Gemini File Search, RAG가 이미지를 읽기 시작했다
Google이 Gemini API File Search에 멀티모달 검색, 메타데이터 필터, 페이지 citation을 추가했습니다. RAG가 데모에서 운영 레이어로 이동하는 신호입니다.

- 무슨 일: Google이
Gemini API File Search에 이미지+텍스트 검색, 메타데이터 필터, 페이지 단위 citation을 추가했습니다.- 발표일은 2026년 5월 5일이며, 공식 문서는 멀티모달 embedding에
gemini-embedding-2를 쓰라고 안내합니다.
- 발표일은 2026년 5월 5일이며, 공식 문서는 멀티모달 embedding에
- 의미: RAG의 병목이 모델 답변 품질에서 근거 검색의 운영성으로 이동하고 있음을 보여줍니다.
- 영향: 에이전트가 PDF, 도표, 스크린샷, 이미지 자산까지 같은 검색 레이어에서 다룰 수 있는 방향으로 갑니다.
- 주의점: 공식 문서 기준 오디오와 비디오는 아직 지원되지 않으며, 권한과 메타데이터 설계는 여전히 제품팀의 몫입니다.

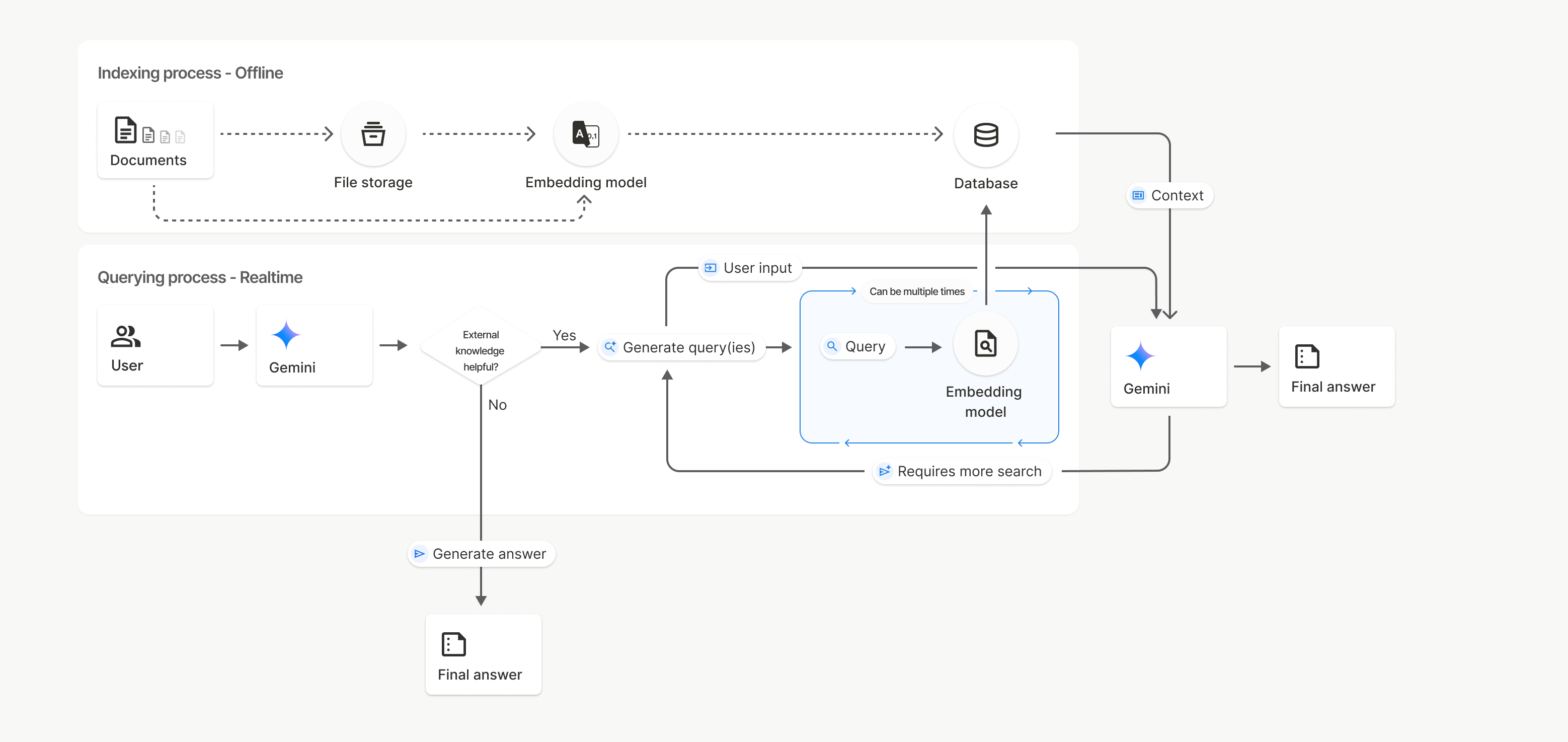
Google이 2026년 5월 5일, Gemini API의 File Search 도구를 확장했습니다. 발표 자체는 짧습니다. 멀티모달 지원, 커스텀 메타데이터, 페이지 단위 citation이 들어갔다는 내용입니다. 하지만 이 세 가지를 묶어 보면 방향이 꽤 선명합니다. RAG가 "문서 몇 개를 벡터 DB에 넣고 답하게 하는 기능"에서, AI 에이전트가 실제 조직의 지식 저장소를 다루는 운영 레이어로 내려오고 있습니다.
