Agent Timeline, 에이전트 장애를 span으로 되감는 관측 전쟁
Honeycomb Agent Observability는 LLM 호출, 도구 실행, 에이전트 핸드오프를 하나의 trace 사건으로 복원하려는 시도입니다.

- 무슨 일: Honeycomb이
Agent Timeline, Canvas Agent, Canvas Skills로 프로덕션 에이전트 관측 기능을 내놨습니다.- 발표일은 2026년 5월 12일이며, O11yCon 2026은 5월 20-21일 "agent era" 운영을 전면에 둡니다.
- 핵심 변화: LLM 호출, 도구 실행, 에이전트 핸드오프, 다운스트림 API 영향을 하나의 시간축으로 재구성합니다.
- 개발자 영향: 에이전트 장애 분석은 평균 latency 대시보드보다
gen_ai.*span과 사건 복원이 중요해집니다.- Honeycomb은 OpenTelemetry GenAI semantic conventions v1.40.0을 통합했다고 밝혔습니다.
- 주의점: Agent Timeline은 Early Access 단계라 벤더별 구현과 표준 안정화 속도를 함께 봐야 합니다.
Honeycomb이 5월 12일 발표한 Agent Observability 기능은 겉으로 보면 관측 도구의 자연스러운 제품 확장처럼 보입니다. 하지만 이번 발표를 단순한 "AI 기능 추가"로 넘기기 어렵습니다. 개발팀이 에이전트를 실험 데모가 아니라 프로덕션 업무에 붙이기 시작하면, 가장 먼저 막히는 질문이 바뀌기 때문입니다. 이제는 "모델이 맞는 답을 했는가"만 묻기 어렵습니다. 더 실무적인 질문은 "어느 모델 호출이 어떤 도구를 실행했고, 그 도구가 어떤 API와 데이터베이스 상태를 만났으며, 그 결과 다음 에이전트가 왜 다른 결정을 했는가"입니다.
