Nature 두 편의 Gemini for Science, 연구 에이전트의 검증대
Google Gemini for Science는 가설, 코드, 문헌 분석을 묶고 Nature 논문 두 편으로 연구 에이전트 검증 경쟁을 열었습니다.

- 무슨 일: Google이 I/O 2026에서
Gemini for Science를 공개하고 과학 연구용 에이전트 실험 3종을 Labs로 열기 시작했습니다.Hypothesis Generation,Computational Discovery,Literature Insights가 각각 가설, 계산 실험, 문헌 분석을 맡습니다.
- 검증 신호: 같은 날
ERA와Co-Scientist논문이 Nature에 공개되며 데모가 아닌 연구 결과를 전면에 세웠습니다. - 개발자 의미: 과학 에이전트의 경쟁축은 모델 답변이 아니라 문헌 검색, 코드 생성, 실행, 평가를 잇는 하네스가 됐습니다.
- Google은
Science Skills를 Antigravity 같은 에이전트 플랫폼에 얹어 생명과학 데이터베이스와 도구 호출을 묶습니다.
- Google은
- 주의점: Labs와 trusted tester 중심의 초기 공개라 실제 연구 품질, 재현성, 책임 소재는 논문 밖 검증이 더 필요합니다.
Google이 2026년 5월 19일 Google I/O에서 Gemini for Science를 공개했습니다. 이름만 보면 Gemini를 과학용으로 포장한 제품처럼 들릴 수 있습니다. 하지만 이번 발표의 핵심은 단일 모델이 아닙니다. Google은 가설을 만들고, 계산 실험 코드를 생성하고, 문헌을 구조화하는 세 가지 실험 도구를 한 묶음으로 제시했습니다. 여기에 Google Antigravity에서 쓸 수 있는 Science Skills까지 붙였습니다.
더 중요한 신호는 발표와 같은 날 Nature 논문이 함께 나왔다는 점입니다. ERA 논문은 과학 소프트웨어를 쓰고 개선하는 AI 시스템을 다루고, Co-Scientist 논문은 과학 가설 생성을 위한 다중 에이전트 시스템을 다룹니다. Google은 Gemini for Science를 "과학자를 위한 챗봇"이 아니라 "과학 방법론의 여러 단계를 에이전트화하는 작업대"로 배치하고 있습니다.
이 차이는 AI 개발자에게 중요합니다. 최근 코딩 에이전트 경쟁은 IDE 안에서 파일을 읽고 테스트를 돌리는 수준을 넘어, 안전한 실행 환경과 도구 호출, 장기 상태, 평가 루프를 어떻게 묶을 것인가로 이동했습니다. 과학 연구도 비슷한 문제를 만납니다. 좋은 답변을 생성하는 모델보다, 어떤 논문을 근거로 삼았는지, 어떤 코드를 실행했는지, 어떤 기준으로 결과를 골랐는지, 실패한 가설을 어떻게 버렸는지가 더 중요해집니다. Gemini for Science는 그 흐름을 연구실 영역에서 보여주는 사례입니다.
세 가지 실험은 연구 과정을 나눈다
Google의 공식 발표는 Gemini for Science의 Google Labs 실험을 세 갈래로 나눕니다. 첫 번째는 Co-Scientist 기반의 Hypothesis Generation입니다. 연구자가 문제를 정의하면, 시스템은 과학 방법론을 흉내 내는 다중 에이전트 "idea tournament"로 가설을 생성, 토론, 평가합니다. Google은 이 과정에서 주장을 클릭 가능한 인용으로 검증한다고 설명합니다.
두 번째는 AlphaEvolve와 ERA를 기반으로 한 Computational Discovery입니다. 이는 단순히 코드를 생성하는 기능이 아닙니다. 과학자가 성공 지표를 주면, 에이전트가 가능한 모델링 접근을 탐색하고 코드를 만들고 평가하면서 더 나은 해법을 찾는 구조입니다. Google Research의 ERA 발표는 이 시스템이 문헌 검색, 코드 작성, 해법 탐색, 결과 평가를 결합한다고 설명합니다.
