Microsoft 5B 코딩 모델, Copilot 기본 선택지로 배포
MAI-Code-1-Flash가 GitHub Copilot VS Code 모델 선택기에 들어갔습니다. 5B 코딩 모델의 성능·비용·벤치마크 한계를 짚습니다.

- 무슨 일: Microsoft AI가 MAI-Code-1-Flash를 공개하고 GitHub Copilot의 VS Code 모델 선택기와 Auto picker에 순차 배포합니다.
- GitHub Changelog는 Copilot Free, Pro, Pro+, Max 개인 사용자부터 제한적으로 시작한다고 밝혔습니다.
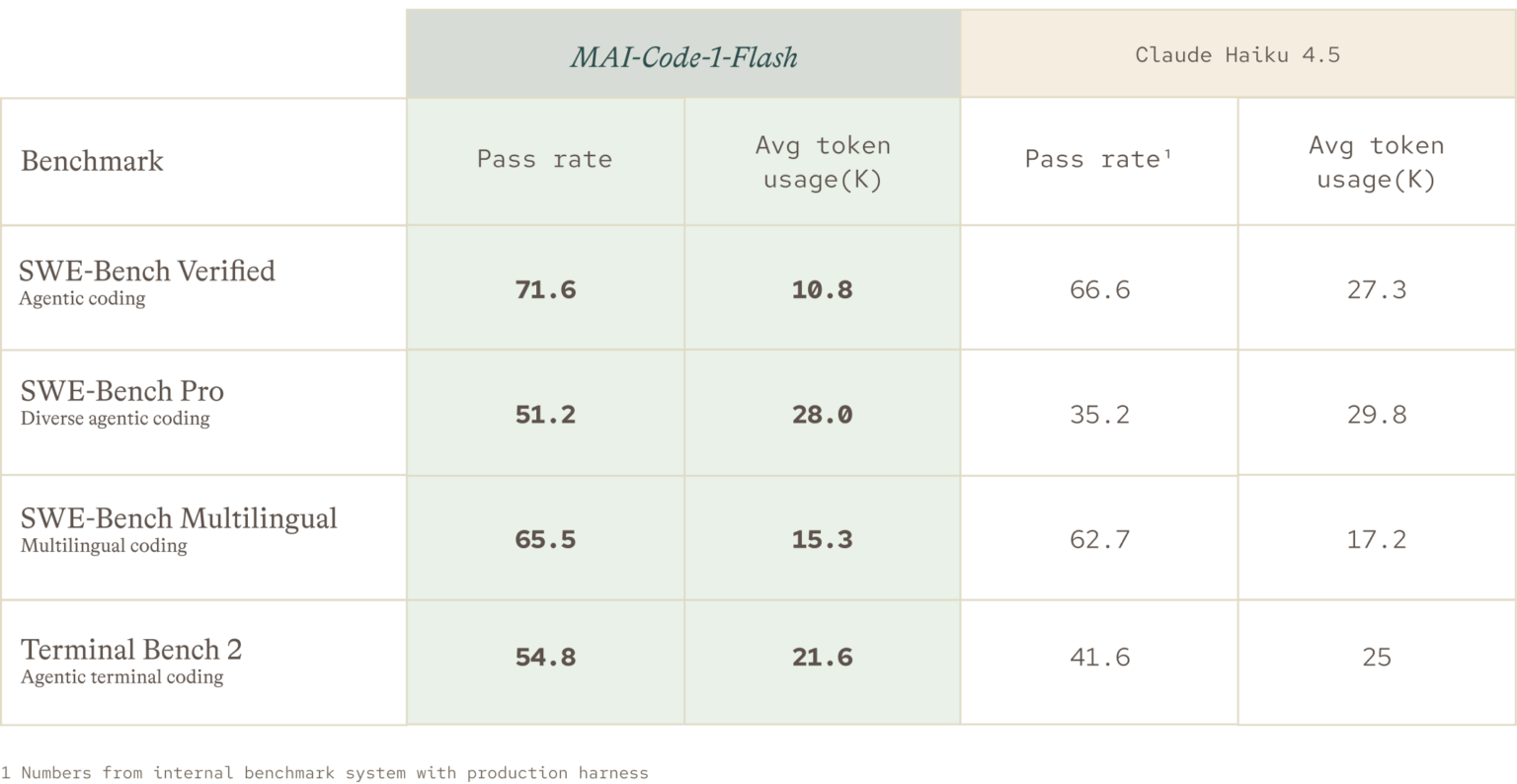
- 숫자: Microsoft는 5B active parameter, SWE-Bench Pro 51.2%, Claude Haiku 4.5 대비 최대 60% 적은 토큰을 제시했습니다.
