Gemma 4가 토큰을 미리 읽는다, 로컬 AI 속도전의 시작
Google이 Gemma 4용 MTP drafter를 공개했습니다. 최대 3배 빠른 추론이 로컬 LLM과 AI 에이전트 배포에 주는 의미를 짚습니다.

- 무슨 일: Google이
Gemma 4계열용 MTP drafter를 공개했습니다.- 작은 drafter가 여러 토큰을 먼저 제안하고, 원래 모델이 병렬 검증하는 speculative decoding 구조입니다.
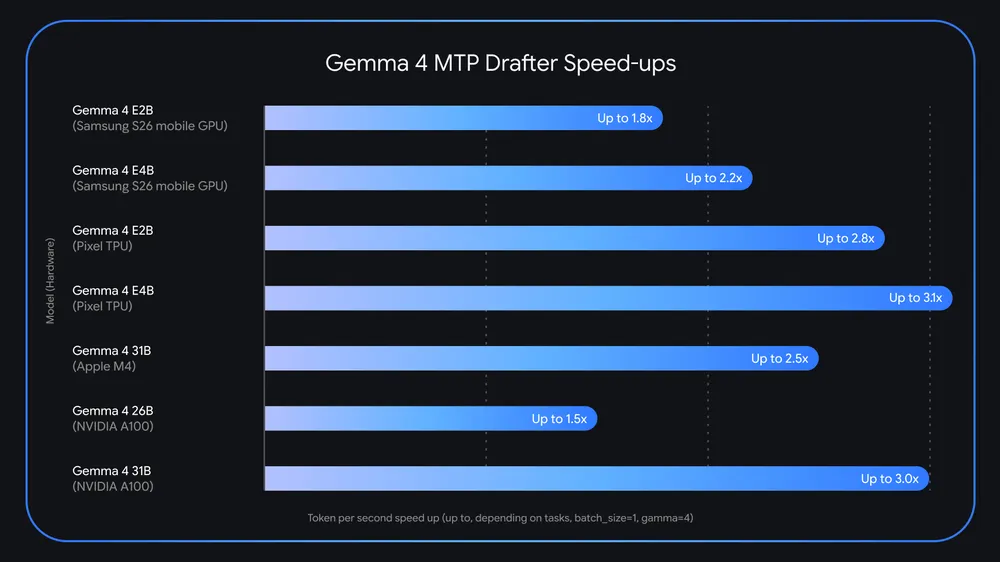
- 숫자: Google은 최대 3배 속도 향상과 품질 저하 없음, Apache 2.0 배포를 제시했습니다.
- 의미: 로컬 LLM 경쟁의 초점이 모델 크기에서
latency, 런타임, 하드웨어 조합으로 이동합니다. - 주의점: 실제 체감 속도는 acceptance rate, 메모리 여유, batch size, 런타임 지원 성숙도에 달려 있습니다.
Google이 2026년 5월 5일 Gemma 4 계열용 Multi-Token Prediction, 줄여서 MTP drafter를 공개했습니다. 표면적으로는 "Gemma 4가 최대 3배 빨라졌다"는 속도 업데이트입니다. 하지만 개발자 관점에서 더 중요한 변화는 로컬 LLM과 AI 에이전트의 병목을 다루는 방식입니다. 모델을 더 크게 만들거나 더 비싼 GPU를 붙이는 대신, 큰 모델이 한 토큰씩 답을 내놓는 시간을 작은 drafter와 병렬 검증 구조로 줄이려는 시도입니다.
공식 발표에서 Google은 Gemma 4가 공개된 지 몇 주 만에 6천만 다운로드를 넘겼다고 설명합니다. Gemma 4는 Google DeepMind의 오픈 웨이트 모델 계열이고, 개발자 워크스테이션, 모바일 기기, 클라우드 배포를 동시에 겨냥합니다. 이번 MTP 공개는 그 다음 단계입니다. 모델 자체의 지능을 다시 발표한 것이 아니라, 이미 배포된 Gemma 4를 더 빠르게 서빙하고 더 짧은 대기 시간으로 쓰게 만드는 추론 계층의 업데이트입니다.
