Foundry ROI 대시보드, 에이전트 비용을 추적하는 운영 루프
Microsoft Foundry가 에이전트 tracing, rubric 평가, optimizer, ROI dashboard를 Agent DevOps 루프로 묶었습니다.

- 무슨 일: Microsoft가 2026년 6월 3일 Foundry agent observability 확장을 공개했습니다.
- tracing·evaluations GA 위에 any framework tracing, multi-turn eval, rubric evaluator, trace replay, ROI 기능을 얹었습니다.
- 운영 단위: prompt, model call, tool invocation, sub-agent hop을
OpenTelemetrytrace로 모읍니다.- 대상은 LangChain, LangGraph, OpenAI SDK, Microsoft Agent Framework, custom framework입니다.
- 실무 영향: 에이전트 품질 논의가 데모 성공률에서 trace replay, rubric score, cost efficiency로 이동합니다.
- 주의점: Agent optimizer와 ROI for agents는 private preview입니다. 실제 비용 귀속은 고객 데이터와 업무 정의에 달려 있습니다.
Microsoft가 2026년 6월 3일 Foundry Blog에서 AI 에이전트 관측성 기능을 Build 2026 발표 묶음으로 공개했습니다. 발표문은 "Shipping an AI agent is the easy part"라는 문장으로 시작합니다. 기사에서 볼 부분은 새 데모가 아니라, Microsoft가 에이전트 운영의 기준을 trace, eval, optimizer, ROI dashboard로 재정의하려 한다는 점입니다. tracing과 evaluations는 Foundry에서 GA에 도달했고, Build 발표에서는 여러 framework와 배포 위치를 Foundry observability로 연결하는 public preview가 붙었습니다.
이번 발표는 이미 나온 Microsoft Build 2026의 hosted agents, Work IQ APIs, MXC, MDASH와 다른 위치에 있습니다. hosted agents는 실행 환경입니다. Work IQ는 Microsoft 365 업무 컨텍스트와 action surface입니다. MXC와 MDASH는 실행 격리와 보안 검증입니다. 6월 3일 Foundry observability 글은 에이전트가 production에서 실제로 무엇을 했고, 어느 단계에서 품질이 낮아졌고, 비용 대비 업무 결과가 있었는지를 측정하는 운영 루프에 초점을 둡니다.
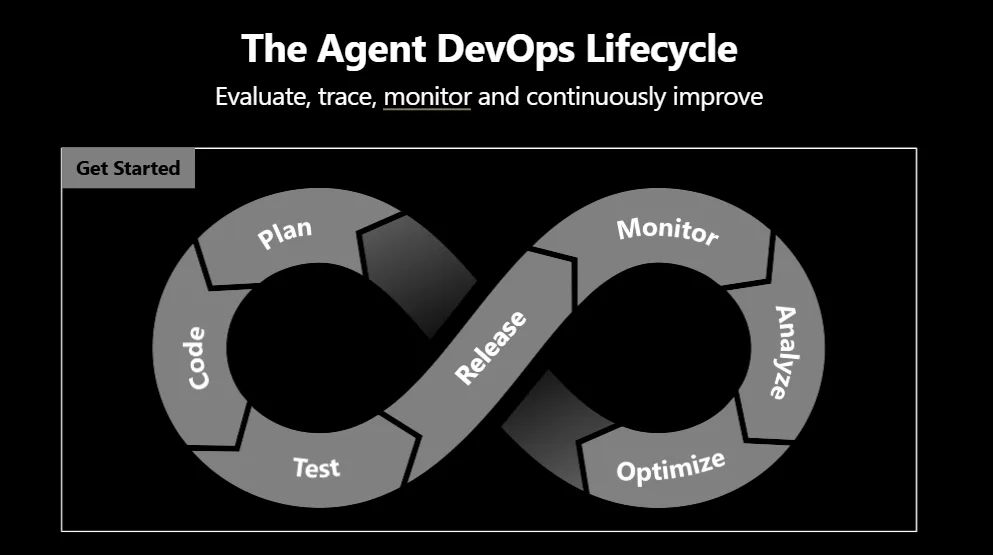
Microsoft가 문제로 잡은 대상은 deterministic software의 장애가 아닙니다. 일반 서비스는 같은 입력과 같은 코드에서 대체로 같은 경로를 탑니다. 에이전트는 같은 사용자 요청에서도 오늘은 검색 도구를 먼저 쓰고, 내일은 하위 에이전트를 호출하고, 모델 업데이트 뒤에는 다른 tool route를 선택할 수 있습니다. Foundry Blog는 model update, tool change, traffic pattern 변화 뒤에 drift가 조용히 생긴다고 설명합니다. 이 문장은 운영팀이 error rate와 latency만 봐서는 에이전트 품질을 판단하기 어렵다는 뜻입니다.
