MCP가 휴대폰 안으로, 로컬 에이전트의 새 실행 경계
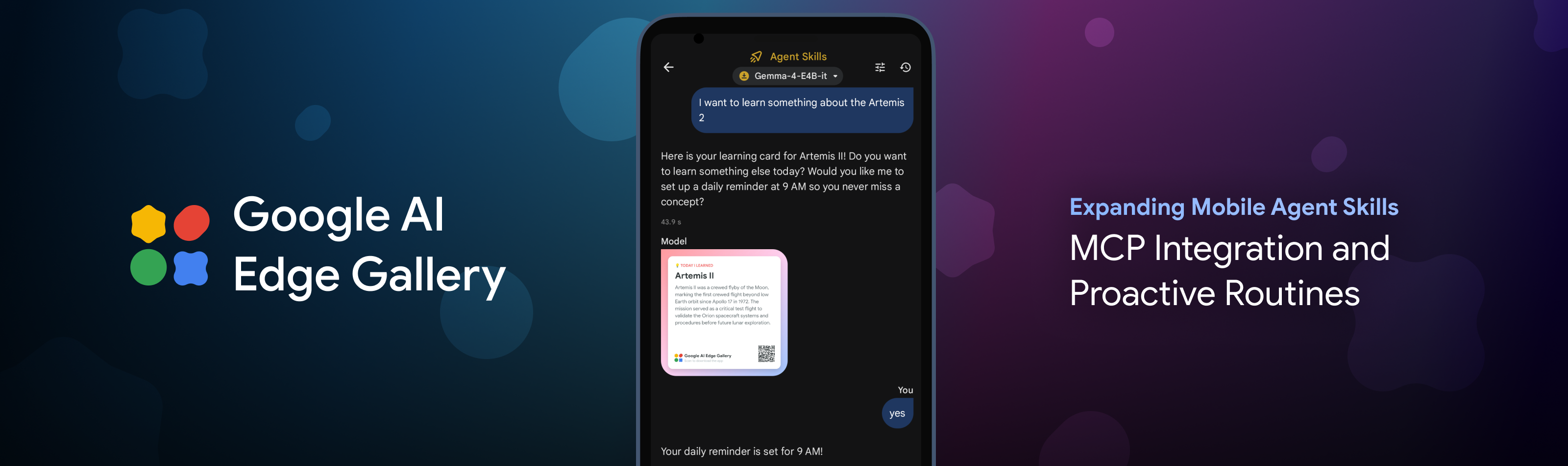
Google AI Edge Gallery는 Gemma 4 온디바이스 에이전트에 MCP, 알림, 세션 지속성을 붙인 모바일 실행 실험입니다.

- 무슨 일: Google AI Edge Gallery가
MCP, 로컬 알림, 지속 채팅 기록을 지원합니다.- Android 앱의 실험 기능으로 시작하며, iOS 업데이트는 이후 제공될 예정입니다.
- 구조: Gemma 4가 휴대폰에서 reasoning과 tool 선택을 하고, MCP 서버가 실제 데이터를 가져옵니다.
- 숫자: LiteRT-LM fast prefill로 현대 phone GPU에서 3,000 tokens/sec+ 복원이 가능하다고 설명했습니다.
- 주의점: 공식 GitHub 문서는
4k-10kcontext, 짧은 tool description, Gemma-4-E4B 권장을 명시합니다.
Google이 2026년 5월 19일 Google AI Edge Gallery 업데이트를 발표했습니다. 표면적으로는 쇼케이스 앱의 기능 추가처럼 보입니다. MCP를 붙였고, 알림 리마인더를 만들 수 있고, 채팅 기록을 이어갈 수 있다는 내용입니다. 하지만 이 조합은 온디바이스 AI가 어디로 가는지 꽤 선명하게 보여줍니다. 휴대폰 안의 작은 모델이 더 이상 "오프라인 챗봇"에 머물지 않고, 외부 도구를 호출하고, 정해진 시간에 사용자를 다시 부르고, 이전 세션을 복원하는 에이전트 런타임 실험으로 이동하고 있습니다.