Honeycomb의 답은 이 질문을 대시보드가 아니라 타임라인으로 풀겠다는 것입니다. 새 제품 페이지에서 Agent Timeline은 multi-agent, multi-trace conversation을 하나의 coherent view로 보여준다고 설명됩니다. 그 안에는 LLM call, tool invocation, agent handoff, downstream system behavior가 함께 들어갑니다. 기존 분산 추적이 서비스 A에서 서비스 B로 이어지는 호출 그래프를 복원했다면, Agent Timeline은 여기에 에이전트의 대화 흐름과 도구 선택까지 올려놓으려는 시도입니다.
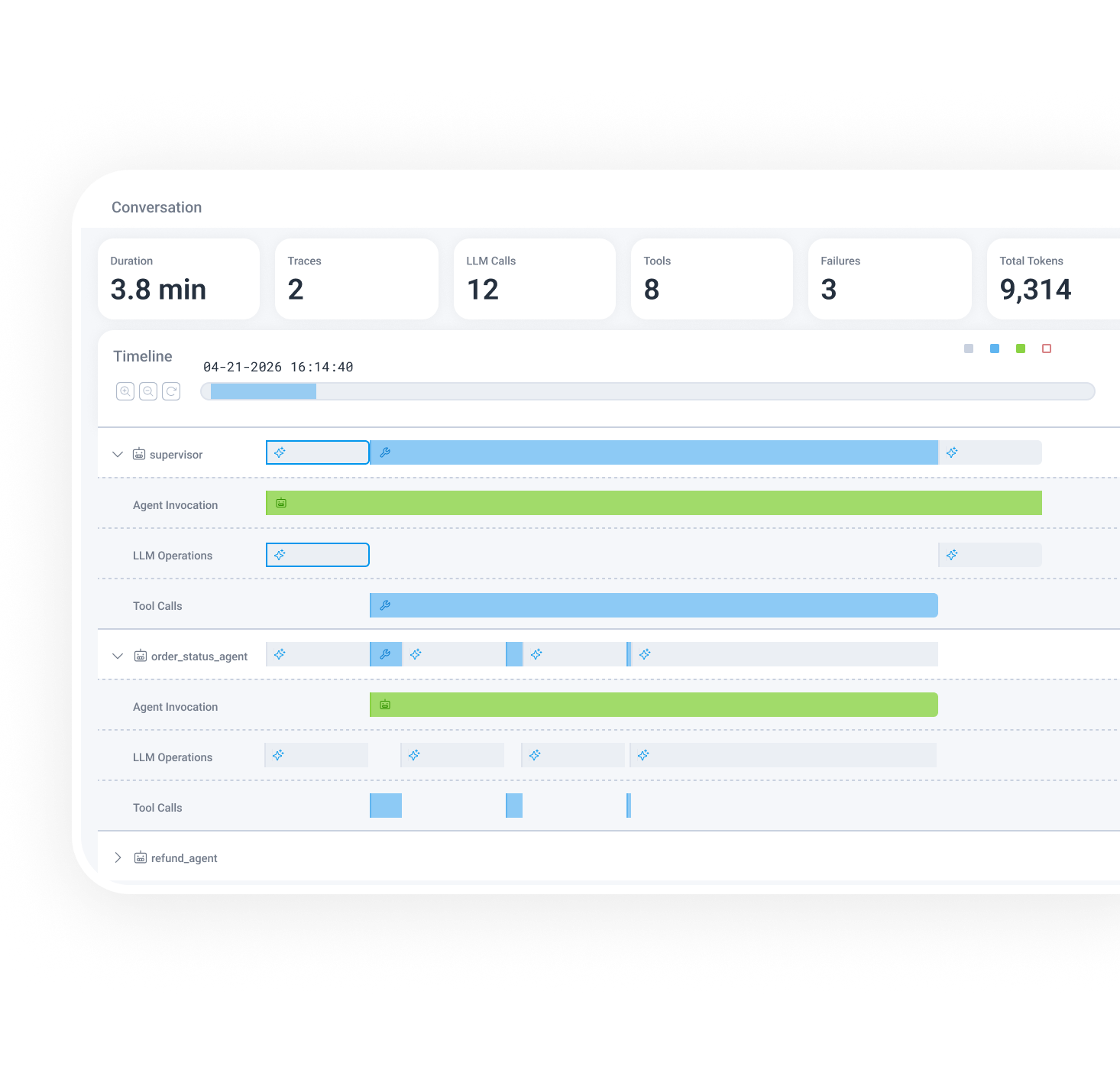
이 차이는 작지 않습니다. 전통적인 백엔드 장애에서는 HTTP 500, DB timeout, queue lag, p95 latency 같은 신호가 사건의 중심에 있었습니다. 에이전트 장애에서는 같은 장애가 훨씬 늦게 보일 수 있습니다. 예를 들어 고객 지원 에이전트가 주문 조회 도구를 두 번 호출하고, 첫 호출의 부분 실패를 자연어 추론으로 덮은 뒤, 다른 에이전트에게 잘못된 상태를 넘긴다고 해봅시다. 최종 API는 200을 반환할 수 있습니다. 평균 latency도 정상일 수 있습니다. 그러나 사용자는 틀린 안내를 받습니다. 이때 필요한 것은 더 많은 차트가 아니라 결정 경로의 복원입니다.
Honeycomb 발표문은 이 지점을 직접 겨냥합니다. 회사는 AI 에이전트가 코드 생성, 인시던트 트리아지, 클라우드 인프라 배포, 고객 서비스 같은 작업을 다루기 시작했지만 기존 관측 도구는 비결정적이고 multi-hop인 agent workflow에 맞게 설계되지 않았다고 말합니다. "대시보드는 무너지고, 평균은 거짓말하며, 에이전트가 인시던트를 일으켰을 때 팀은 무엇을 왜 결정했는지 재구성할 방법이 없다"는 문제의식입니다. 표현은 마케팅 문장에 가깝지만, 실제 현장에서 이미 체감되는 빈칸을 짚습니다.
