AI 검색 11% 미검증, 출처 카드 뒤의 빈틈
5월 13일 arXiv 연구는 Google AI Overviews의 5.5만 검색과 9.8만 주장을 분석해 AI 검색의 출처와 클릭 경제를 드러냅니다.

- 무슨 일: 5월 13일 arXiv 논문이 Google AI Overviews를
55,393개 검색어와98,020개 주장 단위로 측정했습니다.- 전체 활성화율은 13.7%, 질문형 검색은 64.7%로 높았습니다.
- 핵심 수치: 인용된 주장 중 11.0%는 출처로 충분히 뒷받침되지 않았고, 인용 도메인의 29.8%는 같은 검색의 첫 페이지 결과에 없었습니다.
- 의미: AI 검색의 문제는 환각만이 아니라 랭킹, 인용, 클릭 경제가 분리되는 새 정보 유통 구조입니다.
- 개발자는 RAG 제품과 AI 답변 UI를 만들 때 "출처가 붙었다"와 "검증됐다"를 구분해야 합니다.
Google 검색 결과의 맨 위에 뜨는 AI Overviews는 이제 단순한 실험 기능이 아닙니다. 사용자가 별도 챗봇을 켜지 않아도 검색창에 질문을 넣는 순간 생성 답변이 먼저 나타나고, 링크는 답변의 근거 카드처럼 붙습니다. Google은 이 방향을 더 밀고 있습니다. 2026년 1월 27일에는 Gemini 3를 AI Overviews의 글로벌 기본 모델로 적용하고, AI Overview에서 곧바로 AI Mode 대화로 이어지는 흐름을 공개했습니다. 5월 6일에는 AI Mode와 AI Overviews 안에서 원문 링크, 뉴스 구독 링크, 공론장·소셜 출처 미리보기, inline link preview를 더 잘 보여주겠다고 발표했습니다.
이 변화의 공식 설명은 낙관적입니다. Google은 AI 검색이 사용자를 더 깊은 웹으로 연결하고, 원출처와 창작자를 더 쉽게 찾게 만든다고 말합니다. 하지만 2026년 5월 13일 arXiv에 올라온 논문 Measuring Google AI Overviews: Activation, Source Quality, Claim Fidelity, and Publisher Impact는 조금 다른 질문을 던집니다. "AI 답변에 출처가 붙어 있다면, 그 출처는 실제로 무엇을 보증하는가?" "그 출처는 Google의 기존 첫 페이지 랭킹과 같은 세계에서 나온 것인가?" "인용된 페이지가 광고로 먹고사는 퍼블리셔라면, 답변층이 클릭을 흡수할 때 누가 비용을 내는가?"
논문은 Google을 비난하기 위해 만든 의견문이 아니라 측정 논문에 가깝습니다. Washington University in St. Louis 연구진은 2026년 3월 13일부터 4월 21일까지 40일 동안 미국 Google Trends에서 뽑은 55,393개 trending query를 수집했습니다. 19개 주제 카테고리를 매일 돌며 검색 결과, AI Overview 본문, 인용 링크, 첫 페이지 일반 결과, 인용 페이지의 본문과 광고 구조를 함께 저장했습니다. 그리고 AI Overview 답변을 98,020개의 원자 주장으로 나눠, 각각이 인용된 페이지로 지지되는지 검증했습니다.
여기서 중요한 점은 이 연구가 AI 검색을 "정답률" 하나로만 보지 않는다는 것입니다. 활성화율, 출처 선택, 주장 검증, 퍼블리셔 경제를 한 번에 봅니다. 그래서 결과도 더 불편합니다. AI Overview는 질문형 검색에서 매우 자주 나타나고, 인용 출처는 평균적으로 꽤 신뢰할 만하지만, 출처 카드가 붙었다고 해서 그 답변의 모든 주장이 검증되는 것은 아니었습니다.
