GitHub 접근성 에이전트, 3,535개 PR에서 배운 한계
GitHub의 접근성 에이전트 파일럿은 AI 코드 리뷰가 품질 보증으로 확장될 때 필요한 데이터, 멈춤 조건, 인간 검토의 기준을 보여줍니다.

- 무슨 일: GitHub가 Copilot 기반
general-purpose accessibility agent파일럿을 공개했습니다.- 공식 발표일은 2026년 5월 15일이며, 에이전트는 프런트엔드 PR을 자동 평가하고 단순한 접근성 문제를 수정하도록 설계됐습니다.
- 핵심 숫자: 지금까지 3,535개 PR을 리뷰했고 68% resolution rate를 기록했습니다.
- 진짜 신호: GitHub는 병렬 에이전트보다 선형 절차, 템플릿, escalation gate를 강조했습니다.
- 복잡하거나 고위험인 UI 패턴에서는 코드 생성을 멈추고 접근성 팀 상담으로 넘기는 구조입니다.
- 주의점: WCAG A/AA 기준 55개 중 35개만 자동 검사로 결정 가능하며, 약 36%는 수동 평가가 필요합니다.
GitHub가 5월 15일 공개한 접근성 에이전트 파일럿은 언뜻 보면 또 하나의 Copilot 확장 사례처럼 보입니다. 그러나 세부 내용을 읽어보면 더 흥미로운 질문이 드러납니다. AI 코딩 에이전트가 코드를 "작성"하는 단계를 넘어, 품질 보증과 조직의 전문 지식까지 다루려면 어떤 구조가 필요할까요?
GitHub의 답은 낙관적이지만 단순하지 않습니다. 이 에이전트는 GitHub Copilot CLI와 Copilot VS Code 통합 안에서 접근성 질문에 답하고, 프런트엔드 코드가 바뀌는 PR을 자동 평가합니다. 단순하고 객관적인 접근성 문제는 production에 들어가기 전에 잡고, 가능하면 바로 고칩니다. 여기까지만 보면 AI linting처럼 들립니다.
하지만 GitHub가 공개한 숫자와 설계 선택은 조금 다른 이야기를 합니다. 에이전트는 지금까지 3,535개 PR을 리뷰했고, 68% resolution rate를 기록했습니다. 동시에 GitHub는 이 시스템을 접근성의 "완전 자동 해결책"으로 포장하지 않았습니다. 오히려 복잡한 코드는 건드리지 않게 만들고, 고위험 패턴에서는 코드 생성을 멈추게 하며, 자동화로 발견할 수 없는 WCAG 영역을 분명하게 인정합니다.
이 점이 이번 발표의 핵심입니다. AI 에이전트의 다음 전장은 더 많은 코드를 생성하는 능력이 아니라, 언제 생성하지 말아야 하는지 아는 운영 구조입니다.
3,535개 PR을 본 접근성 리뷰어
GitHub의 접근성 에이전트는 두 가지 목표를 가집니다. 첫째, 엔지니어가 작업 중인 자리에서 접근성 질문에 답합니다. 둘째, 프런트엔드 코드 변경을 자동 평가해 간단한 접근성 문제를 production 전에 잡습니다.
공식 블로그에서 GitHub는 지금까지 에이전트가 리뷰한 PR이 3,535개라고 밝혔습니다. 이 PR에서 가장 자주 등장한 문제 유형은 다섯 가지입니다.
- 보조 기술이 구조와 관계를 이해할 수 있게 만드는 문제
- 인터랙티브 컨트롤에 명확하고 간결한 이름을 제공하는 문제
- 중요한 알림을 사용자가 인지할 수 있게 하는 문제
- 비텍스트 콘텐츠에 대체 텍스트를 제공하는 문제
- 키보드 포커스가 페이지와 뷰를 논리적 순서로 이동하게 하는 문제
이 목록은 접근성 자동화가 어디서 효과를 내기 쉬운지 보여줍니다. 버튼 이름, 이미지 대체 텍스트, DOM 순서와 시각적 순서의 불일치처럼 코드 diff에서 비교적 명확히 드러나는 문제는 에이전트가 개입하기 좋습니다. 반대로 전체 사용자 흐름, 복잡한 위젯 상호작용, 디자인 의도는 여전히 어렵습니다.
