Glean ADLC, 에이전트 난립을 막는 7단계 운영 모델
Glean ADLC 발표는 기업 AI 에이전트 경쟁이 데모 수량에서 lifecycle, trace, access policy, ROI 측정으로 이동했음을 보여줍니다.
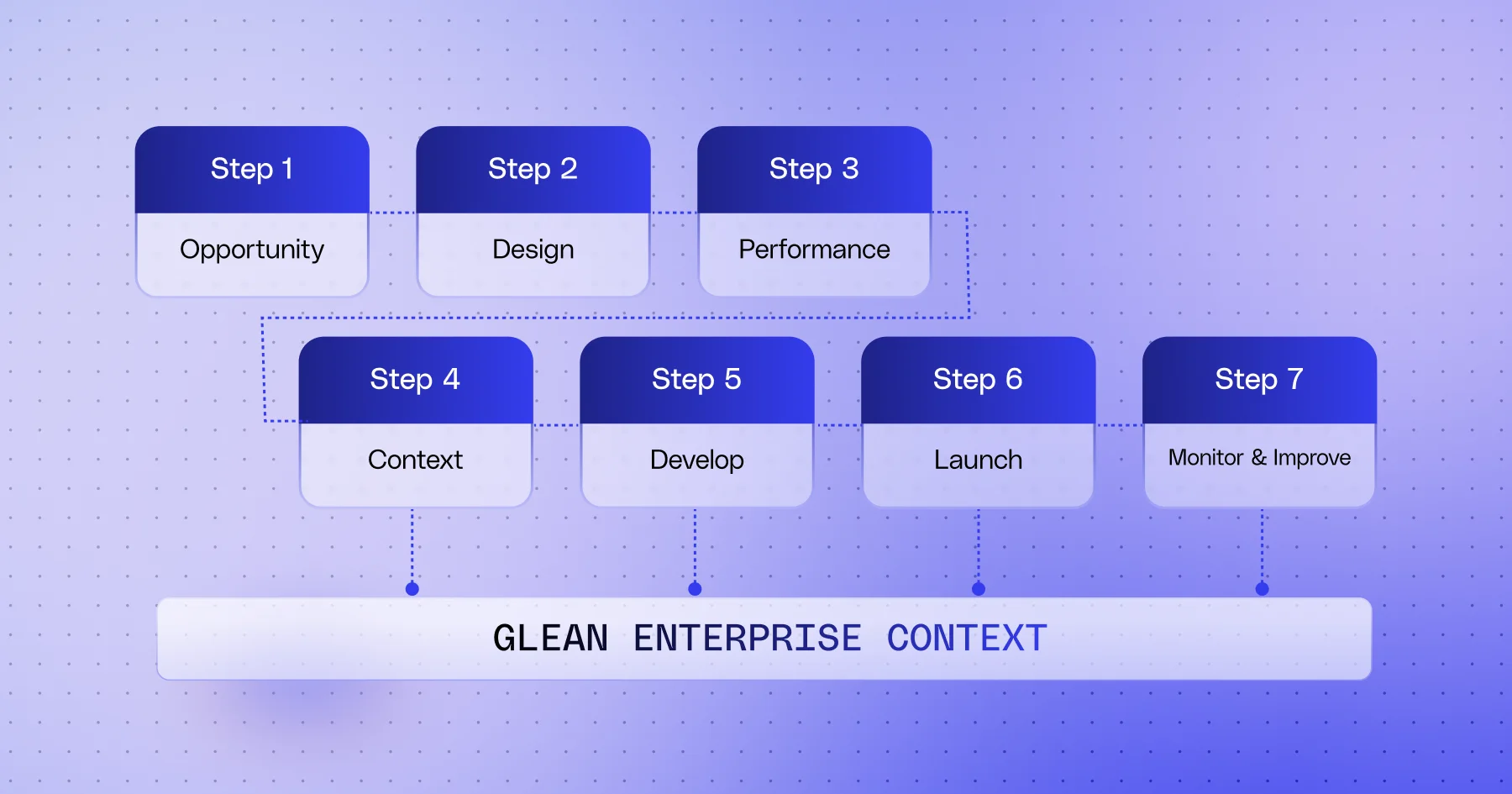
- 무슨 일: Glean이 기업용
Agent Development Lifecycle과 관련 플랫폼 기능을 발표했습니다.- 7단계 lifecycle은 Opportunity, Design, Performance, Context/Input, Develop, Launch, Monitor & Improve로 구성됩니다.