질문형 검색에서 AI 답변은 예외가 아닙니다
가장 먼저 봐야 할 수치는 활성화율입니다. 연구진이 관측한 전체 AI Overview 활성화율은 13.7%였습니다. 이 숫자만 보면 아직 제한적으로 보일 수 있습니다. 그러나 검색어가 질문 형태일 때는 64.7%로 올라갑니다. 반면 질문 형태가 아닌 검색어는 9.5%였습니다. 연구진은 질문형 검색이 비질문형보다 6.8배 더 높은 활성화율을 보였다고 정리합니다.
이 차이는 사용자의 검색 숙련도와 연결됩니다. 짧은 키워드로 검색하는 사람보다 "무엇을 해야 하나요", "왜 이런 일이 생기나요", "어떻게 비교해야 하나요"처럼 자연어 질문을 던지는 사용자가 AI 답변을 훨씬 더 자주 보게 됩니다. 이는 AI Overview가 단순히 일부 정보성 질의에 붙는 부가 기능이 아니라, 질문형 탐색의 기본 인터페이스가 되고 있다는 뜻입니다.
Google의 1월 발표도 같은 방향을 가리킵니다. Google은 Search가 사용자의 길고 복잡한 질문을 더 잘 이해하고, AI Overview에서 바로 follow-up 질문을 던져 AI Mode 대화로 넘어가게 한다고 설명했습니다. 즉 검색의 흐름은 "링크 목록을 보고 사용자가 판단한다"에서 "AI가 먼저 요약하고 사용자가 이어 묻는다"로 바뀌고 있습니다.
문제는 이 흐름이 사용자에게는 자연스럽지만, 검증 책임을 흐리게 만든다는 점입니다. 기존 검색 결과에서는 사용자가 링크 제목, 출처, 순위, 스니펫을 보고 어디를 열지 결정했습니다. AI Overview에서는 먼저 요약된 결론을 읽고, 출처는 그 결론을 보조하는 증거처럼 보입니다. 사용자는 링크를 열지 않고도 답을 얻었다고 느낄 수 있습니다. 이때 출처 카드는 실제 검증의 끝이 아니라, 검증이 끝난 것처럼 보이게 하는 인터페이스가 될 위험이 있습니다.
첫 페이지 밖 출처 29.8%가 말하는 것
논문의 두 번째 흥미로운 결과는 출처 선택입니다. 연구진은 AI Overview가 인용한 도메인과 같은 검색의 첫 페이지 일반 결과를 비교했습니다. 결론은 이중적입니다. 한편으로 AI Overview 인용 도메인은 일반 첫 페이지 결과보다 평균적으로 더 높은 신뢰도 점수를 보였습니다. 이는 "AI Overview가 무작위 저품질 페이지를 끌어온다"는 단순한 비판과는 다릅니다.
하지만 동시에 AI Overview가 인용한 도메인의 29.8%는 같은 검색의 첫 페이지 결과에 나타나지 않았습니다. 이 수치가 중요합니다. Google은 AI Overviews를 Search의 기존 정보 시스템과 결합된 생성 요약으로 설명하지만, 실제 인용 풀은 사용자가 스크롤해서 마주칠 첫 페이지 결과와 꽤 다를 수 있습니다. 같은 검색어에 대해 "랭킹으로 보여주는 웹"과 "AI 답변이 근거로 쓰는 웹"이 분리되는 셈입니다.
이 분리는 품질 문제와 별개로 투명성 문제입니다. 인용 출처가 더 신뢰할 만한 도메인일 수도 있습니다. 그러나 사용자는 왜 그 출처가 선택됐는지, 왜 첫 페이지에는 보이지 않는지, 그 선택이 검색 랭킹과 어떤 관계인지 알기 어렵습니다. AI 답변이 별도의 source selection layer를 갖는다면, SEO와 콘텐츠 전략의 기준도 바뀝니다. 첫 페이지에 오르는 것과 AI 답변에 인용되는 것은 같은 목표가 아닐 수 있습니다.
