Jules 평가 공개, 코딩 에이전트의 침묵도 평가 대상
Google Labs가 Jules 평가 글에서 목표 단위 코딩 에이전트 평가를 제안했습니다. 705개 버그와 Hit@5 57% 수치가 말하는 새 기준을 봅니다.

- 무슨 일: Google Developers Blog가 2026년 6월 22일
Jules의 선제적 코딩 에이전트 평가 방향을 공개했습니다.- 내부 Google 코드베이스의 705개 버그와 1,178개 CL을 사용해 목표 단위 통찰 평가를 시험했습니다.
- 숫자: 단일 탐색 라운드의 평균 최고 점수는 4.5/5, Hit@5는 탐색 예산 3라운드에서 57%였습니다.
- 의미: 코딩 에이전트 평가는 패치 성공률에서
notify,question,draft,stay silent판단으로 넓어집니다. - 주의점: 블로그 수치는 내부 데이터의 예비 결과이며, arXiv 논문은 완성된 공개 벤치마크가 아니라 평가 프레임워크입니다.
Google이 2026년 6월 22일 Developers Blog에 Measuring What Matters with Jules를 올렸습니다. 이 글은 새 버튼이나 가격표를 발표하지 않습니다. Google Labs가 던진 질문은 더 근본적입니다. 코딩 에이전트가 이미 이슈를 읽고, 저장소를 복제하고, 테스트를 돌리고, 풀 리퀘스트를 열 수 있다면 무엇을 다음 평가 기준으로 삼아야 합니까.
Google의 답은 "목표"입니다. SWE-Bench류 평가는 "이 버그를 고쳐라"처럼 이미 좁게 정의된 작업을 봅니다. Google 글은 그 앞단을 보자고 말합니다. 에이전트가 코드베이스와 이슈, 테스트 실패, 설계 문서, 개발자 피드백을 보다가 "지금 개발자가 알아야 할 통찰"을 고를 수 있어야 합니다. 그 통찰을 보여줄지 말지 판단하고, 피드백 뒤 다음 판단을 바꿀 수 있는지도 평가 대상이라는 주장입니다.
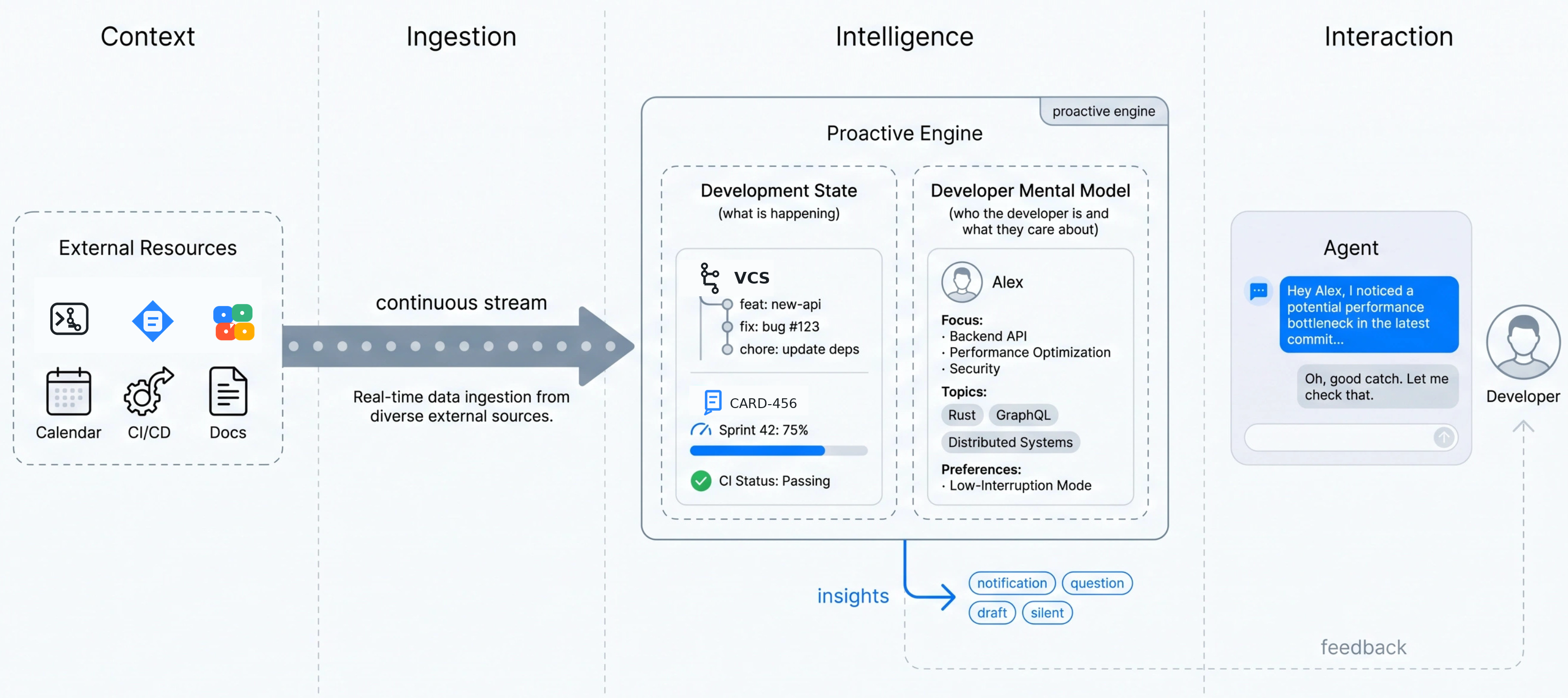