RAG는 지난 2년 동안 너무 쉽게 설명됐습니다. 문서를 잘라 embedding하고, 질문과 비슷한 chunk를 찾아 LLM prompt에 넣으면 된다는 식입니다. 데모에서는 맞습니다. 하지만 실제 제품에서는 바로 문제가 생깁니다. 문서는 PDF만 있는 것이 아닙니다. 스크린샷, 시스템 다이어그램, 제품 이미지, 슬라이드, 표가 섞여 있습니다. 문서가 수천 개로 늘어나면 "관련 있어 보이는" chunk가 너무 많이 들어옵니다. 사용자가 "이 답이 어디에서 왔느냐"고 물으면, 200페이지 PDF 하나를 출처로 던져주는 것만으로는 부족합니다.
이번 Gemini API File Search 업데이트는 정확히 그 약한 지점을 겨냥합니다. Google 공식 발표는 File Search가 이제 텍스트와 이미지를 함께 처리하고, 파일에 붙인 메타데이터로 검색 범위를 좁히며, 답변 근거를 페이지 단위로 보여줄 수 있다고 설명합니다. 기능 이름만 보면 세부 옵션 추가처럼 보이지만, 실제로는 "프로덕션 RAG가 왜 어려운가"에 대한 답에 가깝습니다.
텍스트만 읽는 RAG는 현실을 절반만 봅니다
기존 RAG 파이프라인의 많은 부분은 텍스트 중심으로 설계됐습니다. PDF에서 텍스트를 뽑고, 웹페이지를 Markdown으로 바꾸고, 문서를 chunk로 나누는 방식입니다. 이것은 계약서, 정책 문서, 위키처럼 텍스트가 중심인 지식에는 잘 맞습니다. 하지만 개발팀이나 제품팀의 실제 지식은 그렇게 깨끗하지 않습니다.
아키텍처 결정은 종종 sequence diagram에 들어 있습니다. 장애 대응 기록에는 대시보드 스크린샷이 붙어 있습니다. 디자인 시스템은 텍스트 설명보다 컴포넌트 캡처 이미지에 더 많은 정보를 담습니다. 연구 문서는 그래프와 현미경 이미지, 수식 캡처를 포함합니다. 고객 지원 문서에서는 사용자가 찍은 화면이 문제의 핵심 증거일 때도 많습니다.
텍스트 전용 RAG는 이런 데이터를 다루기 위해 우회로를 만듭니다. 이미지를 OCR에 넣고, 이미지 captioning 모델로 설명을 생성하고, 텍스트 chunk와 별도 vector index를 만들고, 검색 결과를 다시 합칩니다. 이 방식은 가능하지만 유지보수가 어렵습니다. 특히 agent workflow에서는 더 불안정합니다. 에이전트가 "이 에러 화면과 비슷한 기존 사례를 찾아줘"라고 해야 할 때, 이미지가 제대로 검색되지 않으면 이후 추론 전체가 틀어집니다.
Google은 이번 발표에서 File Search가 Gemini Embedding 2를 기반으로 이미지와 텍스트를 함께 처리한다고 설명했습니다. 공식 문서도 멀티모달 File Search를 쓰려면 File Search store 생성 시 embedding model을 models/gemini-embedding-2로 지정하라고 안내합니다. 이것은 단순히 "이미지도 업로드됩니다"가 아닙니다. 검색 레이어가 시각 정보를 원래부터 검색 가능한 지식으로 취급하기 시작했다는 뜻입니다.