병목은 지능이 아니라 토큰 대기 시간입니다
LLM을 제품에 넣어본 팀이라면 "모델이 똑똑한가"와 "사용자가 기다릴 만한가"가 다른 질문이라는 점을 압니다. 채팅 UI에서는 첫 토큰까지의 지연이 중요하고, 음성 에이전트에서는 중간 침묵이 바로 품질 저하로 느껴집니다. 코딩 에이전트나 연구 에이전트처럼 여러 단계를 반복하는 시스템에서는 한 번의 응답 지연이 루프 전체 시간으로 증폭됩니다.
표준 autoregressive inference는 본질적으로 순차적입니다. 모델은 이전 토큰을 보고 다음 토큰을 하나 생성합니다. 다시 그 토큰을 문맥에 붙이고 다음 토큰을 생성합니다. 이 방식은 단순하고 강력하지만, 매번 큰 모델 파라미터를 메모리에서 읽어 와야 합니다. Google은 공식 글에서 이 현실을 "memory-bandwidth bound"라고 설명합니다. 프로세서가 계산을 못 해서 느린 것이 아니라, 수십억 개 파라미터를 VRAM에서 compute unit으로 옮기는 시간이 병목이 됩니다.
이 병목은 로컬 배포에서 더 선명해집니다. 데이터센터 GPU에서는 네트워크, batch, 커널 최적화, 캐시 전략을 복잡하게 조합할 수 있습니다. 개인 워크스테이션, 노트북, 모바일 기기에서는 메모리 대역폭과 전력 예산이 훨씬 빡빡합니다. 그래서 로컬 모델이 "충분히 똑똑해졌다"는 순간 다음 질문은 바로 "충분히 빠른가"가 됩니다. Gemma 4 MTP drafter는 이 질문에 대한 Google의 답입니다.
MTP drafter는 큰 모델의 예고편을 먼저 만듭니다
MTP의 핵심 아이디어는 작은 모델이 몇 개의 미래 토큰을 먼저 제안하게 만드는 것입니다. 큰 Gemma 4 target model은 그 제안이 맞는지 병렬로 검증합니다. target model이 동의하면 여러 토큰을 한 번에 받아들이고, 동의하지 않는 지점에서는 다시 표준 생성으로 돌아갑니다. 사용자는 같은 큰 모델의 품질을 받지만, 쉬운 구간에서는 여러 토큰이 한 번에 지나갑니다.
입력 문맥과 현재까지 생성된 토큰
작은 MTP drafter가 여러 미래 토큰 후보를 빠르게 제안
Gemma 4 target model이 후보를 병렬 검증하고 승인된 토큰을 채택
승인된 구간은 한 번에 출력, 불일치 지점부터 다시 생성
이 구조는 완전히 새로운 연구가 아닙니다. Google 연구진은 2022년 arXiv 논문 "Fast Inference from Transformers via Speculative Decoding"에서 작은 근사 모델과 큰 모델의 병렬 검증으로 출력 분포를 바꾸지 않고 2~3배 가속할 수 있음을 보였습니다. 이번 발표의 차이는 연구 아이디어가 Gemma 4 공개 모델 생태계에 맞춰 배포 가능한 drafter checkpoint로 내려왔다는 점입니다.
Hugging Face의 google/gemma-4-E4B-it-assistant 모델 카드도 같은 구조를 확인합니다. 이 모델 카드는 MTP drafter가 base model을 더 작고 빠른 draft model로 확장하며, speculative decoding pipeline에서 draft model이 여러 토큰을 예측하고 target model이 병렬 검증한다고 설명합니다. 라이선스는 Gemma 4와 같은 Apache 2.0입니다. 즉, 단순 데모가 아니라 개발자가 실제 런타임에 붙여 볼 수 있는 배포 단위입니다.
왜 "최대 3배"라는 숫자는 조심해서 읽어야 하나
Google은 이번 MTP drafter가 최대 3배 속도 향상을 낸다고 말합니다. 동시에 발표문 안에는 더 현실적인 단서도 들어 있습니다. 예를 들어 26B mixture-of-experts 모델은 Apple Silicon에서 batch size 1일 때 routing challenge가 있고, batch size 4~8처럼 여러 요청을 동시에 처리할 때 최대 약 2.2배 로컬 속도 향상을 열 수 있다고 설명합니다. Nvidia A100에서도 batch size 증가에 따른 비슷한 이득을 관찰했다고 합니다.
