Copilot 코드리뷰 과금 이중화, AI 리뷰가 CI 비용이 된 날
GitHub Copilot code review가 6월 1일부터 AI Credits와 Actions minutes를 함께 소비합니다. AI 리뷰가 CI 운영비가 되는 변화를 분석합니다.
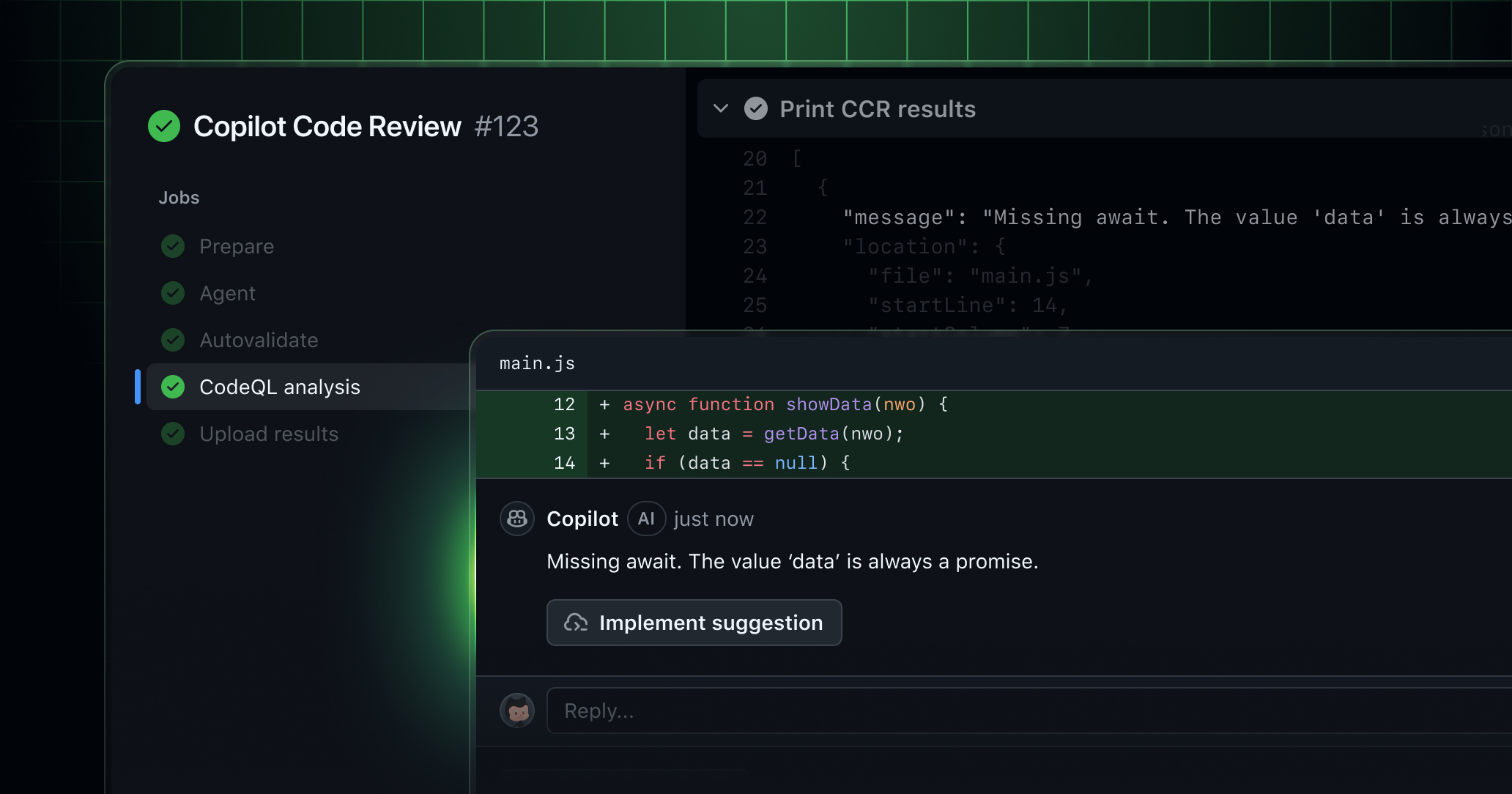
- 무슨 일: GitHub이 2026년 6월 1일부터
Copilot code review에 AI Credits와 GitHub Actions minutes를 함께 적용합니다.- private repository에서 GitHub-hosted runner로 실행되는 리뷰가 Actions minutes entitlement를 소비합니다.
