Honeycomb, AI 에이전트 관측성을 운영 계층으로 끌어올렸다
Honeycomb Agent Timeline 출시는 AI 에이전트 운영의 병목이 모델 성능에서 trace, 비용, 정책 증거로 이동했음을 보여줍니다.

- 무슨 일: Honeycomb이
Agent Timeline, Canvas Agent, Canvas Skills로 AI 에이전트 관측성 제품군을 공개했습니다.- 발표일은 2026년 5월 12일이며, Agent Timeline은 Early Access, Canvas 계열 기능은 다음 주부터 고객 제공으로 안내됐습니다.
- 핵심 변화: LLM 호출, 도구 호출, 에이전트 핸드오프, 다운스트림 trace를 대화 단위로 묶어 복원합니다.
- Honeycomb은 OpenTelemetry GenAI semantic conventions v1.40.0의
gen_ai.*속성을 1급 telemetry로 다룬다고 설명합니다.
- Honeycomb은 OpenTelemetry GenAI semantic conventions v1.40.0의
- 실무 의미: 에이전트 운영의 병목이 "더 똑똑한 모델"에서 비용, 실패 경로, 권한, 정책 증거를 남기는 일로 옮겨갑니다.
- 주의점: OpenTelemetry GenAI 규약은 아직 Development 상태라 벤더 lock-in을 피하려면 schema version과 raw span 보존 전략이 필요합니다.
Honeycomb이 2026년 5월 12일 AI 에이전트용 관측성 기능을 묶어 발표했습니다. 이름만 보면 일반적인 observability 벤더의 제품 업데이트처럼 보입니다. 하지만 이번 발표는 AI 에이전트 시장에서 꽤 중요한 전환점을 보여줍니다. 에이전트 경쟁의 무게중심이 "어떤 모델이 더 긴 코드를 잘 쓰는가"에서 "운영 환경에서 에이전트가 실제로 무엇을 했는지 설명할 수 있는가"로 이동하고 있기 때문입니다.
공식 발표의 핵심 기능은 세 가지입니다. Agent Timeline은 여러 에이전트와 여러 trace를 하나의 coherent view로 렌더링합니다. Canvas Agent는 alert, SLO burn, anomaly가 발생했을 때 자동 조사를 시작합니다. Canvas Skills는 팀의 디버깅 노하우와 서비스별 runbook을 재사용 가능한 playbook으로 인코딩합니다. Honeycomb은 이 조합을 통해 엔지니어링 팀이 독점 SDK나 특정 프레임워크에 묶이지 않고 AI 에이전트가 무엇을 하는지 실시간으로 볼 수 있다고 설명합니다.
이번 뉴스가 흥미로운 이유는 Honeycomb 하나의 기능 출시라서가 아닙니다. IBM Instana도 5월 5일 AI Agent and LLM Observability public preview를 발표했습니다. OpenTelemetry는 GenAI semantic conventions에서 agent spans, model spans, metrics, events, exceptions, MCP conventions를 별도 신호로 정리하고 있습니다. 4월 arXiv에 올라온 Governance-Aware Agent Telemetry 논문은 관측을 넘어 정책 위반을 실시간으로 막는 telemetry plane까지 제안했습니다. 방향은 같습니다. AI 에이전트를 프로덕션에 넣으려면 "로그를 조금 더 남기는 것"이 아니라, 에이전트의 의사결정 경로를 운영 시스템의 1급 데이터로 다뤄야 합니다.
왜 기존 APM으로는 부족한가
전통적인 APM은 대체로 요청, 서비스, 데이터베이스, 큐, 인프라 지표를 중심으로 움직입니다. HTTP 요청이 느려졌는지, 오류율이 올라갔는지, 특정 endpoint가 어떤 downstream dependency에서 시간을 썼는지 보는 데 강합니다. 이 모델은 결정론적 소프트웨어에는 잘 맞습니다. 같은 입력이 들어오면 대체로 같은 코드 경로를 지나고, 실패하면 stack trace나 error log가 남습니다.