세 번째는 NotebookLM 기반의 Literature Insights입니다. 과학 문헌을 검색하고, 결과를 사용자 정의 속성이 있는 표로 구조화하고, 연구자가 만든 코퍼스 안에서 채팅과 보고서, 슬라이드, 인포그래픽, 오디오/비디오 개요를 만들 수 있게 하는 방향입니다. 이 부분은 가장 익숙해 보입니다. 이미 많은 연구자가 논문 요약 도구를 쓰고 있기 때문입니다. 다만 Google은 이를 단독 문헌 요약 도구가 아니라 가설 생성과 계산 실험 앞뒤에 놓이는 한 단계로 배치했습니다.
| 실험 도구 | 기반 시스템 | 연구 단계 | 개발자 관점의 핵심 |
|---|---|---|---|
| Hypothesis Generation | Co-Scientist | 문제 정의, 가설 생성, 검토 | 다중 에이전트 토론과 인용 기반 검증 |
| Computational Discovery | AlphaEvolve, ERA | 계산 실험, 코드 생성, 평가 | 목표 지표를 향한 탐색과 실행 루프 |
| Literature Insights | NotebookLM | 문헌 수집, 비교, 산출물 작성 | 코퍼스 기반 검색과 구조화된 결과 비교 |
| Science Skills | Antigravity, 생명과학 DB | 도구 호출, 데이터베이스 연결 | 에이전트가 쓸 수 있는 전문 도구 번들 |
이 표면만 보면 Google은 과학 연구 전체를 하나의 제품으로 덮으려는 것처럼 보입니다. 그러나 더 정확히 말하면, Google은 연구의 병목을 세분화하고 있습니다. 가설을 찾는 병목, 계산 실험을 반복하는 병목, 문헌을 비교하는 병목은 서로 다릅니다. 하나의 챗 인터페이스가 모두 해결한다고 말하는 대신, 각 단계에 맞는 에이전트형 도구를 붙이는 쪽에 가깝습니다.
ERA는 과학 코드를 쓰는 에이전트다
이번 발표에서 개발자가 특히 봐야 할 부분은 ERA입니다. Nature 초록에 따르면 ERA는 LLM과 tree search를 사용해 성공 지표를 최대화하는 과학 소프트웨어를 만듭니다. 일반 코딩 에이전트가 "테스트를 통과하는 패치"를 목표로 한다면, ERA는 "과학 실험의 품질 지표를 개선하는 코드"를 목표로 합니다. 목표 함수가 더 열려 있고, 평가 비용이 더 크며, 도메인 지식이 더 많이 필요합니다.
Google Research는 ERA가 생명정보학, 공중보건, 위성 이미지 분석, 신경 활동 예측, 시계열 예측, 수치 적분 같은 다양한 벤치마크에서 시험됐다고 설명합니다. Nature 초록은 단일세포 데이터 분석에서 ERA가 인간이 만든 상위 방법을 앞선 40개 신규 방법을 발견했고, COVID-19 입원 예측에서는 CDC ensemble과 다른 개별 모델을 앞선 14개 모델을 생성했다고 밝힙니다. 이 수치가 중요한 이유는 "좋은 답변"이 아니라 "반복 가능한 계산 결과"로 주장한다는 점입니다.