- 의미: Copilot이 외부 모델을 고르는 클라이언트에서 Microsoft 자체 코딩 모델을 기본 경로로 라우팅하는 제품이 됩니다.
- 주의점: 공개 수치는 Microsoft의 production harness 기준입니다. 실제 비용·지연·정확도는 팀별 저장소와 Copilot 라우팅에서 다시 봐야 합니다.
Microsoft가 GitHub Copilot 안에 자체 코딩 모델을 넣기 시작했습니다. Microsoft AI는 2026년 6월 2일 MAI-Code-1-Flash를 공개했습니다. GitHub는 같은 날 Changelog에서 이 모델이 VS Code의 Copilot 모델 선택기에 순차 배포된다고 밝혔습니다. 적용 대상은 Copilot Free, Pro, Pro+, Max 개인 사용자이며, 시작은 제한된 사용자 집단이고 몇 주에 걸쳐 확대됩니다.
이번 발표를 단순한 "새 모델 출시"로 읽으면 핵심이 작아집니다. MAI-Code-1-Flash는 Microsoft AI가 따로 공개한 데모 모델이 아니라 GitHub Copilot의 실제 제품 경로에 들어갑니다. 사용자는 모델 선택기에서 직접 고를 수 있고, Auto picker를 쓰는 경우 GitHub Copilot이 이 모델로 작업을 라우팅할 수 있습니다. Copilot은 이제 OpenAI, Anthropic, Google 모델을 붙이는 표면을 넘어 Microsoft가 직접 만든 코딩 모델을 기본 후보로 넣는 배포 채널이 됩니다.
Microsoft AI의 설명에서 가장 먼저 보이는 숫자는 5B active parameter입니다. Mustafa Suleyman의 MAI 모델군 발표는 MAI-Code-1-Flash를 "inference-efficient agentic coding model"로 부릅니다. 같은 문단은 이 모델이 GitHub Copilot, VS Code, Microsoft stack에 깊게 통합됐다고 설명합니다. 같은 발표는 7개 MAI 모델이 이미지, 음성, 전사, 코딩, 추론을 덮는 Microsoft 자체 모델군이라고 정리했습니다.
GitHub Copilot 관점에서 5B라는 크기는 성능보다 운영 단위에 가깝습니다. Copilot Chat에서 단순 수정, 테스트 추가, 짧은 리팩터링, 에러 로그 해석 같은 작업은 대형 reasoning model을 항상 필요로 하지 않습니다. 사용자가 키보드 앞에 앉아 있을 때는 첫 토큰 지연, 응답 길이, 모델 라우팅 비용이 체감 품질을 좌우합니다. Microsoft가 Flash 이름을 붙인 이유도 "가장 똑똑한 모델"보다 "자주 부를 수 있는 모델"을 Copilot 안에 두려는 선택으로 읽을 수 있습니다.
공식 블로그가 제시한 핵심 성능 비교는 Claude Haiku 4.5와의 대조입니다. Microsoft는 SWE-Bench Verified, SWE-Bench Pro, SWE-Bench Multilingual, Terminal Bench 2를 같은 production harness에서 평가했다고 설명합니다. 이 중 SWE-Bench Pro에서는 MAI-Code-1-Flash가 51.2%, Claude Haiku 4.5가 35.2%였다고 적었습니다. Microsoft는 이 차이를 "+16-point lead"로 표현했습니다. SWE-Bench Verified에서는 더 어려운 문제를 최대 60% 적은 토큰으로 풀었다고 밝혔습니다.
토큰 효율은 코딩 에이전트에서 별도 지표로 봐야 합니다. 같은 pass rate라도 모델이 2배 긴 reasoning trace와 patch 설명을 만들면 사용자는 더 늦게 결과를 보고, 조직은 더 많은 비용을 냅니다. Copilot이 여러 파일을 읽고, 테스트 실패를 분석하고, 터미널 로그를 다시 요약하는 작업에서는 토큰이 곧 latency와 과금의 일부입니다. Microsoft가 "value per token"을 전면에 둔 것은 코딩 모델 경쟁의 비교 기준이 benchmark score 하나에서 pass rate, solution tokens, 라우팅 비용으로 쪼개졌다는 뜻입니다.