이 말은 "모든 기기에서 항상 3배"가 아니라는 뜻입니다. speculative decoding의 속도 향상은 drafter가 얼마나 자주 맞히는지, drafter와 target model을 함께 올릴 메모리가 있는지, KV cache 공유가 얼마나 잘 구현됐는지, 런타임이 해당 구조를 얼마나 효율적으로 처리하는지에 달려 있습니다. 쉬운 문장 계속 생성처럼 예측 가능한 구간에서는 이득이 커질 수 있고, 어려운 추론이나 불안정한 샘플링 구간에서는 acceptance rate가 낮아져 이득이 줄어듭니다.
그래도 방향은 분명합니다. 이제 오픈 웨이트 모델 경쟁은 "파라미터 수와 벤치마크 점수"만의 싸움이 아닙니다. 같은 모델을 어떤 decoding 전략과 런타임으로 배포하느냐가 사용자 경험을 바꿉니다. 작은 모델이 큰 모델의 앞길을 미리 읽고, 큰 모델이 final authority로 남는 구조는 품질 책임과 속도 개선을 분리합니다.
로컬 AI에서 이 업데이트가 중요한 이유
로컬 LLM은 지난 1년 동안 두 방향으로 진화했습니다. 하나는 모델 품질입니다. 작은 모델이 더 긴 context, 더 나은 reasoning, 더 나은 multimodal 입력을 지원하게 됐습니다. 다른 하나는 런타임입니다. MLX, vLLM, SGLang, Ollama, llama.cpp 계열, 모바일용 LiteRT 같은 실행 환경이 빠르게 발전했습니다. Gemma 4 MTP는 두 번째 흐름에 더 가깝습니다.
Google 발표는 MTP drafter를 Hugging Face와 Kaggle에서 받을 수 있고, Transformers, MLX, vLLM, SGLang, Ollama, Google AI Edge Gallery(Android/iOS)에서 실험할 수 있다고 안내합니다. 이 나열이 중요합니다. 모델 발표가 실제 개발자 경험으로 이어지려면 checkpoint만으로는 부족합니다. 팀은 이미 쓰는 serving stack에 붙일 수 있어야 하고, 디버깅할 수 있어야 하며, fallback도 있어야 합니다.
특히 AI 에이전트에서는 토큰 속도가 비용과 안정성에 연결됩니다. 에이전트는 사용자에게 한 번 답하고 끝나는 시스템이 아닙니다. 계획을 세우고, 도구를 호출하고, 결과를 읽고, 다시 계획을 고칩니다. 이 루프가 10번 돌면 응답 지연은 10배로 누적됩니다. 로컬 코딩 에이전트가 파일을 읽고, 테스트 결과를 요약하고, 패치를 설명하는 과정에서도 같은 일이 일어납니다. 한 단계당 몇 초씩 줄어드는 차이가 전체 작업 시간에서는 크게 보입니다.
또 하나의 의미는 개인정보와 비용입니다. 로컬 모델을 빠르게 만들 수 있으면 일부 업무는 클라우드 모델로 보내지 않아도 됩니다. 사내 코드, 문서, 로컬 파일처럼 외부 API 전송이 부담스러운 데이터에 대해 더 현실적인 선택지가 생깁니다. 물론 Gemma 4가 모든 프론티어 모델을 대체한다는 뜻은 아닙니다. 다만 로컬 모델이 "느려서 못 쓰겠다"는 구간이 줄어들면, 팀은 업무별로 클라우드 모델과 로컬 모델을 더 정교하게 나눌 수 있습니다.
Hugging Face 모델 카드가 말하는 배포 맥락
Hugging Face 모델 카드는 이번 drafter가 단순 속도 패치가 아니라 Gemma 4 계열의 배포 전략과 붙어 있음을 보여줍니다. Gemma 4는 dense와 mixture-of-experts 구조를 모두 포함하고, E2B, E4B, 26B A4B, 31B 같은 크기 구성을 가집니다. 모델 카드는 작은 모델은 모바일과 엣지 장치, 큰 모델은 consumer GPU와 워크스테이션을 겨냥한다고 설명합니다.
