Copilot App 기술 프리뷰, 코딩 에이전트의 병목은 하네스
GitHub Copilot App 기술 프리뷰와 VS Code 하네스 공개는 코딩 에이전트 경쟁이 모델보다 실행 환경과 PR 수명주기로 이동했음을 보여줍니다.
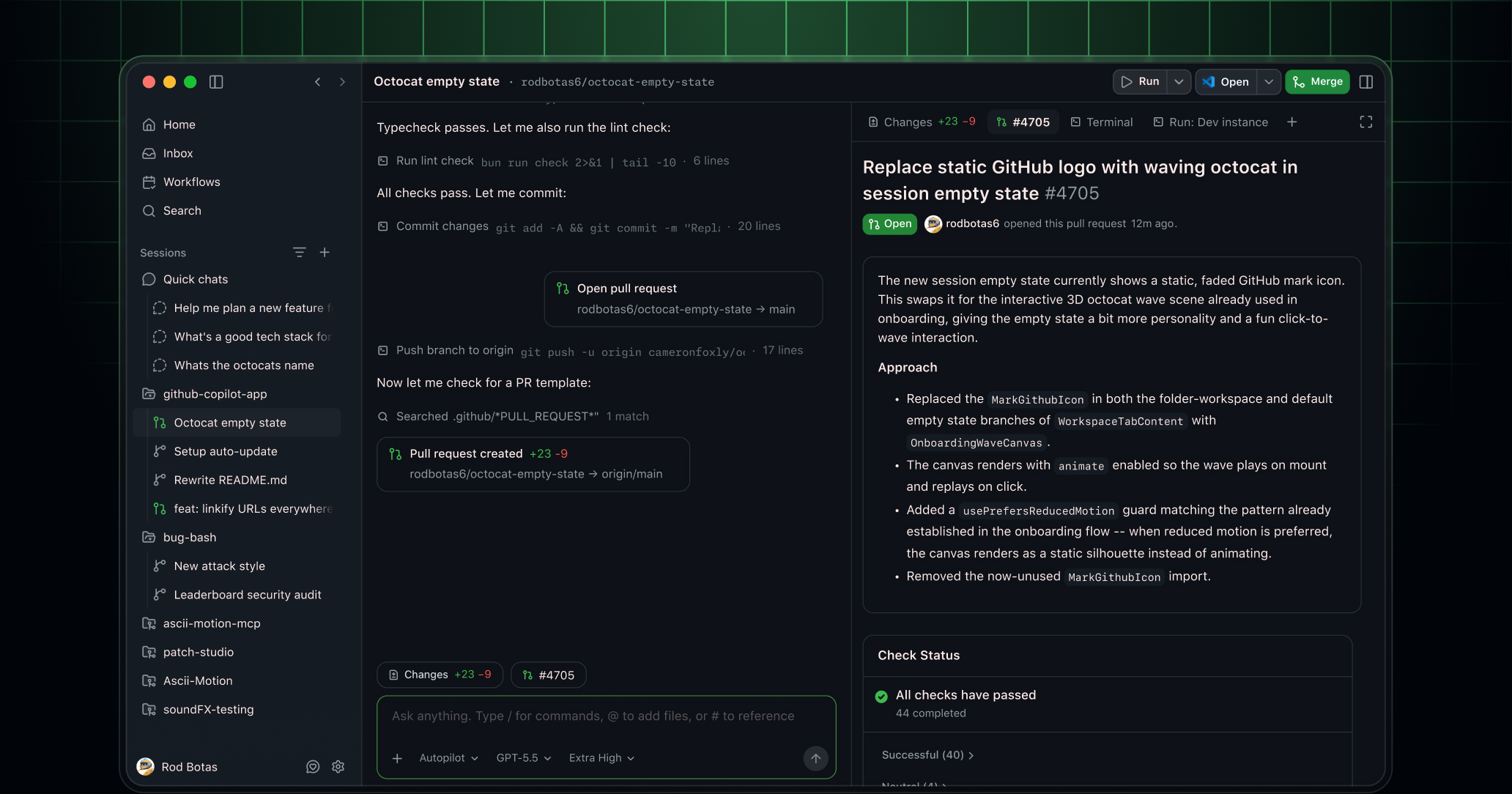
- 무슨 일: GitHub가 Copilot App 기술 프리뷰를 공개하고 이슈, 세션, 검증, PR, 머지를 한 데스크톱 앱 안으로 묶었습니다.