개발자 관점에서는 RAG 시스템 설계와 닮아 있습니다. 검색 랭킹, retrieval candidate, reranking, answer synthesis, citation rendering은 각각 다른 계층입니다. 최종 UI에서 링크가 보인다고 해서 retrieval과 랭킹의 정책이 투명해지는 것은 아닙니다. 오히려 링크가 많을수록 사용자는 "근거가 충분하다"고 느끼기 쉽지만, 실제로는 어떤 근거가 어떤 문장을 지탱하는지 더 세밀하게 봐야 합니다.
98,020개 주장 중 11%는 출처로 충분하지 않았습니다
가장 직접적인 수치는 claim fidelity입니다. 연구진은 7,583개 AI Overview에서 답변을 원자 주장으로 분해했고, 그중 7,491개 검증 가능 AI Overview에서 98,020개 주장을 평가했습니다. 분류는 clear, vague, ambiguous, incorrect, omitted입니다. clear와 vague를 일관된 주장으로 묶으면 89.0%가 consistent입니다. 반대로 ambiguous, incorrect, omitted를 묶으면 11.0%가 inconsistent입니다.
이 11%는 "AI가 11% 틀렸다"와 같은 단순한 문장으로 줄이면 안 됩니다. 세부 구성을 보면 2.7%는 인용 내용과 직접 충돌하는 incorrect, 1.4%는 ambiguous, 7.0%는 omitted입니다. 특히 omitted가 큽니다. 즉 많은 문제는 인용 출처가 반대 사실을 말해서가 아니라, AI 답변의 특정 주장을 인용 페이지에서 찾을 수 없어서 생깁니다. 사용자는 출처 링크를 보지만, 그 링크가 해당 문장을 실제로 말해주지 않을 수 있습니다.
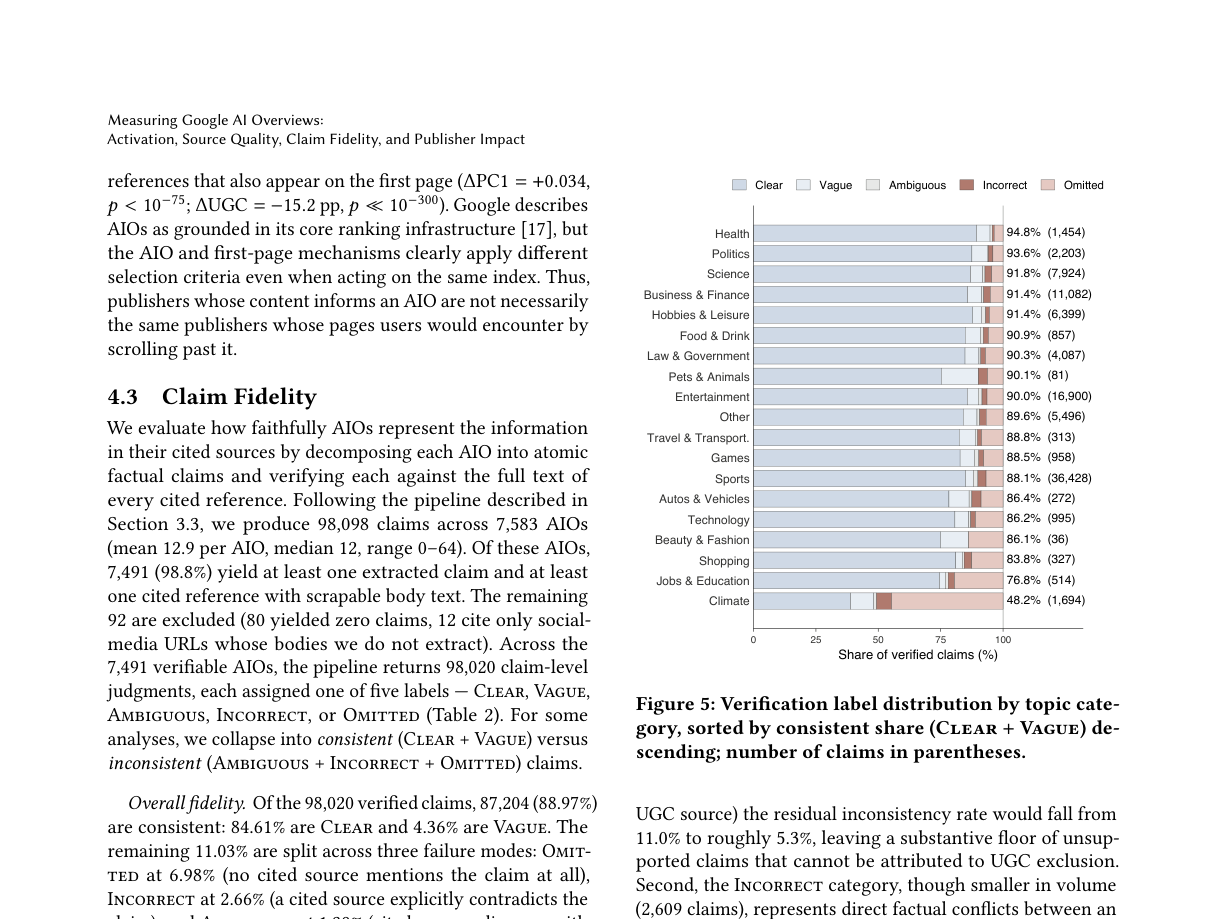