Google AI Edge Gallery는 Gemma와 다른 오픈 모델을 Android와 iOS 기기에서 직접 실행해 보는 앱입니다. Google은 지난달 Gemma 4를 이용해 모바일 기기에서 agentic workflow를 배포하는 기능을 소개했고, 이번에는 그 위에 연결성과 지속성을 붙였습니다. 발표문은 세 가지를 한꺼번에 말합니다. 첫째, Android 앱에서 MCP over Streamable HTTP를 실험 기능으로 지원합니다. 둘째, local notification reminders로 사용자가 지정한 루틴을 다시 열 수 있습니다. 셋째, LiteRT-LM backend의 fast prefill을 활용해 persistent chat history를 복원합니다.
이 뉴스의 핵심은 "MCP가 또 하나의 앱에 붙었다"가 아닙니다. MCP는 이미 데스크톱 코딩 에이전트, IDE, 클라우드 에이전트, 브라우저 도구에서 빠르게 퍼졌습니다. 이번 업데이트가 다른 이유는 실행 위치입니다. reasoning과 tool 선택은 휴대폰에서 일어납니다. 실제 calendar, maps, web fetch 같은 작업은 외부 MCP 서버가 맡을 수 있습니다. 다시 말해 모바일 로컬 모델이 프라이버시와 낮은 지연시간을 가져가되, 필요한 순간에는 네트워크 너머 도구를 빌리는 구조입니다.
로컬 모델은 혼자서는 세상을 모릅니다
온디바이스 LLM의 장점은 분명합니다. 입력이 기기 밖으로 나가지 않아도 되고, 작은 작업은 빠르게 처리할 수 있으며, 네트워크가 약해도 어느 정도 동작합니다. 모바일 앱에서 서버 왕복 없이 텍스트를 정리하거나, 사진과 메모를 분류하거나, 사용자의 반복 루틴을 도와주는 경험은 매력적입니다. 최근 LiteRT-LM, Gemma 4 MTP, WebGPU 로컬 추론 같은 발표가 계속 나오는 것도 이 이유입니다. 모델이 충분히 작아지고 runtime이 빨라지면, 일부 AI 기능은 클라우드 API가 아니라 사용자의 기기 안에서 돌아갈 수 있습니다.