Foundry observability의 기본 축은 네 가지입니다. Trace는 prompt, model call, tool invocation, sub-agent hop을 end-to-end telemetry로 남깁니다. Evaluate는 quality, safety, task completion을 single-turn과 multi-turn 단위로 점수화합니다. Monitor는 Azure Monitor alert와 dashboard로 production issue를 봅니다. Optimize는 trace와 eval 결과를 agent 개선 후보로 바꿉니다. 이 네 단어는 마케팅 분류가 아니라, 에이전트 운영에서 기록해야 하는 데이터 타입을 나눕니다.
Build 2026의 첫 public preview는 interoperability입니다. Foundry의 tracing and evaluations가 LangChain, LangGraph, OpenAI SDK, Microsoft Agent Framework, custom framework까지 확장됩니다. 연결 방식은 OpenTelemetry입니다. 이미 agent run을 OTel span으로 내보내는 팀이라면 exporter를 Foundry로 향하게 하는 구성이 출발점입니다. Microsoft는 "any agent, on any framework"라고 말하지만, 실제 실무에서는 각 framework의 span 구조와 tool metadata가 Foundry 평가 UI에서 얼마나 일관되게 보이는지가 adoption을 좌우합니다.
이 지점은 AI 팀의 기존 관측성 선택과 충돌합니다. LangSmith, Braintrust, Arize Phoenix, custom OpenTelemetry collector를 이미 쓰는 팀은 Foundry가 새 기록 저장소인지, Azure Monitor와 연결되는 enterprise plane인지, 특정 Foundry agent를 위한 보조 UI인지 구분해야 합니다. Microsoft의 장점은 Azure Monitor, Foundry Agent Service, Microsoft Agent Framework, Agent 365와 같은 관리 계층을 묶을 수 있다는 점입니다. 반대로 multi-cloud 조직은 trace export와 data residency, evaluator model 호출 위치를 별도로 검토해야 합니다.
두 번째 묶음은 development loop 안의 평가 기능입니다. azd observability dev experience는 Azure Developer CLI에서 tracing, logging, eval insights를 보여주는 public preview입니다. hosted agent를 새로 만들 때 guided experience에서 observability를 켜고, 첫 실행 trace와 evaluation result를 terminal이나 VS Code에서 확인하는 흐름입니다. agent debugging을 별도 dashboard로 밀어내지 않고 CLI와 editor 안에 넣겠다는 결정입니다. 이는 개발자가 failure trace를 보지 않은 채 prompt만 고치는 반복을 줄이는 데 맞춰져 있습니다.
User simulation도 public preview입니다. Microsoft는 realistic test conversations와 edge-case scenarios를 자동 생성해 실제 사용자 투입 전에 pressure-test할 수 있다고 설명했습니다. 이 기능은 고객지원 agent나 compliance reviewer처럼 multi-turn 상태가 긴 agent에서 중요합니다. 사람이 모든 테스트 대화를 손으로 쓰면 coverage가 작아지고, 모델이 바뀔 때마다 같은 품질 기준을 재현하기 어렵습니다. simulation은 production traffic을 대체하지 못하지만, release 전 regression suite를 늘리는 방법이 됩니다.
Multi-turn evaluation은 single-turn eval의 빈틈을 겨냥합니다. 한 번의 답변만 보면 맞아 보이지만, 다섯 번째 턴에서 사용자의 목표를 잃거나 tone이 달라지거나 이전 tool result를 잘못 기억하는 agent가 있습니다. Microsoft는 multi-turn evaluation이 context carryover, reasoning consistency, end-to-end task success를 본다고 적었습니다. 개발팀 입장에서는 "이 답변이 맞는가"보다 "이 workflow가 끝까지 완료됐는가"를 평가할 수 있어야 합니다. 일정 예약, 주문 수정, incident triage 같은 agent는 마지막 action까지 봐야 합니다.