이 지점에서 Jules는 단순한 비동기 코딩 도구보다 평가 실험의 표면에 가깝습니다. Google은 Jules를 통해 코딩 에이전트가 반응형 도우미에서 지속적으로 문맥을 흡수하는 엔진으로 이동한다고 설명합니다. 에이전트가 먼저 말할 수 있다면, 이제 "얼마나 자주 말하는가"보다 "말해도 되는 순간을 골랐는가"가 중요해집니다. 알림이 많아지면 생산성 도구는 금세 또 다른 소음원이 됩니다.
705개 버그를 목표로 묶은 이유
Google Labs가 공개한 예비 평가 방식은 실제 버그 수정 이력을 출발점으로 삼습니다. 블로그에 따르면 연구팀은 내부 Google 코드베이스에서 705개 버그와 1,178개 CL을 사용했습니다. 여기서 CL은 Google식 코드 변경 단위입니다. 연구팀은 짧은 시간 안에 접수되고 수정된 관련 버그들을 시간적 근접성과 의미적 유사성으로 묶어 더 큰 목표를 만들었습니다.
예시는 "샌드박스 시간 초과 오류", "브로커 설정 실패", "네트워크 격리 테스트 불안정" 같은 항목입니다. 각각은 작은 버그입니다. 하지만 함께 보면 "샌드박스 실행 신뢰성을 강화한다"는 상위 목표가 됩니다. 사람이 실제로 처리한 여러 버그를 묶어 목표를 만들고, 코드베이스를 수정 전 상태로 되돌린 뒤, 에이전트가 같은 위치에서 무엇을 알아차리는지 보는 방식입니다.
이 설계가 중요한 이유는 코딩 에이전트의 실전 사용과 닮았기 때문입니다. 개발자는 항상 완벽하게 정리된 티켓을 주지 않습니다. 테스트가 간헐적으로 실패하고, 로그가 서로 다른 서비스를 가리키고, 최근 배포와 오래된 설정 변경이 섞입니다. 좋은 에이전트는 "이 파일을 고쳐라"만 수행하는 것이 아니라, 흩어진 신호가 같은 문제를 가리키는지 알아차려야 합니다.
Google은 에이전트에게 최대 3라운드의 탐색 예산을 줬다고 설명합니다. 한 라운드만 허용했을 때도 에이전트는 가장 관련 높은 통찰에서 평균 4.5/5점을 기록했습니다. 복잡한 문제에서는 추가 탐색이 영향을 줬습니다. 탐색 예산을 2라운드에서 3라운드로 늘리자 Hit@5가 33%에서 57%로 회복됐습니다. 여기서 Hit@5는 상위 5개 추천 안에 정확한 진단 통찰이 들어가는 비율입니다.
