LiteRT-LM WebGPU, 로컬 에이전트가 브라우저 안으로
Google LiteRT-LM은 Gemma 4 로컬 추론을 Android, iOS, WebGPU, CLI로 넓히며 AI 앱 배포 표면을 바꿉니다.

- 무슨 일: Google이
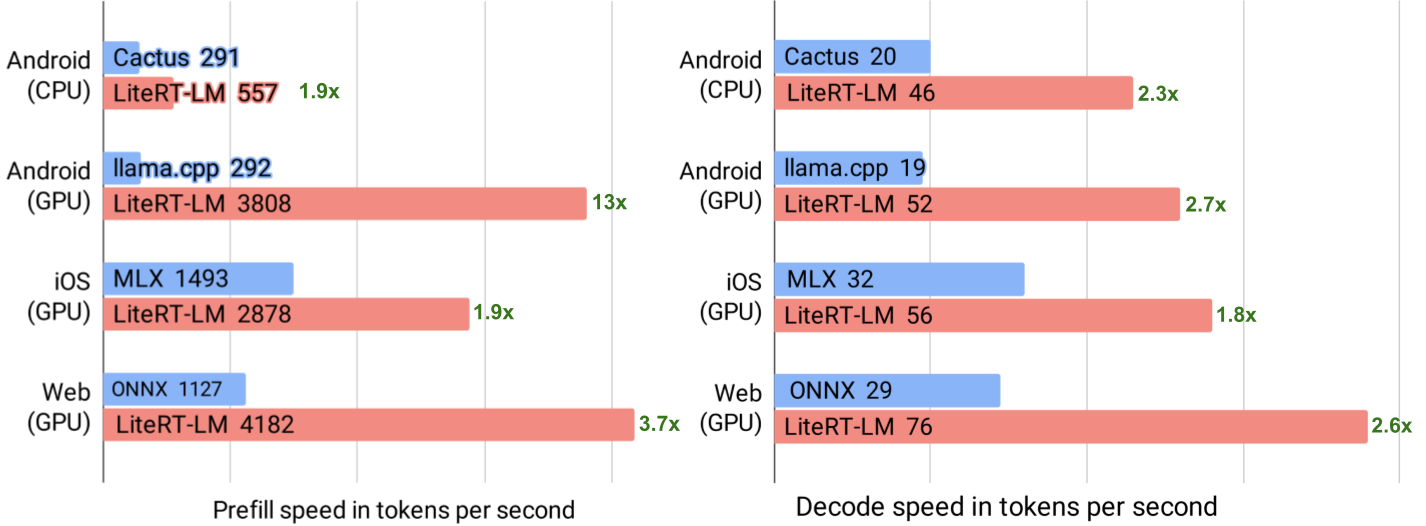
LiteRT-LM업데이트로 Gemma 4 로컬 추론을 Android, iOS, WebGPU, CLI까지 확장했습니다.- 발표 수치는 Gemma 4 E2B 기준 Android GPU 52 tokens/sec, iOS Metal 56 tokens/sec, WebGPU 76 tokens/sec입니다.
- 의미: 온디바이스 AI 경쟁이 모델 파일이 아니라 runtime, backend, 브라우저 배포, agentic I/O로 이동하고 있습니다.
- 주의점: WebGPU 성능은 기기와 브라우저 조건에 민감하며, 로컬 tool use는 앱 권한 모델과 함께 설계해야 합니다.
2026년 5월 19일, Google Developers Blog에 올라온 LiteRT-LM 발표는 겉으로는 온디바이스 LLM 성능 업데이트처럼 보입니다. Gemma 4 E2B가 Android GPU에서 52 tokens/sec, iOS Metal에서 56 tokens/sec, WebGPU 기반 MacBook Pro에서 최대 76 tokens/sec decode를 낸다는 숫자가 먼저 눈에 들어오기 때문입니다. 여기에 Multi-Token Prediction drafter 통합으로 최대 2.2배 speedup을 제공한다는 설명도 붙습니다.
하지만 이번 뉴스의 더 큰 의미는 숫자보다 배포 표면에 있습니다. Google은 LiteRT-LM을 Android 전용 최적화 라이브러리처럼 소개하지 않았습니다. Android, iOS, open web, CLI를 한 묶음으로 놓고, 같은 로컬 LLM runtime이 앱, 브라우저, 개발자 터미널에 들어갈 수 있다고 말합니다. 이 지점에서 온디바이스 AI의 질문은 "작은 모델이 충분히 똑똑한가"에서 "실제 제품의 어느 경로에 로컬 추론을 꽂을 수 있는가"로 바뀝니다.