AI 에이전트는 다릅니다. 하나의 사용자 요청이 LLM 호출, tool call, memory read/write, 검색, 다른 에이전트 handoff, 외부 API 실행, 권한 확인, 재시도, 평가 루프를 거칠 수 있습니다. 같은 요청도 모델 출력과 환경 상태에 따라 다른 경로를 탑니다. 실패도 전통적인 exception으로만 나타나지 않습니다. 잘못된 tool을 골랐거나, 너무 많은 context를 반복해서 모델에 보냈거나, permission denied를 회피하려다 비싼 우회 경로를 택했거나, hallucinated state를 memory에 저장했을 수 있습니다.
Honeycomb의 발표문은 기존 도구가 nondeterministic, multi-hop agent workflow에 맞게 설계되지 않았다고 짚습니다. 대시보드는 깨지고, 평균값은 거짓말을 하며, 에이전트가 인시던트를 만들었을 때 팀은 무엇을 결정했고 왜 그렇게 했는지 재구성할 방법이 없다는 문제의식입니다. 이것은 마케팅 문구로만 보기 어렵습니다. 실제로 에이전트 운영에서 가장 귀찮은 문제는 "작동하지 않는다"가 아니라 "어디서부터 틀어졌는지 설명할 수 없다"입니다.
Agent Timeline이 겨냥하는 단위는 request가 아니라 conversation입니다
Agent Timeline의 포인트는 trace를 더 예쁘게 보여주는 데 그치지 않습니다. Honeycomb은 Agent Timeline이 LLM call, tool invocation, agent handoff, downstream system impact를 real time으로 연결한다고 설명합니다. 중요한 단어는 conversation ID입니다. 일반적인 web request ID만으로는 agent workflow를 묶기 어렵습니다. 에이전트는 하나의 요청 안에서 여러 tool을 호출하고, 때로는 비동기 작업이나 다른 agent로 이어지며, downstream 서비스 trace와 LLM span이 섞입니다.
Honeycomb Innovation Week Day 2 글의 데모는 이 차이를 잘 보여줍니다. 지원팀이 conversation ID 하나만 넘기자 Agent Timeline이 duration, tool calls, failures, tokens consumed를 요약하고, check_shipping 연결 오류와 shipping service 장애를 빠르게 좁혀 들어가는 흐름입니다. 아래쪽 trace waterfall은 agent가 호출한 non-GenAI service까지 끌어와 전체 stack을 한 화면에 둡니다. 즉 "모델이 이상한 답을 했다"와 "배송 서비스가 내려갔다"를 별도 사건으로 보지 않고, 같은 운영 사건 안에서 봅니다.