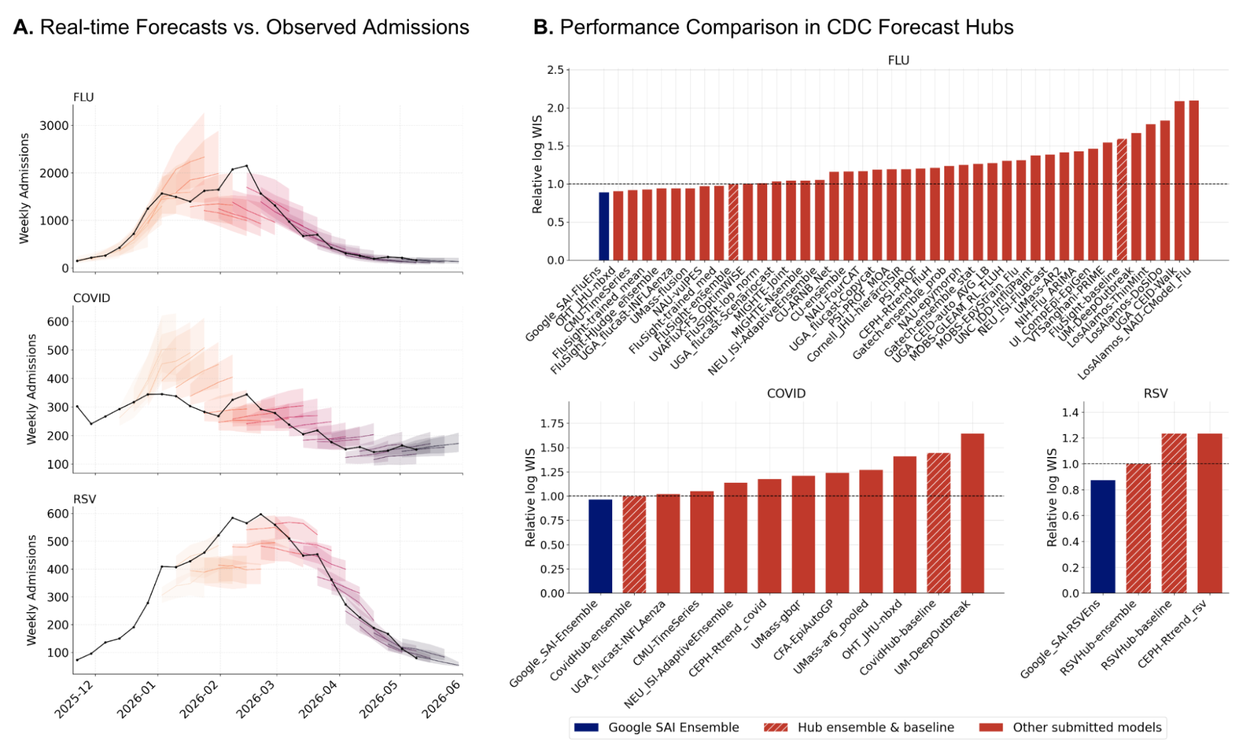
물론 이 결과를 곧바로 모든 과학 분야에 일반화할 수는 없습니다. Nature 페이지도 공개 원고가 최종 편집 전 버전이라고 안내합니다. 또한 특정 벤치마크에서 좋은 성과를 냈다는 사실과, 실제 연구 현장에서 신뢰할 수 있는 발견을 계속 만들어 낸다는 사실은 다릅니다. 하지만 개발자 관점에서 ERA가 던지는 질문은 분명합니다. 에이전트가 코드를 잘 쓰는지를 보려면 단위 테스트만으로 충분하지 않습니다. 평가 대상이 과학적 지표라면, 에이전트 하네스는 실험 설계, 데이터 접근, 계산 비용, 통계적 검증까지 품어야 합니다.
이 지점에서 ERA는 일반 코딩 에이전트보다 더 까다로운 형태의 코드 생성입니다. 웹앱 버그 수정은 대개 실패가 명확합니다. 빌드가 깨지거나, 테스트가 실패하거나, UI가 의도와 다르게 보입니다. 과학 코드는 실패가 더 느리고 더 애매합니다. 모델이 좋아 보이는 수치를 냈지만 데이터 누수가 있을 수 있고, 벤치마크에 과적합했을 수 있으며, 실제 현상과 맞지 않는 단순화가 숨어 있을 수 있습니다. 따라서 과학 에이전트의 핵심은 코드 작성 능력이 아니라 평가 체계와 검증 문화입니다.
Co-Scientist는 답변보다 토론 구조를 판다
Co-Scientist는 또 다른 방향을 보여줍니다. Google은 Hypothesis Generation이 연구자와 협업해 연구 과제를 정의하고, 여러 에이전트가 가설을 생성, 반성, 순위화, 진화시키는 구조로 설명합니다. 여기서 중요한 것은 "모델이 천재적 가설을 냈다"는 식의 서사가 아닙니다. Google이 강조하는 것은 아이디어를 생성한 뒤 서로 비판하고, 출처를 붙이고, 연구자가 검토할 수 있는 형태로 좁히는 프로세스입니다.
이 접근은 최근 에이전트 설계와 닮았습니다. 단일 프롬프트로 정답을 뽑는 대신, 역할이 다른 에이전트를 두고 중간 산출물을 평가합니다. 코딩 에이전트에서는 planner, executor, reviewer를 나누는 방식이 익숙해졌습니다. 과학 가설 생성에서는 generation, reflection, ranking, evolution 같은 역할이 비슷한 문제를 다룹니다. 틀린 가설을 그럴듯하게 쓰는 위험이 크기 때문에, 내부 비판과 외부 인용이 제품 기능의 일부가 됩니다.