숫자를 읽을 때 조심할 부분도 있습니다. 이 결과는 공개 저장소가 아니라 내부 Google 코드베이스의 예비 평가입니다. 재현 가능한 벤치마크가 공개된 것은 아닙니다. 그래도 수치가 보여주는 방향은 분명합니다. 코딩 에이전트 성능은 모델 호출 한 번의 추론력만으로 정해지지 않습니다. 탐색 예산, 과거 버그를 목표로 묶는 방법, 에이전트가 어떤 증거를 본 상태였는지가 결과를 바꿉니다.
패치가 아니라 통찰 정책을 평가한다
이 블로그의 배경에는 2026년 5월 7일 arXiv에 제출된 Google Labs 포지션 페이퍼가 있습니다. 논문은 코딩 에이전트가 단순 자율성을 넘어 선제성을 갖추려면 insight policy, 즉 통찰 정책을 평가해야 한다고 주장합니다. 통찰 정책은 무엇이 중요한지, 어떤 증거가 충분한지, 개발자에게 보여줄지, 질문할지, 초안을 만들지, 아니면 침묵할지를 고르는 정책입니다.
논문은 선제성을 세 단계로 나눕니다. 1단계는 반응형입니다. 개발자가 명시적으로 요청할 때만 실행됩니다. 2단계는 예약형입니다. 일정, 웹훅, GitHub 이벤트, 저장소 상태 같은 트리거로 실행되지만, 개발자별 방해 비용과 피드백을 계속 학습하지는 않습니다. 3단계는 상황 인식형입니다. 지속적인 이벤트 스트림을 보고, 예상 이익과 방해 비용을 비교하고, 침묵을 명시적 행동으로 취급하며, 개발자 피드백을 다음 판단에 반영합니다.
여기서 "침묵도 평가 대상"이라는 말이 나옵니다. 일반 자동화에서는 결과를 많이 내는 도구가 좋아 보입니다. 선제적 에이전트에서는 반대 상황이 생깁니다. 에이전트가 낮은 확신의 경고를 계속 띄우면 개발자는 알림을 무시합니다. 반대로 실제 장애 조짐을 놓치면 선제성은 이름뿐입니다. 따라서 좋은 평가는 표시된 메시지만 보면 부족합니다. 에이전트가 표시하지 않기로 한 후보까지 기록해야 침묵이 합리적이었는지 볼 수 있습니다.
논문은 이를 위해 세 가지 평가 대상을 제안합니다. IDQ는 통찰 결정 품질입니다. 에이전트가 적절한 시점에 알림, 질문, 초안, 침묵 중 맞는 행동을 골랐는지 봅니다. CGS는 문맥 근거 점수입니다. 표시된 통찰이 올바른 파일, 로그, 이슈, 테스트 결과 같은 증거로 뒷받침되는지 평가합니다. LL은 학습 향상입니다. 개발자 피드백을 받은 정책이 고정된 정책보다 나중의 유사 상황에서 나아지는지 봅니다.
| 평가 대상 | 묻는 질문 | 실무에서 드러나는 실패 |
|---|---|---|
IDQ | 지금 말할지, 질문할지, 초안을 만들지, 침묵할지 | 중요하지 않은 알림을 계속 띄우거나 긴급한 신호를 놓침 |
CGS | 통찰이 실제 코드, 로그, 이슈, 테스트 증거에 기대는지 | 그럴듯한 진단을 내지만 근거 파일이나 실패 로그가 빗나감 |
LL | 피드백 뒤 다음 판단이 실제로 개선되는지 | 한 번의 피드백에 과적합해 다음 비슷한 상황을 더 나쁘게 처리함 |
이 표는 코딩 에이전트 팀이 지금 당장 제품 지표를 바꿀 때 쓸 수 있는 언어입니다. "풀 리퀘스트를 몇 개 열었는가"는 여전히 필요합니다. 하지만 선제적 에이전트에는 충분하지 않습니다. 경고를 띄운 이유, 경고를 띄우지 않은 이유, 개발자가 무시하거나 승인한 뒤 정책이 어떻게 바뀌었는지가 함께 남아야 합니다.
