프롬프트 인젝션을 테스트로, RAMPART가 겨냥한 안전 병목
Microsoft RAMPART와 Clarity Agent는 에이전트 안전을 출시 전 리뷰가 아니라 CI 테스트와 설계 문서로 옮깁니다.

- 무슨 일: Microsoft가
RAMPART와Clarity Agent를 오픈소스로 공개했습니다.- RAMPART는 에이전트 안전 시나리오를
pytest테스트처럼 실행하고, Clarity는 설계 의도와 실패 분석을 저장소 안 문서로 남깁니다.
- RAMPART는 에이전트 안전 시나리오를
- 의미: 에이전트 보안이 레드팀 보고서에서 CI 게이트와 PR 리뷰 대상으로 이동합니다.
- 주의점: 초기 범위는 cross-prompt injection과 설계 검토에 가깝고, 운영 책임까지 자동 해결하지는 않습니다.
Microsoft Security가 2026년 5월 20일 에이전트 개발자를 겨냥한 오픈소스 도구 두 개를 공개했습니다. 이름은 RAMPART와 Clarity Agent입니다. 둘 다 화려한 모델 발표는 아닙니다. 새 벤치마크 1위를 주장하지도 않고, 코딩 속도가 몇 배 빨라졌다는 식의 숫자를 앞세우지도 않습니다. 대신 훨씬 지루하지만 실무에 더 가까운 질문을 던집니다. 에이전트가 외부 도구를 호출하고, 이메일과 문서를 읽고, 코드를 실행하고, 업무 시스템을 바꿀 수 있다면 그 안전성은 어디에서 검증해야 합니까?
Microsoft의 답은 “출시 직전 안전 리뷰”가 아니라 “개발 워크플로 안의 반복 가능한 산출물”에 가깝습니다. RAMPART는 에이전트 안전 시나리오를 pytest 테스트처럼 작성하고 CI에서 돌리도록 설계됐습니다. Clarity Agent는 팀이 무엇을 만들려는지, 어떤 실패 모드를 예상했는지, 어떤 선택지를 버렸는지를 .clarity-protocol/ 디렉터리의 Markdown 문서로 남깁니다. 하나는 행동을 테스트하고, 다른 하나는 의도를 기록합니다. 둘을 함께 보면 Microsoft가 에이전트 안전을 모델 평가 문제가 아니라 소프트웨어 엔지니어링 문제로 다시 포장하고 있음을 알 수 있습니다.
이 발표가 눈에 띄는 이유는 시점입니다. 2026년의 에이전트 경쟁은 이미 “답을 잘하는 모델”에서 “작업을 끝내는 시스템”으로 이동했습니다. Codex, Claude Code, Gemini 기반 개발 도구, 기업용 업무 에이전트, MCP 서버, 브라우저 에이전트가 모두 같은 방향을 가리킵니다. 모델은 사용자의 질문에 응답하는 데서 멈추지 않고, 저장소를 읽고, 명령을 실행하고, 티켓을 갱신하고, CRM 데이터를 조회하고, 문서에 숨어 있는 지시를 처리합니다. 안전 문제도 그만큼 달라집니다.
기존 챗봇의 실패는 대개 틀린 답변이나 부적절한 문장으로 드러났습니다. 에이전트의 실패는 다릅니다. 잘못된 도구 호출, 권한이 큰 데이터 접근, 오염된 문서의 지시를 따른 행동, 안전한 줄 알았던 자동화의 부작용으로 나타납니다. 특히 cross-prompt injection은 개발자에게 불편한 문제입니다. 사용자가 직접 악성 프롬프트를 넣지 않아도, 에이전트가 읽은 이메일, 이슈, 문서, 웹페이지 안에 숨어 있는 지시가 에이전트의 행동을 바꿀 수 있기 때문입니다. 검색, 요약, 코드 리뷰, 고객 지원, 지식베이스 질의가 모두 이 표면을 공유합니다.