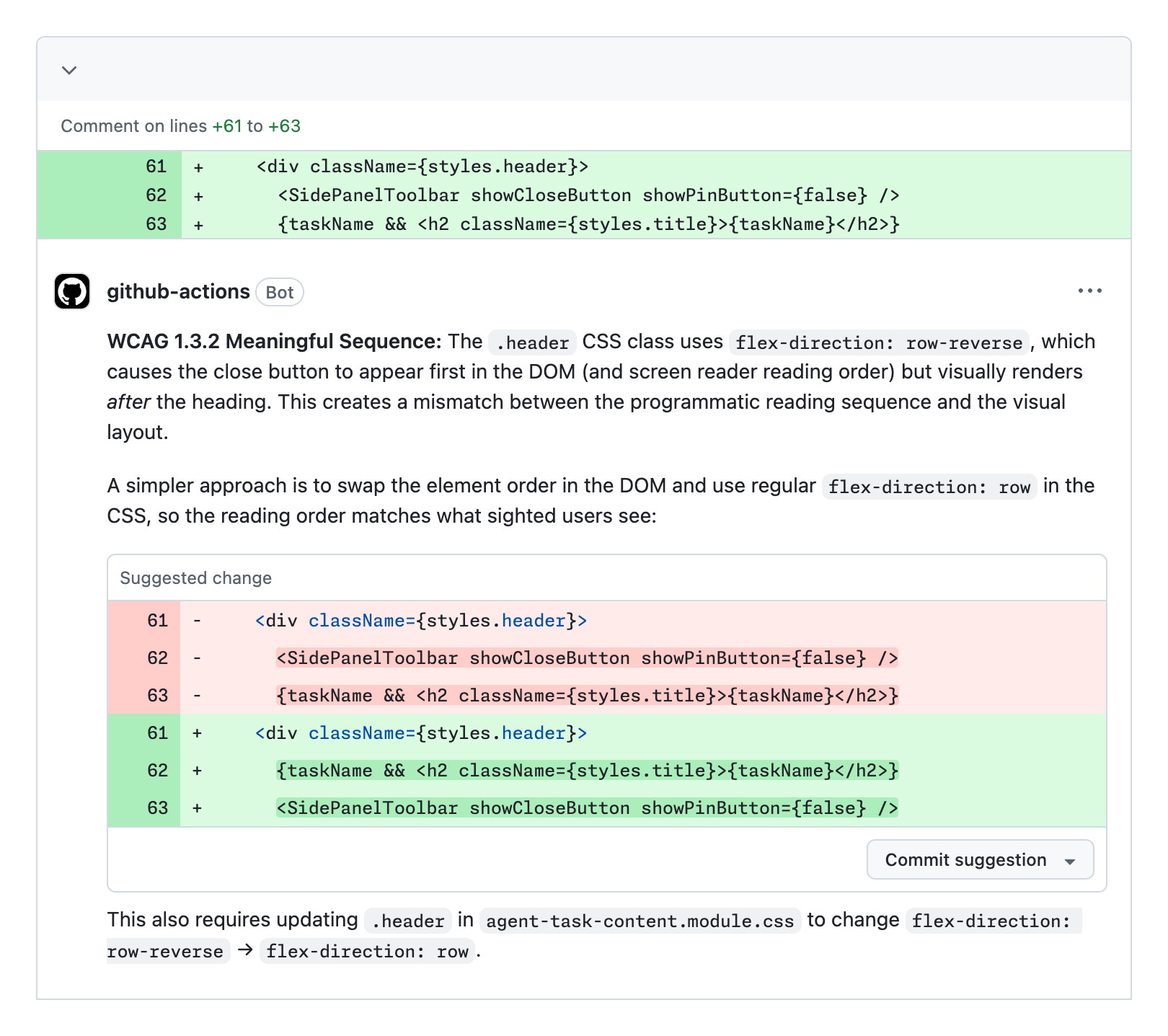
위 스크린샷은 GitHub가 공개한 실제 동작 예시입니다. 에이전트는 flex-direction: row-reverse 때문에 DOM 순서와 화면상 순서가 어긋나는 문제를 지적합니다. 시각적으로는 제목 뒤에 닫기 버튼이 오지만, screen reader의 읽기 순서에서는 닫기 버튼이 먼저 등장할 수 있다는 판단입니다. 그리고 CSS만 바꾸는 것이 아니라 DOM 요소 순서를 조정하라는 코드 제안까지 냅니다.