Agent Timeline이 보는 사건 단위
제품 설명을 풀어보면 Agent Timeline의 핵심 객체는 개별 span 하나가 아니라 agent conversation입니다. 사용자는 conversation ID를 넣고 전체 duration, model call 수, tool call 수, retry, involved agents, failure를 요약 수준에서 봅니다. 그 다음 span으로 내려가면 LLM operation, tool call, token usage, prompt detail을 확인하고, 더 아래에서는 API call, database query, infrastructure behavior까지 이어서 봅니다.
| 관측 단위 | 기존 서비스 관측 | 에이전트 관측 |
|---|---|---|
| 시작점 | 요청, 배포, 서비스 호출 | conversation, task, agent run |
| 중간 사건 | HTTP span, DB query, queue message | LLM call, tool invocation, retry, handoff |
| 실패 신호 | error rate, timeout, saturation | 잘못된 도구 선택, 부분 실패 은폐, downstream 영향 |
| 표준화 축 | OpenTelemetry trace/metric/log | gen_ai.*, agent span, MCP conventions |
여기서 중요한 것은 Honeycomb만의 UI가 아닙니다. 에이전트 관측이 서비스 관측의 하위 기능이 아니라 별도 사건 모델을 요구한다는 점입니다. 에이전트는 한 번의 요청 안에서 같은 도구를 여러 번 호출할 수 있고, 실패한 결과를 자연어로 재해석할 수 있으며, 중간 판단을 다른 에이전트에게 넘길 수 있습니다. 따라서 "요청 하나의 trace"만으로는 충분하지 않고, "작업 하나가 어떻게 모델-도구-시스템 사이를 이동했는가"를 봐야 합니다.
Honeycomb이 내세운 기능도 이 구조에 맞춰져 있습니다. horizontal swim lane은 병렬 실행과 agent handoff를 보여주고, conversation-level failure count와 failing span highlight는 실패를 first-class citizen으로 다룹니다. "Show Failures Only" 같은 모드는 단순 필터처럼 보이지만, 에이전트 운영에서는 꽤 실용적입니다. multi-agent 실행에서는 정상 span이 너무 많고, 실패도 단일 exception이 아니라 retry, fallback, 잘못된 context 전달처럼 흩어져 나타납니다. 실패만 잘라서 봐야 하는 이유가 있습니다.
OpenTelemetry가 조용히 중요한 이유
이번 발표에서 가장 실무적인 문장은 Honeycomb이 OpenTelemetry GenAI semantic conventions v1.40.0을 통합했고, gen_ai.* attributes를 first-class citizen으로 다룬다는 대목입니다. OpenTelemetry 문서는 GenAI semantic conventions를 아직 Development 상태로 두고 있습니다. 동시에 GenAI events, exceptions, metrics, model spans, agent/framework spans, MCP conventions를 별도 영역으로 정리합니다.
이 구조는 에이전트 관측 경쟁의 중요한 신호입니다. 한동안 LLM 앱 관측은 SDK 중심으로 움직였습니다. LangChain을 쓰면 LangSmith, 특정 gateway를 쓰면 해당 provider dashboard, 특정 agent framework를 쓰면 그 프레임워크의 run log를 보는 식입니다. 실험 단계에서는 충분합니다. 하지만 프로덕션에서는 문제가 생깁니다. 실제 에이전트는 모델 provider, vector store, MCP server, 내부 API, queue, database, browser automation을 섞어 씁니다. 관측 데이터가 프레임워크 단위로 갈라지면 장애 복원이 다시 수작업이 됩니다.
OpenTelemetry가 해법의 전부는 아니지만, 최소한 공통 언어가 됩니다. gen_ai.* 속성이 모델 호출과 토큰 사용량만 담는 데서 멈추지 않고 agent span, tool execution, MCP 연결까지 확장되면, 팀은 벤더 전용 이벤트를 일일이 번역하지 않아도 됩니다. Honeycomb이 "proprietary SDK나 framework lock-in 없이" 실시간 가시성을 제공한다고 말하는 배경도 여기에 있습니다. 실제로 lock-in이 얼마나 줄어드는지는 구현을 봐야 하지만, 표준 span을 제품의 전면에 둔 방향은 맞습니다.
사용자 요청 또는 자동 작업
에이전트 span: 계획, 모델 호출, 도구 선택, retry
시스템 span: API, DB, queue, infra 상태
conversation 타임라인: 실패와 결정 경로 재구성
OpenTelemetry 문서가 기존 instrumentation의 기본 emission 버전을 갑자기 바꾸지 말고 opt-in 경로를 쓰라고 안내하는 것도 눈여겨볼 지점입니다. 표준이 개발 중일 때 가장 위험한 것은 "표준을 따른다"는 이유로 운영 데이터 형식이 자주 흔들리는 일입니다. AI 관측 데이터는 이미 prompt, completion, token, tool result, exception, policy decision, retrieval context처럼 민감하고 복잡한 필드를 포함합니다. 표준화가 필요하지만, 안정화되지 않은 표준을 무리하게 강제하면 다시 운영 리스크가 됩니다.
