MiniMax M2.7이 스스로 진화했다, Opus 성능의 90%를 7% 가격에
MiniMax가 AI 모델이 자신의 학습 과정에 직접 참여하는 자기 진화 메커니즘의 M2.7을 오픈소스로 공개했습니다. 230B 파라미터 중 10B만 활성화하며 Claude Opus 4.6에 근접한 성능을 50배 이상 저렴한 가격에 제공합니다.

AI 모델이 자신의 학습 과정을 스스로 수정하고, 100회 이상의 자율 최적화 루프를 돌려 성능을 30% 끌어올렸습니다. 상하이 기반 AI 스타트업 MiniMax가 4월 12일 공개한 M2.7 의 이야기입니다. 230B 파라미터 중 10B만 활성화하는 Sparse MoE 아키텍처로, SWE-Pro 벤치마크에서 56.22%를 기록하며 Claude Opus 4.6(~57%)에 근접했습니다. 가격은 입력 기준 50배, 출력 기준 62.5배 저렴합니다.
하지만 헤드라인 뒤에는 복잡한 현실이 있습니다. 간단한 질문에도 16,000 토큰 이상의 사고 과정을 생성하고, "오픈소스"를 표방하면서도 상업적 사용에는 사전 허가가 필요합니다. M2.7은 AI 모델 개발의 새로운 패러다임을 열었을까요, 아니면 또 하나의 교묘한 마케팅일까요?
MiniMax는 누구인가
M2.7을 이해하려면 먼저 MiniMax라는 회사를 알아야 합니다.
MiniMax는 2021년 前 SenseTime 임원 Yan Junjie가 상하이에서 창업한 AI 스타트업입니다. 2024년 3월 Alibaba가 리드한 $600M 라운드에서 $2.5B 밸류에이션 을 달성했고, 2026년 1월 홍콩 IPO에 성공하며 첫날 70% 이상 급등, 시가총액 HK$90B(약 $11.5B)를 돌파했습니다. NVIDIA CEO Jensen Huang이 "world-class" AI 스타트업으로 직접 언급한 회사이기도 합니다.
MiniMax의 투자자 명단은 중국 테크 생태계의 축소판입니다. Alibaba, Tencent, Hillhouse, HongShan, IDG Capital, 그리고 게임사 miHoYo(원신 개발사)까지 포진해 있습니다. 제품 포트폴리오도 독특합니다. AI 비디오 생성 서비스 Hailuo AI 와 음악 생성 모델 Music-01을 운영하며, 텍스트 모델뿐 아니라 멀티모달 AI 전반에 걸친 풀스택 전략을 구사하고 있습니다.
그동안 MiniMax는 프론티어 모델 경쟁에서 상대적으로 조용한 편이었습니다. DeepSeek, Zhipu(GLM), Alibaba(Qwen) 등 중국 AI 기업들이 오픈소스 LLM 경쟁을 벌이는 동안, MiniMax는 멀티모달 제품에 집중했습니다. M2.7은 그 MiniMax가 프론티어 텍스트 모델 영역에 본격적으로 뛰어든 첫 번째 시도입니다.
자기 진화, AI가 자신의 학습을 수정하는 메커니즘
M2.7의 가장 주목할 만한 혁신은 벤치마크 점수가 아니라 그 점수를 달성한 방법 입니다.
기존 LLM의 학습 파이프라인은 일방향입니다. 데이터 수집 → 전처리 → 학습 → 평가 → 배포. 모델은 학습이 끝나면 고정되고, 개선이 필요하면 엔지니어가 파이프라인을 수동으로 수정합니다. M2.7은 이 구조를 근본적으로 바꿨습니다.
MiniMax는 OpenClaw 라는 자율 에이전트 하네스를 구축했습니다. M2.7의 초기 버전이 이 하네스 안에서 에이전트로 동작하며, 다음 루프를 100회 이상 자율 실행 했습니다.