- 의미: AI 코드리뷰가 더 이상 단순한 Copilot 요청이 아니라, CI 위에서 실행되는 agentic workflow로 취급됩니다.
- 실무 영향: 팀은 PR 리뷰 자동화를 켜기 전에
copilot-pull-request-reviewer사용량, runner 정책, 예산 한도를 같이 봐야 합니다. - 주의점: public repository는 Actions minutes가 계속 무료지만, private repository의 반복 리뷰는 AI 예산과 CI 예산을 동시에 압박할 수 있습니다.
GitHub Copilot의 코드리뷰 버튼이 비용 구조를 바꿉니다. GitHub은 2026년 4월 27일 changelog에서 2026년 6월 1일부터 Copilot code review가 두 가지 방식으로 청구된다고 공지했습니다. 하나는 새 usage-based billing 모델의 AI Credits입니다. 다른 하나는 GitHub Actions minutes입니다. 특히 private repository에서 GitHub-hosted runner로 실행되는 Copilot code review는 기존 Actions 포함량을 소비하고, 포함량을 넘으면 표준 GitHub Actions 요금으로 이어집니다.
겉으로는 Copilot 가격 정책의 또 다른 변경처럼 보입니다. 하지만 개발팀 입장에서는 더 구조적인 신호입니다. AI 코드리뷰가 “모델이 PR에 코멘트를 남기는 기능”을 넘어, repository context를 읽고, 도구를 호출하고, runner 위에서 실행되는 agentic workflow로 계산되기 시작했습니다. 비용이 그렇게 바뀐다는 것은 운영 방식도 그렇게 바뀌어야 한다는 뜻입니다.

왜 코드리뷰가 Actions minutes를 쓰나
이번 공지를 이해하려면 3월 발표부터 봐야 합니다. GitHub은 2026년 3월 5일 Copilot code review가 agentic tool-calling architecture로 일반 제공된다고 발표했습니다. 이 구조에서 Copilot은 단순히 diff 텍스트만 보고 짧은 코멘트를 생성하지 않습니다. 필요할 때 repository의 더 넓은 문맥, directory structure, 관련 코드, 참조 지점을 끌어와 변경이 전체 아키텍처에 어떻게 맞는지 판단하려고 합니다.
GitHub의 설명은 긍정적인 효과를 강조합니다. 더 높은 품질의 findings, 더 낮은 noise, 더 actionable한 guidance입니다. 코드리뷰 자동화에서 이것은 중요한 방향입니다. 개발자가 AI 리뷰를 싫어하는 가장 흔한 이유는 코멘트 수가 많아서가 아니라, 실제로 고칠 가치가 없는 말이 많아서입니다. repository context를 더 읽는 agentic review가 제대로 작동한다면, “스타일 잔소리”보다 correctness와 architecture integrity에 가까운 피드백을 줄 수 있습니다.
그런데 더 넓은 문맥을 읽고 도구를 호출하는 순간, 리뷰는 더 이상 순수 inference 호출이 아닙니다. 실행 환경이 필요합니다. GitHub은 그 실행 계층을 GitHub Actions에 둡니다. 3월 발표에도 “Agentic Copilot code review runs on GitHub Actions”라고 명시되어 있습니다. 이번 4월 공지는 그 기술적 사실이 6월부터 비용 구조에도 반영된다는 뜻입니다.