- 의미: 에이전트 경쟁의 중심이 모델 성능과 데모에서 운영, 추적, 정책, ROI로 이동하고 있습니다.
- 제품 신호: Auto Mode, Debug & Trace, Sub-Agents, Sandbox, Agent Library, Access Policies가 한 묶음으로 나왔습니다.
- Glean은 에이전트를 임시 자동화가 아니라 소프트웨어 시스템처럼 정의하고 배포하자는 쪽에 베팅합니다.
- 주의점: 공식 발표 중심의 초기 뉴스라 독립 커뮤니티 검증과 실제 ROI 재현성은 더 지켜봐야 합니다.
Glean이 2026년 5월 12일 Enterprise Agent Development Lifecycle, 줄여서 ADLC를 발표했습니다. 이름만 보면 또 하나의 기업 AI 프레임워크처럼 보입니다. 하지만 이번 발표가 흥미로운 이유는 Glean이 "더 똑똑한 에이전트"보다 "에이전트를 어떻게 운영할 것인가"를 전면에 내세웠기 때문입니다.
지난 몇 달 동안 기업 AI 시장의 문법은 빠르게 바뀌었습니다. 초기에는 각 회사가 "우리도 에이전트를 만들 수 있다"를 증명하는 데 집중했습니다. 자연어로 workflow를 만들고, SaaS 앱을 호출하고, 사내 문서를 읽고, 티켓을 처리하는 데모가 쏟아졌습니다. 그러나 에이전트가 실제 조직 안으로 들어가면 질문은 달라집니다. 누가 이 에이전트의 owner입니까? 어떤 데이터에 접근합니까? 실패하면 누가 알 수 있습니까? 사람의 승인이 필요한 순간은 어디입니까? 실제로 시간을 줄였는지, 아니면 자동화된 듯 보이는 또 다른 업무를 만든 것인지 어떻게 측정합니까?
Glean ADLC는 바로 이 질문에 대한 답으로 나왔습니다. Glean의 주장은 단순합니다. 에이전트는 소프트웨어입니다. 따라서 에이전트도 일반 소프트웨어처럼 문제 정의, 설계, 성능 기준, 컨텍스트, 개발, 출시, 모니터링과 개선의 주기를 가져야 합니다. 이 문장은 평범해 보이지만, 기업 AI 제품 시장에서는 꽤 중요한 전환입니다. AI 에이전트를 하나의 "마법 같은 assistant"가 아니라 운영되는 시스템으로 낮춰 보는 시선이기 때문입니다.
7단계가 말하는 진짜 변화
Glean이 제시한 ADLC는 7단계입니다. 보도자료에서는 Opportunity, Design, Performance, Input, Develop, Launch, Monitor & Improve라고 설명하고, 블로그에서는 Input 대신 Context라는 표현을 씁니다. 용어 차이는 있지만 핵심은 같습니다. 에이전트를 만들기 전에 먼저 어떤 비즈니스 문제를 풀지 정하고, 어떤 작업 단위를 맡길지 설계하고, 성공 기준을 숫자로 정하고, 필요한 데이터와 권한을 최소화한 뒤, 테스트하고, 제한적으로 출시하고, 운영 지표로 계속 개선하라는 것입니다.
이 흐름은 기존 소프트웨어 개발 생명주기와 비슷합니다. 차이는 에이전트가 확률적이고, 외부 도구를 호출하며, 조직 데이터와 권한을 직접 다룬다는 점입니다. 일반 앱은 잘못된 버튼을 보여줄 수 있습니다. 에이전트는 잘못된 버튼을 누를 수도 있습니다. 일반 검색 시스템은 오래된 문서를 보여줄 수 있습니다. 에이전트는 오래된 문서를 근거로 CRM을 업데이트하거나 고객에게 답변할 수 있습니다. 그래서 에이전트 lifecycle은 단순한 프로젝트 관리 양식이 아니라 권한과 관측성의 문제로 이어집니다.