이런 사례는 AI 접근성 리뷰의 장점을 잘 보여줍니다. 일반적인 정적 분석기는 특정 속성 누락은 잘 찾지만, "보이는 순서와 읽히는 순서의 불일치"처럼 코드 구조와 사용자 경험을 함께 봐야 하는 문제에서는 맥락이 부족할 수 있습니다. LLM 에이전트는 코드, 설명, 조직의 과거 접근성 이슈, WCAG 문서를 함께 읽으며 좀 더 문맥적인 판단을 시도할 수 있습니다.
그렇다고 이 사례가 "접근성 자동화가 해결됐다"는 뜻은 아닙니다. GitHub가 강조하는 포인트는 정반대에 가깝습니다. 이 에이전트는 접근성 팀을 대체하지 않습니다. 기존 접근성 팀이 쌓아둔 지식과 이슈 기록을 이용해, 반복적인 문제를 더 빨리 발견하게 하는 보강 계층입니다.
왜 접근성은 AI 코드 리뷰의 좋은 시험대인가
접근성은 AI 에이전트에게 까다로운 영역입니다. 문법적으로 맞는 HTML이나 React 컴포넌트가 실제로 접근 가능한 경험을 만들지는 않습니다. aria-label이 있다고 해서 좋은 이름이라는 뜻도 아니고, keyboard handler가 있다고 해서 키보드 사용자에게 자연스러운 흐름이 보장되는 것도 아닙니다.
더 큰 문제는 접근성이 코드만의 문제가 아니라는 점입니다. 접근성은 디자인, 카피라이팅, 정보 구조, 상태 변화, 포커스 관리, 오류 메시지, 보조 기술 지원이 함께 만드는 결과입니다. GitHub도 이 지점을 분명히 말합니다. 접근성 작업은 전체 그림을 알아야 하는 경우가 많고, 그 때문에 범용 접근성 에이전트는 토큰을 많이 쓰고, 느려지고, 비용이 커질 수 있습니다.
이 지점에서 GitHub의 접근은 흥미롭습니다. 많은 에이전트 설계 논의는 더 많은 sub-agent를 병렬로 붙이고, 각자 전문 영역을 맡기는 방향으로 흘러갑니다. 그러나 GitHub는 접근성 에이전트에서 그 방식이 잘 맞지 않았다고 설명합니다. 병렬성이 항상 좋은 것은 아니었습니다.
GitHub가 선택한 구조는 두 개의 전용 sub-agent입니다. 하나는 수동 리뷰어이자 리서처입니다. 다른 하나는 능동 구현자입니다. 부모 에이전트는 이 둘 사이에서 라우팅, 코드와 skill 탐색, 복잡도 점수 계산, 출력 검증, escalation gate, 재감사 루프를 맡습니다. 두 sub-agent는 서로 직접 내용을 주고받지 않고, 구조화된 템플릿 출력만 부모 에이전트로 전달합니다.