SWE-Bench 다음의 빈칸
SWE-Bench는 코딩 에이전트 시장에서 중요한 기준점이 됐습니다. 모델 회사와 도구 회사는 점수로 개선을 설명하고, 개발자는 여러 제품을 비교할 최소 공통분모를 얻었습니다. 하지만 SWE-Bench식 작업은 대부분 이미 문제가 정의된 뒤에 시작합니다. 이슈가 있고, 저장소가 있고, 성공 조건이 있습니다. Google 논문이 지적하는 빈칸은 그 이전입니다. 누가 문제를 정의합니까.
실제 팀에서는 많은 문제가 완전한 이슈로 태어나지 않습니다. CI 실패가 처음에는 우연처럼 보이고, 고객지원 티켓이 제품 버그인지 설정 문제인지 불분명하고, 같은 테스트가 서로 다른 브랜치에서 다른 이유로 실패합니다. 선제적 코딩 에이전트가 가치 있으려면 이런 신호들을 묶어 "이건 지금 볼 만한 문제"라고 제안해야 합니다. 그 제안이 틀리면 방해이고, 맞으면 개발자의 주의를 아껴 줍니다.
Google의 접근은 평가 데이터를 만드는 방식에서도 흥미롭습니다. 이미 사람이 고친 여러 버그를 사후에 묶어 목표를 추정합니다. 이것은 완벽하지 않습니다. 사람이 나중에 붙인 해석이 들어갈 수 있고, Google 내부 코드베이스의 작업 방식이 다른 조직과 다를 수 있습니다. 그러나 완전히 인공적인 목표를 만드는 것보다 실제 개발 기록에 가깝습니다. 공개 GitHub 이슈와 해결 PR로 확장하겠다는 Google의 다음 계획이 중요한 이유입니다.
공개 데이터로 확장하면 난점도 커집니다. 이슈 제목과 PR 설명만으로 상위 목표를 만들면 놓치는 신호가 많습니다. 설계 문서, 코드 리뷰 대화, 장애 보고서, 채팅 기록은 대개 공개되지 않습니다. 반대로 모든 기록을 평가 데이터로 공개하면 개인정보와 회사 기밀 문제가 생깁니다. 논문이 원시 IDE 스냅샷이나 채팅 전문 대신, 시간 정렬된 증거 창과 출처 정보를 저장하는 방식을 언급한 이유가 여기에 있습니다.
Jules만의 이야기가 아니다
이번 글의 제목에는 Jules가 들어가지만, 경쟁 구도는 훨씬 넓습니다. Claude Code, OpenAI Codex, GitHub Copilot coding agent, Cursor, Gemini CLI, Devin 같은 제품은 이미 저장소와 터미널, 이슈, 풀 리퀘스트 사이에서 작업합니다. 최근 제품 업데이트도 명령형 프롬프트를 넘어 예약 실행, 백그라운드 작업, 웹훅, 팀 단위 자동화로 이동했습니다.
이런 제품들이 늘수록 사용자는 같은 질문에 부딪힙니다. 에이전트가 먼저 이슈를 만들어도 됩니까. 실패한 테스트를 보고 개발자를 불러도 됩니까. 같은 파일을 건드리는 세 개의 비동기 작업을 동시에 열어도 됩니까. 오래된 피드백을 근거로 새 작업을 조용히 낮은 우선순위로 밀어도 됩니까. 이 질문들은 모델 성능표만으로 답할 수 없습니다. 권한, 방해 비용, 팀 규칙, 작업 맥락이 함께 들어갑니다.