이 변화는 AI 기능의 비용이 어디에서 발생하는지 드러냅니다. 모델 token만 비싼 것이 아닙니다. repository checkout, context gathering, tool execution, workflow orchestration, log streaming, runner allocation도 비용입니다. Copilot code review는 모델 기능이면서 동시에 CI workload입니다. GitHub은 이제 이 둘을 분리하지 않고 함께 청구하겠다고 말하고 있습니다.
6월 1일에 실제로 바뀌는 것
GitHub의 공지는 범위를 꽤 명확히 나눕니다. 2026년 6월 1일부터 Copilot Pro, Pro+, Business, Enterprise가 대상입니다. 모든 Copilot usage는 새 usage-based billing 아래 AI Credits로 계산됩니다. 그리고 Copilot code review가 private repository에서 GitHub-hosted runners로 실행되면 GitHub Actions minutes도 소비합니다.
public repository는 다릅니다. GitHub은 public repository의 Actions minutes가 계속 무료라고 설명합니다. 따라서 오픈소스 프로젝트에서 Copilot code review를 실행하는 경우, Actions minutes 측면의 변화는 제한적입니다. 다만 Copilot usage 자체가 AI Credits 체계 안에 들어간다는 큰 방향은 유지됩니다.
self-hosted runner도 중요한 예외입니다. GitHub Docs의 models and pricing 문서는 Copilot code review가 token consumption과 agentic infrastructure라는 두 방식으로 청구된다고 설명하면서, self-hosted runners는 GitHub Actions minutes를 소비하지 않는다고 말합니다. 그러나 이것이 “무료 리뷰”를 의미하지는 않습니다. self-hosted runner는 Actions minutes 청구를 피할 수 있지만, AI Credits 과금은 남습니다. 또한 runner 운영 비용, 보안 설정, 네트워크 정책, secret 관리 책임은 조직 쪽으로 이동합니다.
이 지점이 실무적으로 중요합니다. 어떤 팀은 GitHub-hosted runner로 편하게 시작할 수 있습니다. 어떤 팀은 비용 통제나 보안 정책 때문에 self-hosted runner를 선호할 수 있습니다. 어떤 팀은 larger runner를 써야 할 수 있습니다. 이제 Copilot code review를 켜는 결정은 “AI 리뷰가 유용한가”만으로 끝나지 않습니다. “어떤 runner에서 돌릴 것인가”가 같이 붙습니다.
| 항목 | AI Credits | Actions minutes | 팀이 봐야 할 것 |
|---|---|---|---|
| 무엇을 반영하나 | 모델 token 사용량 | 리뷰 agent 실행 인프라 | 리뷰 빈도와 PR 크기 |
| 예측 난이도 | 모델이 자동 선택되어 review마다 달라질 수 있음 | runner 종류와 실행 시간에 좌우됨 | billing report와 Actions metrics |
| 통제 수단 | Copilot 예산과 플랜 정책 | Actions budget, spending limit, runner policy | repository별 자동 리뷰 기준 |
예측하기 어려운 비용이 더 어려운 이유
이번 변화에서 가장 까다로운 부분은 이중 과금 자체보다 예측 가능성입니다. 일반적인 Copilot 기능에서는 사용자가 어떤 모델을 쓰는지 볼 수 있고, pricing table을 보고 대략적인 token cost를 추정할 수 있습니다. 하지만 GitHub Docs는 Copilot code review를 예외로 둡니다. code review에서는 모델이 자동 선택되고 공개되지 않으므로, review마다 per-token cost가 달라질 수 있다고 설명합니다.
이것은 제품 설계상 이해할 수 있습니다. 코드리뷰 agent가 PR 크기, 언어, repository context, security signal, review task 난이도에 따라 적절한 모델을 고르는 것이 품질 면에서는 합리적일 수 있습니다. 작은 문서 수정과 대규모 권한 모델 변경을 같은 모델로 리뷰할 필요는 없습니다.