- Pro/Pro+는 waitlist, Business/Enterprise는 조직 프리뷰와
Copilot CLI정책이 조건입니다.
- Pro/Pro+는 waitlist, Business/Enterprise는 조직 프리뷰와
- 핵심 변화: Agent Merge는 리뷰 코멘트와 실패한 체크를 에이전트가 이어받아 조건 충족 시 머지까지 가는 흐름을 겨냥합니다.
- 의미: 같은 주 VS Code 팀의 하네스 공개와 합치면, 경쟁축은 모델 선택보다 컨텍스트, 도구 루프, 평가, PR 수명주기로 이동합니다.
- 좋은 모델을 고르는 문제보다, 그 모델이 어떤 파일을 보고 어떤 도구를 쓰며 언제 멈출지 정하는 계층이 더 중요해집니다.
- 주의점: 커뮤니티 반응은 기능 기대보다 Copilot 표면이 너무 많아졌다는 혼란과 과금 피로가 더 크게 보입니다.
GitHub가 2026년 5월 14일 GitHub Copilot App 기술 프리뷰를 공개했습니다. 겉으로만 보면 또 하나의 AI 코딩 앱입니다. 하지만 발표문을 자세히 읽어보면 GitHub가 겨냥하는 지점은 자동완성이나 채팅창이 아닙니다. 이슈를 고르고, 격리된 세션을 열고, 브랜치를 만들고, 코드를 고치고, 터미널과 브라우저로 검증하고, PR을 열고, 리뷰 코멘트와 실패한 체크를 처리하고, 조건이 맞으면 머지하는 전체 개발 수명주기입니다.
이 발표가 흥미로운 이유는 바로 다음 날 나온 VS Code 팀의 글과 맞물리기 때문입니다. VS Code 팀은 The Coding Harness Behind GitHub Copilot in VS Code에서 코딩 에이전트의 실제 제품 품질을 좌우하는 계층을 "coding harness"라고 설명했습니다. 모델은 텍스트를 생성할 뿐이고, 파일을 읽고, diff를 만들고, 터미널을 실행하고, 실패를 다시 모델에 돌려주는 일은 하네스가 맡는다는 설명입니다.
따라서 이번 뉴스의 핵심은 "GitHub도 데스크톱 앱을 냈다"가 아닙니다. 더 정확히는 "코딩 에이전트의 병목이 모델에서 하네스와 PR 수명주기로 옮겨가고 있다"입니다. GPT, Claude, Gemini 중 어느 모델이 가장 똑똑한지 묻는 질문은 여전히 중요합니다. 그러나 실제 팀에서 코딩 에이전트를 쓰려면 다른 질문이 더 빨리 따라옵니다. 에이전트가 어느 브랜치에서 일합니까? 어떤 컨텍스트를 봅니까? 어떤 도구를 쓸 수 있습니까? 테스트 실패를 어디까지 고칩니까? 리뷰어가 남긴 코멘트는 누가 반영합니까? 머지는 누가, 어떤 조건에서 합니까?
Copilot App이 실제로 묶는 것
GitHub의 발표문은 Copilot App을 "GitHub-native desktop experience"라고 부릅니다. 세션은 이슈, PR, 프롬프트, 이전 세션에서 시작할 수 있고, 이슈 상세, 저장소 상태, 리뷰 코멘트, 체크 결과가 세션과 연결됩니다. 사용자는 여러 일을 동시에 진행할 수 있으며, 각 세션은 자체 브랜치, 파일, 대화, 작업 상태를 갖는 격리된 공간으로 유지됩니다.
여기까지는 다른 코딩 에이전트 앱과 크게 다르지 않아 보일 수 있습니다. 차이는 마지막 단계에서 더 선명해집니다. GitHub는 "코드가 바뀌었다고 일이 끝난 것이 아니라, 리뷰되고 테스트되고 머지할 준비가 되었을 때 끝난다"고 설명합니다. 그래서 Copilot App 안에는 계획과 diff 리뷰, 통합 터미널과 브라우저 검증, PR 생성, 기존 리뷰와 체크 요구사항 연결, 그리고 Agent Merge가 들어갑니다.
Agent Merge는 이번 발표의 가장 노골적인 신호입니다. GitHub는 이 기능을 통해 에이전트가 리뷰 코멘트를 처리하고, 실패한 체크를 고치고, 사용자가 정한 조건이 맞으면 머지까지 이어갈 수 있다고 설명합니다. 에이전트가 코드를 "제안"하는 단계를 넘어, PR이 닫힐 때까지 남아 있는 후속 작업을 맡는 구조입니다.