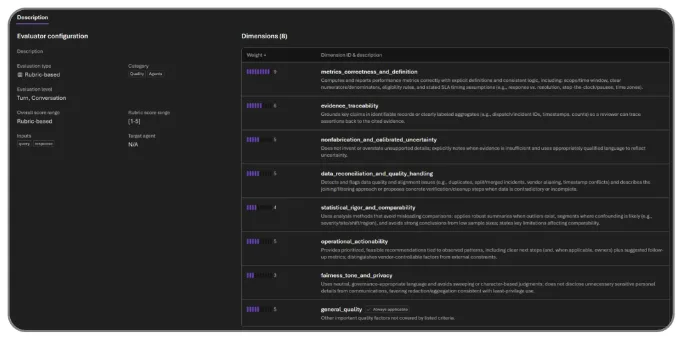
Rubric evaluator는 이번 발표에서 가장 제품적인 기능입니다. Microsoft는 vendor history agent, customer support agent, compliance reviewer마다 "좋음"의 기준이 다르다고 설명합니다. Rubric evaluator는 agent의 intended behavior에서 context-aware evaluation criteria를 만들고, task success, tone, safety, cost, latency 같은 dimension에 weight를 붙입니다. 그 결과를 Foundry의 built-in safety and quality evaluators와 함께 scorecard로 돌립니다. 평가 기준이 prompt 밖의 별도 artifact가 되는 셈입니다.
이 기능은 LLM-as-judge를 쓰는 많은 팀이 겪는 문제를 건드립니다. "정확하고 친절한 답변" 같은 일반 rubric은 거의 모든 agent에 붙일 수 있지만, 실제 운영에서는 업무별 실패 비용이 다릅니다. vendor history agent가 계약 날짜를 틀리는 것과 support agent가 tone을 딱딱하게 쓰는 것은 같은 failure가 아닙니다. compliance reviewer는 모르는 내용을 추측하는 것보다 근거 문서가 없다고 멈추는 편이 낫습니다. Rubric evaluator가 가치 있으려면, generated rubric을 사람이 검토하고 versioning하는 workflow가 함께 있어야 합니다.
Intelligent trace sampling은 비용 문제를 다룹니다. production trace를 모두 평가하면 evaluation cost가 커집니다. 아무 trace도 평가하지 않으면 품질 하락을 놓칩니다. Microsoft는 signal-rich interactions를 걸러 curated sample에 evaluation을 돌린다고 설명했습니다. 이 기능은 agent 운영에서 흔한 타협입니다. 샘플링 기준이 실패율, high-cost run, sensitive tool call, long conversation, low confidence 같은 조건을 잘 잡아야 합니다. 그렇지 않으면 대시보드는 깔끔하지만 진짜 위험 trace는 빠질 수 있습니다.
Trace replay and visualization은 incident review에 직접 연결됩니다. Microsoft는 prompt, decision, tool call, model output을 시각적으로 따라가고 replay할 수 있다고 적었습니다. 실패를 재현하기 위해 사용자의 원래 문장을 다시 추측하는 대신, 깨진 실행 trace를 후보 수정안에 다시 돌리는 방식입니다. coding agent나 business workflow agent에서는 이 차이가 큽니다. 모델 답변만 저장하면 원인을 잃습니다. tool input, tool output, intermediate state, handoff까지 남아야 "왜 이 이메일을 보냈는가"를 나중에 설명할 수 있습니다.
Traces to dataset은 production과 offline eval의 거리를 줄입니다. Microsoft는 production traces를 structured evaluation datasets로 바꿔 offline에서 다시 쓸 수 있다고 설명했습니다. 이 기능은 release engineering 관점에서 중요합니다. 실제 사용자가 만든 실패 사례를 다음 버전의 regression dataset에 넣을 수 있기 때문입니다. 다만 privacy와 retention 정책이 함께 필요합니다. production trace에는 사용자 입력, 업무 문서, tool output, 개인 정보가 들어갈 수 있습니다. dataset 전환은 기술 기능이면서 동시에 data governance 작업입니다.
| 기능 | Build 2026 상태 | 검토할 질문 |
|---|---|---|
| Tracing & evaluations | GA, any framework 확장은 public preview | 기존 OTel span과 tool metadata가 Foundry에서 보존되는가 |
| Rubric evaluator | Public preview | 업무별 rubric을 사람이 검토하고 versioning하는가 |
| Trace replay | Public preview | 실패 trace를 incident review와 release gate에 연결하는가 |
| ROI for agents | Private preview | task completion, time saved, cost efficiency를 누가 정의하는가 |
Agent optimizer는 private preview입니다. Foundry Blog는 optimizer가 agent의 current prompts와 skills를 읽고, scenario와 constraint에서 quality를 높이는 configuration 후보를 찾고, full diffs, lineage, audit trail, rollback을 제공한다고 설명했습니다. Microsoft Command Line의 별도 글은 이 루프를 더 구체적으로 풀었습니다. optimizer는 instructions, models, skills, tool definitions를 search space로 보고, evaluator suite로 baseline과 후보를 같은 bar에서 비교합니다. candidate는 점수표 없이 바로 배포되는 것이 아니라 developer review를 거칩니다.