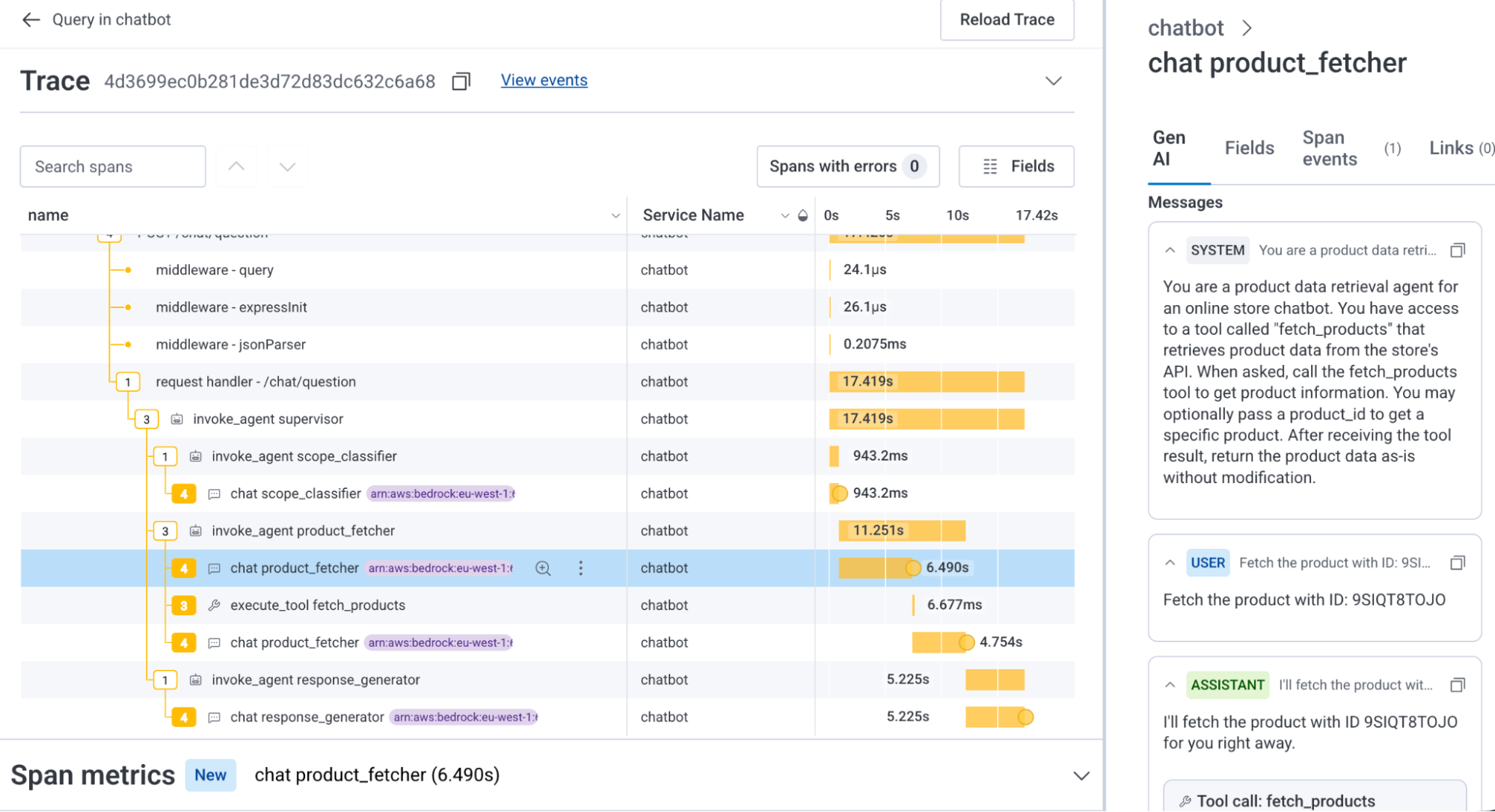
이 관점은 AI 제품팀과 플랫폼팀의 책임 경계를 바꿉니다. 지금까지 많은 LLM observability 도구는 prompt, completion, token, latency, eval score를 중심으로 모델 행동을 봤습니다. 반면 전통 APM은 API latency와 database query를 봤습니다. 에이전트가 실무 시스템을 만지기 시작하면 둘을 분리할 수 없습니다. tool call이 실패하면 모델 품질 문제가 아니라 권한, schema, network, data freshness 문제일 수 있습니다. 반대로 downstream API가 정상이어도 에이전트가 같은 데이터를 매 turn마다 145K씩 다시 보내면 비용과 latency가 폭발합니다.
OpenTelemetry가 공용어가 될 수 있을까
Honeycomb이 강조한 또 다른 축은 OpenTelemetry입니다. 발표문은 Honeycomb이 OpenTelemetry GenAI semantic conventions v1.40.0을 플랫폼에 통합했고, gen_ai.* attributes를 first-class citizen으로 만든다고 말합니다. 모델 평가, tool execution, MCP call, LLM, agent를 모두 관측 대상으로 다룬다는 뜻입니다.
OpenTelemetry 공식 문서를 보면 GenAI semantic conventions는 현재 1.41.0 문서 기준 Development 상태입니다. 문서는 기존 GenAI instrumentation이 v1.36.0 이하 규약을 기본 emission으로 쓰는 경우 무리하게 바꾸지 말고, 최신 experimental convention을 선택적으로 emit하려면 OTEL_SEMCONV_STABILITY_OPT_IN 같은 환경변수를 쓰는 전환 계획을 제시합니다. 또한 Generative AI operations를 events, exceptions, metrics, model spans, agent spans로 나누고, Anthropic, Azure AI Inference, AWS Bedrock, OpenAI, MCP 같은 기술별 conventions를 따로 둡니다.