이 구성에서 MTP drafter는 모델 크기별로 다른 의미를 가집니다. E2B와 E4B 같은 edge model에서는 배터리와 발열, 첫 토큰 지연이 중요합니다. 26B A4B와 31B에서는 개인 워크스테이션에서 "쓸 만한 속도"를 만드는 것이 중요합니다. Google은 E2B/E4B에서 final logit calculation 병목을 줄이기 위해 embedder clustering도 적용했다고 설명합니다. 작은 모델이라고 병목이 사라지는 것이 아니기 때문입니다.
개발자에게는 이 지점이 실무 체크리스트가 됩니다. 단순히 "MTP를 켜면 빠르다"가 아니라, target model과 matching drafter가 맞는지, 런타임이 해당 architecture를 지원하는지, quantization과 cache 설정이 호환되는지 확인해야 합니다. 특히 로컬 배포에서는 main model과 draft model을 동시에 다뤄야 하므로, VRAM과 system RAM 여유가 속도 향상보다 먼저 발목을 잡을 수 있습니다.
커뮤니티는 빠르게 실험하지만 검증 기준은 아직 정리 중입니다
LocalLLaMA 커뮤니티에서는 발표 직후 llama.cpp 계열 실험과 GGUF 변환 이야기가 올라왔습니다. 한 게시글은 MacBook Pro M5 Max에서 Gemma 26B가 MTP 적용 전 97 tokens/s, 적용 후 138 tokens/s를 기록해 약 40% 빨라졌다고 보고했습니다. 이 숫자는 Google의 최대 3배와 다르지만, 오히려 현실적인 신호로 볼 수 있습니다. 런타임, quantization, hardware, prompt, sampling 설정에 따라 결과가 크게 달라진다는 뜻입니다.
흥미로운 것은 댓글의 관심이 단순 속도 자랑에 머물지 않았다는 점입니다. 한 사용자는 같은 seed와 temperature 0.0 조건에서 결과가 동일한지 비교해야 품질 저하가 없다는 주장을 검증할 수 있다고 지적했습니다. 게시자는 실제 모델 답변은 매번 달라질 수 있어 judge가 필요하다고 답했습니다. 이 대화는 speculative decoding이 제품팀에 던지는 질문을 잘 보여줍니다. "빠르다"는 것과 "동일한 품질이다"는 것은 별도로 검증해야 합니다.
Google의 공식 주장은 target model이 최종 검증을 하기 때문에 output quality와 reasoning logic이 유지된다는 것입니다. 논문적으로도 speculative decoding은 큰 모델의 분포를 보존할 수 있습니다. 하지만 제품 관찰에서는 sampling 설정, 구현 세부, quantization, fallback 처리, tokenizer 차이가 모두 영향을 줄 수 있습니다. 따라서 프로덕션 팀은 "MTP 사용 여부"를 feature flag로 관리하고, latency, acceptance rate, error, 사용자 만족 지표를 함께 봐야 합니다.
경쟁은 모델보다 런타임 쪽에서 더 거칠어집니다
최근 오픈 모델 생태계는 모델 발표만큼이나 런타임 발표가 중요해졌습니다. Qwen, GLM, Nemotron, Gemma 같은 모델들이 서로 다른 구조와 decoding 전략을 내놓고, vLLM, SGLang, MLX, Ollama, llama.cpp 계열은 이를 빠르게 흡수합니다. 어떤 모델이 더 좋은가라는 질문은 이제 어떤 런타임에서 어떤 quantization으로 어떤 batch 조건에서 돌리는가라는 질문으로 분해됩니다.
MTP drafter는 이 경쟁을 더 복잡하게 만듭니다. target model만 비교하던 시절에는 모델 파일 하나와 벤치마크 하나로 어느 정도 대화가 가능했습니다. 이제는 target model, drafter, cache sharing, draft length, acceptance policy, memory layout, hardware backend가 한 묶음입니다. 좋은 조합을 찾으면 체감 속도는 크게 좋아질 수 있지만, 나쁜 조합에서는 메모리만 더 쓰고 이득이 작을 수 있습니다.