세 가지 업데이트는 따로가 아니라 함께 봐야 합니다
이번 발표의 핵심은 세 기능이 서로를 보완한다는 점입니다. 멀티모달 검색만 있으면 흥미로운 데모가 됩니다. 메타데이터 필터만 있으면 기존 문서 검색의 편의 기능에 가깝습니다. 페이지 citation만 있으면 근거 표시가 조금 좋아진 정도로 보일 수 있습니다. 하지만 셋이 함께 들어가면 그림이 달라집니다.
| 업데이트 | 해결하는 문제 | 에이전트 관점의 의미 |
|---|---|---|
| 멀티모달 검색 | 이미지, 도표, 스크린샷이 검색 밖으로 밀려나는 문제 | 텍스트 문서와 시각 자료를 같은 근거 풀에서 탐색 |
| 메타데이터 필터 | 문서가 많아질수록 irrelevant context가 늘어나는 문제 | 부서, 상태, 제품, 권한 단위로 검색 범위를 먼저 축소 |
| 페이지 citation | 답변의 근거를 사용자가 검증하기 어려운 문제 | 행동 전 사람이 확인할 수 있는 감사 가능한 흔적 제공 |
멀티모달 검색은 evidence pool을 넓힙니다. 메타데이터 필터는 그 pool을 좁힙니다. citation은 결과를 검증 가능하게 만듭니다. 좋은 RAG는 많이 찾는 시스템이 아니라, 필요한 범위 안에서 맞는 근거를 찾아 사용자가 확인할 수 있게 하는 시스템입니다. 이번 업데이트는 그 세 축을 한 번에 건드립니다.
특히 메타데이터 필터는 과소평가되기 쉽습니다. 가장 화려한 기능은 이미지 검색입니다. 하지만 운영에서 더 중요한 것은 검색 범위를 줄이는 일입니다. 법무팀의 최종 계약서만 검색해야 할 때, 초안과 외부 공유 금지 문서까지 섞이면 모델이 아무리 좋아도 답변 품질이 흔들립니다. 고객 지원 에이전트가 한국어 문서와 일본어 문서를 동시에 뒤지면 정확도와 latency가 함께 나빠질 수 있습니다. department: Legal, status: Final, region: KR 같은 필터는 단순한 라벨이 아니라 retrieval policy의 일부가 됩니다.
File Search는 벡터 DB가 아니라 Gemini tool입니다
여기서 중요한 제품적 차이가 있습니다. Gemini API File Search는 독립적인 vector database 제품이라기보다 Gemini API 안에서 쓰는 tool입니다. 공식 문서는 파일을 File Search store로 가져오면 자동으로 chunking, embedding, indexing이 일어나고, generateContent 호출에서 FileSearch tool을 지정해 모델이 관련 정보를 찾아 응답 근거로 쓰는 흐름을 설명합니다.
이 구조는 편합니다. 애플리케이션 개발자는 파일 저장, chunking 작업자, embedding queue, vector DB schema, 검색 API, citation stitching을 전부 직접 만들지 않아도 됩니다. 특히 작은 팀이나 빠르게 agent prototype을 만들려는 팀에는 매력적입니다. Google은 발표에서 weekend project부터 수천 명 규모의 production application까지 같은 도구를 쓸 수 있다고 말합니다. 과장은 걸러 들어야 하지만, 목표 시장은 분명합니다. "RAG 인프라를 직접 만드는 팀"뿐 아니라 "Gemini 기반 제품을 빨리 운영 수준으로 올리고 싶은 팀"입니다.
하지만 이 편의성은 선택의 비용도 만듭니다. File Search store는 Gemini API에 붙은 관리형 저장소입니다. ranking logic, embedding strategy, 권한 모델, deletion policy, observability를 얼마나 세밀하게 제어할 수 있는지는 자체 stack보다 제한적일 수 있습니다. 대규모 조직이 이미 자체 vector DB, data catalog, 권한 시스템, 감사 로그를 갖고 있다면 File Search만으로 모든 요구를 만족하기 어려울 수 있습니다.
따라서 이 업데이트를 "모든 RAG stack의 대체재"로 보는 것은 무리입니다. 더 정확한 해석은 Gemini 생태계 안에서 관리형 retrieval layer가 빠르게 성숙하고 있다는 것입니다. 애초에 Gemini 모델과 Gemini API로 agent를 만들고 있다면, File Search는 첫 번째 선택지가 될 수 있습니다. 반대로 multi-model routing, 사내 보안 정책, 복잡한 ranking 실험이 핵심이라면 자체 retrieval layer를 유지하면서 일부 workflow에만 Gemini File Search를 붙이는 방식이 더 현실적입니다.