이 접근은 prompt engineering을 CI에 더 가깝게 만듭니다. 지금 많은 팀은 agent instruction을 고치고, 몇 개 sample을 돌리고, production에서 문제가 줄었는지 기다립니다. optimizer가 실제로 쓸모 있으려면 candidate generation보다 comparison discipline이 중요합니다. 같은 dataset, 같은 evaluator, 같은 cost constraint에서 baseline과 후보를 비교해야 합니다. 성능이 오른 dimension과 떨어진 dimension을 분리해서 보여줘야 합니다. "더 좋아졌다"가 아니라 "routing accuracy는 올랐지만 latency와 cost가 늘었다"가 나와야 운영 결정이 됩니다.
ROI for agents도 private preview입니다. Microsoft는 task completion rates, time saved, cost efficiency를 Foundry portal과 API에서 나란히 보여주고, version comparison, daily trends, low-ROI trace drill-down을 제공한다고 설명했습니다. CFO가 물어볼 질문에 답하겠다는 표현도 들어갔습니다. 이 기능은 agent 시장의 현재 압박을 잘 드러냅니다. 2025년과 2026년의 에이전트 데모는 "가능하다"를 많이 보여줬습니다. enterprise buyer는 이제 "얼마나 자주 성공했고, 얼마를 썼고, 어느 workflow에서 값어치가 있었는가"를 묻습니다.
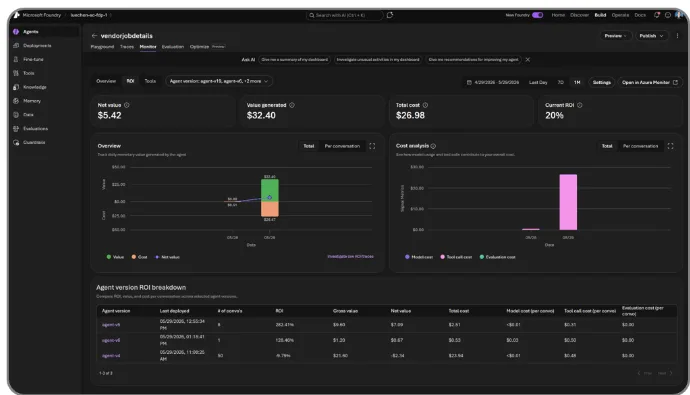
ROI dashboard가 어려운 이유는 비용보다 value 정의입니다. token, model call, tool call, latency는 비교적 계측하기 쉽습니다. time saved는 업무별 baseline이 필요합니다. task completion rate는 성공 조건을 사람이 정해야 합니다. cost efficiency는 실패한 실행까지 포함해야 합니다. 예를 들어 incident triage agent가 20분을 줄였지만 잘못된 escalation을 한 번 만들었다면, 단순 time saved는 실제 운영 가치를 과장합니다. Foundry가 trace drill-down을 넣은 이유도 aggregate chart만으로는 이 판단이 불가능하기 때문입니다.
이번 발표는 Microsoft의 다른 agent governance 발표와도 맞물립니다. 6월 2일 Foundry Blog는 ASSERT와 Agent Control Specification을 공개하며 open eval과 control standard를 설명했습니다. Work IQ는 업무 데이터와 action plane을 엽니다. Agent 365는 agent inventory와 governance를 봅니다. Foundry observability는 agent run의 trace와 평가 결과를 모읍니다. ROI dashboard는 그 run이 비용 대비 어떤 business value를 만들었는지 묻습니다. 각각 다른 제품처럼 보이지만, Build 2026에서는 enterprise agent 운영 체계의 일부로 배열됐습니다.
경쟁 구도는 이미 복잡합니다. LangSmith는 LangChain/LangGraph 생태계의 tracing과 eval에 강합니다. Braintrust는 eval dataset, experiment, prompt iteration을 전면에 둡니다. Arize Phoenix는 open-source observability와 tracing을 내세웁니다. OpenAI Evals나 Promptfoo 같은 도구는 특정 평가와 regression 흐름에 쓰입니다. Microsoft Foundry의 차별점은 평가 도구 하나가 아니라 Azure Monitor, Foundry Agent Service, Microsoft Agent Framework, Agent 365, Microsoft 365 배포 경로와 연결된다는 점입니다. 약점은 Azure 중심 운영 모델을 받아들여야 한다는 점입니다.