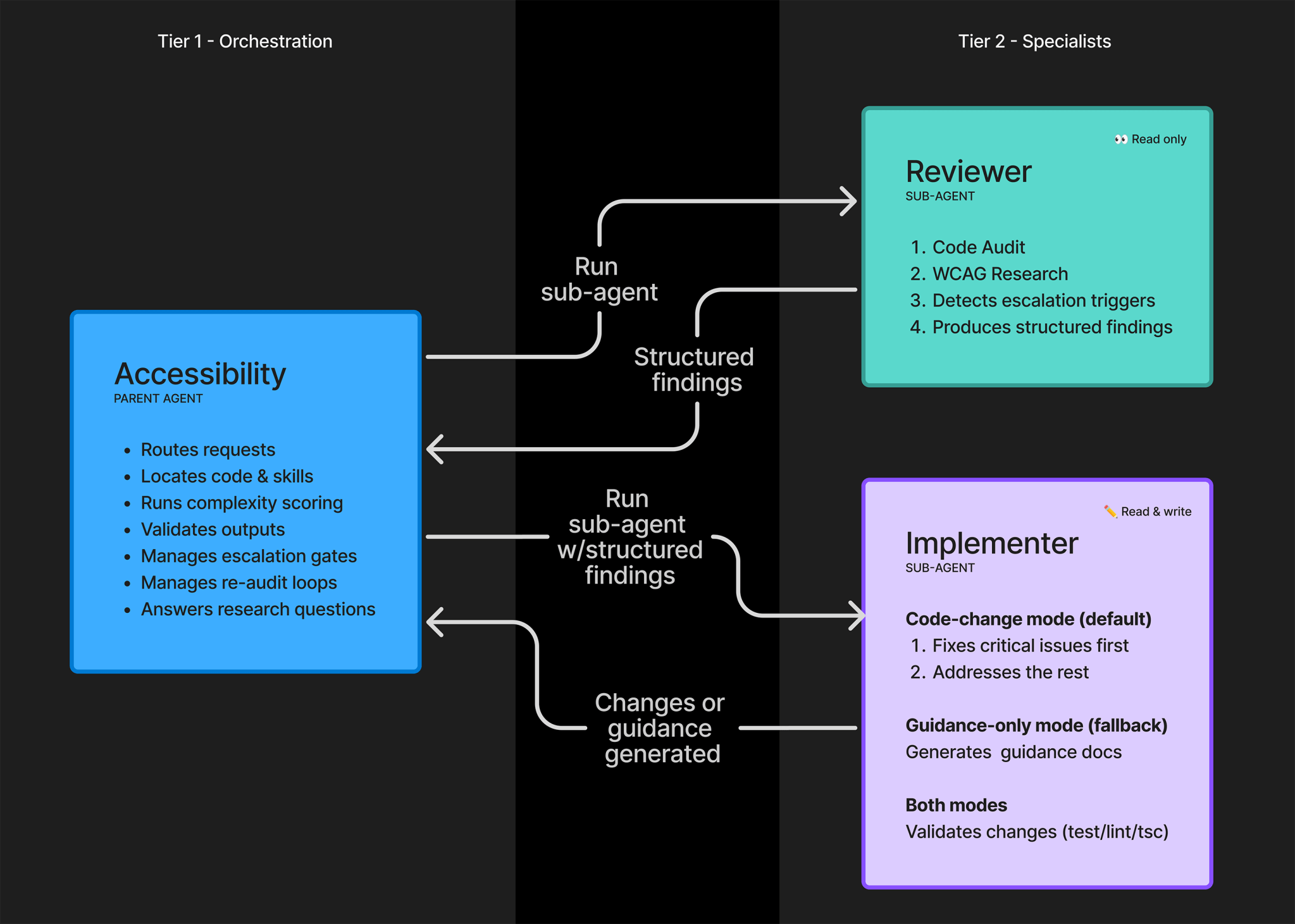
이 설계는 속도보다 감사 가능성을 우선합니다. 접근성 문제는 "대충 고쳤다"가 통하지 않습니다. 잘못된 자동 수정은 사용자를 더 어렵게 만들고, 나중에 더 비싼 재작업으로 돌아옵니다. 그래서 GitHub는 sub-agent끼리 자유롭게 대화시키는 대신, 누가 무엇을 판단했는지 추적 가능한 형태로 남기는 방식을 택했습니다.