Glean 블로그는 에이전트 프로젝트가 멈추는 이유를 모델 지능 부족보다 운영 모델 부재에서 찾습니다. 적절한 컨텍스트가 없고, integration이 agent마다 깨지고, 출시 뒤 성공 기준을 아무도 모르는 상황입니다. 이 진단은 최근 기업 AI 팀들이 겪는 문제와 잘 맞습니다. 많은 조직에서 AI 에이전트는 중앙 플랫폼보다 먼저 부서별 실험으로 퍼졌습니다. 영업팀은 CRM 요약 에이전트를 만들고, 지원팀은 티켓 분류 에이전트를 만들고, 엔지니어링팀은 코드 리뷰나 릴리스 노트 에이전트를 만듭니다. 처음에는 생산성이 올라가는 것처럼 보이지만, 시간이 지나면 비슷한 권한, 비슷한 데이터 connector, 비슷한 평가 지표가 중복됩니다.
이때 CIO가 원하는 것은 더 많은 데모가 아닙니다. 어떤 에이전트가 돈을 벌거나 비용을 줄이는지, 어떤 에이전트가 위험한 권한을 갖는지, 어떤 에이전트가 퇴역해야 하는지를 한눈에 보는 방식입니다. ADLC는 이 요구를 lifecycle 언어로 포장합니다. "에이전트를 몇 개 만들었나"에서 "각 에이전트가 어떤 단계에 있고 무엇을 증명했나"로 질문을 바꾸는 것입니다.
Glean이 같이 낸 제품 신호
Glean은 ADLC를 선언문으로만 내지 않았습니다. 같은 발표에서 플랫폼 기능을 여러 개 묶었습니다. Auto Mode Agent Builder는 사용자가 자연어로 원하는 일을 설명하면 agent가 기업 graph 위에서 계획하고 실행하는 방식입니다. Debug & Trace Views는 agent run의 input, tool call, LLM decision, output을 단계별로 보여줍니다. Sub-Agents는 하나의 거대한 agent 대신 재사용 가능한 전문 agent를 parent agent가 runtime에 호출하는 구조입니다. Expanded Agent Sandbox는 고객 VPC 안에서 안전한 파일 시스템과 코드 실행 환경을 제공합니다.
이 중 개발자와 플랫폼 팀이 가장 주목해야 할 것은 Debug & Trace입니다. 에이전트 실패는 전통적인 버그와 다릅니다. 코드가 항상 같은 입력에서 같은 출력을 내지 않을 수 있고, 실패 원인이 prompt, context, tool schema, permission, model routing, user instruction, 외부 SaaS 상태 중 어디에 있는지 바로 보이지 않습니다. 마지막 답변만 보고 고치려 하면 추측이 됩니다. Glean이 trace를 ADLC의 중심 기능으로 넣은 것은 에이전트 운영의 병목을 정확히 본 결정입니다.
Agent Library controls와 Agent Access Policies도 중요합니다. 에이전트가 많아지면 검색과 배포 자체가 문제가 됩니다. 누가 승인한 에이전트인지, 어느 부서용인지, 어떤 agent가 deprecated인지, 특정 사용자 그룹에게 보이면 안 되는 agent는 무엇인지 정해야 합니다. Glean은 verification badge, featured agents, departmental categories, soft-delete와 admin restore를 Agent Library에 넣고, 조직 단위 guardrail로 sensitive content blocking이나 system of record write restriction을 적용하겠다고 설명합니다.
이런 기능은 화려한 AI 데모와 거리가 있어 보일 수 있습니다. 그러나 실제 기업 도입에서는 이런 기능이 더 오래 살아남습니다. 사내 agent가 하나일 때는 Slack 채널에 링크 하나를 공유하면 됩니다. agent가 수십 개가 되면 카탈로그가 필요합니다. agent가 수백 개가 되면 owner, 정책, 접근 제어, 사용량, incident 대응이 필요합니다. agent가 업무 시스템에 쓰기 권한을 갖기 시작하면 "누가 만들었는지"보다 "누가 책임지는지"가 더 중요해집니다.
ROI 장부가 필요한 이유
Glean 발표에서 눈에 띄는 또 다른 부분은 ROI입니다. Glean은 ADLC가 고객의 agent adoption을 scale하는 데 쓰였고, Zillow, Ericsson, Motive 같은 고객이 주당 수백만 건의 agent run을 처리한다고 말합니다. 또한 Glean 내부 엔지니어링 팀의 단일 agent가 연간 17,000시간 이상, 170만 달러 이상 ROI를 회수했다고 주장합니다.