논문은 주제별 차이도 보여줍니다. Health와 Politics는 consistent share가 높게 나왔고, Jobs and Education, Climate는 낮게 나왔습니다. 연구진은 Climate의 낮은 비율을 측정 artifact 가능성과 함께 조심스럽게 다룹니다. 이 점은 중요합니다. AI 검색 측정은 결과 하나를 캡처해 "맞다/틀리다"로 끝내기 어렵습니다. 검색 결과는 시간, 위치, 계정 상태, query phrasing, UI 실험, 크롤러 탐지에 따라 달라집니다. 연구진도 fresh browser profile, AWS Lambda, CAPTCHA 재시도, randomized typing 같은 장치를 썼지만, 완전한 실사용자 대표성은 주장하지 않습니다.
그럼에도 이번 수치는 AI 답변 제품이 피하기 어려운 기준선을 제시합니다. 출처를 보여주는 제품이라면 "출처가 존재한다"가 아니라 "각 주장과 출처가 매핑된다"를 증명해야 합니다. 개발자가 사내 검색, 문서 Q&A, 고객지원 에이전트, 법무·의료·금융 RAG를 만들 때도 같은 문제를 만납니다. citation UI는 신뢰를 만드는 장치이지만, claim-level grounding이 없으면 신뢰의 외형만 만들 수 있습니다.
Google의 링크 강화와 논문의 긴장
흥미로운 타이밍도 있습니다. Google은 5월 6일 공식 블로그에서 AI Mode와 AI Overviews에 더 많은 링크를 직접 붙이고, 뉴스 구독 링크를 강조하고, public discussion과 social source preview를 보여주며, 데스크톱에서 inline link hover preview를 제공하겠다고 발표했습니다. 글의 핵심 메시지는 명확합니다. AI 검색이 웹과 끊기는 것이 아니라, 더 좋은 링크 경험을 통해 사용자를 원출처로 연결한다는 것입니다.
이번 논문은 바로 그 주장에 측정 가능한 질문을 붙입니다. 링크가 더 많아졌는가보다 중요한 것은 링크가 어떤 역할을 하느냐입니다. 링크가 "추가 탐색의 입구"인지, "이미 생성된 답변의 근거처럼 보이는 장식"인지, "광고 기반 웹의 수익 흐름을 보존하는 통로"인지는 서로 다른 문제입니다. Google은 링크 가시성을 높이겠다고 말하지만, 연구진은 AI Overview 인용 페이지 중 최소 50.6%가 display advertising을 포함한다고 보고합니다.