다만 여기에도 한계가 있습니다. 인용이 있다고 해서 가설이 맞는 것은 아닙니다. 좋은 문헌 검색과 그럴듯한 조합은 출발점일 뿐입니다. 과학은 결국 실험과 재현을 요구합니다. Google이 Nature 논문과 100개 이상 기관의 검증 파트너를 함께 강조한 이유도 여기에 있습니다. AI가 과학자의 아이디어를 넓혀 줄 수 있다는 주장만으로는 부족합니다. 그 아이디어가 어떤 조건에서 유효했고, 어떤 실험으로 반박될 수 있는지가 제품 안팎에서 관리돼야 합니다.
Science Skills는 에이전트용 전문 도구 번들이다
Gemini for Science가 흥미로운 또 다른 이유는 Science Skills입니다. Google은 이 번들이 UniProt, AlphaFold Database, AlphaGenome API, InterPro 등 30개 이상 생명과학 데이터베이스와 도구의 인사이트를 통합한다고 밝혔습니다. 사용자는 이를 Google Antigravity 같은 에이전트 플랫폼에서 활용해 구조 생물정보학이나 유전체 분석 같은 수작업 워크플로를 빠르게 수행할 수 있습니다.
이 부분은 AI 인프라 관점에서 중요합니다. 범용 모델만으로 전문 업무를 처리하려는 방식은 오래가지 않습니다. 실제 연구 업무에는 데이터베이스, 파일 형식, API, 도메인별 검증 규칙, 기관별 권한이 따라옵니다. Science Skills는 과학자를 위한 프롬프트 모음이라기보다, 에이전트가 특정 도구와 데이터에 접근하는 방법을 패키징한 계층에 가깝습니다.
최근 AI 개발 도구 시장에서도 비슷한 흐름이 보입니다. MCP 서버, 커넥터, 스킬 파일, 샌드박스, 감사 로그가 에이전트 제품의 핵심 기능이 되고 있습니다. Gemini for Science는 이 패턴을 과학 연구로 가져옵니다. 연구자가 "AK2 변이와 관련된 구조 생물정보학 분석을 해 달라"고 요청했을 때, 에이전트는 단순 설명문을 만드는 것이 아니라 어떤 데이터베이스를 조회하고 어떤 분석 코드를 실행할지 알아야 합니다. Google은 초기 테스트에서 Science Skills가 몇 시간이 걸리는 분석을 몇 분으로 줄였고, AK2 유전자 돌연변이 관련 희귀 질환 메커니즘에 대한 새로운 인사이트로 이어졌다고 말합니다.
이 주장은 아직 조심스럽게 읽어야 합니다. "몇 시간에서 몇 분"이라는 표현은 강한 제품 메시지이지만, 어떤 데이터와 과제에서 측정됐는지에 따라 의미가 달라집니다. 그래도 방향성은 분명합니다. 과학 에이전트의 제품화는 모델 카드만으로 끝나지 않습니다. 도구 연결, 데이터 출처, 실행 환경, 평가 결과를 함께 묶는 운영 문제가 됩니다.
경쟁은 과학자의 자리를 뺏는 쪽보다 검증을 파는 쪽으로 간다
Gemini for Science를 둘러싼 경쟁 구도는 "AI가 과학자를 대체한다"는 식으로 단순화하기 어렵습니다. 오히려 지금 보이는 경쟁은 검증 가능한 연구 보조 시스템을 누가 더 설득력 있게 만들 수 있느냐에 가깝습니다. FutureHouse의 Robin 같은 과학 에이전트, OpenAI의 생명과학·과학 추론 모델, Anthropic의 기업 연구 워크플로, 그리고 학술 검색·문헌 분석 제품들이 모두 같은 문제의 일부를 건드립니다.
Google의 강점은 넓은 연구 자산입니다. AlphaFold, AlphaGenome, Google Scholar, Colab, Earth Engine, NotebookLM, Gemini, Antigravity가 서로 다른 층에 있습니다. 이번 발표는 이 자산을 하나의 과학 워크플로로 묶겠다는 선언입니다. 반대로 약점도 여기서 나옵니다. 너무 많은 도구가 얽히면 연구자는 결과가 어디서 왔는지, 어떤 모델과 데이터베이스가 어떤 단계에 개입했는지 추적하기 어려워질 수 있습니다. 과학에서 설명 가능성과 재현성은 제품 편의성보다 더 엄격한 기준을 요구합니다.