이 지점에서 GitHub의 강점은 모델 그 자체가 아닙니다. GitHub는 이미 이슈, PR, 브랜치 보호 규칙, CI 체크, 코드 리뷰, Actions, 모바일 알림, 조직 정책을 갖고 있습니다. Copilot App은 이 자산들을 에이전트의 작업장으로 재배치합니다. Cursor나 Claude Code가 로컬 개발 경험에서 강한 인상을 주는 동안, GitHub는 "코드가 실제로 합쳐지는 장소"를 장악하고 있다는 점을 전면에 세우는 셈입니다.
VS Code 팀이 말한 하네스의 실체
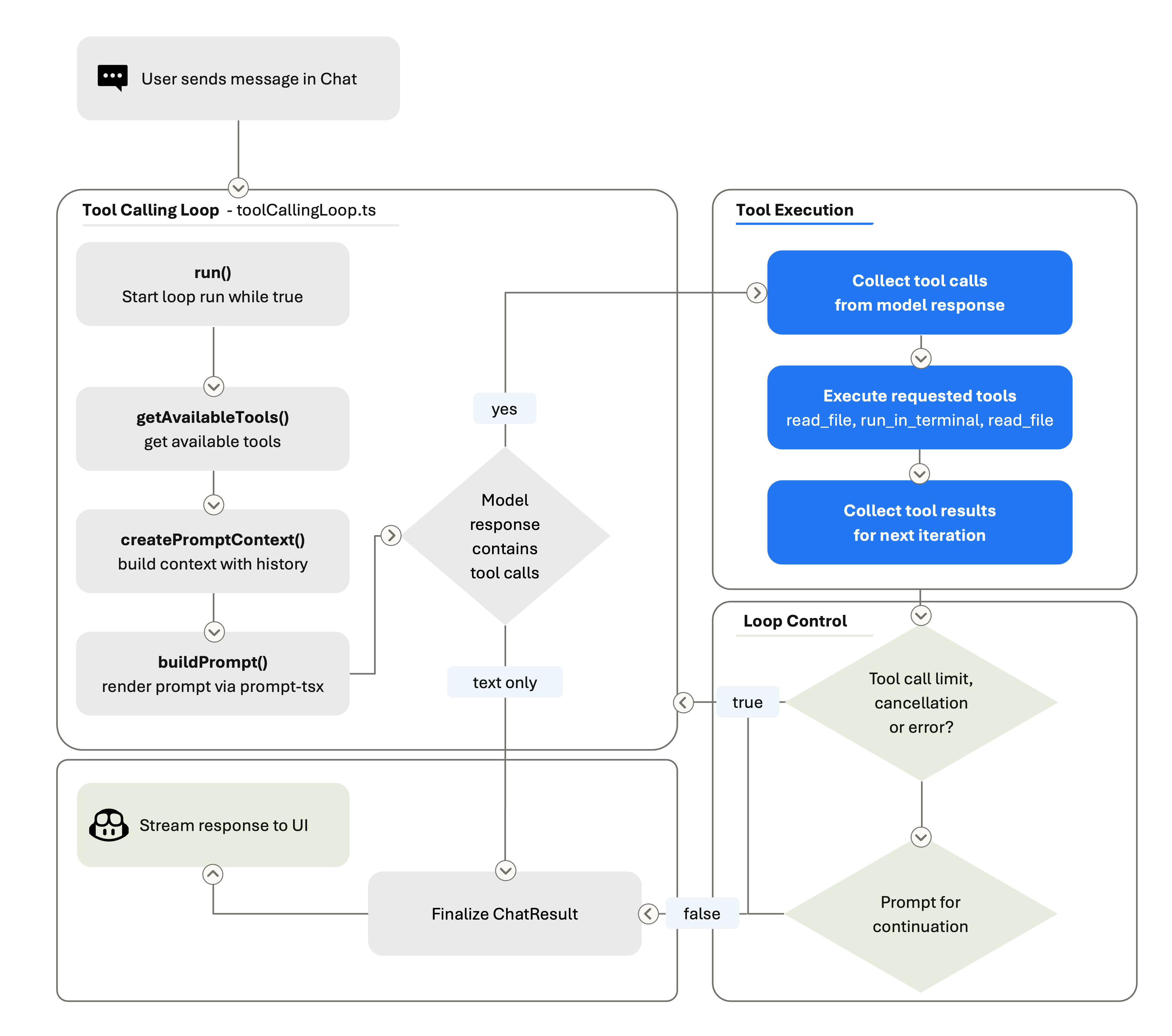
VS Code 블로그는 이번 Copilot App 발표를 해석하는 데 좋은 기술적 배경을 줍니다. 글은 코딩 하네스의 세 가지 책임을 컨텍스트 조립, 도구 노출, 도구 실행으로 나눕니다. 컨텍스트 조립은 시스템 메시지, 사용자 요청, 워크스페이스 구조, 열린 파일, 대화 기록, 도구 결과, 사용자 지침, 이전 세션 메모리 등을 어떤 형태로 모델에 전달할지 정하는 일입니다.