- 실패 궤적(failure trajectories) 분석
- 변경 계획 수립
- 스캐폴드 코드 수정
- 평가 실행
- 결과 비교
- 유지/롤백 결정
쉽게 말해, 모델이 자신의 실패를 분석하고, 왜 실패했는지 진단하고, 학습 환경의 코드를 직접 수정하고, 다시 시도하는 과정을 스스로 반복한 것입니다. 이 자율 최적화를 통해 내부 평가 세트에서 30%의 성능 향상 을 달성했습니다. 모델은 자체 메모리를 업데이트하고, 강화학습 실험을 돕기 위한 수십 개의 복잡한 스킬을 하네스에 구축했습니다.
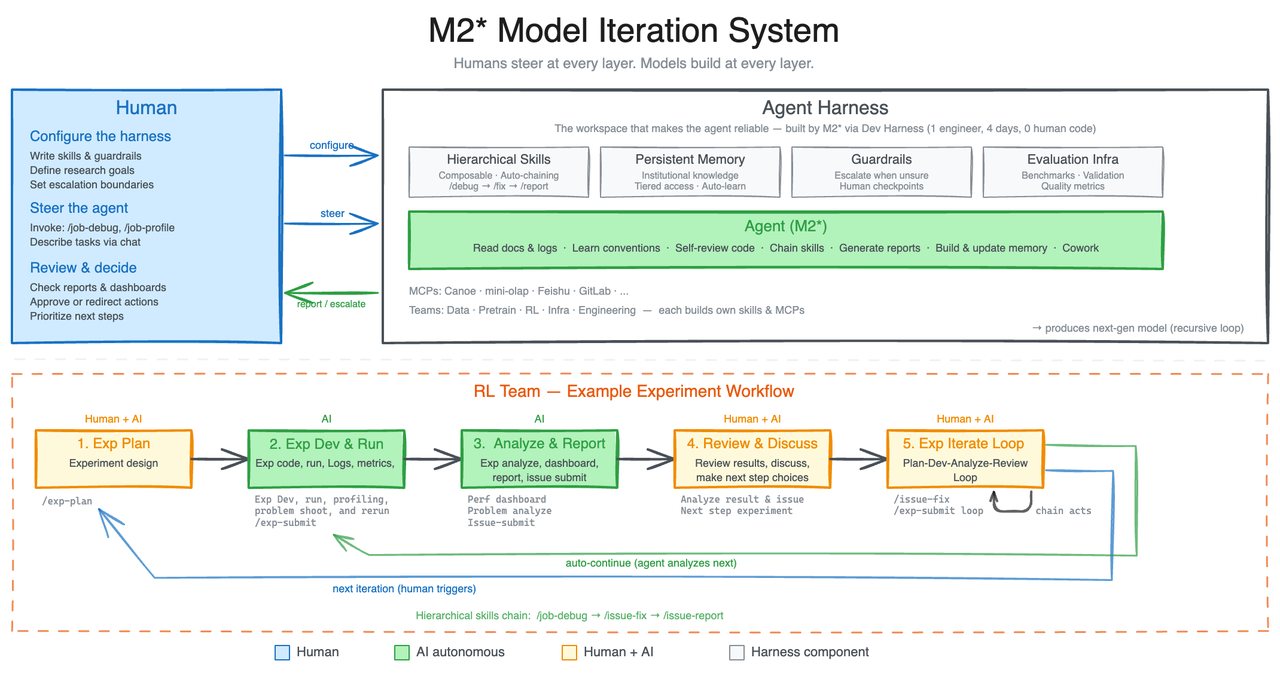
이것이 왜 중요할까요? 기존의 RLHF(인간 피드백 기반 강화학습)나 RLAIF(AI 피드백 기반 강화학습)와는 본질적으로 다릅니다. RLHF/RLAIF에서 모델은 피드백을 받는 수동적 주체입니다. M2.7의 자기 진화에서는 모델이 학습 파이프라인 자체를 수정하는 능동적 주체 입니다. 모델이 "이 학습 방식이 비효율적이니 코드를 이렇게 바꾸겠다"고 판단하고 실행하는 것입니다.
MLE-Bench Lite에서의 검증 결과도 주목할 만합니다. 단일 A30 GPU에서 22개 머신러닝 경진대회를 테스트한 결과, 평균 메달 획득률 66.6%를 기록했습니다. Claude Opus 4.6(75.7%)과 GPT-5.4(71.2%)에 이어 3위이며, Gemini 3.1(66.6%)과 동률입니다.