커뮤니티 반응도 이 양면성을 보여줍니다. Reddit의 r/accelerate에서는 Gemini for Science가 AI에서 가장 기대되는 영역이라는 반응과, 여러 과학 분야의 지식을 한 문제에 가져오는 능력이 큰 변화를 만들 것이라는 기대가 보였습니다. 반면 Google I/O 전체 토론에서는 AI Overview의 오류와 Google AI 제품 전반에 대한 신뢰를 걱정하는 목소리도 있었습니다. 과학 에이전트는 그 신뢰 문제에서 더 자유롭지 않습니다. 오히려 더 높은 기준을 요구받습니다.
개발팀이 봐야 할 실무 신호
첫 번째 신호는 에이전트 평가의 기준이 더 구체화되고 있다는 점입니다. 일반 챗봇 평가는 사용자 만족도나 정답률로 흐르기 쉽습니다. 코딩 에이전트는 테스트 통과율과 PR 품질을 봅니다. 과학 에이전트는 한 단계 더 나아가 실험 지표, 문헌 근거, 재현성, 데이터 누수 여부를 봐야 합니다. ERA의 tree search와 품질 지표 최적화 구조는 앞으로 전문 도메인 에이전트가 어떻게 평가될지 보여주는 힌트입니다.
두 번째 신호는 에이전트 제품이 점점 "도구 묶음"이 된다는 점입니다. Gemini for Science의 Science Skills는 모델 능력보다 연결 계층을 강조합니다. 개발자가 자체 도메인 에이전트를 만든다면, 이제 좋은 프롬프트보다 안전한 데이터 커넥터, 도메인별 평가 함수, 실행 환경, 산출물 감사 로그가 더 중요해집니다. 과학 분야만의 이야기가 아닙니다. 법무, 금융, 보안, 제조에서도 같은 구조가 반복될 가능성이 큽니다.
세 번째 신호는 제품 공개와 논문 검증의 결합입니다. Google은 I/O 무대에서 Labs 제품을 보여주면서 동시에 Nature 논문을 근거로 제시했습니다. 이는 AI 제품 발표의 설득 방식이 바뀌고 있음을 보여줍니다. "새 모델이 나왔다"보다 "이 시스템이 어떤 벤치마크와 실제 파트너 검증을 통과했는가"가 더 중요해지는 흐름입니다. 특히 과학과 의료처럼 실패 비용이 큰 분야에서는 이 기준이 더 강해질 것입니다.
마지막으로, 연구자는 여전히 루프 안에 있어야 합니다. Google 발표도 인간 과학자를 제거한다기보다, 지식 폭증과 반복 실험 병목을 줄이는 도구로 설명합니다. 좋은 방향입니다. 과학 에이전트가 진짜 유용해지려면 연구자의 질문을 더 빠르게 좁히고, 반복 가능한 후보를 더 많이 만들고, 검증할 근거를 더 투명하게 남겨야 합니다. 연구자의 판단을 대신하는 제품보다, 연구자가 반박하고 추적할 수 있는 제품이 더 오래 살아남을 가능성이 큽니다.
Gemini for Science는 아직 완성된 과학 자동화 플랫폼이라기보다 출발선에 가깝습니다. Labs 접근은 점진적으로 열리고, trusted tester와 기관 파트너 중심의 검증이 이어집니다. 하지만 이번 발표는 AI for Science가 더 이상 논문 속 데모만이 아니라, 개발 플랫폼과 제품 표면으로 내려오고 있음을 보여줍니다. 코딩 에이전트가 소프트웨어 개발의 실행 루프를 바꿨다면, 과학 에이전트는 연구의 가설과 실험 루프를 어디까지 제품화할 수 있는지 묻기 시작했습니다.
그 질문의 답은 Gemini가 얼마나 똑똑한가보다 더 넓습니다. 어떤 도구를 호출할 수 있는가, 어떤 실험을 실행할 수 있는가, 어떤 근거를 남기는가, 어떤 실패를 연구자가 볼 수 있게 하는가가 핵심입니다. 이번 Gemini for Science 발표의 의미는 바로 거기에 있습니다. Google은 과학자를 위한 더 큰 챗봇을 낸 것이 아니라, 연구 에이전트가 검증받아야 할 무대를 공개했습니다.