하지만 로컬 모델에는 큰 약점도 있습니다. 혼자서는 최신 정보와 외부 상태를 모릅니다. 사용자의 calendar를 읽으려면 calendar 도구가 필요하고, 주변 식당이나 이동 시간을 알려면 maps 도구가 필요합니다. URL을 요약하려면 web fetch 도구가 필요합니다. 서버 대형 모델은 넓은 context, 강한 tool calling, 클라우드 인증 흐름을 묶어 이 문제를 해결해 왔습니다. 휴대폰 안의 작은 모델은 이 모든 것을 한 번에 품기 어렵습니다.
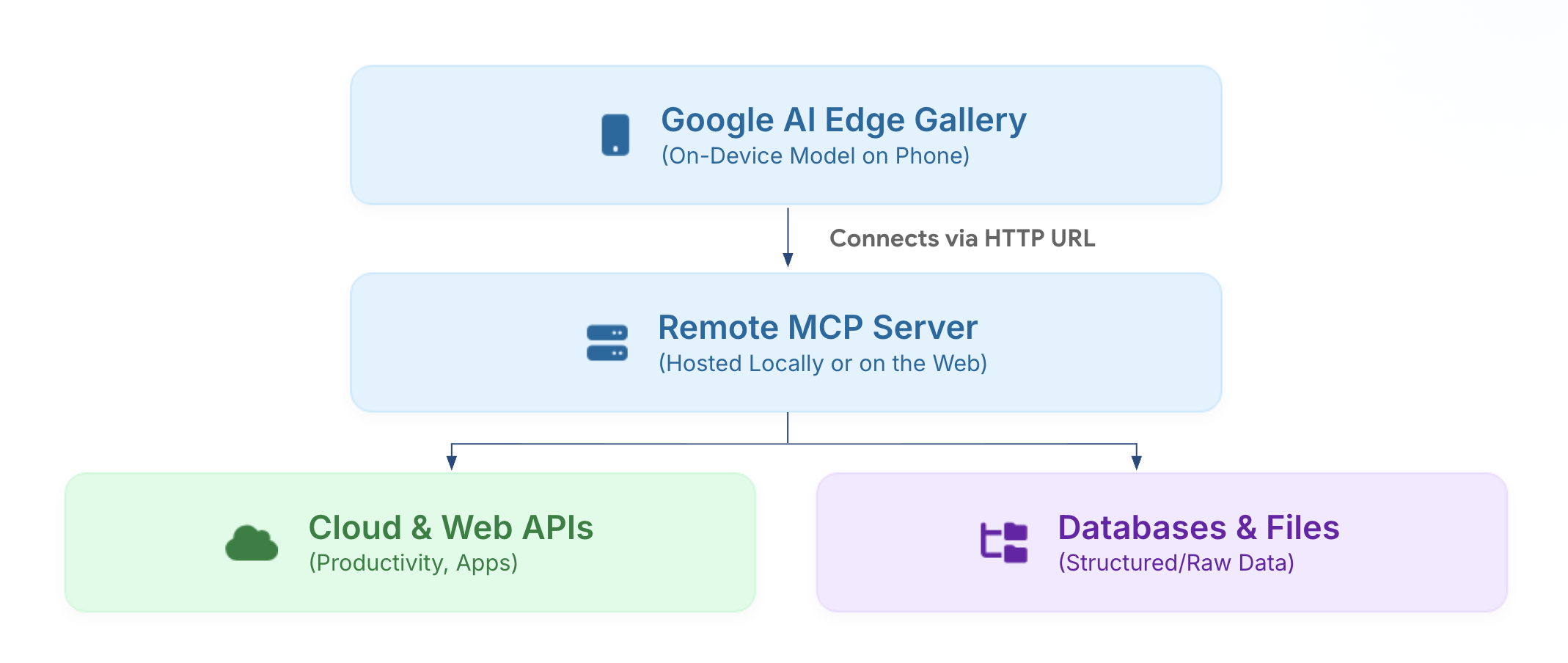
Google의 이번 답은 MCP입니다. 발표문은 Google AI Edge Gallery가 Android 앱에서 open-source Model Context Protocol을 Streamable HTTP로 지원한다고 설명합니다. 사용자가 앱에 유효한 MCP URL을 등록하면, 앱은 tool definitions와 resource schemas를 동적으로 가져와 온디바이스 모델의 system prompt에 넣습니다. 사용자가 질문하면 Gemma 4가 어떤 도구가 필요한지 휴대폰에서 판단하고 tool call을 생성합니다. 실제 요청은 MCP 서버가 실행합니다. 그 서버는 집 컴퓨터일 수도 있고, 보안된 클라우드 endpoint일 수도 있습니다.
이 구조는 로컬 AI의 강점과 약점을 동시에 인정합니다. 모델의 판단은 기기 안에 두지만, 세상과 연결되는 통로는 표준화된 도구 서버로 분리합니다. 개발자 입장에서는 흥미로운 절충입니다. 완전 오프라인 AI는 기능이 너무 좁고, 완전 클라우드 AI는 비용과 데이터 이동이 부담됩니다. AI Edge Gallery의 MCP 통합은 그 사이에 있는 "로컬 reasoning, 원격 tool execution" 패턴을 모바일 앱에서 보여줍니다.
MCP가 데스크톱에서 모바일로 내려올 때 생기는 차이
데스크톱 MCP를 그대로 생각하면 오해가 생깁니다. Claude Code, Codex, Gemini CLI 같은 도구에서 MCP 서버는 대개 같은 컴퓨터에서 stdio로 붙습니다. 로컬 파일, GitHub, database, 브라우저, 터미널과 연결됩니다. AI 클라이언트와 MCP 서버가 같은 개발 환경 안에 있으니 설치와 권한 모델도 비교적 단순합니다. 반면 휴대폰 앱은 다릅니다. 모바일 앱은 stdio MCP 서버를 옆에 띄워둘 수 없습니다. 네트워크로 접근 가능한 endpoint가 필요합니다.