다만 이 수치는 독립 leaderboard의 최종 결론처럼 읽기 어렵습니다. Microsoft는 "same production harness"를 강조합니다. 제품 harness는 실제 Copilot 환경을 반영한다는 장점이 있지만, 외부 독자가 동일 조건을 재현하기 어렵다는 단점도 있습니다. Hacker News의 첫 반응 중 하나도 SWE-Bench Pro 평가 세트와 훈련 사이의 경계를 물었습니다. 다른 댓글은 모델 카드와 더 넓은 MAI 발표를 근거로 봐야 한다고 답했고, 또 다른 댓글은 flash 모델이라면 tokens per second 수치가 필요하다고 지적했습니다.
이 논쟁은 불필요한 흠집 잡기가 아닙니다. 코딩 모델 벤치마크는 모델이 어떤 도구를 썼는지, 테스트를 몇 번 돌렸는지, patch 실패를 어떻게 처리했는지에 따라 결과가 달라집니다. SWE-Bench 계열은 문제 해결 능력을 보는 데 유용하지만, Copilot 제품에서는 repository indexing, terminal access, context packing, instruction hierarchy, billing policy가 함께 작동합니다. Microsoft의 발표는 "Copilot 안에서는 이 모델이 잘 작동한다"는 주장에 가깝고, "모든 환경에서 Claude Haiku 4.5보다 낫다"는 주장으로 확장하면 근거가 약해집니다.
MAI-Code-1-Flash가 흥미로운 부분은 훈련 목표입니다. Microsoft AI는 이 모델이 GitHub Copilot production harness에 맞춰 훈련·설계됐다고 밝혔습니다. 블로그는 repository question answering, refactoring, telemetry-grounded tasks, core software engineering tasks를 평가에 썼다고 설명합니다. 이는 공개 benchmark만 잘 맞춘 모델보다, Copilot이 실제로 받는 요청 분포와 도구 사용 방식을 모델 학습 루프에 넣겠다는 접근입니다.
이 접근은 Cursor, Claude Code, OpenAI Codex와 다른 출발점을 만듭니다. Claude Code와 Codex는 모델과 에이전트 제품이 같은 브랜드로 묶여 있고, 사용자는 CLI·앱·브라우저·샌드박스 단위로 경험합니다. GitHub Copilot은 GitHub, VS Code, Visual Studio, JetBrains, Codespaces, Actions, code review, issue를 이미 갖고 있습니다. Microsoft의 선택은 새 독립 코딩 앱보다 기존 Copilot 표면에서 모델을 갈아 끼우고, Auto picker가 작업별로 비용과 품질을 조절하게 만드는 쪽입니다.
GitHub Changelog의 문장도 이 해석을 뒷받침합니다. GitHub는 MAI-Code-1-Flash를 "first in a new wave of purpose-built coding models from Microsoft"라고 설명했습니다. "새로운 물결"이라는 표현은 이번 모델이 단발 발표가 아니라 Copilot용 특화 모델군의 시작이라는 뜻입니다. Free와 Pro 계층까지 포함한 점도 중요합니다. 저렴하고 빠른 모델은 프리미엄 reasoning model보다 더 넓은 사용자층의 기본 경험을 바꿉니다.
Microsoft의 더 큰 발표와 연결하면 공급망 메시지가 드러납니다. 같은 날 공개된 7개 MAI 모델 발표는 "clean and appropriately licensed data", "zero distillation", "Microsoft stack"을 반복했습니다. 최근 기업 고객은 모델 성능만 묻지 않습니다. 학습 데이터 출처, 라이선스 리스크, 데이터 보존, 조달 계약, 장애 시 대체 모델, 특정 벤더 의존도를 함께 봅니다. Copilot이 Microsoft 자체 코딩 모델을 기본 선택지로 갖게 되면 GitHub은 외부 모델 가격과 availability에 덜 묶인 라우팅 전략을 만들 수 있습니다.