이 숫자는 강력한 마케팅 재료입니다. 동시에 조심해서 읽어야 합니다. hours saved와 ROI는 계산 방식에 따라 크게 달라집니다. 어떤 업무가 정말 사라졌는지, 사람이 검토하는 시간이 얼마나 남았는지, agent failure를 고치는 비용은 어디에 넣었는지, security review와 change management 비용은 어떻게 처리했는지에 따라 결과가 바뀝니다. 그래서 이 발표의 가치는 "Glean의 숫자가 그대로 모든 기업에 적용된다"가 아니라 "agent ROI를 lifecycle 안에 넣어야 한다"는 문제 제기에 있습니다.
많은 AI 도입 프로젝트는 time saved claim으로 시작합니다. "회의록 요약에 30분을 아꼈다", "티켓 분류가 70% 빨라졌다", "코드 리뷰 초안이 자동으로 생성됐다" 같은 식입니다. 하지만 기업 포트폴리오 관점에서는 개별 절감 시간이 충분하지 않습니다. agent가 실제 KPI를 움직였는지, 특정 부서에만 유용한지, 사용자가 지속적으로 쓰는지, 품질이 떨어질 때 rollback할 수 있는지, compliance evidence를 남기는지가 함께 필요합니다.
Glean의 Agent Insights Dashboard는 이 문제를 겨냥합니다. 발표에 따르면 dashboard는 adoption, top use cases, estimated hours saved, feedback trends를 추적하도록 설계됐습니다. 이것이 실제로 얼마나 깊은 분석을 제공하는지는 제품을 더 봐야 합니다. 그래도 방향은 분명합니다. 에이전트는 이제 "사용자 반응이 좋다"가 아니라 "포트폴리오 지표로 관리된다"는 압박을 받기 시작했습니다.
경쟁자들도 같은 곳을 보고 있습니다
Glean만 이 방향을 보는 것은 아닙니다. IBM은 Think 2026에서 watsonx Orchestrate를 multi-agent era의 control plane으로 설명했습니다. IBM의 표현도 Glean과 비슷합니다. 조직이 수천 개 agent를 여러 팀과 여러 플랫폼에서 만들면, 핵심 문제는 agent를 만드는 일이 아니라 거의 실시간으로 governance와 auditability를 유지하는 일이 됩니다.
Honeycomb은 Agent Observability와 Agent Timeline을 발표하면서 LLM call, tool invocation, agent handoff, downstream system impact를 하나의 timeline으로 보겠다고 말했습니다. Collibra는 AI Command Center로 agent와 AI use case, data lineage, policy evidence를 연결하려 합니다. ServiceNow, Microsoft, UiPath도 각자의 control plane과 orchestration layer를 강조합니다. 이름은 다르지만 모두 같은 압력을 받습니다. 에이전트가 조직 안에서 실제 작업을 하면, 플랫폼은 runtime, identity, trace, policy, catalog, ROI를 다뤄야 합니다.
Glean의 차별점은 enterprise context입니다. Glean은 원래 workplace search와 enterprise graph를 기반으로 성장한 회사입니다. 따라서 에이전트 운영을 말할 때도 "어떤 데이터에 접근할 수 있는가", "사용자 권한이 어떻게 반영되는가", "답변의 출처가 무엇인가"를 자연스럽게 중심에 놓습니다. 이는 coding agent나 infrastructure agent 중심 회사와 다른 출발점입니다. Glean이 노리는 주 전장은 개발자의 IDE가 아니라 전사 업무 흐름입니다. 영업, 지원, HR, IT, 엔지니어링이 같은 context layer 위에서 agent를 만들고 관리하는 그림입니다.
물론 이 접근에도 위험이 있습니다. Horizontal platform은 넓은 범위를 다루지만 각 업무의 깊이를 놓칠 수 있습니다. Sales agent와 support agent와 engineering agent는 필요한 데이터, 실패 허용치, 승인 흐름이 다릅니다. 하나의 lifecycle 언어가 공통 기준을 주는 것은 좋지만, 실제 구현에서는 각 도메인의 세부 평가와 workflow 설계가 필요합니다. ADLC가 체크리스트로만 소비되면 또 하나의 governance ritual이 될 수 있습니다.