여기서 실무적인 긴장이 생깁니다. 벤더들은 "우리는 open standard 기반"이라고 말하고 싶습니다. 사용자는 vendor SDK에 묶이고 싶지 않습니다. 그러나 규약이 아직 움직이는 동안에는 attribute 이름, span 구조, event payload가 바뀔 수 있습니다. 따라서 팀이 지금 해야 할 일은 특정 vendor UI를 먼저 고르는 것보다, 원본 trace와 raw attributes를 얼마나 보존할지, schema version을 어떻게 기록할지, agent runtime과 product telemetry를 어떤 ID로 연결할지 정하는 것입니다.
Honeycomb의 실전 글은 이 문제를 현실적으로 다룹니다. Pydantic AI 예시에서는 agentic span에 최소한 gen_ai.conversation.id, gen_ai.agent.name, gen_ai.operation.name을 넣으라고 제안합니다. 또 CLAUDE.md, AGENT.md 같은 에이전트 context 파일에 OpenTelemetry instrumentation 지침을 처음부터 포함하라고 권합니다. 이 부분이 중요합니다. 에이전트가 코드를 작성하는 시대에는 instrumentation도 사람이 나중에 덧붙이는 작업이 아니라, 에이전트가 생성하는 코드의 기본 품질 기준이 되어야 합니다.
비용 관측성은 별도 제품이 아니라 운영 관측성의 일부입니다
AI 에이전트 운영에서 token 비용은 별도 FinOps dashboard로만 볼 수 없습니다. 비용은 behavior의 결과입니다. 어떤 agent가 어떤 tool을 잘못 호출했는지, 어떤 memory를 반복해서 넣었는지, 어떤 prompt override가 context size를 늘렸는지 알아야 합니다. Honeycomb Day 2 데모의 숫자는 이 지점을 노골적으로 보여줍니다. customer service chat agent에서 88개 conversation이 80,000 tokens를 넘었고, order status agent가 전체 token의 79%를 태웠으며, runaway loop가 원인이었습니다.
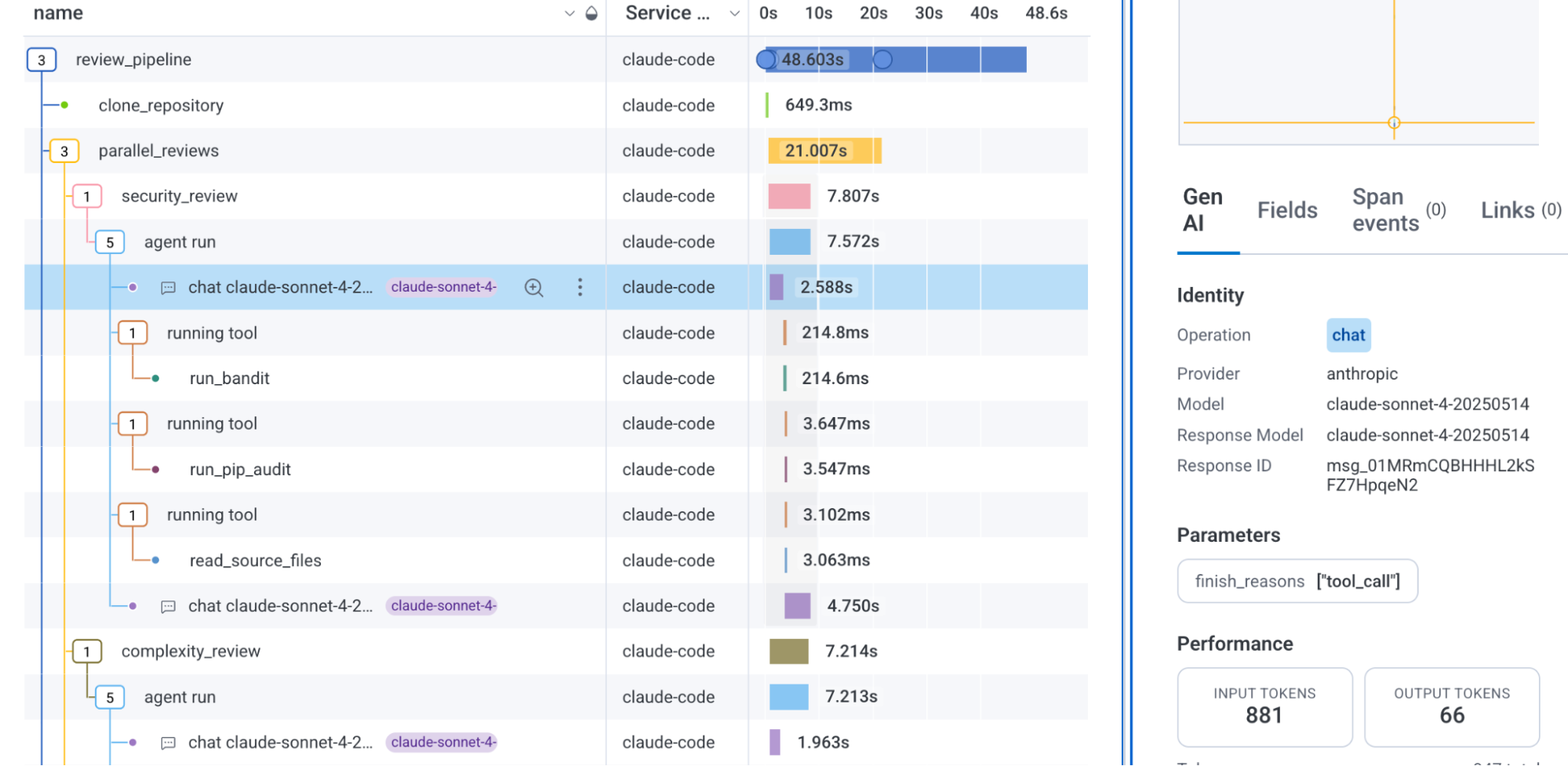