실제로 MiniMax의 RL 팀에서는 M2.7이 일상 업무의 30-50%를 자율 처리 하고 있다고 합니다. 문헌 리뷰, 데이터 파이프라인 관리, 실험 런칭, 모니터링, 로그 분석, 디버깅, 코드 수정, 머지 리퀘스트까지. 연구원은 핵심 의사결정에만 개입하고, 나머지 루틴 ML 엔지니어링은 M2.7이 자율 수행합니다.
230B 중 10B만 깨운다, 아키텍처의 효율성
M2.7의 가격 파괴를 가능하게 한 것은 극단적으로 효율적인 아키텍처입니다.
| 항목 | MiniMax M2.7 | Claude Opus 4.6 | GPT-5 |
|---|---|---|---|
| 총 파라미터 | 230B | 비공개 | 비공개 |
| 활성 파라미터 | 10B ✦ | 비공개 | 비공개 |
| 컨텍스트 윈도우 | 200K | 200K | 128K |
| 입력 가격 ($/M 토큰) | $0.30 | $15.00 | $10.00 |
| 출력 가격 ($/M 토큰) | $1.20 | $75.00 | $30.00 |
| 추론 속도 | ~100 TPS | ~33 TPS | ~40 TPS |
| 아키텍처 | Sparse MoE | Dense | 비공개 |
✦ Tier-1 성능 클래스에서 활성 파라미터 10B는 M2.7이 유일
M2.7은 총 230B(2,300억) 파라미터를 가지고 있지만, 하나의 토큰을 처리할 때 실제로 활성화되는 파라미터는 10B(100억)에 불과 합니다. 256개의 전문가(expert) 중 8개만 토큰당 활성화되는 Sparse Mixture-of-Experts(MoE) 아키텍처 덕분입니다. 62개 레이어, Hidden Size 3,072, 200K 컨텍스트 윈도우를 갖추고 있습니다.
이 효율성은 곧바로 비용과 속도의 차이로 이어집니다.
| 모델 | 입력 ($/M 토큰) | 출력 ($/M 토큰) | 추론 속도 |
|---|---|---|---|
| MiniMax M2.7 | $0.30 | $1.20 | ~100 TPS |
| Claude Opus 4.6 | $15.00 | $75.00 | ~33 TPS |
| GPT-5 | $10.00 | $30.00 | ~40 TPS |
입력 토큰 기준 Opus 대비 50배, 출력 토큰 기준 62.5배 저렴합니다. 추론 속도도 Opus의 약 3배인 ~100 TPS입니다. Tier-1 성능 클래스에서 활성 파라미터가 10B에 불과한 모델은 M2.7이 유일합니다.
소프트웨어 엔지니어링 벤치마크에서의 성적은 이 가격 차이를 더욱 극적으로 만듭니다.
| 벤치마크 | M2.7 | Claude Opus 4.6 | GPT-5.3 Codex |
|---|---|---|---|
| SWE-Pro | 56.22% | ~57% | 56.2% |
| SWE-bench Verified | 78% | 55% | - |
| Terminal Bench 2 | 57.0% | - | - |
SWE-Pro에서 Opus와 0.78%p 차이. SWE-bench Verified에서는 78% vs 55%로 오히려 크게 앞섭니다. 에이전트 생산성 벤치마크인 GDPval-AA에서는 ELO 1495로 오픈소스 모델 중 최고를 기록했고, Skill Adherence(40개 복잡한 태스크 기준)에서는 97%를 달성했습니다.
가격 파괴의 이면, 실제 비용은 헤드라인과 다르다
하지만 여기서 중요한 경고가 필요합니다. 헤드라인 가격과 실제 비용은 다릅니다.
M2.7은 평균적인 모델 대비 4배 많은 출력 토큰 을 생성하는 경향이 있습니다. 간단한 프롬프트에도 16,000 토큰 이상의 사고 과정(thinking tokens)을 생성한다는 보고가 커뮤니티에서 잇따르고 있습니다. 출력 토큰이 $1.20/M이라고 해도, 같은 작업에 4배 많은 토큰을 쓰면 실질 비용은 $4.80/M에 가까워집니다.