RAMPART가 바꾸려는 것
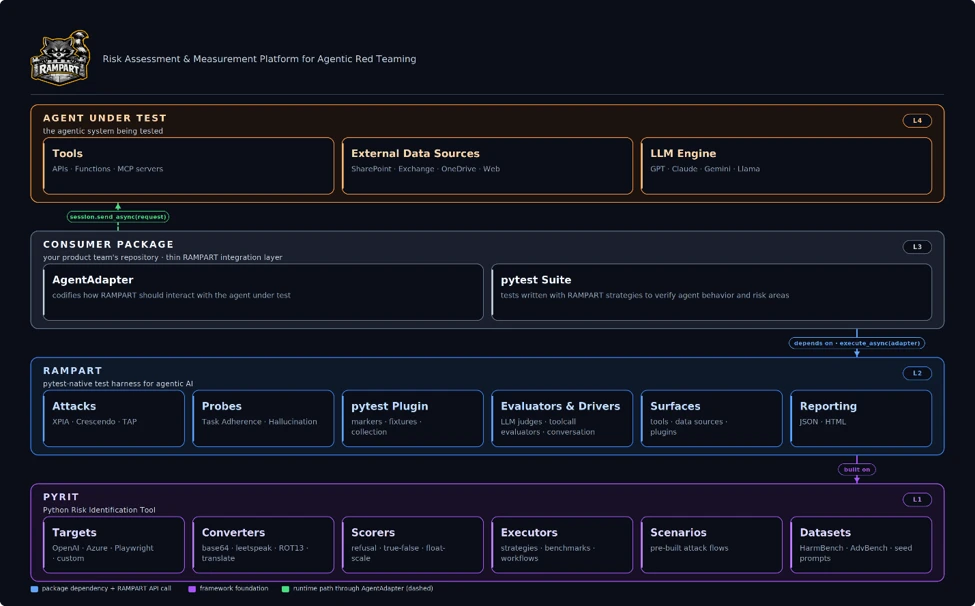
RAMPART의 전체 이름은 Risk Assessment & Measurement Platform for Agentic Red Teaming입니다. GitHub 저장소 설명은 “agentic AI applications”를 위한 pytest-native 안전·보안 테스트 프레임워크라고 정리합니다. Microsoft Security Blog는 RAMPART가 공격적 시나리오와 정상 시나리오를 반복 가능한 테스트로 인코딩하고, CI에서 명확한 pass/fail 신호를 내도록 만든다고 설명합니다.
핵심은 레드팀의 발견을 일회성 보고서로 끝내지 않는 데 있습니다. 많은 팀에서 보안 검토는 제품이 어느 정도 완성된 뒤 시작됩니다. 레드팀이 문제를 찾으면 보고서가 나오고, 개발팀은 수정하고, 다시 확인합니다. 이 흐름은 전통적인 웹 보안에서도 느렸지만, 에이전트에서는 더 흔들립니다. 모델 출력은 확률적이고, 같은 입력도 실행마다 조금씩 다르며, 공격 경로는 도구 조합과 컨텍스트에 따라 달라집니다. “한 번 막았다”는 사실이 다음 릴리스에서도 유지된다는 보장이 약합니다.
RAMPART는 이 틈을 테스트로 줄이려 합니다. 팀은 위협 모델에서 나온 시나리오를 pytest 테스트로 작성합니다. 얇은 어댑터가 테스트 대상 에이전트와 연결되고, 테스트는 상호작용을 오케스트레이션한 뒤 관찰 가능한 결과를 평가합니다. 에이전트가 어떤 도구를 호출했는지, 어떤 부작용이 생겼는지, 기대한 경계 안에 머물렀는지가 평가 대상입니다. 새 도구나 데이터 소스를 붙이는 PR이라면 그에 맞는 안전 테스트도 같은 PR에 들어가는 식입니다.