이런 사건은 단순히 "토큰이 많이 나갔다"로 끝나지 않습니다. 고객 응답 지연, LLM rate limit, downstream service load, 운영 비용, 잘못된 답변 가능성이 한꺼번에 올라갑니다. 따라서 token spend는 청구서의 항목이 아니라 trace의 속성이 되어야 합니다. 어떤 conversation에서, 어떤 agent가, 어떤 tool call 뒤에, 어떤 모델로, 얼마의 input/output token을 썼는지가 연결되어야 원인 분석이 가능합니다.
Honeycomb이 heatmap과 span duration을 함께 보여주는 것도 같은 이유입니다. 비싼 호출은 느린 호출일 수 있고, 느린 호출은 재시도를 만들 수 있으며, 재시도는 다시 비용을 만듭니다. 평균 token 사용량만 보면 이 경로를 놓칩니다. 특히 multi-agent system에서는 한 agent의 작은 비효율이 handoff를 거치며 커질 수 있습니다. 운영팀 입장에서는 "이번 달 모델 비용이 올랐다"보다 "지난 화요일 배포된 system prompt override 이후 order status agent가 특정 tool 결과를 매 turn 재주입했다"가 훨씬 유용한 설명입니다.
Canvas Agent와 Skills는 관측성의 자동화 방향을 보여줍니다
Canvas Agent와 Canvas Skills는 "보는 도구"를 넘어 "조사하는 도구"로 관측성을 확장합니다. Honeycomb은 auto-investigations가 alert, SLO burn, anomaly가 발생했을 때 데이터를 모으고, 가설을 만들고, remediation을 제안한다고 설명합니다. Canvas Skills는 팀의 debugging knowledge와 framework/service best practices를 autonomous playbook으로 만든다고 합니다.
이 접근은 엔지니어링 조직에서 자주 보던 문제를 AI 에이전트 방식으로 다시 푸는 것입니다. 좋은 SRE나 senior engineer는 대시보드 숫자만 보지 않습니다. 최근 배포, traffic shape, feature flag, dependency 상태, 과거 incident, 팀의 암묵지까지 함께 봅니다. Canvas Skills는 이 암묵지를 skill로 저장해 다음 조사에 재사용하려는 시도입니다.