이 수치는 퍼블리셔에게 예민합니다. AI Overview가 사용자의 클릭을 줄이면 인용된 페이지는 콘텐츠를 제공하고도 광고 노출을 잃을 수 있습니다. 반면 같은 검색 결과 페이지에서 Google의 sponsored ads는 계속 노출될 수 있습니다. 논문은 일부 경우 Google 광고가 AI Overview 위에 나타난다고도 지적합니다. 즉 AI 답변층은 퍼블리셔의 콘텐츠를 근거로 삼으면서, 클릭 이전 단계에서 사용자의 주의를 붙잡고, 플랫폼 광고 수익은 유지하는 구조가 될 수 있습니다.
물론 이 논문 하나만으로 AI Overviews가 전체 웹 트래픽에 얼마만큼의 인과적 피해를 줬다고 단정할 수는 없습니다. 연구진도 clickstream 데이터를 직접 측정한 것은 아닙니다. 하지만 "AI 답변이 출처를 인용한다면 퍼블리셔도 이익을 본다"는 단순 논리는 흔들립니다. 인용과 방문은 다릅니다. visibility와 revenue도 다릅니다. AI 검색 시대의 퍼블리셔 문제는 이제 rank tracking보다 citation tracking, answer share, click-through attribution, subscription linking 같은 복합 문제로 바뀌고 있습니다.
커뮤니티 논쟁은 이미 출처의 성격으로 옮겨갔습니다
이번 arXiv 논문 자체가 아직 Hacker News나 GeekNews에서 큰 독립 토론을 만든 흔적은 제한적입니다. 하지만 같은 축의 논쟁은 이미 있습니다. GeekNews에는 올해 초 "건강 검색 시 Google AI Overviews가 의료 사이트보다 YouTube를 더 많이 인용한다"는 연구 보도가 소개됐고, 댓글은 꽤 선명하게 갈렸습니다. 한쪽은 AI 답변이 AI 생성 영상이나 검증이 약한 영상으로 연결되면 현실 왜곡의 순환이 생길 수 있다고 봤습니다. 다른 쪽은 YouTube에도 병원, 의사, 공공기관 채널이 있고, 플랫폼 단위 비판은 지나치게 거칠다고 반박했습니다.
이 논쟁은 이번 논문과 잘 맞닿아 있습니다. 출처 품질은 도메인 이름만으로 끝나지 않습니다. YouTube라는 도메인은 동시에 대학 강의, 병원 설명 영상, 개인 경험담, SEO성 콘텐츠, AI 생성 영상의 집합입니다. Reddit도 마찬가지입니다. 공론장과 경험담은 어떤 질문에는 귀중하지만, 어떤 질문에는 위험합니다. Google이 5월 6일 발표에서 public online discussions와 social media preview를 AI 답변에 더 넣겠다고 한 만큼, 출처의 "형식"과 "주장 지지력"을 나눠 보는 일이 더 중요해집니다.
AI 제품을 만드는 팀에게도 같은 교훈이 있습니다. 내부 문서 검색에서는 Confluence 페이지 하나가 출처일 수 있지만, 그 페이지 안에도 오래된 정책, 최신 결정, 댓글, 초안이 섞입니다. 코드 에이전트에서는 GitHub issue가 출처일 수 있지만, issue 본문과 최신 댓글의 상태가 다를 수 있습니다. 출처가 있다는 사실보다 더 중요한 것은 그 출처의 어느 조각이 어떤 주장에 연결되는지입니다.