그래도 Opus의 $75.00/M과 비교하면 여전히 15배 이상 저렴합니다. 하지만 "62.5배 저렴"이라는 헤드라인은 실제 사용에서 체감하기 어렵습니다. Kilo Code의 독립 테스트는 이를 "Opus 품질의 90%를 7% 비용으로" 라고 정리했는데, 이 "7%"라는 숫자도 thinking 토큰을 고려한 실질 비용 기준일 가능성이 높습니다.
또 하나의 제약은 긴 컨텍스트 성능 입니다. llama.cpp 커뮤니티에서는 M2.7이 full attention을 적용하기 때문에 긴 컨텍스트에서 매우 느려진다는 지적이 나왔습니다. 200K 컨텍스트 윈도우를 가지고 있지만, 실제로 긴 컨텍스트를 채워 사용하면 속도 이점이 크게 줄어들 수 있습니다.
실무 영향, MMX-CLI와 에이전트 생태계 통합
M2.7과 함께 공개된 MMX-CLI 는 개발자 실무에 직접적인 영향을 미칩니다. MMX-CLI는 에이전트용 멀티모달 CLI 도구로, Claude Code, Cursor, OpenClaw 등 기존 에이전트 환경에서 MCP 서버 없이 네이티브로 MiniMax 모델을 호출할 수 있게 합니다.
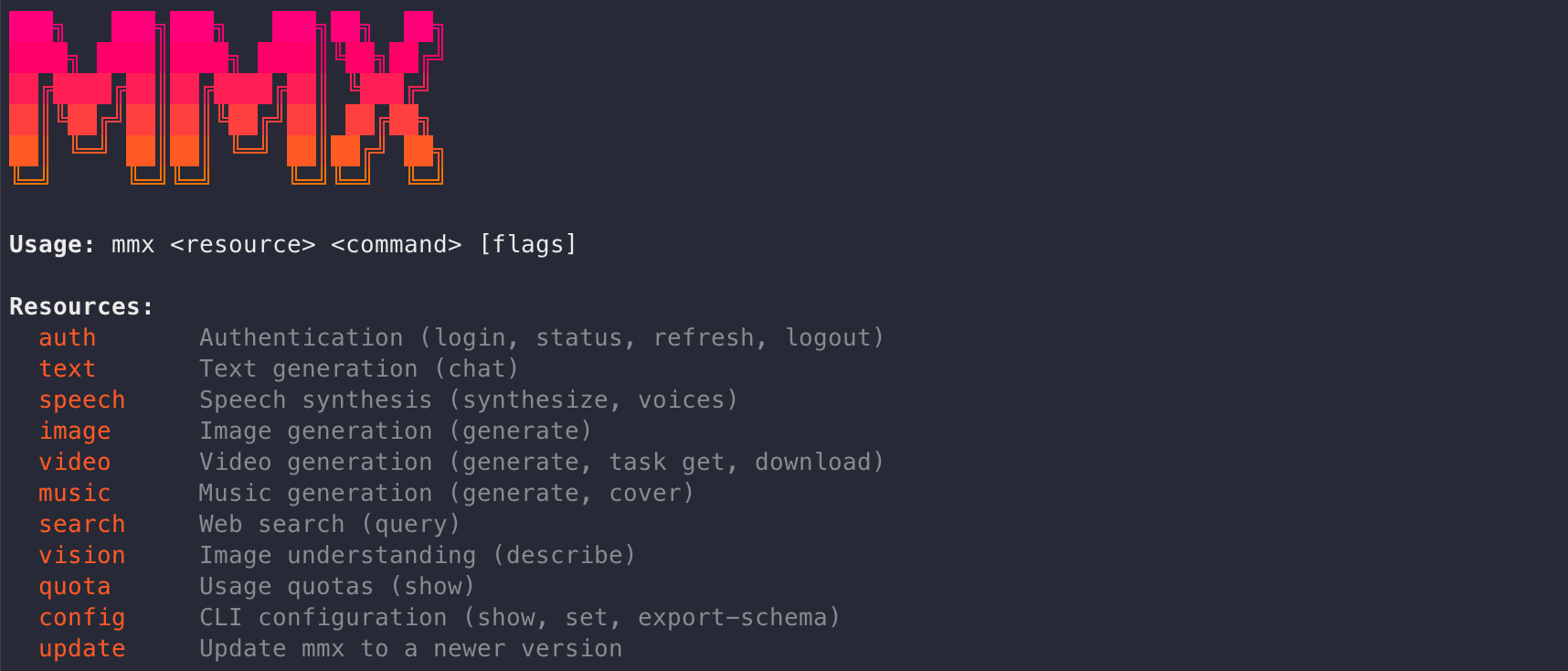
기존에 Claude Code에서 이미지나 비디오 생성을 하려면 복잡한 API 연동이나 MCP 서버 구축이 필요했습니다. MMX-CLI는 이를 커맨드라인 한 줄로 해결합니다. TypeScript 기반으로 Node.js 18+ 환경에서 동작하며, 7개 생성 모달리티를 지원합니다. 텍스트, 이미지, 비디오, 음성, 음악, 비전, 검색까지.