도구 노출은 모델이 호출할 수 있는 도구를 정의하는 일입니다. 파일 읽기, 코드 수정, 터미널 실행, 코드베이스 검색, MCP 서버, 확장 기능이 제공하는 도구가 여기에 들어갑니다. 도구 실행은 모델이 JSON 형태로 요청한 일을 실제 환경에서 검증하고 실행한 뒤, 결과를 다시 모델에 돌려주는 계층입니다. 모델은 "이 명령을 실행하라"고 텍스트를 낼 수 있지만, 실제 프로세스를 띄우고, stdout을 캡처하고, 실패를 해석하고, 다음 반복으로 연결하는 것은 하네스입니다.
이 구조는 개발자가 체감하는 품질을 직접 바꿉니다. 같은 모델이라도 어떤 파일을 먼저 보게 하느냐, tool description을 어떻게 쓰느냐, 실패한 명령을 몇 번까지 반복하게 하느냐, diff를 어떻게 적용하게 하느냐에 따라 결과가 크게 달라집니다. VS Code 팀은 모델별 차이까지 공개했습니다. Claude 모델은 replace_string_in_file 방식의 편집을 쓰고, GPT 모델은 apply_patch를 쓰며, Gemini에는 도구를 실제로 호출하도록 별도 유도가 필요하다는 식입니다. 이것은 "모델을 바꾸면 끝"이라는 단순한 그림과 거리가 멉니다.
특히 중요한 대목은 루프 제어입니다. VS Code의 에이전트 루프는 한 사용자 턴 안에서도 여러 라운드를 돕니다. 모델이 파일을 검색하고, 코드를 읽고, 수정하고, 테스트를 돌리고, 실패를 읽고, 다시 수정하는 과정입니다. 하네스는 도구 호출 제한, 취소, stop hook, 대화 요약을 관리합니다. 컨텍스트가 커지면 이전 라운드를 요약해 모델이 계속 작업할 수 있게 하는 것도 하네스의 일입니다.
Copilot App은 이 하네스를 IDE 밖의 더 긴 작업 단위로 확장하려는 시도입니다. VS Code의 하네스가 한 편집기 안에서 tool-calling loop를 다룬다면, Copilot App은 여러 세션, 여러 브랜치, 여러 PR, 여러 검증 단계를 데스크톱 앱과 GitHub 수명주기 안에서 다룹니다. 둘은 경쟁 표면처럼 보이지만, 실제로는 같은 방향의 제품화입니다.
모델 선택보다 어려워진 기본값의 문제
GitHub Copilot의 2026년 4월 VS Code 릴리스도 같은 흐름을 보여줍니다. GitHub는 Copilot이 모든 워크스페이스에서 의미 기반 검색을 할 수 있고, githubTextSearch로 저장소와 조직 전체를 grep 스타일로 검색할 수 있으며, /chronicle로 과거 채팅 기록을 검색할 수 있다고 발표했습니다. 또 prompt caching, deferred tool loading, agentic tools로 토큰 사용을 줄이고, inline diff, browser tab sharing, 열린 터미널 read/write, BYOK, 원격 CLI 세션 조작을 추가했습니다.
이 목록을 모델 릴리스 노트처럼 읽으면 놓치는 것이 있습니다. 대부분은 "모델이 더 똑똑해졌다"가 아니라 "모델이 일할 수 있는 환경이 더 촘촘해졌다"에 가깝습니다. 브라우저 탭을 공유하면 프론트엔드 검증의 관측면이 넓어집니다. 열린 터미널을 읽고 쓰면 이미 실행 중인 REPL이나 dev server를 활용할 수 있습니다. deferred tool loading은 모든 도구 설명을 매번 프롬프트에 밀어 넣지 않고 필요한 시점에 노출하려는 비용 관리입니다. BYOK는 모델 공급자를 바꿔도 같은 하네스 경험을 유지하려는 전략입니다.