AI 검색의 새 기준은 claim-level provenance입니다
이번 논문의 가장 실무적인 의미는 claim-level provenance입니다. 검색과 RAG 제품은 지금까지 "답변 아래에 링크를 달았다"는 수준에서 신뢰 UI를 마무리하는 경우가 많았습니다. 그러나 AI Overview처럼 대규모 기본 인터페이스가 되면 이 기준은 부족합니다. 답변의 문장마다 근거가 있어야 하고, 근거가 없으면 없는 것으로 표시해야 하며, 출처가 충돌하면 충돌을 드러내야 합니다.
| 계층 | 사용자가 보는 것 | 실제로 검증할 것 |
|---|---|---|
| 검색 랭킹 | 첫 페이지 링크와 스니펫 | AI 답변 인용 풀이 랭킹 결과와 얼마나 겹치는지 |
| 답변 생성 | 요약된 결론과 문단 | 각 문장이 인용된 텍스트에서 직접 지지되는지 |
| 출처 카드 | 링크, 도메인, 미리보기 | 도메인 신뢰도와 claim fidelity가 독립적으로 관리되는지 |
| 경제 효과 | 답변 안의 출처 노출 | 노출이 실제 방문, 광고 노출, 구독 전환으로 이어지는지 |
이 기준은 Google만의 문제가 아닙니다. Perplexity, ChatGPT Search, Microsoft Copilot Search, 기업용 지식 검색, 고객지원 챗봇, 개발자 문서 에이전트 모두 같은 압력을 받습니다. 답변형 인터페이스는 사용자의 시간을 줄여주지만, 동시에 사용자가 원문을 읽으며 수행하던 검증 노동도 흡수합니다. 그 노동을 시스템이 대신하지 못하면, 시간 절약은 신뢰 비용으로 바뀝니다.
제품 설계 관점에서 몇 가지 질문이 남습니다. 첫째, 답변 UI는 모든 출처를 같은 무게로 보여줘도 되는가. 둘째, 인용된 출처가 주장을 직접 지지하지 않을 때 시스템은 침묵해야 하는가, 아니면 "근거 부족"을 표시해야 하는가. 셋째, AI 답변이 클릭을 줄이는 경우 콘텐츠 제공자에게 어떤 피드백 루프를 제공해야 하는가. 넷째, 사용자가 질문형 검색을 할수록 AI 답변에 더 많이 노출된다면, 초보 사용자와 고위험 주제에 더 보수적인 정책이 필요한가.
결론
이번 논문은 AI Overviews가 무가치하거나 위험하다고 단정하지 않습니다. 오히려 더 미묘한 결론을 보여줍니다. Google AI Overviews는 질문형 검색에서 강하게 작동하고, 평균적으로 더 신뢰도 높은 출처를 고르는 경향도 있습니다. 하지만 같은 검색의 첫 페이지 결과와 다른 출처 풀을 쓰고, 98,020개 주장 중 11.0%는 인용 페이지로 충분히 지지되지 않았으며, 인용된 퍼블리셔의 광고 경제와 Google의 검색 광고 경제가 충돌할 수 있습니다.
그래서 핵심은 "AI 검색이 틀린다"가 아닙니다. 핵심은 검색의 신뢰 구조가 바뀌었다는 점입니다. 링크 목록의 시대에는 사용자가 여러 출처를 열고 비교했습니다. AI Overview의 시대에는 시스템이 먼저 답을 쓰고, 출처는 그 답의 보증서처럼 붙습니다. 그 보증서가 실제로 어떤 문장까지 보증하는지 측정하는 일이 앞으로의 검색 품질, RAG 품질, 퍼블리셔 경제를 가르는 기준이 됩니다.
Google은 5월 6일 공식 블로그에서 AI 검색 안의 링크를 더 풍부하게 만들겠다고 했습니다. 좋은 방향입니다. 하지만 링크의 수와 위치만으로는 충분하지 않습니다. 이제 필요한 것은 링크가 아니라 주장 단위의 출처성입니다. AI 검색의 다음 경쟁력은 더 그럴듯한 답변이 아니라, 사용자가 "이 문장은 무엇으로 뒷받침되는가"를 끝까지 따라갈 수 있는 구조일 가능성이 큽니다.