최근 몇 달 동안 로컬 LLM 이야기는 크게 두 갈래로 흘렀습니다. 하나는 모델 쪽입니다. Gemma, Llama, Phi, Qwen 같은 소형 모델이 점점 더 긴 context, 더 나은 reasoning, 더 나은 tool use를 지원하게 됐습니다. 다른 하나는 runtime 쪽입니다. llama.cpp, MLX, ONNX Runtime, WebLLM, Transformers.js, Core ML, MediaPipe, LiteRT처럼 모델을 실제 기기에서 굴리는 계층이 빨라지고 넓어졌습니다. 이번 LiteRT-LM 발표는 두 번째 흐름에 더 가깝습니다. Google이 말하는 핵심은 "Gemma 4가 좋다"가 아니라, Gemma 4 계열 기능을 여러 플랫폼에서 낮은 지연시간으로 실행할 runtime을 만들겠다는 것입니다.
LiteRT-LM이 겨냥하는 병목
클라우드 LLM API는 개발자에게 편합니다. 서버에 요청을 보내면 최신 모델, 큰 context, tool calling, safety layer, 모니터링, billing이 한 번에 따라옵니다. 대신 비용과 지연시간, 개인정보, 네트워크 의존성이 제품 설계의 상수로 들어옵니다. 모바일 앱에서 매번 서버 왕복을 해야 한다면 타이핑 보조, 로컬 검색, 사진 정리, command palette, 간단한 tool routing 같은 기능은 UX가 쉽게 무거워집니다. 규제 산업이나 기업 앱에서는 사용자 입력이 기기를 떠나는 순간 별도의 법무 검토와 데이터 처리 계약이 필요해집니다.
온디바이스 LLM은 이 문제를 일부 덜어낼 수 있습니다. 사용자의 문맥을 기기 안에서 처리하고, 네트워크가 약해도 답을 만들며, 반복적인 작은 추론을 API 호출 비용 없이 처리할 수 있습니다. 그러나 반대쪽 병목도 만만치 않습니다. 모델 크기는 크고, 메모리는 작고, 배터리와 발열은 제한되어 있습니다. Android의 GPU/NPU 경로, iOS의 Metal/Core ML 경로, 웹의 WebGPU 경로는 서로 다릅니다. 개발자가 각 플랫폼마다 모델 포맷, quantization, delegate, streaming, safety 처리, function calling을 따로 맞추면 로컬 AI는 곧 유지보수 비용이 됩니다.
LiteRT-LM은 이 복잡성을 runtime 계층에서 흡수하려는 시도입니다. 공식 LiteRT-LM 문서는 이를 Google AI Edge의 LLM inference API로 설명합니다. 발표 본문은 hardware backend 최적화를 LiteRT가 맡고, Android에서는 OpenCL GPU와 NPU, iOS에서는 Metal, 웹에서는 WebGPU를 활용하는 방향을 제시합니다. AI 앱 개발자에게 중요한 말은 하나입니다. 로컬 추론을 하고 싶다면 모델만 고르는 것이 아니라, 여러 기기에서 같은 제품 의미를 유지할 runtime을 골라야 한다는 것입니다.
| 표면 | LiteRT-LM 경로 | 개발자에게 생기는 질문 |
|---|---|---|
| Android | GPU/NPU backend, Google AI Edge 앱 생태계 | 기기별 accelerator와 권한 모델을 어떻게 추상화할 것인가 |
| iOS/macOS | Swift API와 Metal backend | Apple 플랫폼의 MLX/Core ML 경로와 어디서 나눌 것인가 |
| Web | JavaScript API와 WebGPU | 브라우저에서 모델 다운로드, 캐시, 권한, 성능 편차를 어떻게 다룰 것인가 |
| CLI | 로컬 모델 평가와 반복 테스트 | 제품 코드와 실험 루프를 얼마나 가깝게 둘 것인가 |
WebGPU 76 tokens/sec가 말하는 것
발표에서 가장 흥미로운 숫자는 WebGPU의 76 tokens/sec입니다. Google은 WebGPU를 사용하는 웹 경로에서 MacBook Pro 기준 최대 76 tokens/sec decode를 기대할 수 있다고 설명합니다. 이 숫자는 "브라우저에서 LLM을 돌릴 수 있다"는 데모 수준의 이야기를 조금 더 실무적인 영역으로 밀어 올립니다. 브라우저는 이미 배포가 끝난 runtime입니다. 사용자는 앱을 설치하지 않아도 되고, 개발자는 업데이트를 서버에서 밀어 넣을 수 있습니다. 여기에 로컬 LLM이 안정적으로 들어가면 웹앱은 일부 AI 기능을 서버 API에서 떼어낼 수 있습니다.