에이전트 장애는 왜 평균으로 잡히지 않는가
Honeycomb 공동창업자 Charity Majors는 3월 글에서 "anomaly detection 자체가 어려운 문제가 아니라, 어떤 anomaly를 신경 써야 하는지 결정하는 것이 더 어렵다"는 취지로 설명했습니다. 이 관점은 에이전트에도 잘 맞습니다. 에이전트는 정상과 비정상의 경계가 단순하지 않습니다. 모델이 도구를 세 번 호출했는지 다섯 번 호출했는지는 그 자체로 장애가 아닙니다. 답변 시간이 3초 늘어난 것도 반드시 장애는 아닙니다. 문제는 그 지연과 재시도가 특정 사용자 상태, 특정 도구 응답, 특정 prompt branch와 결합해 잘못된 행동으로 이어졌는가입니다.
일반적인 APM 대시보드는 평균, percentile, error rate를 잘 보여줍니다. 그러나 에이전트의 중요한 사건은 고차원 조합에 숨어 있습니다. 같은 모델, 같은 도구, 같은 API라도 retrieval 결과가 다르고, tool schema가 조금 바뀌고, MCP server가 다른 permission을 반환하면 행동이 달라질 수 있습니다. 그렇기 때문에 에이전트 관측은 "모든 것을 로그로 남기자"가 아니라 "나중에 재구성 가능한 형태로 남기자"에 가까워야 합니다.
Agent Timeline의 가치는 여기서 생깁니다. 대시보드가 현재 상태를 압축한다면, 타임라인은 사건을 펼칩니다. 에이전트가 어떤 tool call을 선택했고, 실패한 span이 어디에 있었고, downstream API degradation과 agent stall이 어떻게 연결됐는지를 한 화면에서 봐야 합니다. 이것은 운영팀만의 문제가 아닙니다. AI 제품팀, 플랫폼팀, 보안팀, 데이터팀이 같은 사건을 서로 다른 언어로 보지 않게 만드는 문제입니다.
경쟁은 이미 시작됐습니다
Honeycomb이 이 영역에 들어온 것은 놀랍지 않습니다. 2026년 들어 관측 기업들은 대부분 AI/agent 운영을 전면에 내세우고 있습니다. Grafana Labs는 GrafanaCON에서 AI Observability와 agentic workflow를 발표했고, IBM Instana도 AI Agent and LLM Observability를 내세웠습니다. Datadog, New Relic, Elastic도 AI assistant와 LLM 관측, MCP 기반 UI 경험을 강화하고 있습니다. LLM 앱 전용으로는 LangSmith, Arize 같은 도구가 이미 개발자 워크플로에 자리 잡았습니다.
차이는 출발점입니다. LangSmith류 도구는 개발자가 agent run을 디버깅하는 데 강합니다. 기존 observability vendor는 프로덕션 시스템, SLO, trace, incident response에 강합니다. Honeycomb의 발표는 후자에서 전자로 들어오는 움직임입니다. "에이전트 자체를 보는 UI"만이 아니라 "에이전트가 건드린 시스템 전체를 같이 보는 UI"가 차별점입니다. 이 관점은 실제 운영에서 중요합니다. 에이전트 장애의 원인이 prompt가 아니라 slow database, rate-limited API, 권한이 빠진 MCP tool, 잘못된 feature flag일 수 있기 때문입니다.
반대로 한계도 분명합니다. Agent Timeline은 Early Access이고, GA는 다음 달로 예고됐습니다. 제품 설명만으로는 대규모 multi-agent 시스템에서 cardinality 비용, prompt/response 개인정보 처리, retention 정책, sampling 전략을 어떻게 다루는지 충분히 알 수 없습니다. gen_ai.*를 first-class로 취급한다는 말도 실제로는 어떤 attribute를 저장하고, 어떤 필드를 마스킹하고, 어떤 구조로 query할 수 있는지까지 봐야 의미가 있습니다.
