Honeycomb Agent Timeline 공개, 에이전트 관측의 새 표준 경쟁
Honeycomb이 Agent Timeline과 Canvas Agent를 공개했습니다. AI 에이전트 운영은 이제 로그 수집보다 사건 재구성이 핵심입니다.
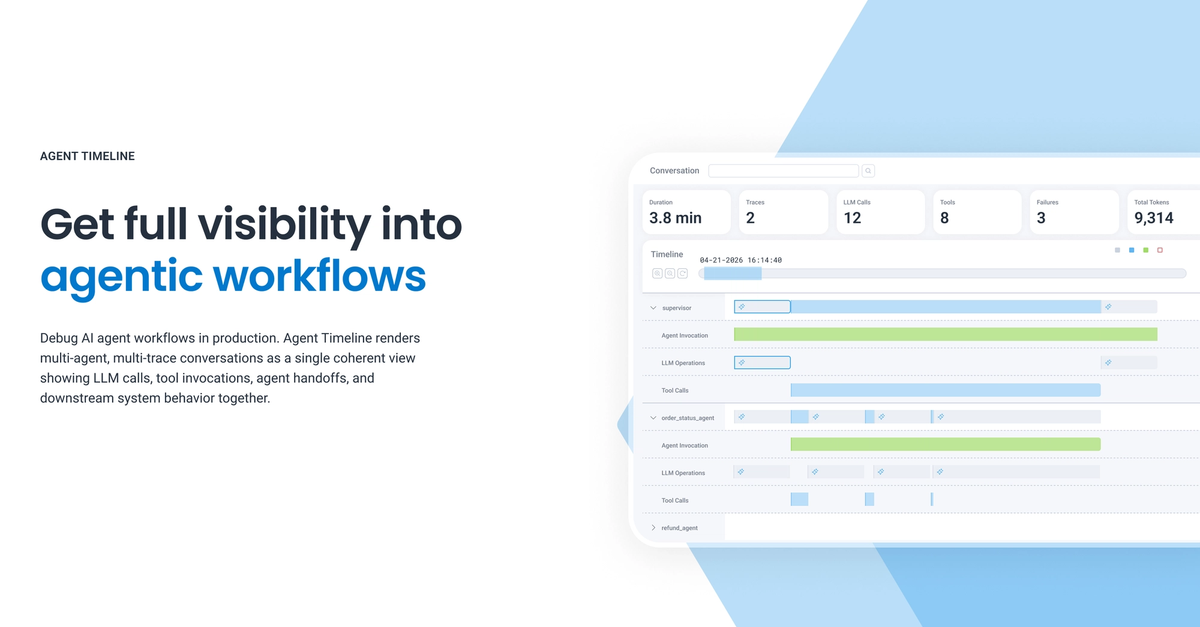
- 무슨 일: Honeycomb이 2026년 5월 12일
Agent Timeline,Canvas Agent,Canvas Skills를 공개했습니다.- LLM 호출, 툴 실행, 에이전트 handoff, downstream span을 한 흐름에서 재구성하겠다는 관측성 제품 발표입니다.
- 의미: AI 에이전트 운영의 병목이 "모델이 답했는가"에서 무엇을 왜 실행했는가로 이동하고 있습니다.
- 주의점: Honeycomb은
OpenTelemetry GenAIv1.40.0 통합을 강조하지만, 해당 convention은 아직 Development 상태입니다.
Honeycomb이 2026년 5월 12일 Agent Timeline, Canvas Agent, Canvas Skills를 발표했습니다. 표면적으로는 관측성 제품의 기능 추가입니다. 하지만 이 발표가 흥미로운 이유는 AI 에이전트가 프로덕션 시스템 안에서 실제 일을 하기 시작했을 때, 기존 APM과 로그 도구가 무엇을 놓치는지 정면으로 겨냥하기 때문입니다.
최근 AI 에이전트 논의는 주로 모델 성능, 코딩 능력, 툴 호출, 장기 실행 작업에 집중됐습니다. 그런데 에이전트가 코드 생성뿐 아니라 incident triage, cloud infrastructure deployment, customer service, 내부 운영 자동화까지 맡으면 질문이 달라집니다. "이 에이전트가 정답을 냈는가"보다 더 중요한 질문은 "이 에이전트가 어떤 관찰을 했고, 어떤 툴을 호출했고, 어떤 시스템에 영향을 줬으며, 왜 그 순서로 움직였는가"입니다.