다만 여기에는 조심할 점도 있습니다. 관측성 agent가 remediation을 제안하거나 trigger를 만들 수 있다면, 그 agent 자체도 관측 대상이 됩니다. 어떤 데이터에 접근했는지, 어떤 가설을 버렸는지, 어떤 playbook을 적용했는지, 어떤 권한으로 alert rule을 만들었는지 남겨야 합니다. "에이전트를 감시하는 에이전트"가 생기면 운영 구조는 더 강력해질 수 있지만, 설명 책임도 한 단계 올라갑니다.
경쟁 구도는 LLMOps에서 AgentOps로 이동합니다
IBM Instana의 발표도 같은 방향을 가리킵니다. IBM은 AI Agent and LLM Observability가 AI component를 자동 발견하고, agent와 workflow, LLM, service dependency를 end-to-end view로 매핑하며, output quality evaluation과 drift detection을 제공한다고 설명합니다. Honeycomb이 OpenTelemetry와 high-cardinality trace 분석을 전면에 내세운다면, IBM은 enterprise AI operations와 business context를 더 강하게 내세웁니다.
| 축 | Honeycomb | IBM Instana | OpenTelemetry/연구 |
|---|---|---|---|
| 기본 단위 | conversation ID와 trace | AI component와 dependency map | agent span, model span, MCP signal |
| 강조점 | 고차원 trace, unknown unknowns | 운영 이해, 품질 평가, business context | 공통 schema와 정책 enforcement |
| 실무 질문 | 이 agent가 왜 이 경로를 탔나 | AI system이 어디에 붙어 있나 | 어떤 telemetry를 표준으로 남길 것인가 |
여기에 Langfuse, Datadog, New Relic, Dynatrace, Arize/Phoenix 같은 LLM observability와 APM 계열 도구가 각자의 영역에서 겹쳐 들어옵니다. 앞으로의 차별점은 "prompt와 completion을 보여준다"가 아닐 가능성이 큽니다. 에이전트가 실제 시스템을 만질 때, 모델 span과 서비스 trace와 permission event와 eval result와 business outcome을 얼마나 자연스럽게 묶느냐가 중요해집니다.
4월 arXiv에 올라온 GAAT 논문은 이 흐름을 더 밀어붙입니다. 논문은 OpenTelemetry와 Langfuse 같은 도구가 telemetry를 수집하지만 governance를 downstream analytics로 취급한다고 비판합니다. 그래서 policy violation을 damage 이후에야 감지하는 observe-but-do-not-act gap이 생긴다고 봅니다. 논문이 제안하는 구조는 OpenTelemetry를 확장한 Governance Telemetry Schema, OPA-compatible policy engine, Governance Enforcement Bus, cryptographic provenance가 있는 Trusted Telemetry Plane입니다. 제품화된 주류 기능은 아니지만, 관측성의 다음 단계가 "보는 것"에서 "정책을 걸고 즉시 개입하는 것"으로 갈 수 있음을 보여줍니다.
개발팀이 지금 바꿔야 할 기본값
이번 Honeycomb 발표를 보고 모든 팀이 당장 Honeycomb을 도입해야 한다는 결론을 낼 필요는 없습니다. 더 중요한 결론은 에이전트 instrumentation을 나중 일로 미루면 안 된다는 점입니다. AI 에이전트가 고객 데이터, 결제, 배포, 인프라, 내부 티켓, 코드 저장소에 접근한다면 telemetry는 기능 출시 후 붙이는 장식이 아닙니다. 제품 요구사항입니다.
최소 기준은 몇 가지로 정리할 수 있습니다. 첫째, conversation 또는 task 단위 ID가 필요합니다. 둘째, agent name, operation name, model, provider, prompt version, tool name, permission result, token count, latency, evaluation result를 같은 trace 안에서 연결해야 합니다. 셋째, 에이전트가 읽거나 쓴 memory와 external action은 감사 가능한 이벤트로 남겨야 합니다. 넷째, schema version을 기록해 나중에 OpenTelemetry GenAI 규약이 바뀌어도 데이터를 해석할 수 있어야 합니다.