개발팀이 이 발표를 검토한다면 첫 질문은 "Foundry를 써야 하는가"가 아닙니다. 이미 production agent가 있다면 먼저 현재 trace에 무엇이 빠져 있는지 봐야 합니다. model input과 output만 저장하는지, tool call과 tool result까지 남기는지, sub-agent handoff를 구분하는지, user approval과 policy violation을 같은 timeline에서 볼 수 있는지 확인해야 합니다. 이 항목이 없으면 어떤 observability 제품을 붙여도 failure analysis가 빈약합니다.
두 번째 질문은 evaluation ownership입니다. Rubric evaluator가 기준을 자동 생성하더라도 최종 기준은 product owner, security reviewer, domain expert가 봐야 합니다. 고객지원 agent의 tone, 법무 agent의 citation, coding agent의 test pass, finance agent의 calculation tolerance는 같은 팀이 정할 수 없습니다. evaluation score가 release gate가 되려면 rubric 변경도 code review처럼 기록되어야 합니다. Microsoft가 lineage와 audit trail을 optimizer 설명에 넣은 이유가 여기에 있습니다.
세 번째 질문은 비용 귀속입니다. ROI for agents가 task completion과 cost efficiency를 보여주려면 agent run이 어느 user, team, customer, workflow, business process에 속하는지 알아야 합니다. 계측이 모델 비용까지만 닿으면 "이번 달에 많이 썼다"는 말밖에 못 합니다. 구매 승인과 운영 개선에 필요한 것은 "어느 workflow가 낮은 ROI trace를 만들었고, 어떤 tool step에서 실패 비용이 생겼는가"입니다. 이 데이터 모델은 dashboard 도입 전부터 설계해야 합니다.
네 번째 질문은 data retention입니다. traces to dataset은 매력적이지만, production trace를 평가 dataset으로 바꾸는 순간 민감 정보가 학습·평가 자산이 됩니다. Microsoft 365 문서, customer support transcript, source code, incident log가 trace 안에 들어갈 수 있습니다. 따라서 masking, retention period, access control, deletion workflow가 필요합니다. 에이전트 품질을 높이려는 데이터가 compliance risk를 새로 만들면 운영 루프 전체가 멈춥니다.
커뮤니티 반응은 아직 기능별로 크지 않습니다. Hacker News나 GeekNews에서 Foundry ROI 발표 자체가 큰 토론으로 번지지는 않았습니다. 한국어 Build 2026 요약 글은 Rubric Evaluator와 Agent Optimizer가 production trace를 읽어 평가 기준과 개선 후보를 만든다는 점을 따로 짚었습니다. 더 넓은 개발자 반응은 AI coding agent의 비용, quota, 품질 변동, governance 부족에 대한 불만이 많습니다. Microsoft가 ROI dashboard를 발표한 배경도 이 질문과 맞닿아 있습니다. agent가 비싸졌다는 느낌을 대시보드가 해결하지는 못하지만, 어디서 비용이 새는지는 보여줄 수 있습니다.
이번 발표의 실무 결론은 좁고 분명합니다. production agent 운영에서 "잘 답했는가"만으로는 부족합니다. 어떤 prompt와 tool route를 탔는지, multi-turn 목표를 끝까지 유지했는지, rubric 기준에서 어느 dimension이 떨어졌는지, 같은 실패 trace가 새 버전에서 재현되는지, 그 실행이 시간 절감과 비용 효율로 이어졌는지를 봐야 합니다. Microsoft Foundry의 새 기능들은 이 질문을 하나의 Agent DevOps loop로 묶으려는 시도입니다.
앞으로 확인할 지표는 세 가지입니다. 첫째, any framework tracing이 실제 LangChain, LangGraph, OpenAI SDK agent의 복잡한 handoff를 얼마나 보존하는지입니다. 둘째, Rubric evaluator가 만든 기준이 domain expert 검토와 release gate에 들어갈 만큼 안정적인지입니다. 셋째, ROI for agents가 private preview를 벗어날 때 task completion, time saved, cost efficiency 정의를 고객이 얼마나 세밀하게 바꿀 수 있는지입니다. 에이전트 운영의 병목은 모델 이름보다 관측 데이터, 평가 기준, 비용 귀속으로 이동하고 있습니다.