Honeycomb은 이번 발표에서 바로 그 지점을 제품 메시지로 삼았습니다. Agent Timeline은 multi-agent, multi-trace workflow를 하나의 coherent view로 렌더링하고, LLM call, tool invocation, agent handoff, downstream system impact를 실시간으로 연결한다고 설명합니다. 쉽게 말하면 에이전트의 작업을 채팅 로그나 분리된 span 목록으로 보는 것이 아니라, 사건의 순서와 영향 경로로 재구성하겠다는 뜻입니다.

이 뉴스의 배경에는 단순한 "AI 기능 붙이기"보다 큰 변화가 있습니다. 전통적인 observability는 서비스, 엔드포인트, trace, metric, log를 사람이 탐색할 수 있게 만드는 데 집중했습니다. 그러나 AI 에이전트는 결정적 프로그램처럼 동작하지 않습니다. 같은 입력도 다른 계획으로 이어질 수 있고, 툴 호출이 외부 시스템 상태를 바꾸며, 중간 판단이 다음 판단의 컨텍스트가 됩니다. 평균 latency나 error rate만 보면 왜 잘못된 remediation을 제안했는지, 왜 같은 alert를 두고 다른 실행 경로를 택했는지 알기 어렵습니다.
Honeycomb의 발표문은 이 문제를 꽤 직접적으로 짚습니다. 기존 소프트웨어 관측 도구가 비결정적이고 multi-hop인 agent workflow를 위해 설계되지 않았고, 대시보드는 깨지고 평균은 거짓말을 하며, 에이전트가 incident를 만들었을 때 팀은 무엇을 결정했고 왜 그랬는지 재구성할 방법이 없다는 주장입니다. 표현은 마케팅 문장에 가깝지만 문제의식은 실무적으로 맞습니다. 에이전트 시스템의 장애는 단일 HTTP 500이나 단일 예외로 끝나지 않습니다.
예를 들어 장애 대응 에이전트를 생각해보면, 첫 단계는 alert 수신일 수 있습니다. 다음은 최근 배포 확인, 로그 질의, trace 비교, runbook 검색, Slack 또는 Jira 업데이트, feature flag 조정 제안일 수 있습니다. 이 흐름에서 중요한 것은 각각의 API 호출이 성공했는지만이 아닙니다. 어떤 가설을 세웠는지, 그 가설을 확인하기 위해 어떤 데이터를 봤는지, 어떤 툴 결과가 다음 행동을 바꿨는지, 사람이 승인한 지점이 어디였는지가 중요합니다. Agent Timeline이 노리는 영역이 바로 이 빈 공간입니다.
| 관측 대상 | 기존 APM에서 흔한 단위 | 에이전트 운영에서 필요한 단위 |
|---|---|---|
| 실행 흐름 | 서비스별 trace와 span | 프롬프트, 툴 호출, handoff, downstream 영향의 시간순 연결 |
| 실패 원인 | 예외, latency, error rate | 잘못된 가설, 누락된 컨텍스트, 위험한 툴 선택, 승인 경계 이탈 |
| 개선 루프 | 알림 튜닝과 대시보드 개선 | 실패 trajectory를 평가 데이터와 runbook, policy로 되돌리는 과정 |
이번 발표에서 두 번째 축은 Canvas입니다. Honeycomb은 Canvas를 collaborative workspace, chat interface, autonomous agent가 한데 있는 화면으로 다시 만들었다고 설명합니다. 사용자는 자연어로 이슈를 질의하고, 사람과 에이전트가 같은 조사 공간에서 작업하며, 공유 가능한 visualization snapshot을 만들 수 있습니다. 여기서 중요한 단어는 "chat"보다 "workspace"입니다. 관측성 제품에 채팅창을 붙이는 것만으로는 프로덕션 문제를 풀기 어렵습니다. 조사 과정에서 나온 그래프, query, trace, 가설, 반박, 결론이 같은 맥락에 남아야 합니다.
Canvas Agent와 Auto-investigations는 이 흐름을 더 밀어붙입니다. Honeycomb은 alert가 울리거나 SLO burn, anomaly가 발생하면 Canvas agent가 먼저 데이터를 모으고, 가설을 만들고, 테스트하고, remediation을 제안한다고 설명합니다. 사람이 노트북을 열기 전에 조사가 시작된다는 메시지입니다. 운영팀 입장에서는 매력적이지만 동시에 위험한 영역입니다. 장애 대응의 초동 조사 속도는 빨라질 수 있지만, 잘못된 자동 가설이 팀의 주의를 특정 방향으로 고정할 수 있기 때문입니다.