물론 이 숫자를 일반화하면 안 됩니다. WebGPU 성능은 브라우저, OS, GPU, 드라이버, power mode, 모델 quantization, context 길이에 크게 좌우됩니다. 발표의 수치는 특정 조건의 최대치이고, 저가형 노트북이나 모바일 브라우저에서는 체감이 달라질 수 있습니다. 또한 로컬 모델을 브라우저에서 실행하려면 모델 파일 다운로드와 캐시가 제품 경험의 일부가 됩니다. 첫 실행 때 수백 MB가 내려온다면, 서버 API보다 privacy와 latency가 낫더라도 onboarding이 무거워집니다.
그래도 방향은 중요합니다. 지금까지 브라우저 AI는 주로 세 가지 방식으로 나뉘었습니다. 서버 API를 호출하는 방식, Chrome built-in AI처럼 브라우저가 제공하는 모델 API를 쓰는 방식, WebGPU 위에서 앱이 직접 모델을 실행하는 방식입니다. LiteRT-LM의 JavaScript 경로는 세 번째 선택지를 Google AI Edge 런타임 안으로 끌어들입니다. 이는 Chrome에만 묶인 API가 아니라, 웹 표준 그래픽/컴퓨트 계층인 WebGPU를 통해 앱이 더 직접적으로 runtime을 관리하는 접근입니다.

AI 제품팀 입장에서 이 변화는 비용 구조와 배포 전략을 동시에 건드립니다. 모든 요청을 클라우드 모델로 보내던 기능 중 일부를 브라우저로 내릴 수 있다면, 서버 비용은 줄고 응답성은 좋아집니다. 예를 들어 문서의 private 요약, 폼 자동 완성, 로컬 command palette, 클라이언트 사이드 검색 질의 재작성, 간단한 분류와 라우팅은 클라우드 API가 항상 필요하지 않을 수 있습니다. 반대로 최신 지식, 장문 추론, 복잡한 tool orchestration, 높은 정확도가 필요한 작업은 여전히 서버 모델에 남겨야 합니다. LiteRT-LM은 이 둘 중 하나를 고르라는 메시지보다, 앱 안에서 로컬과 클라우드 모델을 나눠 쓰는 하이브리드 구조를 더 현실적으로 만듭니다.
MTP 2.2배보다 중요한 런타임 설계
이번 발표에서 Google은 Gemma 4의 Multi-Token Prediction drafter를 LiteRT-LM에 통합했다고 설명합니다. MTP는 한 번에 하나의 토큰을 생성하는 전통적 decode 병목을 줄이기 위해, 작은 drafter가 미래 토큰 후보를 제안하고 primary model이 이를 검증하는 방식입니다. Google은 이 경로로 최대 2.2배 speedup을 제시합니다.
흥미로운 점은 Google이 MTP를 단순한 speculative decoding 레시피로만 설명하지 않는다는 것입니다. 발표는 primary Gemma 4 model과 lightweight MTP drafter를 같은 hardware IP, 예컨대 GPU에서 실행해 KV cache와 activation을 local memory에 두는 전략을 강조합니다. 서로 다른 accelerator 사이를 오가면 동기화와 데이터 전송 비용이 생기기 때문입니다. 다시 말해 speedup은 알고리즘만의 결과가 아닙니다. 모델 구조, runtime scheduler, memory locality, kernel 최적화가 함께 맞아야 합니다.
이 대목은 온디바이스 LLM의 현실을 잘 보여줍니다. 서버 GPU에서는 성능을 높이는 많은 기법이 이미 추론 프레임워크와 클러스터 운영 계층에 녹아 있습니다. 하지만 모바일과 웹에서는 하드웨어가 훨씬 다양하고, 앱이 OS sandbox 안에서 돌아가며, 사용자 기기의 thermal budget을 존중해야 합니다. 같은 MTP라도 runtime이 KV cache와 activation을 어디에 두는지, drafter와 verifier를 어떤 backend에 배치하는지에 따라 실효 성능이 크게 달라질 수 있습니다.
그래서 이번 발표의 실무 메시지는 "Gemma 4 MTP가 빠르다"보다 "로컬 AI runtime이 이제 model-aware scheduler가 되어야 한다"에 가깝습니다. AI 앱 개발자는 모델과 prompt만 생각할 수 없습니다. streaming 지연, context 관리, tool call schema, constrained decoding, local cache, backend fallback까지 제품 품질에 영향을 줍니다. LiteRT-LM은 이 복잡한 층을 Google AI Edge라는 이름으로 묶으려 합니다.