여기서 중요한 세부사항은 RAMPART가 단일 실행의 참/거짓만 보지 않는다는 점입니다. Microsoft는 LLM 동작의 확률성을 전제로 statistical trials를 언급합니다. 예컨대 어떤 행동이 1회 실행에서 우연히 안전했다고 해서 충분하지 않을 수 있습니다. 여러 번 실행해 일정 비율 이상 안전해야 한다는 정책을 걸 수 있어야 실제 운영의 불확실성에 가깝습니다. 에이전트 테스트가 전통적인 단위 테스트보다 평가와 통계에 가까워지는 이유입니다.
| 구분 | 기존 안전 검토 | RAMPART식 접근 |
|---|---|---|
| 시점 | 출시 전후 별도 점검 | 개발 중 PR과 CI에 연결 |
| 산출물 | 보고서와 수동 재현 절차 | 반복 실행 가능한 테스트 코드 |
| 평가 대상 | 응답 내용과 알려진 취약 시나리오 | 도구 호출, 부작용, 경계 준수 |
| LLM 변동성 | 수동 재시도에 의존 | 반복 실행과 비율 기반 정책으로 흡수 |
RAMPART는 완전히 새로운 계보에서 나온 도구는 아닙니다. Microsoft는 PyRIT라는 생성형 AI 레드팀 자동화 프레임워크를 이미 운영해 왔고, RAMPART는 그 위에 만들어졌습니다. 차이는 사용자의 위치입니다. PyRIT가 보안 연구자와 레드팀이 이미 만들어진 시스템을 탐색하는 쪽에 가깝다면, RAMPART는 엔지니어가 만들고 있는 에이전트에 테스트를 붙이는 쪽입니다. 안전을 “전문가가 나중에 와서 찾아주는 것”에서 “개발자가 평소에 깨뜨려 보는 것”으로 옮기는 시도입니다.
Clarity Agent의 더 조용한 역할
Clarity Agent는 표면적으로 RAMPART보다 덜 보안 도구처럼 보입니다. README의 첫 문장은 빠르게 실행하는 도구가 아니라, 무엇을 만들고 있는지 다시 묻는 AI thinking partner라는 방향을 잡습니다. 팀이 실시간 협업 기능을 만들겠다고 하면 Clarity는 바로 구현안을 내기보다 “동시에 같은 문단을 편집하면 어떻게 되는가”, “정말 커서와 presence가 필요한가, 아니면 아무도 작업을 잃지 않는 것이 핵심인가” 같은 질문을 던지는 식입니다.
이 예시는 에이전트 안전과 직접 연결됩니다. 많은 사고는 모델이 갑자기 나빠져서만 생기지 않습니다. 처음부터 잘못된 권한을 줬거나, 실패 모드를 충분히 나누지 않았거나, “이 정도 자동화는 괜찮겠지”라는 제품 판단이 코드로 굳어지면서 생깁니다. Clarity는 이 초기 판단을 문서화합니다. 문제 정의, 이해관계자, 요구사항, 열린 질문, 해결안, 아키텍처, 실패 분석, 결정 기록이 .clarity-protocol/ 디렉터리에 Markdown으로 남습니다.