공식 GitHub 문서는 이 차이를 아주 실무적으로 설명합니다. 대부분의 오픈소스 MCP 서버는 stdio transport를 전제로 만들어졌지만, 모바일 앱에서는 그것이 그대로 작동하지 않습니다. 그래서 예시는 mcp-server-fetch를 supergateway로 감싸 Streamable HTTP로 노출하고, 필요하면 Cloudflare Quick Tunnels로 외부에서 접근 가능한 HTTPS URL을 만든 뒤 앱에 /mcp endpoint를 등록하는 흐름을 보여줍니다.
# fetch MCP 서버를 설치한 뒤 Streamable HTTP로 감쌉니다.
python3 -m venv venv
source venv/bin/activate
pip install mcp-server-fetch
npx -y supergateway --stdio 'mcp-server-fetch' --outputTransport streamableHttp
이 예시는 간단해 보이지만, 모바일 에이전트의 현실을 잘 드러냅니다. 휴대폰 안의 모델이 tool call을 하려면, 도구 서버는 휴대폰에서 접근 가능한 네트워크 표면이 되어야 합니다. 사내 데이터, 개인 PC, 홈 서버, 클라우드 API, Google Maps MCP처럼 성격이 다른 endpoint가 섞입니다. 인증도 달라집니다. GitHub 문서는 cloud MCP 서버가 공개 endpoint로 노출되므로 명시적 authorization이 필요하다고 적고, Maps Grounding Lite 예시에서는 X-Goog-Api-Key header를 직접 넣는 방식을 보여줍니다. 동시에 full OAuth flow는 아직 작업 중이라고 말합니다.
여기서 개발자의 질문은 "연결이 되나"에서 끝나지 않습니다. 어떤 MCP 도구를 켜둘 것인가, tool description을 얼마나 짧게 쓸 것인가, 사용자가 매번 승인해야 하는가, 항상 허용해도 되는 도구는 무엇인가, API key는 어디에 저장되는가, 휴대폰을 잃어버렸을 때 MCP auth state는 어떻게 폐기되는가 같은 질문이 따라옵니다. Google이 AI Edge Gallery를 제품이 아니라 gallery와 playground로 포지셔닝하는 이유도 여기에 있습니다. 아직 정답을 제시했다기보다, 모바일 에이전트 앱이 마주칠 문제를 개발자가 실험할 수 있게 만든 쪽에 가깝습니다.
작은 context window가 설계를 바꿉니다
Google은 발표문에서 온디바이스 모델의 context window가 서버 대형 모델보다 작으므로 MCP tool descriptions를 짧게 유지하고, 반환 데이터도 bite-sized snippets로 보내는 편이 낫다고 권합니다. GitHub 문서는 더 구체적입니다. Google AI Edge Gallery 모델은 4k-10k tokens의 더 빡빡한 context 안에서 작동하고, 많은 공식 MCP 서버는 32k에서 200k+ tokens를 가진 데스크톱 애플리케이션을 전제로 설계됐다고 설명합니다.
이 차이는 사소하지 않습니다. 데스크톱의 강한 모델에는 도구 스키마를 넉넉히 넣고, 긴 문서나 JSON을 돌려줘도 어느 정도 버틸 수 있습니다. 모바일 로컬 모델은 그렇지 않습니다. tool schema가 길면 system prompt만으로 context가 대부분 차고, 응답 데이터가 길면 사용자의 실제 요청과 이전 대화가 밀려납니다. MCP가 표준이라고 해서 모든 tool surface가 같은 모델에 같은 방식으로 맞는 것은 아닙니다.
그래서 모바일 MCP 앱의 설계 원칙은 데스크톱과 달라질 가능성이 큽니다. 도구는 적게 켜고, description은 짧게 쓰고, 결과는 요약해서 돌려주고, 사용자가 지금 하려는 작업에 필요한 tool만 활성화하는 방식입니다. GitHub 문서도 특정 task에 필요한 tool만 enable하는 것을 권합니다. 모델 호환성도 제한입니다. 문서는 Gemma-4-E4B가 tool calling에서 가장 안정적이며, 더 작은 모델은 schema parsing에 어려움을 겪을 수 있다고 적습니다.