VS Code 팀은 새 모델을 넣는 일이 모델 picker에 옵션 하나를 추가하는 문제가 아니라고 말합니다. 공급자마다 도구 호출, structured output, reasoning control, prompt caching, context limit, error behavior가 다릅니다. 어떤 모델은 긴 계획에 강하고, 어떤 모델은 짧은 편집에 강합니다. 어떤 모델은 많은 reasoning effort를 주면 좋아지지만, 어떤 경우에는 토큰만 더 쓰고 성과가 줄어듭니다.
그래서 VS Code 팀은 VSC-Bench를 만들었습니다. 공개 벤치마크인 SWE-bench나 Terminal-Bench도 참고하지만, 실제 제품 안에서 중요한 일은 더 넓다는 문제의식입니다. 에디터 안의 코딩 에이전트는 알려진 버그 패치를 맞히는 것만으로 충분하지 않습니다. 프로젝트를 스캐폴딩하고, 여러 파일을 리팩터링하고, 터미널과 브라우저를 다루고, MCP와 확장 도구를 사용하고, 여러 턴에 걸친 지시를 따라야 합니다. VSC-Bench는 이런 VS Code 특화 업무를 컨테이너화된 워크스페이스에서 실행하며, 해결률뿐 아니라 agent effort, 토큰 효율, 지연시간까지 봅니다.
이 대목은 실무 팀에도 그대로 적용됩니다. 에이전트 도입의 어려움은 "가장 좋은 모델 하나를 고르자"에서 끝나지 않습니다. 회사 저장소의 구조, 테스트 비용, 브랜치 정책, secret 접근, 외부 API 호출, 코드 리뷰 기준, 장애 대응 절차가 모두 하네스의 일부가 됩니다. Copilot App이 GitHub 수명주기에 붙는다는 것은 이 복잡한 기본값을 GitHub가 대신 제시하겠다는 의미이기도 합니다.
Agent Merge가 불편하게 만드는 질문
Agent Merge는 매력적이지만, 동시에 불편한 질문을 남깁니다. 에이전트가 리뷰 코멘트를 처리하고 실패한 체크를 고친 뒤 머지할 수 있다면, 개발자는 어느 순간에 책임을 확인해야 합니까? "조건이 맞으면 머지"에서 조건은 누가 정의하며, 그 조건은 조직의 코드 품질 기준을 충분히 대표합니까? CI가 통과했지만 설계가 나쁘거나, 보안 리뷰가 충분하지 않거나, 테스트가 누락된 변경은 어떻게 걸러야 합니까?
GitHub 입장에서는 기존 보호 장치를 활용할 수 있습니다. 브랜치 보호, required review, required status checks, CODEOWNERS, secret scanning, CodeQL 같은 장치가 이미 GitHub 안에 있습니다. 그러나 에이전트가 PR 수명주기의 더 많은 부분을 차지할수록, 이 보호 장치들의 설정 품질이 곧 에이전트 품질의 일부가 됩니다. 약한 보호 규칙을 가진 저장소에서는 Agent Merge가 단순한 편의 기능이 아니라 위험 증폭기가 될 수 있습니다.
반대로 성숙한 저장소에서는 가치가 큽니다. 사소한 리뷰 코멘트 반영, 실패한 포맷팅 체크 수정, 누락된 테스트 실행, 린트 오류 처리처럼 사람의 집중력을 깎는 후속 작업을 에이전트가 맡을 수 있습니다. 코딩 에이전트가 처음 코드를 생성하는 순간보다, 리뷰 이후의 잡다한 마무리 단계에서 더 안정적으로 가치를 낼 가능성도 있습니다. 사람은 방향과 판단을 맡고, 에이전트는 반복적인 PR 마감 작업을 맡는 분업입니다.
이것이 GitHub가 앱까지 만든 이유일 수 있습니다. IDE 안의 채팅 패널은 코드를 쓰는 순간에는 가깝지만, 리뷰와 머지의 끝단까지는 멉니다. 웹 UI는 PR과 이슈에는 가깝지만, 로컬 파일, 터미널, 브라우저 검증에는 약합니다. 데스크톱 앱은 이 둘 사이를 잇는 표면입니다. 이 표면이 성공하면 GitHub는 에이전트 작업의 시작점과 종착점을 모두 자사 플랫폼 안에 둘 수 있습니다.