하지만 비용 관리 관점에서는 다른 이야기입니다. 모델이 공개되지 않고, context gathering 범위도 review마다 달라지고, 여기에 runner 실행 시간까지 붙으면, 리뷰 한 번의 비용을 PR 작성자가 직관적으로 알기 어렵습니다. 팀이 느끼는 문제는 “몇 센트 더 나간다”가 아니라 “어떤 작업이 비용을 유발하는지 사전에 설명하기 어렵다”에 가깝습니다.
그래서 GitHub이 권장하는 준비 작업도 billing과 metrics에 집중되어 있습니다. billing manager는 Actions usage와 entitlement를 확인해야 하고, spending limits와 budgets를 조정해야 하며, Copilot usage metrics, GitHub Actions metrics, Billing Usage Report를 같이 봐야 합니다. Docs는 Copilot code review 사용량을 확인할 때 GitHub Actions metrics에서 copilot-pull-request-reviewer workflow로 필터링하라고 안내합니다. Billing usage report에서는 6월 1일 이후 dynamic/agents/copilot-pull-request-reviewer workflow path를 볼 수 있습니다.
이런 필터 이름이 중요해지는 순간, AI 기능은 개발자 편의 기능이 아니라 platform accounting 대상이 됩니다. 누가 어떤 PR에서 AI review를 요청했는지, 어떤 repository에서 자동 review가 반복되는지, 어떤 팀이 Actions minutes를 많이 쓰는지 확인할 수 있어야 합니다. 그렇지 않으면 AI 코드리뷰는 품질 도구가 아니라 알 수 없는 청구 항목이 됩니다.
비용 변화가 말하는 제품 방향
GitHub은 2026년 들어 Copilot을 빠르게 확장하고 있습니다. Copilot app 기술 프리뷰, cloud agent task REST API, team-level usage metrics, auto model selection, CLI agent, unified sessions view가 같은 시기에 쏟아졌습니다. 이 흐름에서 code review 과금 변화는 별개의 회계 이벤트가 아닙니다. Copilot이 IDE 자동완성에서 개발 운영 계층으로 이동하고 있다는 또 하나의 증거입니다.
초기의 Copilot은 한 줄 추천과 함수 생성으로 기억됩니다. 그때 비용 모델은 비교적 단순했습니다. 사용자는 구독료를 내고, GitHub은 모델 호출 비용을 내부에서 흡수했습니다. 그러나 agentic coding으로 넘어오면 단위가 달라집니다. agent는 repository를 읽고, branch를 만들고, test를 실행하고, PR을 열고, review comment에 답하고, 실패한 check를 다시 고칩니다. 이것은 채팅 한 번이 아니라 workflow입니다.
Copilot code review도 마찬가지입니다. PR diff를 보고 코멘트를 다는 것처럼 보이지만, GitHub의 설명대로라면 agentic architecture는 broader repository context를 필요에 따라 가져옵니다. 코드리뷰가 architecture integrity를 판단하려면 관련 파일, 호출 관계, 디렉터리 구조, 기존 패턴을 읽어야 합니다. 그러면 AI 리뷰는 점점 CodeQL, Actions, branch protection, required checks, security scanning과 같은 GitHub의 기존 운영 표면에 가까워집니다.
여기서 GitHub의 장점은 분명합니다. PR과 Actions와 Copilot이 같은 플랫폼에 있습니다. 외부 AI code review SaaS를 붙일 때 필요한 webhook, token, 권한, check reporting, comment permission을 GitHub 내부에서 자연스럽게 다룰 수 있습니다. 반대로 이것은 잠금 효과도 만듭니다. 리뷰 품질과 비용, 실행 환경, 조직 정책이 모두 GitHub 계정과 Actions 예산에 묶입니다.