개발자에게 당장 달라지는 부분은 작지만 명확합니다. VS Code에서 Copilot 모델 선택기를 열면 MAI Code 1 Flash가 보일 수 있습니다. Auto를 쓰는 사용자는 별도 설정 없이 일부 요청이 이 모델로 갈 수 있습니다. 짧은 코드 생성, 테스트 보강, 설명, 오류 메시지 해석 같은 작업에서 응답이 충분히 좋고 빠르다면 사용자는 모델명을 신경 쓰지 않을 가능성이 큽니다. 반대로 복잡한 설계 변경이나 여러 패키지를 건드리는 장기 작업에서는 여전히 더 큰 reasoning model이 필요할 수 있습니다.
팀 단위 도입에서는 세 가지를 확인해야 합니다. 첫째, Copilot의 Auto picker가 어떤 요청을 MAI-Code-1-Flash로 보내는지 관측할 수 있는지입니다. 둘째, 조직의 coding standard와 private repository에서 작은 모델이 충분히 안전한 patch를 만드는지입니다. 셋째, token-based billing에서 실제 비용 차이가 얼마나 나는지입니다. Microsoft Build 키노트 transcript의 주석은 GitHub Copilot의 새 token-based billing에서 MAI-Code-1-Flash가 Claude Haiku 4.5보다 싸다고 적지만, 팀별 총액은 호출 빈도와 자동 라우팅 정책에 따라 달라집니다.
커뮤니티 반응은 이 세 질문을 이미 건드립니다. Hacker News 스레드는 2026년 6월 3일 확인 시점에 500점대와 200개가 넘는 댓글을 기록했습니다. 일부 사용자는 5B active parameter로 51% SWE-Bench Pro가 가능하다는 점을 작고 특화된 모델의 신호로 읽었습니다. 다른 사용자는 Gemma 4 계열처럼 active parameter가 낮아도 높은 점수를 내는 사례가 있다며 놀랄 일은 아니라고 봤습니다. 또 다른 축은 flash 모델의 속도입니다. pass rate보다 tokens per second를 보고 싶다는 요구가 반복됐습니다.
한국 개발자 커뮤니티에서도 이 발표는 빠르게 들어왔습니다. GeekNews 홈에는 2026년 6월 3일 기준 MAI-Code-1-Flash 항목이 올라왔고, 설명은 VS Code의 GitHub Copilot 개인 사용자에게 제공되며 적응형 사고와 토큰 효율을 강조했습니다. 이미 Copilot, Claude Code, Cursor, Codex를 동시에 쓰는 개발자에게 이 뉴스는 "또 하나의 모델"이 아니라 모델 선택이 제품 기본값으로 숨어 들어가는 장면입니다.
이번 발표에서 조심해야 할 표현은 "OpenAI 의존 종료"입니다. Microsoft와 OpenAI의 관계, Azure 공급, Copilot의 다른 모델 선택지는 여전히 복잡합니다. 하지만 Copilot의 기본 경로에 Microsoft 자체 코딩 모델이 들어간 것은 의존도를 낮추는 실무적 단계입니다. 모델 공급망을 완전히 바꿨다고 말하기보다는, Microsoft가 가장 사용량이 많을 수 있는 everyday coding workflow부터 자체 모델로 처리할 수 있는 발판을 만든 것으로 보는 편이 정확합니다.
앞으로 볼 지표는 네 가지입니다. MAI-Code-1-Flash가 Copilot Auto picker에서 어느 비중으로 선택되는지, enterprise Copilot에서도 같은 모델이 어떤 정책 아래 제공되는지 먼저 봐야 합니다. 그다음은 GitHub이 모델별 latency·token·success telemetry를 관리자에게 얼마나 공개하는지, Microsoft가 다음 purpose-built coding model을 어떤 크기와 가격대로 내놓는지입니다. 이 지표가 나오면 이번 발표가 발표용 모델인지, Copilot의 비용 구조를 바꾸는 기본 엔진인지 구분할 수 있습니다.
MAI-Code-1-Flash는 frontier model 경쟁의 주인공은 아닙니다. 그러나 개발자가 하루에 수십 번 부르는 Copilot 요청을 처리하는 모델이라면 영향은 작지 않습니다. 코딩 AI 시장에서 매번 가장 큰 모델을 고르는 시대는 비용과 지연 때문에 오래가기 어렵습니다. Microsoft는 Copilot 안에서 "작고 빠른 자체 모델을 먼저 쓰고, 더 어려운 작업만 큰 모델로 넘기는" 라우팅 전략을 공개 제품에 넣기 시작했습니다. 이 변화는 모델 성능표보다 Copilot의 기본값에서 더 크게 나타날 수 있습니다.