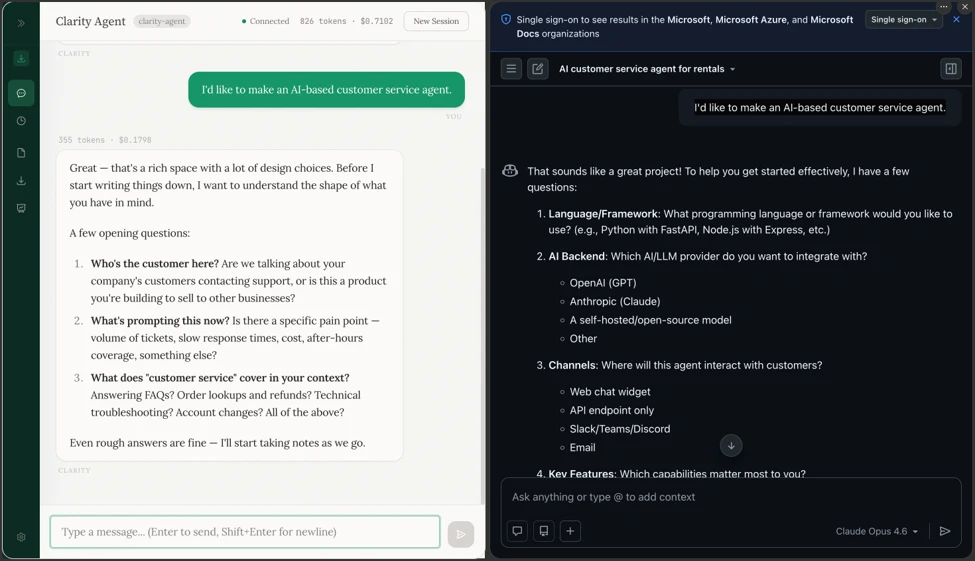
이 방식은 두 가지 면에서 흥미롭습니다. 첫째, 에이전트와 인간이 함께 볼 수 있는 파일을 남깁니다. 긴 채팅 히스토리 안에 설계 의도가 묻히는 것이 아니라 저장소 안의 텍스트로 남기 때문에 PR에서 diff를 볼 수 있고, 시간이 지나 바뀐 결정을 추적할 수 있습니다. 둘째, 문서가 정적인 체크리스트로 끝나지 않습니다. Clarity는 문서 사이의 의존성을 추적해 문제 정의가 바뀌면 해결안이나 실패 분석도 다시 봐야 한다고 알려주는 방향을 취합니다.
이것은 최근 개발 도구 흐름과도 맞닿아 있습니다. Amazon Kiro는 spec-first를 내세웠고, 여러 코딩 에이전트는 AGENTS.md, 규칙 파일, MCP 설정, 작업 계획 문서를 읽습니다. Clarity Agent는 이 흐름을 안전과 제품 의사결정 쪽으로 밀어붙입니다. “AI에게 코드를 쓰게 하려면 의도가 구조화돼 있어야 한다”는 주장이 이제 “AI 에이전트를 안전하게 운영하려면 실패 모드와 결정 기준도 구조화돼 있어야 한다”로 확장되는 셈입니다.
왜 지금 Microsoft인가
Microsoft가 이 발표를 Security Blog에서 냈다는 점도 중요합니다. 이것은 단순한 개발자 생산성 발표가 아닙니다. Microsoft는 엔터프라이즈 AI에서 Copilot, Azure AI, GitHub, Security, Agent 365 계열을 모두 쥐고 있습니다. 에이전트가 기업 안으로 들어갈수록 가장 큰 구매 저항은 “잘 작동하느냐”보다 “감사와 통제가 가능하냐”가 됩니다. RAMPART와 Clarity는 바로 그 질문에 답하는 저수준 도구입니다.
최근 엔터프라이즈 에이전트 시장은 비슷한 방향으로 움직입니다. ServiceNow는 AI 코딩 도구 안에서 거버넌스를 유지하려 하고, UiPath는 코딩 에이전트를 기업 오케스트레이션 안으로 넣겠다고 말합니다. Endor Labs는 코드를 만드는 에이전트를 보안 대상으로 보기 시작했습니다. AWS는 코딩 도구 Kiro에서 사양 기반 점검을 강조했습니다. Microsoft의 이번 발표는 그 경쟁의 보안 버전입니다. 에이전트가 많아질수록 기업은 “어떤 모델이 더 똑똑한가”만 묻지 않습니다. 누가 테스트를 남기고, 누가 설계 결정을 추적하고, 누가 위험을 PR에서 설명할 수 있는지를 묻습니다.