개발팀은 무엇을 바꿔야 하나
가장 먼저 할 일은 Copilot code review를 “기본 켜기 좋은 기능”으로만 보지 않는 것입니다. AI 리뷰는 PR 품질을 높일 수 있지만, 모든 PR에 같은 방식으로 붙일 필요는 없습니다. 문서 수정, 단순 config 변경, dependency lockfile 업데이트, generated file 변경까지 매번 agentic review를 돌리면 비용 대비 신호가 낮을 수 있습니다. 반대로 권한 모델, 결제 로직, 인증, data migration, API contract 변경에는 더 강한 리뷰 자동화가 가치 있을 수 있습니다.
둘째, repository별 정책이 필요합니다. public repository와 private repository의 비용 구조가 다르고, GitHub-hosted runner와 self-hosted runner의 비용 표면도 다릅니다. 민감한 private repository에서 Copilot code review를 쓴다면 runner 환경, secret 접근, network policy, log retention을 함께 봐야 합니다. AI 리뷰가 repository context를 더 넓게 읽는다는 것은 더 좋은 피드백을 줄 가능성이 있다는 뜻이지만, 동시에 더 넓은 권한과 실행 흔적을 남긴다는 뜻이기도 합니다.
셋째, PR 작성자에게 비용 감각을 줘야 합니다. “AI 리뷰 요청” 버튼이 보이면 개발자는 그것을 제품 기능으로 인식합니다. 그러나 조직 입장에서는 AI Credits와 Actions minutes가 동시에 움직입니다. PR template이나 contribution guide에 어떤 상황에서 Copilot review를 요청하는지, 자동 review가 켜진 repository는 어디인지, 대형 PR을 쪼개야 하는 기준은 무엇인지 적어두는 편이 좋습니다.
넷째, 비용을 품질 지표와 함께 봐야 합니다. AI 리뷰가 Actions minutes를 쓰는 것 자체는 나쁜 일이 아닙니다. 사람이 놓칠 버그를 잡고, review turnaround를 줄이고, architecture drift를 낮춘다면 비용을 정당화할 수 있습니다. 문제는 그 효과를 보지 않고 review count와 comment count만 늘리는 경우입니다. 팀은 Copilot review가 남긴 코멘트 중 실제 코드 변경으로 이어진 비율, false positive 체감, reviewer time 감소, security finding 품질을 함께 추적해야 합니다.
커뮤니티의 불만은 가격보다 신뢰에 가깝다
Reddit r/GithubCopilot의 공개 스레드에서는 반응이 좋지 않았습니다. 일부 사용자는 최근 token-based pricing, rate limit, model multiplier 변화에 이어 Actions minutes까지 붙는 점을 “또 다른 비용층”으로 받아들였습니다. 인용할 필요 없이 분위기를 요약하면, 개발자들은 Copilot이 더 강력해지는 속도만큼 비용 구조도 더 복잡해지고 있다고 느끼고 있습니다.
이 불만은 단순히 가격 저항으로만 보면 안 됩니다. AI 개발 도구는 이미 신뢰 문제를 안고 있습니다. 모델이 언제 바뀌는지, 요청이 어떤 한도를 쓰는지, 어떤 데이터가 학습에 쓰이는지, 어떤 작업이 자동으로 실행되는지, 어떤 리뷰 코멘트가 신뢰할 만한지 개발자가 계속 판단해야 합니다. 여기에 billing surface가 늘어나면 제품 신뢰는 더 민감해집니다.
GitHub도 이 점을 모르는 것은 아닙니다. changelog는 “billing administrators and engineering leads”에게 6월 1일 전에 업데이트를 공유하라고 권고합니다. 이는 이번 변화가 개인 개발자 경험보다 조직 운영 변화에 가깝다는 뜻입니다. AI 코드리뷰를 쓰는 팀은 이제 engineering productivity, developer experience, FinOps, security를 한 테이블에 올려야 합니다.