그래서 Canvas Skills가 중요해집니다. Honeycomb은 Skills를 Kafka 같은 프레임워크나 서비스에 대한 best engineer의 debugging knowledge와 best practice를 reusable playbook으로 인코딩하는 기능으로 설명합니다. 이는 단순한 prompt template 이상의 의미가 있습니다. 에이전트가 운영 데이터를 해석할 때, 도메인별로 무엇을 먼저 봐야 하고, 어떤 지표 조합을 의심해야 하며, 어떤 remediation은 사람 승인이 필요한지 규칙화해야 합니다. 제품 관점에서는 Honeycomb이 관측 데이터만 저장하는 도구에서 조사 절차를 실행하는 도구로 올라가려는 움직임입니다.
물론 Honeycomb만 이 시장을 보는 것은 아닙니다. Datadog, New Relic, Grafana 계열, LangSmith, Langfuse, Arize Phoenix, Helicone 같은 도구들은 이미 LLM tracing, prompt/version 추적, 평가, 비용 분석, latency 분석을 각자의 방식으로 제공합니다. 차이는 어디를 중심축으로 잡느냐입니다. LLM 앱 개발 도구들은 대개 prompt, model call, eval, dataset을 중심에 둡니다. 전통 APM 벤더들은 기존 trace와 metric 위에 LLM workload를 얹습니다. Honeycomb의 이번 메시지는 production telemetry와 agent reasoning trail을 같은 조사 흐름으로 묶는 쪽에 가깝습니다.
여기서 OpenTelemetry가 등장합니다. Honeycomb은 이번 발표에서 OpenTelemetry GenAI semantic conventions v1.40.0을 플랫폼에 통합했고, gen_ai.* attributes를 first-class citizen으로 다룬다고 밝혔습니다. 이 문장은 작지만 중요합니다. AI 에이전트 관측이 벤더별 SDK와 독자 schema에 갇히면, 팀은 에이전트 프레임워크를 바꾸거나 관측 백엔드를 바꿀 때 데이터를 다시 심어야 합니다. 반대로 OpenTelemetry convention 위에 쌓이면 instrumentation은 비교적 오래 남고, 분석 표면은 바꿀 수 있습니다.
하지만 이 대목에는 주의가 필요합니다. OpenTelemetry의 GenAI semantic conventions 문서는 현재 Status를 Development로 표시합니다. 문서는 기존 v1.36.0 이하 convention을 쓰는 instrumentation이 기본 방출 버전을 바로 바꾸지 말아야 하며, 최신 experimental convention을 쓰려면 OTEL_SEMCONV_STABILITY_OPT_IN 같은 opt-in 경로를 도입해야 한다고 안내합니다. 즉 시장이 표준으로 수렴하고 있다는 방향은 맞지만, "이미 완전히 안정화된 표준"으로 읽으면 안 됩니다.
OpenTelemetry의 2025년 AI agent observability 글도 같은 방향을 가리킵니다. 그 글은 AI agent application과 AI agent framework를 구분하고, agent app과 framework가 standardized metrics, traces, logs를 보고해야 통합과 비교가 쉬워진다고 설명합니다. 특히 agent framework가 자체 instrumentation을 baked-in으로 제공할 때 adoption은 쉬워지지만, OpenTelemetry 의존성이 뒤처지거나 vendor-specific convention에 갇힐 수 있다는 단점도 함께 적습니다. 이번 Honeycomb 발표는 이 표준화 논의가 제품 경쟁으로 내려온 사례입니다.
개발팀이 이 뉴스를 읽을 때 가져가야 할 질문은 "Honeycomb을 써야 하는가"보다 "우리 에이전트는 실패했을 때 재구성 가능한가"입니다. 프로덕션 에이전트에 필요한 최소 telemetry는 단순하지 않습니다. model name, input/output token, latency, cost는 기본입니다. 여기에 prompt template version, retrieved context, selected tool, tool input/output, external side effect, human approval, policy decision, retry reason, handoff target, downstream trace link가 붙어야 합니다. 그래야 한 번의 실패가 다음 eval case나 runbook 수정으로 이어집니다.
또 하나의 현실적인 이슈는 민감 데이터입니다. 에이전트 관측을 잘하려면 prompt와 completion, tool result, retrieved document 일부를 저장하고 싶어집니다. 그러나 그 안에는 고객 정보, 내부 코드, 보안 토큰, 운영 로그, incident 세부사항이 들어갈 수 있습니다. OpenTelemetry convention이 schema를 정리해도, 무엇을 수집하고 무엇을 redaction하며 얼마나 보관할지는 별도 정책 문제입니다. 관측 가능성을 높이려다 데이터 노출 위험을 키우면 운영 신뢰를 잃습니다.