그래서 이번 뉴스의 실무적 결론은 "Gemma 4가 무조건 3배 빨라졌다"가 아닙니다. 더 정확한 결론은 "Google이 Gemma 4를 중심으로 로컬/엣지 추론 가속을 공식 배포 경로에 넣었다"입니다. 이는 모델 제공자가 이제 checkpoint뿐 아니라 추론 전략과 runtime adoption까지 같이 책임져야 한다는 신호입니다.
AI 에이전트에는 작은 지연도 큰 비용입니다
코딩 에이전트와 업무 에이전트에서 대기 시간은 UX 문제이면서 운영 비용 문제입니다. 에이전트가 한 번에 끝나는 답변을 만들 때보다, 여러 번의 생각과 도구 호출을 반복할 때 latency 개선 효과가 더 큽니다. 예를 들어 에이전트가 코드베이스를 읽고, 테스트를 실행하고, 실패 로그를 분석하고, 패치를 작성하고, 다시 테스트하는 루프를 돈다면 각 단계의 토큰 생성 속도는 전체 완료 시간에 직접 영향을 줍니다.
음성 에이전트에서는 더 민감합니다. 사용자가 말한 뒤 1초 이상 침묵이 생기면 시스템이 망설이는 것처럼 느껴집니다. MTP 같은 drafter 구조는 쉬운 continuation을 빠르게 통과시켜 첫 응답과 중간 응답의 템포를 개선할 수 있습니다. Google이 공식 발표에서 near real-time chat, immersive voice applications, agentic workflows를 직접 언급한 이유도 여기에 있습니다.
다만 에이전트에서는 속도만으로 충분하지 않습니다. 빠른 모델이 도구 호출을 잘못하면 더 빠르게 잘못된 일을 합니다. 따라서 MTP는 planning 품질이나 tool-use 안정성을 대체하지 않습니다. 대신 이미 충분히 좋은 모델을 더 빠르게 응답하게 만드는 레이어입니다. 이 구분이 중요합니다. 제품팀은 MTP를 "더 똑똑한 모델"이 아니라 "같은 모델의 대기 시간을 줄이는 실행 전략"으로 이해해야 합니다.
앞으로 볼 지표
앞으로 Gemma 4 MTP의 실제 가치는 세 가지 지표에서 드러날 가능성이 큽니다. 첫째는 acceptance rate입니다. drafter가 제안한 토큰 중 target model이 얼마나 많이 받아들이는지가 속도 향상의 핵심입니다. 둘째는 memory overhead입니다. 작은 drafter라고 해도 target model과 함께 올라가야 하므로, 특히 노트북과 모바일에서는 메모리 사용량이 중요합니다. 셋째는 runtime portability입니다. 발표에는 여러 런타임이 나열돼 있지만, 각 런타임에서 같은 수준의 안정성과 사용 편의성을 보장하는지는 별개의 문제입니다.
개발자라면 자체 워크로드로 테스트해야 합니다. 제품의 prompt 길이, 출력 길이, temperature, batch 형태, 동시 사용자 수가 공개 벤치마크와 다르면 결과도 달라집니다. 특히 코딩 에이전트처럼 긴 context를 자주 쓰는 경우에는 KV cache와 메모리 압박이 속도 향상을 제한할 수 있습니다. 반대로 짧고 반복적인 응답, voice turn-taking, 자동완성, 단순 요약처럼 예측 가능한 토큰이 많은 구간에서는 이득이 더 클 수 있습니다.
이번 발표는 로컬 AI의 다음 병목을 분명하게 보여줍니다. 모델 품질이 올라가면 배포 기술이 곧 경쟁력이 됩니다. Gemma 4 MTP drafter는 그 경쟁이 이미 시작됐다는 신호입니다. 이제 좋은 로컬 AI 제품은 좋은 모델을 고르는 데서 멈추지 않습니다. target model과 drafter를 맞추고, 런타임을 고르고, 하드웨어별 acceptance rate와 latency를 측정하는 팀이 더 빠른 사용자 경험을 가져갈 것입니다.