개발팀은 무엇을 준비해야 하나
이번 뉴스를 당장 "Honeycomb을 써야 한다"는 결론으로 읽을 필요는 없습니다. 더 중요한 결론은 에이전트 운영 데이터의 설계가 제품 초기부터 필요하다는 점입니다. 많은 팀이 LLM 앱을 만들 때 evaluation과 observability를 뒤섞습니다. evaluation은 답변 품질, task success, regression을 판단하는 체계입니다. observability는 실제 운영에서 어떤 사건이 발생했는지 설명하는 데이터 체계입니다. 둘은 연결돼야 하지만 같은 것은 아닙니다.
예를 들어 고객 지원 에이전트가 환불 정책을 잘못 안내했다면 evaluation은 그 답변이 정책과 어긋났는지 판단합니다. observability는 그 답변이 나오기까지 어떤 retrieval 문서가 들어왔고, 어떤 tool call이 실패했고, fallback model이 쓰였는지 보여줍니다. 둘 중 하나만 있으면 팀은 원인을 놓칩니다. 좋은 평가 점수에도 특정 production path에서 장애가 날 수 있고, 완벽한 trace가 있어도 품질 기준이 없으면 "그래서 틀렸는지" 판단하기 어렵습니다.
개발팀 입장에서 지금 확인할 체크리스트는 비교적 명확합니다. 첫째, agent run에 안정적인 correlation ID가 있는지 봐야 합니다. 둘째, model call과 tool call이 같은 trace 안에서 이어지는지 봐야 합니다. 셋째, prompt와 tool result를 전부 저장할 수 없다면 최소한 마스킹된 요약, schema version, token usage, provider, model, retry reason을 남겨야 합니다. 넷째, 에이전트가 downstream 시스템에 준 영향을 기존 service trace와 연결해야 합니다. 다섯째, OpenTelemetry GenAI conventions의 안정화 상태를 따라가되, 변경 가능한 experimental 필드를 운영 계약처럼 고정하지 않아야 합니다.
O11yCon이 말해주는 전환점
Honeycomb은 발표문에서 5월 12-14일 Innovation Week와 5월 20-21일 O11yCon을 함께 언급했습니다. 이벤트 일정 자체보다 흥미로운 것은 주제의 이동입니다. 관측성 컨퍼런스가 이제 "서비스를 어떻게 모니터링할 것인가"에서 "AI-powered systems in production을 어떻게 운영할 것인가"로 무게중심을 옮기고 있습니다. 이는 에이전트가 아직 과장된 말이라서가 아니라, 실제 운영팀이 이미 에이전트와 함께 일하기 시작했기 때문입니다.
에이전트는 코드도 만들고, 배포 실패를 조사하고, cloud resource를 조정하고, 고객 대화를 처리합니다. 이 작업들은 모두 기존 시스템을 건드립니다. 따라서 에이전트 운영은 AI 팀만의 책임으로 남을 수 없습니다. SRE는 agent span을 읽어야 하고, AI 엔지니어는 service trace를 읽어야 합니다. 보안팀은 tool permission과 prompt leakage를 봐야 하고, 제품팀은 실패한 conversation이 사용자 경험에 어떤 영향을 줬는지 봐야 합니다. 관측 도구가 이 교차점을 잡으려는 것은 자연스러운 흐름입니다.
Honeycomb의 Agent Timeline은 이 흐름의 한 장면입니다. 아직 답이 완성됐다고 보기는 어렵습니다. 표준은 개발 중이고, 제품은 Early Access이며, 실제 팀마다 에이전트 architecture가 다릅니다. 하지만 방향은 선명합니다. AI 에이전트의 다음 경쟁은 더 똑똑한 모델 호출만이 아닙니다. 그 모델 호출이 프로덕션에서 어떤 행동을 만들었는지, 실패했을 때 누가 얼마나 빨리 재구성할 수 있는지가 경쟁력이 됩니다.
개발자에게 남는 질문은 단순합니다. 지금 만드는 에이전트가 내일 장애를 냈을 때, 우리는 그 사건을 설명할 수 있습니까? Honeycomb의 이번 발표는 그 질문을 관측 업계의 전면으로 끌어올렸습니다. 그리고 이 질문은 특정 벤더보다 오래갈 가능성이 큽니다. 에이전트가 제품 안으로 깊이 들어갈수록, trace는 성능 최적화 도구를 넘어 책임과 신뢰의 기록이 되기 때문입니다.