이것은 AI 에이전트 운영 전반에도 중요한 힌트를 줍니다. 복잡한 조직 업무에서는 에이전트의 "자율성"보다 결정의 경로를 남기는 것이 더 중요할 수 있습니다. 특히 접근성, 보안, 법무, 개인정보처럼 실패 비용이 큰 영역에서는 빠른 병렬 실행보다 선형 절차와 템플릿이 더 현실적인 선택입니다.
오래된 접근성 이슈가 에이전트의 데이터가 됐다
GitHub가 이번 파일럿에서 얻은 중요한 교훈 중 하나는 "좋은 skill 파일만으로는 부족하다"는 점입니다. "접근성 best practice를 따르라"는 식의 막연한 지시는 잘 작동하지 않습니다. GitHub는 LLM이 수십 년간 축적된 접근성 낮은 코드에서 학습됐기 때문에, 접근성 antipattern을 생성하는 경향이 있다고 지적합니다.
그래서 GitHub가 활용한 자산은 내부 접근성 이슈 기록입니다. 이 기록에는 문제 보고 템플릿, 재현 단계, 심각도, 서비스 영역, 적용되는 WCAG success criterion, 수정 PR, acceptance criteria가 구조적으로 들어 있습니다. 이 자료는 LLM이 조직의 실제 UI 관행과 과거 수정 사례를 참고하는 데 쓰입니다.
여기서 중요한 것은 데이터의 성격입니다. 범용 웹 문서나 공개 WCAG 설명만으로는 "우리 제품의 이 컴포넌트에서 어떤 수정을 선호하는가"를 알기 어렵습니다. 반면 과거에 인간 접근성 전문가가 검토하고 수정한 이슈와 PR은 조직 맥락이 들어 있는 고품질 예제입니다.
즉, GitHub 접근성 에이전트의 성능은 모델만의 문제가 아닙니다. 조직이 이전에 얼마나 잘 기록하고, 분류하고, 검증했는지가 에이전트의 품질을 결정합니다. 이것은 최근 기업 AI 도입에서 반복해서 등장하는 패턴입니다. AI 에이전트는 지식 관리가 잘 된 조직에서 더 잘 작동합니다. 반대로 문서와 이슈 기록이 흩어져 있으면, 에이전트는 일반론만 반복하거나 부정확한 수정을 제안하기 쉽습니다.
접근성은 이 사실을 더 선명하게 보여줍니다. 접근성 문제는 법규와 표준을 따르지만, 실제 해결 방식은 제품의 컴포넌트 구조, 디자인 시스템, 사용자 흐름에 깊게 묶여 있습니다. "버튼에 이름을 붙이라"는 원칙은 보편적이지만, 어떤 이름이 명확한지는 제품 언어와 사용자 맥락이 결정합니다.
68% 해결률보다 중요한 멈춤 조건
GitHub 발표에서 가장 실무적인 대목은 한계 처리입니다. 접근성 에이전트는 모든 문제를 고치도록 설계되지 않았습니다. 복잡도 점수가 일정 기준을 넘으면 코드 변경을 하지 않고, 사용자가 접근성 팀과 상담하라고 안내합니다.
또한 에이전트는 고위험 패턴에서 코드 생성을 피하도록 설정됐습니다. GitHub가 예로 든 패턴은 drag and drop, toast, rich text editor, tree view, data grid입니다. 이들은 보조 기술과의 상호작용, 키보드 조작, 상태 알림, 포커스 이동, ARIA 역할이 복잡하게 얽힙니다. 자동 검사에서 통과해도 실제 사용자에게는 사용할 수 없는 UI가 될 수 있습니다.
이 판단은 AI 에이전트 제품화에서 매우 중요합니다. 많은 코딩 에이전트는 "어떻게든 수정안을 내는" 방향으로 최적화됩니다. 사용자는 답을 기대하고, 모델은 코드를 생성합니다. GitHub는 이 bias to action을 별도 문제로 다룹니다. 에이전트가 인간 전문가가 필요한 상황에서도 몰래 우회해 코드를 만들지 않도록 anti-gaming 지시를 넣었다고 설명합니다.
여기서 보이는 원칙은 명확합니다. 좋은 품질 보증 에이전트는 항상 수정하는 에이전트가 아닙니다. 좋은 에이전트는 다음 세 가지를 구분해야 합니다.