페이지 citation은 신뢰의 UX입니다
RAG의 신뢰 문제는 hallucination만으로 설명되지 않습니다. 모델이 맞는 말을 해도 사용자가 검증할 수 없으면 업무 도구로 쓰기 어렵습니다. 특히 정책, 계약, 재무 문서, 연구 보고서, 의료/법률/규제 문서에서는 "어느 문서에서 왔는가"보다 "어느 페이지, 어느 문맥에서 왔는가"가 중요합니다.
Google 공식 문서는 File Search 사용 시 모델 응답에 citation이 포함될 수 있고, grounding_metadata에서 citation 정보를 확인할 수 있다고 설명합니다. 페이지가 있는 문서에서는 retrieved_context.page_number를 통해 페이지 번호도 접근할 수 있습니다. 이것은 작은 API 필드처럼 보이지만, 제품 UX에서는 큽니다. 답변 옆에 "출처: 정책 PDF 37쪽"을 보여줄 수 있으면 사용자는 모델을 신뢰하기보다 근거를 검토할 수 있습니다.
에이전트에서는 더 중요합니다. 챗봇은 틀리면 다시 물어보면 됩니다. 하지만 에이전트는 티켓을 라우팅하고, 문서를 수정하고, 결재 초안을 만들고, 시스템 변경을 제안할 수 있습니다. 행동하는 시스템일수록 근거가 남아야 합니다. page citation은 완전한 audit log는 아니지만, 사람이 승인하는 경계에서 중요한 재료가 됩니다.
혼합 데이터 업로드: PDF, 이미지, 문서, 다이어그램
File Search store: chunking, embedding, indexing
검색 제약: metadata filter와 multimodal semantic search
Gemini 응답: grounding metadata와 page citation
Google의 더 큰 흐름은 agentic backend입니다
이번 File Search 발표 하루 전인 2026년 5월 4일, Google은 Gemini API Webhooks도 발표했습니다. 이 기능은 장시간 걸리는 agentic application에서 polling 대신 완료 이벤트를 서버로 push하는 구조입니다. 공식 발표는 Deep Research, 긴 비디오 생성, Batch API로 수천 개 prompt를 처리하는 작업처럼 몇 분에서 몇 시간까지 걸릴 수 있는 작업을 예로 들었습니다. 요청은 webhook-signature, webhook-id, webhook-timestamp 헤더로 서명되고, 최대 24시간 자동 retry가 보장된다고 설명합니다.
File Search와 Webhooks는 다른 기능입니다. 하지만 같은 방향을 봅니다. Google은 Gemini API를 단발성 text completion API가 아니라, 파일을 저장하고 검색하고, 장시간 작업을 기다리고, 완료 이벤트를 받아 후속 처리를 하는 agentic backend로 다듬고 있습니다. 모델 경쟁이 benchmark에서만 벌어지던 시기와 달리, 지금은 주변 인프라가 제품 경쟁력입니다.
개발자 입장에서는 이 흐름이 실용적입니다. 에이전트 애플리케이션은 대부분 "모델 호출"보다 그 주변이 어렵습니다. 입력 데이터를 어디에 넣을지, 검색 근거를 어떻게 제한할지, 긴 작업을 어떻게 기다릴지, 실패와 retry를 어떻게 처리할지, 사용자가 답변을 검증할 수 있게 어떤 흔적을 남길지가 핵심입니다. Gemini API가 이 주변 기능을 흡수할수록, Google은 모델 제공자에서 agent application platform으로 이동합니다.
그래도 남는 질문들
먼저 지원 범위입니다. 공식 문서는 File Search가 텍스트 embedding은 gemini-embedding-001, 이미지/멀티모달 embedding은 gemini-embedding-2로 지원된다고 설명하지만, 오디오와 비디오는 현재 지원하지 않는다고 명시합니다. Google의 발표 문구만 보면 "멀티모달"이 매우 넓게 들릴 수 있지만, 이번 File Search에서 바로 다룰 수 있는 범위는 주로 텍스트와 이미지입니다. 영상 회의 녹화, 긴 오디오, 제품 데모 영상까지 같은 저장소에서 검색하려는 팀은 별도 전처리나 다른 API가 필요합니다.
둘째, 권한 모델입니다. 메타데이터 필터가 검색 범위를 좁히는 데 유용한 것은 맞습니다. 하지만 metadata는 권한 시스템 그 자체가 아닙니다. 민감 문서를 다루는 조직에서는 업로드 시점의 접근 권한, 사용자의 역할, tenant isolation, 문서 폐기 정책, 감사 로그가 함께 설계되어야 합니다. department=Legal 필터를 걸 수 있다는 사실과, 법무팀 외 사용자가 그 데이터를 절대 볼 수 없다는 보장은 다른 문제입니다.