이 지점이 이번 뉴스의 가장 현실적인 부분입니다. 온디바이스 AI는 "프라이버시가 좋다"는 한 문장으로 끝나지 않습니다. 작은 context, 모바일 GPU의 수치 정확도, 배터리, 발열, 네트워크 endpoint, 인증 저장, permission UX가 모두 제품 설계의 일부가 됩니다. 서버 LLM을 줄여서 휴대폰에 넣는다고 같은 에이전트 경험이 자동으로 나오지 않습니다. 모바일 에이전트에는 모바일다운 tool surface가 필요합니다.
| 항목 | 데스크톱 MCP | 모바일 온디바이스 MCP |
|---|---|---|
| transport | stdio 또는 local process 중심 | Streamable HTTP endpoint 필요 |
| context | 32k-200k+ tokens 전제 도구가 많음 | 4k-10k tokens 안에서 tool schema를 절약해야 함 |
| 승인 | 개발 환경 권한과 CLI 설정에 묶임 | per-call prompt와 always allow가 UX 핵심 |
| 장점 | 강한 모델, 넓은 도구, 풍부한 context | 낮은 지연시간, 기기 내 reasoning, 개인 루틴과 가까움 |
알림은 작은 기능이 아니라 에이전트의 시간 감각입니다
이번 업데이트에서 MCP만큼 중요한 기능은 Schedule Notification skill입니다. Google은 지금까지 앱의 AI 상호작용이 사용자가 앱을 열고 prompt를 입력하는 reactive 방식이었다고 말합니다. 알림 skill은 이 흐름을 바꿉니다. 사용자가 "매일 밤 10시에 기분을 기록하라고 알려줘"라고 말하면 앱은 로컬 알림을 예약합니다. 사용자가 알림을 탭하면 AI Edge Gallery가 바로 필요한 도구와 함께 열리고, Gemma 4 세션이 이어집니다.
이 기능은 단순한 reminder처럼 보입니다. 하지만 에이전트 관점에서는 시간 감각의 시작입니다. 챗봇은 사용자가 부를 때만 대답합니다. 에이전트는 특정 시점에 다시 나타나야 하고, 맥락을 기억해야 하며, 사용자가 승인한 범위 안에서 루틴을 이어가야 합니다. Google의 예시는 mood tracking, 매일 새로운 개념 학습, 아침 calendar briefing입니다. 모두 "사용자가 다시 앱을 열어야만 시작되는 대화"보다 한 단계 능동적입니다.
물론 여기에도 경계가 있습니다. 로컬 알림은 자동 실행이 아니라 사용자를 다시 세션으로 초대하는 장치입니다. 알림을 탭하면 앱이 열리고 모델이 준비되는 구조이지, 사용자의 확인 없이 모든 일을 백그라운드에서 처리한다는 의미는 아닙니다. 이 차이는 중요합니다. 모바일 OS는 배터리와 프라이버시 때문에 백그라운드 실행에 강한 제약을 둡니다. 에이전트가 "항상 실행되는 비서"가 되려면 OS 권한, 알림 정책, 사용자 신뢰를 통과해야 합니다. AI Edge Gallery는 그 중간 단계로 보입니다. 완전 자율 실행보다는 사용자가 허용한 루틴을 알림으로 복원하는 방식입니다.
세션 지속성도 같은 맥락입니다. Google은 persistent chat history를 추가해 text, image, audio input 상태를 유지한 채 세션을 재개할 수 있다고 설명합니다. LiteRT-LM backend의 fast prefill 덕분에 현대 phone GPU에서는 prefill speed가 3,000 tokens/sec를 넘을 수 있어 긴 session context를 거의 즉시 복원할 수 있다는 설명도 붙었습니다. 이 수치는 로컬 에이전트 UX에서 중요합니다. 사용자가 알림을 탭했는데 모델이 이전 대화를 되살리는 데 오래 걸리면 루틴 경험은 금방 무너집니다.
