플레이스, API 라우터, 기업 커스텀 트레이닝이 모델의 실전 가치를 결정합니다.
이 세 갈래가 합쳐지면 모델 선택 방식이 달라집니다. 팀은 더 이상 한 모델만 고르지 않습니다. 프론티어 모델은 복잡한 추론과 고위험 판단에 쓰고, 중간 모델은 일반적인 업무 자동화에 쓰고, 작은 모델은 로컬 전처리와 반복 호출에 씁니다. 어떤 요청은 사내 서버에서 처리하고, 어떤 요청은 외부 API로 보내고, 어떤 요청은 비용 상한을 넘으면 fallback합니다. 결국 모델 전략은 애플리케이션 아키텍처의 일부가 됩니다.
Mistral이 Large 3와 Ministral 3를 같은 발표에 넣은 이유도 여기에 있을 가능성이 큽니다. 대형 모델만으로는 비용과 배포의 질문에 답하지 못합니다. 작은 모델만으로는 프론티어급 브랜드와 고난도 작업의 질문에 답하지 못합니다. 둘을 함께 내야 "오픈 AI 스택"이라는 메시지가 완성됩니다.
개발팀이 지금 확인할 것
Mistral 3를 바로 제품에 넣을지 여부와 별개로, 개발팀이 확인할 질문은 분명합니다. 첫째, 우리 워크로드 중 외부 API에 보내기 어려운 데이터는 무엇입니까. 둘째, 그중 작은 모델로 충분한 작업은 무엇입니까. 셋째, 모델 품질을 공개 벤치마크가 아니라 자체 eval로 측정할 수 있습니까. 넷째, 오픈 모델을 운영할 GPU, 로깅, 보안, 업데이트, 롤백 체계가 있습니까.
이 질문에 답할 수 있다면 Mistral 3는 흥미로운 선택지가 됩니다. Apache 2.0 라이선스와 다양한 배포 경로는 실험 비용을 낮춥니다. Hugging Face와 vLLM 기반 경로는 기존 오픈 모델 운영 경험이 있는 팀에게 친숙합니다. 작은 모델 제품군은 비용을 통제하면서 더 많은 호출을 로컬로 옮길 가능성을 줍니다.
반대로 이 질문에 답하지 못한다면 Mistral 3는 또 하나의 체크포인트로 끝날 수 있습니다. 오픈 모델은 다운로드 버튼이 쉬워 보이지만, 운영은 쉽지 않습니다. 특히 에이전트와 툴 호출을 붙이면 모델은 단순한 텍스트 생성기가 아니라 시스템의 행동 주체가 됩니다. 권한, 감사 로그, 실패 처리, 샌드박스, 민감 데이터 경계가 함께 설계돼야 합니다.
Mistral 3의 진짜 의미는 "오픈 모델이 폐쇄형 모델을 완전히 이겼다"가 아닙니다. 그렇게 말하기에는 아직 독립 재현과 실제 제품 피드백이 더 필요합니다. 더 정확한 해석은 이것입니다. 오픈 모델 진영이 이제 크기, 라이선스, 엣지 배포, 멀티모달, 에이전트 기능, 서빙 생태계를 한 묶음으로 경쟁하기 시작했습니다.
Mistral 3는 그 경쟁의 새 기준선을 그었습니다. 앞으로의 질문은 어떤 모델이 가장 유명한가가 아니라, 어떤 팀이 자신들의 데이터 경계와 비용 구조에 맞는 모델 포트폴리오를 가장 잘 설계하느냐입니다.