- 자동으로 고칠 수 있는 문제
- 문제는 감지했지만 guidance만 줘야 하는 문제
- 인간 전문가에게 escalation해야 하는 문제
AI 도구가 성숙해질수록 세 번째 범주의 중요성이 커집니다. "이건 내가 처리할 수 없습니다"라는 답변은 제품 데모에서는 매력적이지 않을 수 있습니다. 그러나 실제 조직에서는 그 대답이 잘못된 자동 수정 하나보다 훨씬 가치 있습니다.
WCAG의 36%는 자동화 밖에 남아 있다
GitHub가 제시한 또 다른 숫자는 55와 35입니다. WCAG level A와 AA success criterion은 총 55개이며, 그중 35개만 deterministic automated code checker로 감지할 수 있다고 설명합니다. 다시 말해 약 36%는 자동 검사만으로 발견할 수 없습니다.
이 숫자는 접근성 에이전트의 위치를 정하는 데 중요합니다. LLM 기반 에이전트는 이 36%의 일부에 접근할 수 있습니다. 코드와 UI 맥락을 읽고, 과거 이슈를 참고하고, 보조 기술 경험을 추론하며, 정적 분석보다 넓은 판단을 시도할 수 있기 때문입니다. 하지만 GitHub도 이것을 완벽한 과학으로 보지 않습니다.
특히 많은 접근성 문제는 design과 prototyping 단계에서 시작됩니다. 컴포넌트를 구현한 뒤에 에이전트가 PR에서 문제를 찾는 것은 유용하지만, 그 시점에는 이미 정보 구조와 상호작용 모델이 굳어졌을 수 있습니다. GitHub가 접근성 팀과 디자이너의 조기 협업을 강조하는 이유입니다.
AI 에이전트는 이 문제를 완전히 없애지 못합니다. 오히려 잘못 쓰면 "PR에서 에이전트가 봐줄 테니 나중에 고치면 된다"는 착각을 만들 수 있습니다. 접근성은 나중에 덧붙이는 장식이 아니라 제품 구조입니다. 에이전트는 그 구조를 늦게라도 감지할 수 있지만, 구조 자체를 대신 설계하지는 못합니다.
Copilot의 경쟁 무대가 코드 생성에서 품질 체계로 이동한다
이번 발표는 GitHub Copilot의 경쟁 무대가 어디로 이동하는지도 보여줍니다. 초기 Copilot 경쟁은 코드 완성, 함수 생성, 테스트 작성이 중심이었습니다. 최근에는 agent mode, PR 생성, 이슈 처리, CLI, mobile, cloud agent처럼 실행 환경이 중요해졌습니다. 이제 GitHub는 접근성이라는 품질 보증 영역에서 Copilot을 조직 프로세스에 붙이고 있습니다.
이 흐름은 보안 쪽 Copilot Autofix와도 닮아 있습니다. 보안 취약점과 접근성 문제는 모두 "나중에 발견하면 비싸고, 초기에 잡으면 싸다"는 특성이 있습니다. 또한 둘 다 전문가 지식과 표준, 조직별 예외, 감사 가능성이 필요합니다. 따라서 AI 에이전트가 이 영역에 들어가려면 단순한 코드 생성보다 훨씬 엄격한 운영 설계가 필요합니다.
GitHub 접근성 에이전트의 의미는 "Copilot이 접근성을 고친다"가 아닙니다. 더 정확히 말하면, Copilot이 조직의 품질 체계 안으로 들어가고 있다는 신호입니다. PR마다 반복되는 접근성 문제를 잡고, 과거 이슈를 참조하고, reviewer sentiment를 수집하고, 잘못된 동작을 다시 지시로 보정합니다. 이것은 일회성 챗봇이 아니라 지속적으로 조정되는 운영 시스템입니다.