개발자에게는 무엇이 달라지나
개발자와 AI 제품팀 입장에서 이번 발표의 실무적 메시지는 세 가지입니다.
첫째, agent를 만들 때 처음부터 관측성을 설계해야 합니다. prompt와 tool schema만 저장하는 것으로는 부족합니다. agent가 어떤 context를 읽었고, 어떤 tool을 왜 호출했으며, 어떤 중간 판단을 했고, 어느 지점에서 사용자 승인이나 정책 검사가 있었는지 남겨야 합니다. 그래야 실패를 재현하고 개선할 수 있습니다. 이는 일반 애플리케이션의 logging보다 더 까다롭습니다. 민감 데이터와 reasoning trace가 섞일 수 있기 때문입니다.
둘째, agent catalog는 사소한 기능이 아닙니다. 조직 안에 agent가 늘어나면 discoverability와 trust가 병목이 됩니다. 사용자는 어떤 agent가 공식인지 알아야 하고, 관리자는 오래된 agent를 숨기거나 되돌릴 수 있어야 하며, 보안팀은 특정 agent가 위험한 쓰기 권한을 갖는지 볼 수 있어야 합니다. "누구나 agent를 만든다"는 말은 "누구나 production automation을 배포한다"는 뜻이 될 수 있습니다. 따라서 배포면은 협업 도구처럼 쉬워야 하지만, 통제면은 소프트웨어 릴리스처럼 엄격해야 합니다.
셋째, ROI는 launch 뒤에 붙이는 보고서가 아니라 design 단계의 입력값이어야 합니다. agent가 줄일 시간을 미리 가정하고, baseline과 target range를 정하고, 실패 시 pause나 rollback 기준을 정해야 합니다. 특히 에이전트가 사람의 판단을 대체하는 것이 아니라 사람의 검토 비용을 이동시키는 경우가 많기 때문에, 단순 생성 건수보다 end-to-end cycle time과 rework rate를 봐야 합니다.
아직 확인할 점
이번 발표는 공식 자료 중심이어서 독립 커뮤니티 검증은 아직 제한적입니다. HN이나 GeekNews에서 큰 공개 토론이 형성된 주제는 아니었습니다. 따라서 Glean의 수치와 고객 사례를 그대로 일반화하기보다는, 기업 agent 시장이 어디로 움직이는지 보여주는 신호로 읽는 편이 안전합니다.
또 하나의 질문은 vendor lock-in입니다. ADLC는 보편적인 운영 언어처럼 보이지만, Glean은 이를 자사 Work AI 플랫폼 기능과 깊게 묶습니다. Auto Mode, Enterprise Graph, Agent Library, Access Policies, Insights Dashboard가 한 플랫폼 안에서 잘 작동하면 편합니다. 반대로 이미 Microsoft, ServiceNow, IBM, Slack, GitHub, Datadog, 내부 orchestration 도구가 뒤섞인 조직에서는 또 하나의 control plane이 생기는 문제도 있습니다. 에이전트 운영의 다음 경쟁은 "누가 더 좋은 lifecycle 그림을 그리는가"가 아니라 "누가 이미 있는 시스템과 충돌 없이 evidence를 모을 수 있는가"로 갈 가능성이 큽니다.
그럼에도 ADLC 발표는 의미가 있습니다. 에이전트 시장이 성숙해질수록 멋진 데모의 가치는 줄고, 운영 가능한 시스템의 가치가 커집니다. 기업은 결국 agent가 무엇을 할 수 있는지보다, agent가 왜 그 일을 했는지 설명할 수 있는지, 실패했을 때 멈출 수 있는지, 실제 성과를 냈는지 묻습니다.
Glean ADLC는 그 질문을 7단계 lifecycle로 정리했습니다. 이 프레임워크가 업계 표준이 될지는 알 수 없습니다. 하지만 방향은 분명합니다. 2026년의 기업 AI 에이전트 경쟁은 agent를 더 많이 만드는 싸움이 아니라, agent를 운영 가능한 포트폴리오로 묶는 싸움이 되고 있습니다. 모델은 여전히 중요하지만, 이제 모델만으로는 충분하지 않습니다. 에이전트가 조직의 일을 맡는 순간, 승부처는 prompt가 아니라 lifecycle, trace, policy, ROI 장부로 이동합니다.