커뮤니티가 혼란을 먼저 본 이유
발표 직후 Reddit r/GitHubCopilot의 반응은 기대보다 혼란에 가까웠습니다. "VS Code의 새 Agents window와 왜 나뉘어 있나", "Copilot, Codex, Cursor, Claude Code, OpenCode가 다 비슷하게 들린다", "VS Code agents가 하지 못하는 무엇을 제공하나" 같은 질문이 이어졌습니다. GitHub 측으로 보이는 한 댓글은 VS Code, 웹, CLI, 앱 팀이 함께 단일 플랫폼으로 통합하는 작업을 하고 있다고 답했지만, 사용자 입장에서 표면이 많아진 것은 사실입니다.
가격 피로도 함께 보입니다. 최근 Copilot의 usage-based billing과 premium request multiplier 논의가 커뮤니티에 남아 있기 때문에, 새 앱 발표도 순수한 기능 뉴스로만 받아들여지지 않습니다. "모델을 더 많이 쓰고, 에이전트가 더 오래 돌고, 리뷰와 머지까지 자동화하면 비용은 어떻게 계산되는가"라는 질문이 자연스럽게 따라옵니다. 코딩 에이전트가 장기 실행 작업으로 이동할수록 과금 모델은 제품 경험의 일부가 됩니다.
이 반응은 GitHub가 풀어야 할 제품 과제입니다. Copilot은 이미 자동완성, IDE chat, GitHub.com chat, CLI, cloud agent, mobile, Spark, Spaces, code review, PR 요약 등 많은 표면을 갖고 있습니다. Copilot App이 이들을 정리하는 중심이 될지, 아니면 또 하나의 표면을 추가하는 데 그칠지는 아직 기술 프리뷰 단계에서 판단하기 어렵습니다.
다만 방향은 분명합니다. GitHub는 개발자의 한 화면을 더 차지하려는 것이 아니라, 에이전트가 일하는 방식을 GitHub 객체 모델에 맞추려 합니다. 이슈는 작업 단위, 브랜치는 격리 단위, PR은 검토 단위, 체크는 검증 단위, 머지는 완료 단위입니다. Copilot App은 이 객체들을 에이전트의 기본 언어로 만들려는 시도입니다.
개발팀이 지금 봐야 할 것
개발팀 관점에서 이번 발표를 "써볼까 말까"로만 보면 너무 좁습니다. 더 중요한 질문은 우리 조직의 코딩 에이전트 하네스가 무엇인가입니다. 에이전트가 어떤 저장소에 접근할 수 있는지, 어떤 명령을 실행할 수 있는지, 실패를 어떻게 보고하는지, 어떤 테스트를 신뢰하는지, 리뷰어가 어디서 개입하는지, 자동 머지 조건은 무엇인지 정리되어 있습니까?
Copilot App을 쓰지 않더라도 이 질문은 남습니다. Claude Code, Codex, Cursor, OpenCode, 사내 에이전트 모두 같은 문제를 만납니다. 모델은 점점 강해지고 모델 간 차이는 워크플로우에 따라 뒤집힙니다. 반면 하네스, 정책, 평가, 로그, 권한, PR 규칙은 조직별로 다르고 쉽게 복제되지 않습니다. 앞으로 AI 코딩 생산성의 차이는 이 로컬한 운영 계층에서 더 많이 날 가능성이 큽니다.
GitHub가 유리한 지점은 이미 많은 팀의 개발 사실상 기록 시스템이라는 점입니다. 에이전트가 이슈에서 시작해 PR에서 끝난다면 GitHub는 자연스러운 제어면입니다. 약한 지점은 제품 표면의 혼란과 과금 신뢰입니다. 개발자가 "어떤 Copilot을 써야 하지"라고 느끼는 순간, 하네스의 장점은 브랜드 복잡성에 묻힙니다.
이번 Copilot App 기술 프리뷰는 정답이라기보다 방향 표식에 가깝습니다. 코딩 에이전트의 다음 경쟁은 누가 더 멋진 채팅 UI를 만들었는지가 아니라, 누가 더 안전하고 관측 가능하며 중단 가능한 실행 루프를 만들었는지에 달려 있습니다. 그리고 그 루프가 PR 리뷰와 머지라는 실제 소프트웨어 공급망의 끝단까지 닿는 순간, AI 코딩 도구는 개발 보조 도구가 아니라 개발 운영 계층이 됩니다.