AI 리뷰의 다음 경쟁은 코멘트 품질만이 아니다
AI 코드리뷰 시장은 이미 붐빕니다. GitHub Copilot code review, CodeRabbit, Graphite Reviewer, Sourcegraph Cody, CodeQL autofix, 사내 LLM review action, 각종 GitHub Actions 기반 리뷰 봇이 비슷한 공간을 두고 경쟁합니다. 초기 경쟁은 “누가 더 정확한 코멘트를 남기는가”에 가까웠습니다. 앞으로는 “누가 더 예측 가능한 운영 모델을 제공하는가”가 중요해집니다.
좋은 AI 리뷰 도구는 단순히 똑똑한 모델을 붙인 것이 아닙니다. 어떤 파일을 읽었는지 설명할 수 있어야 합니다. 왜 그 코멘트가 중요한지 우선순위를 줄 수 있어야 합니다. false positive를 줄이고, 팀의 coding standard를 반영하고, security-sensitive change에서 더 엄격해져야 합니다. 그리고 이제 비용도 설명해야 합니다. review one-click 경험 뒤에 token budget과 runner budget이 있다면, 그 비용이 어떤 정책으로 제어되는지 보여줘야 합니다.
GitHub의 위치는 강합니다. PR, Actions, branch protection, review UI, billing report가 모두 같은 플랫폼에 있습니다. 그러나 강한 위치는 높은 기대를 동반합니다. Copilot code review가 Actions minutes를 소비한다면, 사용자는 그만큼 Actions 수준의 관측 가능성과 제어를 기대합니다. 어떤 workflow가 뛰었고, 왜 뛰었고, 얼마를 썼고, 어떤 결과를 남겼는지 명확해야 합니다.
6월 1일 전 체크리스트
조직에서 Copilot code review를 쓰고 있다면, 6월 1일 전에는 최소한 네 가지를 확인해야 합니다.
첫째, 현재 Actions minutes 사용량입니다. 이미 CI가 빡빡한 조직이라면 Copilot code review가 private repository에서 추가로 소비하는 minutes가 예산 경고를 더 빨리 당길 수 있습니다. 둘째, Copilot usage metrics입니다. 어떤 팀과 repository에서 AI review가 많이 실행되는지 알아야 합니다. 셋째, runner 설정입니다. GitHub-hosted runner, larger runner, self-hosted runner 중 무엇을 쓸지 비용과 보안 기준을 함께 판단해야 합니다. 넷째, repository별 자동화 정책입니다. 모든 PR에 AI review를 붙일지, 특정 label이나 path, risk class에만 붙일지 정해야 합니다.
이 체크리스트의 핵심은 AI 리뷰를 끄라는 것이 아닙니다. 반대로 제대로 쓰려면 운영 기준이 필요하다는 뜻입니다. AI 코드리뷰는 좋은 팀에서 리뷰어의 시간을 절약하고, 놓치기 쉬운 edge case를 찾고, junior developer에게 빠른 피드백을 줄 수 있습니다. 하지만 무제한으로 켜두면 비용과 noise도 같이 늘어납니다.
이번 GitHub 공지는 AI 개발 도구 시장의 성숙을 보여줍니다. 무료처럼 보이던 기능이 실제 실행 비용을 드러내고, agentic architecture가 CI 예산과 연결되고, 개발팀이 AI 사용량을 운영 지표로 다루기 시작합니다. 이것은 불편하지만 피할 수 없는 방향입니다.
Copilot code review의 6월 1일 변화는 단순한 과금 항목 추가가 아닙니다. AI 리뷰가 개발자의 화면 안 기능에서 CI/CD 운영 계층으로 이동했다는 신호입니다. 앞으로의 AI 코딩 도구 경쟁은 모델 품질만으로 끝나지 않습니다. 누가 리뷰 품질, 실행 안전성, 사용량 예측, 비용 통제를 한 흐름으로 묶을 수 있는지가 더 중요해집니다.