설계도 에이전트 친화적입니다. 사람용 진행 표시는 stderr로, 머신이 파싱할 데이터는 stdout로 분리하는 출력 격리 원칙을 따릅니다. 실패 유형별 다른 종료 코드를 반환하는 시맨틱 종료 코드, --async 플래그를 통한 비동기 제어도 지원합니다.
생태계 확산도 빠릅니다. M2.7 공개 수시간 내에 Ollama, OpenRouter, Vercel, NVIDIA NIM 등에서 지원을 시작했습니다. 로컬 추론, 클라우드 API, 엔터프라이즈 배포 경로가 모두 열린 셈입니다.
같은 날 공개된 Music 2.6 도 눈여겨볼 만합니다. AI 커버(Cover) 기능이 핵심으로, 기존 곡의 멜로디 뼈대를 추출한 뒤 스타일과 장르를 완전히 재해석합니다. 포크를 헤비메탈로, 클래식 심포니를 사이버펑크 일렉트로닉으로 변환하는 식입니다. BPM과 키 제어의 정확도가 99% 이상이며, 첫 출력까지 20초 이내로 이전 모델 대비 크게 개선되었습니다. MiniMax가 텍스트 모델과 멀티모달 능력을 동시에 공격적으로 확장하고 있다는 신호입니다.
커뮤니티 반응, 찬사와 논란이 공존한다
M2.7에 대한 커뮤니티 반응은 양극단으로 나뉩니다.
찬사: 가격 대비 성능의 새 기준
Kilo Code의 독립 테스트에서 M2.7은 보안 취약점 탐지에서 Opus와 동일한 버그를 포착 했습니다. r/LocalLLaMA에서는 백엔드 코딩에서의 강점과 깊은 코드 읽기 습관이 긍정적으로 평가되었습니다.
"하네스 엔지니어링이 진정한 차별화 요소가 되고 있다"
전문가들은 M2.7의 자기 진화 메커니즘이 모델 자체보다 학습 인프라 에서의 혁신이라는 점에 주목하고 있습니다. 모델 아키텍처의 진보가 아니라, 모델을 만드는 과정의 진보라는 것입니다.
논란 1: "오픈소스"는 정말 오픈소스인가
가장 뜨거운 논란은 라이선스입니다. M2.7은 Modified MIT License 를 사용하는데, 여기에는 상업적 사용 시 MiniMax의 사전 서면 허가 가 필요하다는 조건이 포함되어 있습니다. Reddit에서는 즉각적인 반발이 나왔습니다.