로컬 에이전트 기능이 붙는 지점
LiteRT-LM 발표에는 성능 수치와 함께 agentic workflow라는 표현이 나옵니다. Google은 Thinking Mode, constrained decoding, function calling, multimodal input과 output을 언급합니다. 이 조합은 중요합니다. 온디바이스 LLM이 단순한 챗봇 응답 생성에 머문다면, 빠른 decode는 편의 기능입니다. 하지만 로컬 모델이 앱 함수 호출, JSON schema 준수, 화면/이미지 이해, 단계적 reasoning까지 맡으면 이야기가 달라집니다. 사용자의 기기 안에서 작은 에이전트 루프가 생기기 때문입니다.
예를 들어 사진 앱에서 "지난주 회의 화이트보드만 찾아서 제목을 붙여줘"라는 요청을 생각해볼 수 있습니다. 모든 사진 metadata와 thumbnail을 서버로 올리는 대신, 기기 안에서 후보를 좁히고, 필요한 경우에만 서버 모델을 호출할 수 있습니다. 브라우저 문서 편집기에서는 사용자가 열어둔 문서를 외부 API로 보내지 않고 로컬 모델이 문단 분류와 작은 재작성 제안을 처리할 수 있습니다. 기업 모바일 앱에서는 field worker가 오프라인 상태에서도 checklist를 질의하고, 네트워크가 돌아오면 서버와 동기화할 수 있습니다.
하지만 로컬 에이전트는 더 엄격한 권한 설계를 요구합니다. function calling이 기기 안에서 실행된다고 해서 안전해지는 것은 아닙니다. 오히려 사진, 연락처, 캘린더, 파일, 브라우저 storage처럼 민감한 local resource에 가까워집니다. constrained decoding은 출력 형식을 안정화하지만, 어떤 함수를 호출할 수 있는지, 사용자가 언제 승인해야 하는지, tool call 결과가 모델 context에 어떻게 남는지는 별개의 문제입니다. Google AI Edge Gallery의 function calling 흐름이 흥미로운 이유도 여기에 있습니다. 온디바이스 tool use는 모델 성능만이 아니라 OS 권한, 앱 sandbox, 사용자 승인 UI와 묶여야 합니다.
사용자 입력과 로컬 문맥
LiteRT-LM: streaming, constrained decoding, function calling
Android GPU/NPU, iOS Metal, WebGPU backend
로컬 응답, 로컬 도구 호출, 필요 시 클라우드 모델 escalation
경쟁자는 클라우드 모델이 아니라 다른 로컬 런타임
LiteRT-LM을 OpenAI, Anthropic, Google Gemini API 같은 클라우드 모델과 정면 비교하는 것은 절반만 맞습니다. 실제 경쟁 구도는 로컬 runtime 생태계에 더 가깝습니다. 개발자는 llama.cpp로 데스크톱과 서버 로컬 추론을 할 수 있고, MLX로 Apple Silicon 앱을 만들 수 있으며, WebLLM이나 Transformers.js로 브라우저 추론을 구현할 수 있습니다. ONNX Runtime, Core ML, ExecuTorch, MediaPipe도 각자 강한 영역이 있습니다.
Google의 차별점은 모델, runtime, Android, Chrome/WebGPU, AI Edge 문서를 한 회사 안에서 묶을 수 있다는 데 있습니다. Gemma 4 모델 계열이 MTP와 Thinking Mode 같은 기능을 제공하고, LiteRT-LM이 이를 Android/iOS/Web에서 실행하며, Google AI Edge Gallery가 function calling과 앱 데모를 보여주는 식입니다. 이것은 vertical integration에 가깝습니다. Apple이 Foundation Models framework와 Apple Intelligence로 OS 내부 통합을 밀고, Meta가 Llama와 ExecuTorch로 오픈 모델 배포를 밀며, 커뮤니티가 llama.cpp와 MLX로 빠른 실험을 하는 것과 다른 결입니다.
이 전략에는 약점도 있습니다. Google runtime에 기대면 Gemma 계열과 Google AI Edge의 우선순위에 영향을 받을 수 있습니다. WebGPU 경로는 브라우저 호환성과 사용자 기기 성능 편차에 민감합니다. iOS에서는 Apple이 제공하는 Core ML, MLX, Foundation Models와의 선택 기준이 필요합니다. Android에서도 NPU path가 언제나 균일하게 열려 있는 것은 아닙니다. 결국 개발자는 "가장 빠른 demo"가 아니라 "가장 예측 가능한 배포 경로"를 선택해야 합니다.