개발팀 입장에서는 질문이 바뀝니다. "우리도 AI 접근성 에이전트를 붙일 수 있나?"보다 먼저 물어야 할 것은 "우리에게 에이전트가 배울 수 있는 접근성 기록이 있나?"입니다. 과거 접근성 이슈가 흩어져 있고, 수정 PR이 연결돼 있지 않고, acceptance criteria가 없으면 에이전트는 일반적인 WCAG 요약 이상의 일을 하기 어렵습니다.
한국 개발팀에 주는 실무적 의미
한국 개발팀에도 이 발표는 직접적인 의미가 있습니다. 2025년 이후 국내에서도 금융, 공공, 커머스, 교육 서비스의 접근성 요구가 강해지고 있습니다. 동시에 프런트엔드 배포 속도는 빨라졌고, 디자인 시스템 위에 수많은 제품 화면이 빠르게 쌓입니다. 접근성 전문가는 늘 부족합니다.
이 상황에서 AI 접근성 에이전트는 매력적으로 보일 수 있습니다. 하지만 GitHub 사례가 보여주는 순서는 반대입니다. 먼저 접근성 이슈를 구조적으로 기록해야 합니다. 어떤 화면에서 문제가 있었는지, 어떤 WCAG 기준과 연결되는지, 어떤 PR에서 어떻게 고쳤는지, 실제 보조 기술 검증은 통과했는지 남겨야 합니다. 그 기록이 있어야 에이전트가 조직에 맞는 판단을 합니다.
또한 에이전트를 도입한다면 처음부터 "자동 수정"을 전면에 두기보다, 리뷰 보조와 guidance부터 시작하는 것이 현실적입니다. 단순한 대체 텍스트 누락, 버튼 이름, DOM 순서 문제처럼 비교적 객관적인 영역은 자동 제안으로 처리할 수 있습니다. 반대로 data grid, rich text editor, 복잡한 modal flow, drag and drop은 사람이 설계해야 합니다.
이것은 보수적인 접근이 아닙니다. 오히려 AI 에이전트를 오래 쓰기 위한 조건입니다. 접근성 도구가 한 번 신뢰를 잃으면 개발자는 코멘트를 무시하기 시작합니다. 정확도보다 더 중요한 것은 신뢰 가능한 범위 설정입니다.
다음 단계는 오픈소스화 여부
GitHub는 이 접근성 에이전트를 언젠가 오픈소스화하길 희망한다고 밝혔습니다. 아직은 파일럿이고, 내부 자료와 조직 프로세스에 강하게 의존합니다. 따라서 그대로 공개되더라도 다른 조직이 즉시 같은 성과를 내기는 어렵습니다.
하지만 설계 원칙은 이미 참고할 수 있습니다.
- 접근성 이슈와 수정 PR을 구조화된 corpus로 만든다.
- 에이전트는 단일 거대 프롬프트가 아니라 역할이 분리된 구조로 둔다.
- sub-agent 출력은 템플릿으로 제한해 감사 가능하게 만든다.
- 복잡도와 고위험 패턴을 기준으로 코드 생성을 중단한다.
- 자동화로 못 잡는 WCAG 영역을 명시하고 인간 검토를 유지한다.
- reviewer sentiment와 수동 검토 결과를 다시 지시와 자료에 반영한다.
이 원칙은 접근성에만 국한되지 않습니다. 보안 리뷰, 개인정보 검토, 성능 예산, 디자인 시스템 준수, 법무 문구 검토에도 비슷하게 적용됩니다. AI 에이전트를 전문 업무에 붙이는 순간, 중요한 것은 "모델이 똑똑한가"보다 "조직의 판단 기준을 어떻게 구조화했는가"입니다.
GitHub 접근성 에이전트 파일럿은 화려한 제품 출시가 아닙니다. 오히려 좋은 자동화가 얼마나 많은 수동 지식, 멈춤 조건, 감사 경로 위에 서 있는지 보여주는 사례입니다. 3,535개 PR과 68% 해결률은 성과입니다. 하지만 이 발표에서 더 오래 남을 숫자는 36%일 수 있습니다. 자동화 밖에 남아 있는 영역을 인정하는 순간, AI 에이전트는 비로소 실제 품질 시스템의 일부가 됩니다.