"오픈소스라고 부르면서 비상업 조건을 붙였다"
이 논란은 MiniMax만의 문제가 아닙니다. 최근 Meta가 Muse Spark에서 MSL(Meta Spark License)을 도입하며 기존 오픈소스 방침을 사실상 철회한 것과 궤를 같이합니다. DeepSeek, Zhipu(GLM) 등 중국 AI 기업들이 "오픈소스"를 마케팅 전략으로 활용하면서도 실제로는 상업적 통제를 유지하려는 패턴이 반복되고 있습니다.
| 모델 | 라이선스 | 상업적 사용 | 제약 조건 | 실질 오픈소스 |
|---|---|---|---|---|
| GLM-5.1 | Apache 2.0 | 자유 | 없음 | ✅ 완전 오픈 |
| DeepSeek | MIT | 자유 | 없음 | ✅ 완전 오픈 |
| MiniMax M2.7 | Modified MIT | 사전 허가 필요 | MiniMax 서면 승인 | ⚠️ 조건부 |
| Meta Llama 4 | Llama License | 조건부 | 7억 MAU 초과 시 제한 | ⚠️ 조건부 |
| Meta Muse Spark | MSL | 엄격 제한 | 사실상 독점 | ❌ 비오픈소스 |
"오픈소스"라는 명칭이 항상 동일한 자유도를 의미하지는 않습니다
흥미로운 대조점은 같은 주에 공개된 Zhipu의 GLM-5.1 입니다. Apache 2.0 라이선스로 완전한 상업적 자유를 보장하며 SWE-Bench Pro에서 1위를 차지했습니다. "진짜 오픈소스"를 원하는 개발자라면 GLM-5.1이 더 매력적인 선택일 수 있습니다.
논란 2: 긴 thinking 토큰과 실질 비용
앞서 언급했듯이, M2.7은 간단한 프롬프트에도 과도하게 긴 사고 과정을 생성합니다. 한 사용자는 단순한 질문에 16,000 토큰 이상의 thinking 출력 이 나왔다고 보고했습니다. 이는 사용자 경험과 실질 비용 모두에 영향을 미칩니다. 저렴한 가격이 매력이지만, 필요 이상으로 많은 토큰을 소비한다면 실제 비용 절감폭은 헤드라인보다 작아집니다.
자기 진화가 가리키는 방향
M2.7이 촉발한 가장 중요한 질문은 이것입니다. AI 모델이 자신의 학습에 참여하는 것이 일반화될 수 있을까?
현재 이 방향으로 움직이고 있는 것은 MiniMax만이 아닙니다. Meta의 HyperAgents 프로젝트도 에이전트 자기 개선을 연구하고 있으며, M2.7과 함께 AI 자기 진화 연구의 두 축을 형성하고 있습니다. 만약 이 접근법이 확산된다면, LLM 개발에서 "엔지니어가 학습 파이프라인을 수동으로 튜닝하는 시대"가 끝나고, "모델이 자신의 학습 인프라를 자율적으로 개선하는 시대"가 열릴 수 있습니다.
가격 경쟁에 미치는 영향도 무시할 수 없습니다. 활성 10B 파라미터로 Tier-1 성능을 달성한 것은 독점 모델의 가격 구조에 직접적인 압력입니다. Latent Space는 이를 "MiniMax M2.7이 독점 AI 연구소에 큰 문제" 라고 분석했습니다. Anthropic, OpenAI가 프리미엄 가격을 유지하기 위해서는 M2.7이 따라올 수 없는 품질 차이를 지속적으로 증명해야 합니다.
하지만 냉정하게 봐야 할 부분도 있습니다. M2.7의 자기 진화는 학습 단계에서만 일어납니다. 배포된 모델이 실시간으로 자기 개선하는 것은 아닙니다. 또한 Modified MIT 라이선스의 상업적 제약은 실제 엔터프라이즈 채택에 걸림돌이 될 수 있습니다. Apache 2.0의 GLM-5.1이나 MIT 라이선스의 DeepSeek과 비교하면, M2.7은 "오픈소스"라는 이름에 걸맞은 자유도를 제공하지 못합니다.
M2.7은 완벽한 모델이 아닙니다. 하지만 "AI가 자신의 학습을 개선한다" 는 개념이 논문 속 이론에서 실제 프로덕션 모델로 구현되었다는 점은 부정할 수 없습니다. 모델 성능의 상향 평준화가 가속되는 가운데, 경쟁의 초점이 "더 큰 모델"에서 "더 똑똑한 학습 방법"으로 이동하고 있음을 M2.7은 증명하고 있습니다.