사용자 요청 또는 운영 alert
conversation ID로 agent span과 model span 연결
tool call, MCP call, permission, memory event 기록
downstream trace, token cost, eval score, business outcome 결합
이 기본값은 코딩 에이전트에도 그대로 적용됩니다. Codex, Claude Code, Cursor 같은 도구가 코드를 생성할 때 AGENTS.md나 CLAUDE.md에 "새 agentic workflow에는 OpenTelemetry span을 남긴다"는 규칙을 넣는 것은 점점 자연스러워질 것입니다. Honeycomb 문서가 Agent Skills for AI Coding Assistants를 별도로 제공하는 것도 이 맥락입니다. AI assistant가 production debugging, OpenTelemetry instrumentation, Honeycomb feature usage를 이해하도록 skill과 MCP를 연결합니다.
관측성은 AI 안전의 낮은 층입니다
AI safety를 말할 때 흔히 모델 alignment, jailbreak, red teaming이 먼저 떠오릅니다. 하지만 운영 환경에서는 더 낮은 층의 안전이 필요합니다. 누가 무엇을 시켰는지, agent가 어떤 도구를 호출했는지, 어떤 데이터에 접근했는지, 실패 후 어떤 경로로 우회했는지, 비용이 어디서 늘었는지, 정책 위반 가능성이 언제 생겼는지 알아야 합니다. 이 정보가 없으면 alignment 논쟁 이전에 사고 조사 자체가 불가능합니다.
Honeycomb의 발표는 이 낮은 층을 제품으로 포장한 사례입니다. 에이전트가 더 자율적으로 움직일수록 팀은 더 많은 통제 장치를 원합니다. 그러나 통제는 단순한 kill switch만으로 충분하지 않습니다. kill switch를 누르기 전에 무엇이 일어났는지 알아야 하고, 누른 뒤에는 어떤 고객 요청과 작업이 중단됐는지 알아야 합니다. 관측성은 그래서 거버넌스, 보안, 비용 관리, 품질 평가의 공통 전제입니다.
물론 아직 초기 시장입니다. OpenTelemetry GenAI conventions는 Development 상태이고, 벤더마다 span 구조와 UI 모델이 다릅니다. agent memory나 multi-agent handoff의 표준화는 더 복잡합니다. "왜"라는 설명도 trace만으로 완성되지는 않습니다. 모델의 chain-of-thought를 공개하지 않는 환경에서 의사결정 원인을 어디까지 기록할 수 있는지도 별도 문제입니다. 그래서 지금 필요한 것은 과장된 자율 운영 약속이 아니라, 적어도 나중에 조사할 수 있는 evidence trail을 남기는 습관입니다.
결론
Honeycomb Agent Observability 출시는 AI 에이전트가 프로덕션 소프트웨어의 일부가 됐다는 신호입니다. 데모에서는 에이전트가 support workflow를 처리하고, shipping service와 연결되고, token을 태우고, tool loop에 빠지고, system prompt regression의 영향을 받습니다. 이것은 더 이상 챗봇 로그의 문제가 아닙니다. 운영 시스템의 문제입니다.
앞으로 AI 에이전트 플랫폼의 성숙도는 모델 성능표만으로 평가하기 어려워집니다. 좋은 에이전트 런타임은 실패하지 않는 척하는 런타임이 아니라, 실패했을 때 경로를 재구성하고 비용과 영향을 계산하며 정책 위반 가능성을 증명할 수 있는 런타임입니다. Honeycomb, IBM, OpenTelemetry, 그리고 agent telemetry 연구가 같은 방향으로 움직이는 이유도 여기에 있습니다.
AI 팀이 지금 던져야 할 질문은 단순합니다. "우리 에이전트가 어제 고객 데이터에 접근해 외부 API를 호출했을 때, 그 이유와 경로와 비용과 결과를 한 화면에서 설명할 수 있는가?" 이 질문에 답하지 못한다면, 다음 병목은 모델이 아니라 운영 증거입니다.