Hacker News의 이전 Jules 토론에서도 이 문제가 드러납니다. 일부 사용자는 무료 티어의 긴 작업 실행량을 높게 평가했지만, 진행 상태와 diff 가시성이 부족하고 여러 PR을 동시에 맡기면 수동 확인이 필요하다고 적었습니다. 이 반응은 "더 자율적으로 실행하라"보다 "무엇을 보고했고, 언제 사용자가 끼어들 수 있었는가"가 중요하다는 신호입니다. 선제성 평가는 바로 이 지점을 수치화하려는 시도입니다.
제품팀 입장에서는 평가 로그 설계가 달라집니다. 지금 많은 코딩 에이전트 로그는 입력 프롬프트, 도구 호출, 파일 변경, 테스트 결과, 최종 diff에 집중합니다. 선제적 평가를 하려면 후보 통찰 목록, 표시하지 않은 이유, 표시한 메시지의 근거, 사용자의 반응, 이후 유사 상황에서 정책이 바뀐 기록까지 필요합니다. 즉 평가를 나중에 덧붙일 수 없습니다. 제품에 처음부터 이벤트 장부와 피드백 경로가 들어가야 합니다.
내부 수치와 공개 벤치마크 사이
Google 블로그의 4.5/5와 Hit@5 57%는 눈에 띄는 숫자입니다. 하지만 이 숫자를 곧바로 "Jules가 목표형 코딩 에이전트를 해결했다"는 뜻으로 읽으면 안 됩니다. 데이터는 내부 Google 코드베이스에서 왔고, 평가자는 LLM을 사용해 통찰을 1점에서 5점까지 판정했습니다. 논문 자체도 IDQ, CGS, LL이 완성된 벤치마크가 아니라 평가 대상이라고 명시합니다.
그래도 이번 공개가 중요한 이유는 코딩 에이전트 경쟁의 질문을 바꾸기 때문입니다. 2024년과 2025년에는 "이 에이전트가 몇 개 이슈를 고치나"가 중심이었습니다. 2026년의 실전 질문은 더 운영적입니다. 이 에이전트가 언제 시작해야 합니까. 어떤 증거가 충분합니까. 개발자를 방해할 만큼 중요한 신호입니까. 한 번 무시당한 경고를 다음에도 반복합니까. 이런 질문은 팀의 실제 개발 리듬과 연결됩니다.
이 기준이 널리 쓰이면 벤치마크도 한 줄 점수에서 멀어질 가능성이 큽니다. IDQ가 높고 CGS가 낮으면 타이밍은 맞지만 근거가 약한 에이전트입니다. CGS가 높고 IDQ가 낮으면 자료는 잘 찾지만 표시 시점이 나쁜 에이전트입니다. LL이 음수라면 피드백을 배운다는 기능이 오히려 과적합을 만들 수 있습니다. 하나의 순위표보다 진단표가 더 유용해지는 구조입니다.
개발 조직이 지금 가져갈 실무 교훈은 세 가지입니다. 첫째, 비동기 코딩 에이전트를 도입할 때 작업 성공률만 보지 말고 방해율을 같이 기록해야 합니다. 둘째, 에이전트가 근거로 든 파일, 로그, 이슈, 테스트를 사람이 추적할 수 있어야 합니다. 셋째, 피드백은 채팅 반응으로 끝나면 안 됩니다. 다음 유사 상황에서 정책이 바뀌었는지 확인할 수 있는 평가 세트가 필요합니다.
Jules 평가 글은 Google 제품 홍보처럼 보일 수 있지만, 더 오래 남을 부분은 평가 언어입니다. 코딩 에이전트가 개발자 옆에서 기다리는 도구에서 개발 흐름을 감시하는 동료로 이동한다면, 침묵은 빈칸이 아니라 선택입니다. 좋은 에이전트는 모든 것을 고치려 들지 않습니다. 어떤 문제를 지금 꺼낼지, 어떤 문제는 더 많은 증거를 모을지, 어떤 순간에는 개발자의 집중을 건드리지 않을지 판단해야 합니다. Google Labs가 이번에 공개한 프레임은 그 판단을 측정 가능한 대상으로 끌어낸 첫 신호에 가깝습니다.