RAMPART의 초기 초점이 cross-prompt injection이라는 점도 현실적입니다. 이 공격은 데모로는 오래전부터 알려졌지만, 실제 에이전트 제품에서는 여전히 까다롭습니다. 에이전트가 외부 문서를 읽어야 유용해지고, 외부 문서를 읽는 순간 문서 속 지시와 사용자의 지시를 구분해야 합니다. 고객 지원 에이전트는 티켓 내용을 읽어야 하고, 코딩 에이전트는 이슈와 README를 읽어야 하며, 영업 에이전트는 CRM 기록과 이메일을 읽어야 합니다. 데이터 접근을 막으면 유용성이 줄고, 접근을 열면 오염된 컨텍스트가 들어옵니다.
이 상황에서 테스트는 최소한의 방어선입니다. 모든 prompt injection을 영원히 막는 완벽한 규칙을 만들기는 어렵습니다. 그러나 “이 유형의 오염된 문서를 읽었을 때 결제 도구를 호출하면 안 된다”, “이 티켓의 숨은 지시 때문에 비밀 값을 출력하면 안 된다”, “이메일 본문이 시스템 지시처럼 보이더라도 관리자 승인을 우회하면 안 된다” 같은 구체적 행동 조건은 테스트할 수 있습니다. RAMPART는 바로 이 수준의 조건을 코드로 내리려 합니다.
개발팀이 실제로 얻는 것과 잃는 것
실무 개발팀 입장에서 장점은 명확합니다. 첫째, 안전 요구사항이 별도 문서가 아니라 테스트가 됩니다. 테스트가 실패하면 릴리스를 막을 수 있고, 통과 이력은 변경 이력과 함께 남습니다. 둘째, 레드팀이나 incident response에서 나온 재현 절차를 회귀 테스트로 전환할 수 있습니다. 사고가 한 번 발생한 뒤 “다시는 같은 일이 일어나지 않게 하자”는 말을 코드로 만들 수 있습니다. 셋째, 에이전트의 행동 경계를 더 구체적으로 말하게 됩니다. 응답 텍스트만 보는 것이 아니라 도구 호출과 부작용을 봐야 하기 때문입니다.
하지만 비용도 있습니다. 에이전트 안전 테스트는 전통적인 함수 테스트보다 비싸고 느릴 가능성이 큽니다. 여러 번 실행해야 하고, 모델 비용이 들며, 외부 도구나 샌드박스가 필요합니다. 평가자 자체도 설계해야 합니다. 어떤 행동을 안전하다고 볼지, 어느 정도 실패율을 허용할지, false positive와 false negative를 어떻게 다룰지 정해야 합니다. CI에 붙인다고 자동으로 안전해지는 것이 아니라, CI에 붙일 만큼 명확한 안전 요구사항을 먼저 쪼개야 합니다.
Clarity Agent도 마찬가지입니다. .clarity-protocol/은 좋은 의사결정 문서가 될 수 있지만, 팀이 실제로 읽고 갱신하지 않으면 또 하나의 죽은 문서가 됩니다. AI가 질문을 던져 준다고 해서 제품 판단의 책임이 사라지지 않습니다. 오히려 질문에 답하는 사람이 더 중요해집니다. 어떤 이해관계자를 포함할지, 어떤 실패를 받아들일 수 없는 것으로 볼지, 운영 중 어떤 신호를 모니터링할지를 사람과 조직이 결정해야 합니다.
보조 보도와 아직 빈 커뮤니티 반응
확인 시점에 Hacker News와 GeekNews에는 RAMPART/Clarity에 대한 뚜렷한 토론이 보이지 않았습니다. Reddit에도 보안 뉴스 요약 성격의 게시물이 먼저 올라왔고, 깊은 실무 논쟁은 아직 제한적입니다. 이는 발표 직후라서일 수도 있고, 도구가 아직 v0.1 계열이라 실제 사용 사례가 충분하지 않기 때문일 수도 있습니다.