이 지점에서 "에이전트 관측"은 보안과 거버넌스의 문제로 넘어갑니다. 에이전트가 툴을 호출해 실제 시스템을 변경할 수 있다면, trace는 사후 디버깅 자료인 동시에 감사 로그가 됩니다. 누가 어떤 권한으로 어떤 에이전트를 실행했는지, 에이전트가 어떤 근거로 변경을 제안했는지, 사람이 어디서 승인했는지, 자동 실행이 허용된 범위를 넘지 않았는지 남아야 합니다. Honeycomb의 발표가 직접 보안 제품은 아니지만, Agent Timeline 같은 표면은 이런 감사 가능성의 전제 조건이 됩니다.
커뮤니티 반응은 아직 큰 단일 토론으로 모이지 않았습니다. 다만 GeekNews에는 지난해 Honeycomb의 관측성/AI 관련 글이 공유되며 "LLM이 분석을, OpenTelemetry가 계측을 평준화하고 관측성의 핵심은 빠른 피드백 루프로 이동한다"는 요약이 붙었습니다. Reddit과 observability 커뮤니티에서도 agent observability가 단순 LLM tracing에 머물러서는 안 된다는 논의가 이어졌습니다. 특히 state transition, parent-child span, tool call result, portable incident artifact 같은 키워드가 반복됩니다. 이번 발표는 그런 문제의식이 제품명과 가격표를 가진 시장으로 이동하고 있음을 보여줍니다.
비판적으로 볼 지점도 있습니다. 첫째, 자동 조사는 데모에서 좋아 보이지만 실제 운영에서는 false positive와 stale context 문제가 큽니다. 에이전트가 "그럴듯한 원인"을 너무 빨리 제시하면 팀이 다른 가능성을 덜 보게 됩니다. 둘째, OTel GenAI convention이 Development 상태인 만큼 버전 호환성과 attribute 해석 차이가 남습니다. 셋째, 벤더가 제공하는 AI 조사 표면은 편리하지만, 데이터와 workflow가 제품 내부 표현에 강하게 묶일 수 있습니다. 표준을 쓴다는 말과 완전한 이식성은 같은 말이 아닙니다.
그럼에도 방향은 선명합니다. AI 에이전트가 개발과 운영의 주변 도구가 아니라 실제 작업자로 들어오면, observability는 사람을 위한 대시보드에서 사람과 에이전트가 함께 쓰는 사건 기록 시스템으로 바뀝니다. 지금까지의 LLM observability가 "어떤 모델이 얼마의 비용으로 얼마나 빨리 답했는가"에 가까웠다면, 다음 단계는 "어떤 행동 사슬이 어떤 결과를 만들었는가"입니다. Honeycomb의 Agent Timeline이라는 이름은 그래서 꽤 정확합니다. 관측 대상이 단일 호출이 아니라 시간 속의 행동이 됐기 때문입니다.
AI 팀이 지금 준비할 수 있는 일은 명확합니다. 먼저 에이전트 workflow에서 side effect가 생기는 지점을 식별해야 합니다. 파일 수정, 배포, 티켓 작성, 고객 응답, 권한 변경, 데이터 삭제 같은 행동은 반드시 trace와 approval boundary를 남겨야 합니다. 다음으로 프레임워크와 벤더 선택에서 OpenTelemetry 호환성을 확인해야 합니다. 마지막으로 실패 사례를 eval dataset과 runbook 개선으로 되돌리는 루프를 만들어야 합니다. 관측은 보는 것으로 끝나지 않고, 다음 실행을 바꾸는 재료가 될 때 가치가 생깁니다.
Honeycomb의 발표는 아직 모든 답을 주지는 않습니다. Agent Timeline은 Early Access이고, Canvas 계열 기능은 다음 주부터 고객에게 제공됩니다. 실제 품질은 긴 장애 조사, 다중 에이전트 handoff, 민감 데이터 redaction, 대규모 trace 비용, OTel convention 변화 대응에서 검증될 것입니다. 하지만 뉴스 자체의 의미는 충분히 큽니다. 에이전트 시대의 관측성 경쟁은 이제 모델 호출 로그를 넘어, 프로덕션에서 벌어진 AI 행동을 얼마나 정확히 재구성하고 개선 루프로 되돌릴 수 있는지의 싸움으로 넘어가고 있습니다.