커뮤니티가 보는 기대와 불안
커뮤니티 반응은 꽤 실용적입니다. Reddit LocalLLaMA에는 AI Edge Gallery v1.0.13/v1.0.14 업데이트를 정리한 글이 올라왔고, MCP support, Pixel TPU support, speculative decoding, calendar skills, scheduled notifications, persistent chat history가 함께 언급됐습니다. 로컬 모델이 휴대폰에서 외부 도구를 호출하는 흐름에 관심이 컸습니다. 동시에 어떤 데이터가 로컬 DataStore에 저장되는지, OAuth token이나 MCP server auth data가 어떻게 관리되는지 분석하려는 반응도 보였습니다.
이 균형이 맞습니다. 온디바이스 AI는 무조건 안전하다는 보증이 아닙니다. 모델 추론이 기기 안에서 일어나도, tool call은 외부 서버로 나갈 수 있습니다. MCP URL과 API key를 앱에 등록하면 그 자체가 민감한 설정이 됩니다. chat history가 로컬에 남는 것은 클라우드 전송을 줄이는 장점이 있지만, 기기 분실이나 백업 정책에서는 별도 위험이 됩니다. permission prompt와 "always allow" 토글은 편의와 통제 사이의 결정입니다.
개발자가 이 업데이트에서 배울 점은 분명합니다. 모바일 에이전트는 모델 하나로 완성되지 않습니다. 필요한 것은 네 가지입니다. 첫째, 작은 모델이 다룰 수 있는 짧고 안정적인 tool schema입니다. 둘째, 사용자가 이해할 수 있는 permission UX입니다. 셋째, 세션을 빠르게 복원하는 runtime입니다. 넷째, 알림과 루틴을 OS 정책 안에서 다루는 제품 설계입니다. Google AI Edge Gallery는 이 네 가지를 한 앱에 실험적으로 모아 놓았습니다.
로컬 에이전트 경쟁의 다음 질문
AI Edge Gallery 업데이트는 Google의 큰 I/O 2026 흐름 안에 있습니다. 같은 행사에서 Google은 Gemini 3.5, Antigravity, Managed Agents, Android AI Studio, LiteRT-LM, Chrome의 WebMCP와 DevTools for agents까지 한꺼번에 발표했습니다. 표면은 다르지만 방향은 비슷합니다. 모델이 혼자 답하는 시대에서, 모델이 도구와 런타임과 플랫폼 권한을 통해 행동하는 시대로 이동하고 있습니다.
그중 AI Edge Gallery가 맡은 위치는 작지만 중요합니다. 클라우드 에이전트는 강력하지만 항상 서버와 계정, 비용, 네트워크를 전제로 합니다. 데스크톱 에이전트는 개발자 작업에는 강하지만 일상 루틴과 모바일 센서, 개인 알림과는 거리가 있습니다. 모바일 온디바이스 에이전트는 반대로 사용자의 가장 가까운 기기에 있습니다. 하지만 context와 성능은 작고, 권한은 민감하며, tool execution은 복잡합니다.
그래서 이번 발표를 "Google이 휴대폰에서 MCP를 지원했다" 정도로만 보면 아깝습니다. 더 큰 질문은 이것입니다. 로컬 AI 앱은 어디까지 혼자 판단하고, 어디서 외부 서버를 불러야 하며, 어떤 순간에 사용자 승인을 받아야 할까요. 알림과 세션 기록은 편의를 위해 얼마나 오래 남겨야 할까요. 작은 모델이 긴 tool schema를 감당하지 못할 때, 도구 설계는 어떻게 바뀌어야 할까요.
Google AI Edge Gallery는 아직 실험장입니다. 공식 문서도 MCP 통합이 experimental이라고 못박습니다. 그렇지만 실험장이기 때문에 더 관찰할 가치가 있습니다. 완성된 소비자 제품은 위험한 세부를 숨깁니다. 반면 gallery는 개발자가 직접 endpoint를 붙이고, tool을 켜고 끄고, prompt를 줄이고, permission을 확인하며 모바일 에이전트의 실제 병목을 볼 수 있게 합니다. 온디바이스 AI의 다음 경쟁은 모델을 휴대폰에 넣는 데서 끝나지 않습니다. 그 모델이 안전하게 도구를 부르고, 시간을 기억하고, 사용자가 다시 돌아왔을 때 곧바로 이어서 일할 수 있는 실행 경계를 만드는 쪽으로 이동하고 있습니다.