개발팀이 지금 확인할 것
이번 발표를 바로 제품 로드맵으로 가져가려면 먼저 기능을 나눠야 합니다. 모든 LLM 기능을 로컬로 옮기는 접근은 현실적이지 않습니다. 로컬에 맞는 작업은 대체로 짧고 반복적이며, 사용자 문맥이 민감하고, 최신 외부 지식이 덜 필요하며, 실패해도 서버 모델로 escalation할 수 있는 작업입니다. 반대로 법적 판단, 복잡한 planning, 긴 문서 synthesis, 신뢰성이 높은 external tool execution은 여전히 더 큰 모델과 서버 관측성이 필요합니다.
두 번째로 측정 환경을 직접 만들어야 합니다. Google의 52, 56, 76 tokens/sec 수치는 좋은 출발점이지만, 제품의 실제 prompt 길이, context reuse, streaming UI, 모델 다운로드, cold start, 배터리 소모, 발열을 대신 측정해주지 않습니다. 특히 웹에서는 모델 파일 캐시 정책과 첫 실행 경험이 핵심입니다. 사용자가 기능을 한 번 쓰기 위해 긴 다운로드를 기다려야 한다면, 로컬 추론의 낮은 per-token latency는 체감되기 어렵습니다.
세 번째로 권한과 감사 로그를 설계해야 합니다. 로컬 function calling은 서버에 데이터가 가지 않는다는 장점이 있지만, 사용자의 기기에서 실제 작업을 실행할 수 있다는 뜻이기도 합니다. 어떤 tool이 읽기 전용인지, 어떤 tool이 쓰기 작업인지, 언제 사용자 confirmation이 필요한지, tool call 결과를 얼마나 오래 보관하는지 정해야 합니다. 브라우저에서는 origin과 storage, permission prompt, enterprise policy까지 고려해야 합니다.
마지막으로 하이브리드 아키텍처를 전제로 봐야 합니다. 앞으로의 AI 앱은 하나의 모델 호출로 끝나지 않을 가능성이 큽니다. 작은 로컬 모델이 privacy-sensitive routing과 빠른 초안을 맡고, 서버 모델이 어려운 reasoning과 최신 정보를 맡으며, 경우에 따라 둘 사이에 verifier나 policy layer가 들어갑니다. LiteRT-LM의 의미는 클라우드를 대체한다는 데 있지 않습니다. 클라우드 모델만으로 짜던 AI 제품 설계에 로컬 runtime이라는 추가 축을 넣는 데 있습니다.
조용하지만 중요한 신호
이번 LiteRT-LM 발표는 모델 발표처럼 화려하지 않습니다. 새로운 frontier benchmark를 내세우지도 않고, 거대한 챗봇 제품을 공개하지도 않았습니다. 그러나 AI 개발자에게는 오히려 이런 런타임 뉴스가 더 오래 남을 수 있습니다. 실제 AI 제품은 모델 성능표 위에서만 돌아가지 않습니다. 사용자의 브라우저, 휴대폰, 배터리, 네트워크, 권한 UI, 앱 업데이트 경로 위에서 돌아갑니다.
Google이 LiteRT-LM을 Android, iOS, WebGPU, CLI로 넓힌 것은 로컬 LLM을 실험실 데모에서 제품 배포 문제로 끌어내리는 움직임입니다. 76 tokens/sec WebGPU나 2.2배 MTP speedup은 그 흐름을 보여주는 숫자입니다. 더 중요한 질문은 이 숫자가 어디에 쓰일 수 있느냐입니다. 문서 편집기, 모바일 업무 앱, private 검색, 오프라인 assistant, 브라우저 기반 developer tool에서 일부 추론이 사용자 기기 안으로 내려간다면, AI 앱의 비용과 개인정보 경계는 지금과 달라집니다.
그래서 이번 뉴스의 핵심은 "로컬 LLM이 클라우드를 이긴다"가 아닙니다. 더 현실적인 결론은 "AI 앱의 실행 위치가 하나가 아니게 된다"입니다. LiteRT-LM은 그 다중 실행 위치를 Google식으로 정리하려는 런타임입니다. 개발팀이 지금 볼 것은 발표 숫자의 크기만이 아니라, 자신의 제품에서 어떤 판단을 서버 밖으로 내려도 되는지, 그리고 그 판단을 어떤 runtime과 권한 모델로 책임질 수 있는지입니다.