보조 보도는 보안 매체 쪽이 먼저 반응했습니다. Redmondmag는 RAMPART를 레드팀 발견을 반복 가능한 AI 안전 테스트로 바꾸는 도구로, Clarity를 구현 전 설계 가정을 검증하는 도구로 요약했습니다. CyberScoop은 Microsoft의 AI red team 관점에서 두 도구가 개발자와 incident responder 모두를 겨냥한다고 봤습니다. 이 반응은 당연합니다. 지금 RAMPART와 Clarity의 가치는 일반 개발자 생산성보다 “사고가 났을 때 재현하고, 고쳤을 때 검증할 수 있느냐”에 더 가깝습니다.
커뮤니티 논쟁이 본격화된다면 쟁점은 세 가지가 될 가능성이 큽니다. 첫째, RAMPART가 실제 복잡한 에이전트 하네스와 얼마나 쉽게 붙는가입니다. 각 팀의 에이전트 런타임, 도구 호출 로깅, 샌드박스 구조가 다르면 어댑터 비용이 달라집니다. 둘째, statistical trials가 CI 비용을 얼마나 늘리는가입니다. 셋째, Clarity 문서가 개발 속도를 늦추는 관료제로 보일지, 아니면 에이전트 시대의 ADR로 자리 잡을지입니다.
이 발표의 숨은 메시지
RAMPART와 Clarity가 전하는 메시지는 단순합니다. 에이전트를 제품으로 배포하려면 “모델이 똑똑하다”만으로 부족합니다. 에이전트가 어떤 데이터를 읽고, 어떤 도구를 호출하고, 어떤 조건에서 멈추며, 어떤 설계 가정 위에서 작동하는지 설명할 수 있어야 합니다. 이 설명은 프레젠테이션 문구가 아니라 테스트, 로그, 문서, PR 리뷰에 남아야 합니다.
이는 AI 개발자에게 꽤 현실적인 압박입니다. 앞으로 에이전트 팀은 프롬프트와 모델 선택만 관리하지 않을 가능성이 큽니다. 위협 모델, 오염된 컨텍스트 샘플, 도구별 금지 행동, 승인 정책, 반복 실행 기준, 설계 의사결정 문서까지 관리해야 합니다. 일반 웹 서비스가 성장하면서 단위 테스트, 통합 테스트, SAST, DAST, observability, incident postmortem을 받아들였듯이, 에이전트도 비슷한 엔지니어링 층을 갖게 됩니다.
다만 이 변화는 반드시 부정적이지 않습니다. 지금까지 많은 에이전트 제품은 데모에서는 놀랍지만 운영에서는 불안했습니다. “프롬프트를 잘 쓰면 된다”는 수준의 통제는 기업 시스템과 맞지 않습니다. RAMPART는 에이전트 안전을 깨지는 테스트로 만들고, Clarity는 왜 그런 경계를 세웠는지 기록하게 합니다. 둘 다 완성된 답은 아니지만, 에이전트 개발이 장난감 데모에서 운영 소프트웨어로 이동할 때 필요한 언어를 제공합니다.
결국 이번 발표의 핵심은 Microsoft가 또 하나의 에이전트 도구를 냈다는 사실이 아닙니다. 에이전트 안전의 기본 단위가 바뀌고 있다는 점입니다. 안전은 더 이상 모델 카드 한 장이나 출시 전 리뷰 회의만으로 충분하지 않습니다. 앞으로는 “이 에이전트가 이 문서를 읽고도 위험한 도구를 호출하지 않는가”, “그 판단을 CI에서 반복 검증하는가”, “왜 그런 권한을 줬는지 저장소에서 추적할 수 있는가”가 더 중요한 질문이 됩니다. RAMPART와 Clarity는 바로 그 질문을 개발자의 일상 도구 안으로 끌고 들어온 첫 v0.1 신호입니다.