셋째, retrieval 품질의 검증입니다. 멀티모달 검색이 가능하다고 해서 모든 이미지 검색이 정확해지는 것은 아닙니다. 다이어그램의 작은 글자, 복잡한 차트, 손글씨, 코드 스크린샷, 오래된 스캔 문서는 여전히 까다롭습니다. 프로덕션 팀은 "이제 이미지도 검색된다"에서 멈추지 말고, 자신들의 실제 corpus로 recall, precision, citation correctness를 측정해야 합니다.
넷째, vendor lock-in입니다. 관리형 File Search는 빠르게 시작하게 해주지만, 검색 index와 grounding metadata가 Gemini API 흐름에 묶입니다. 멀티 모델 전략을 쓰는 팀이라면 추후 OpenAI, Anthropic, 자체 모델, 온프레미스 모델로 이동할 때 검색 레이어를 어떻게 재사용할지 고민해야 합니다. 모델은 바꿔도 지식 저장소는 오래갑니다. RAG 인프라 선택은 단순한 SDK 선택보다 더 오래 남는 결정입니다.
개발팀은 무엇을 봐야 하나
이번 업데이트를 바로 도입할지 여부와 별개로, 개발팀이 확인해야 할 질문은 꽤 구체적입니다.
첫째, 우리 knowledge base에는 이미지로만 존재하는 지식이 얼마나 많은가. 아키텍처 다이어그램, ERD, 제품 화면, 장애 캡처, 실험 그래프가 많다면 텍스트 전용 RAG의 한계가 이미 있었을 가능성이 큽니다. 이런 팀에는 멀티모달 retrieval이 실제 품질 차이를 만들 수 있습니다.
둘째, 검색 전에 좁혀야 하는 축이 무엇인가. 부서, 국가, 제품, 문서 상태, 고객 등급, 공개 범위, 날짜 같은 metadata가 없으면 retrieval은 쉽게 noisy해집니다. File Search의 metadata filter는 그런 설계를 API 수준에서 반영할 수 있게 해주지만, 좋은 metadata schema는 자동으로 생기지 않습니다. 문서 ingestion 단계에서부터 taxonomy를 정해야 합니다.
셋째, citation을 사용자 경험의 일부로 넣을 준비가 되어 있는가. 근거를 수집해도 UI가 보여주지 않으면 신뢰는 크게 오르지 않습니다. 답변 아래에 출처 파일과 페이지를 보여주고, 클릭하면 해당 페이지로 이동하게 하고, 모델이 근거 없이 말한 부분은 낮은 confidence로 표시하는 식의 UX가 필요합니다.
넷째, 관리형 stack과 자체 stack의 경계를 어디에 둘 것인가. 빠른 프로토타입, 내부 도구, Gemini 중심 제품이라면 File Search는 좋은 출발점입니다. 하지만 ranking 실험, strict access control, cross-model retrieval, on-premise 요구가 강하면 자체 검색 레이어와 병행하는 편이 낫습니다.
RAG의 다음 경쟁은 검색의 품질보다 운영의 품질입니다
LLM 경쟁은 계속 모델 성능으로 이야기됩니다. 하지만 제품을 만드는 사람에게는 모델보다 검색 레이어가 더 자주 문제를 일으킵니다. 답변이 틀린 이유가 모델의 지능 부족인지, 잘못된 문서가 들어갔기 때문인지, 이미지 증거를 못 봤기 때문인지, 오래된 초안을 final 문서로 착각했기 때문인지 구분해야 합니다. 이 구분이 안 되면 개선도 어렵습니다.
Gemini API File Search의 이번 업데이트는 그 문제를 완전히 해결하지 않습니다. 다만 Google이 무엇을 중요하게 보고 있는지는 보여줍니다. 멀티모달 evidence, metadata-based narrowing, page-level provenance. 이것들은 AI 에이전트가 실제 업무에 들어갈 때 필요한 기본 구성요소입니다. 화려한 agent demo보다 덜 눈에 띄지만, 운영에서는 이런 기능이 더 오래 갑니다.
이번 발표를 "Google도 RAG 기능을 강화했다" 정도로 보면 작게 보입니다. 더 큰 변화는 RAG가 application code 바깥의 관리형 플랫폼 기능으로 흡수되고 있다는 점입니다. 검색, 저장, citation, 장시간 작업 이벤트까지 API 제공자가 묶어 제공하기 시작하면, 에이전트 제품의 기본 아키텍처도 바뀝니다. 개발자는 더 빨리 만들 수 있지만, 동시에 어떤 레이어를 플랫폼에 맡기고 어떤 레이어를 직접 소유할지 더 신중하게 결정해야 합니다.
결국 좋은 RAG는 모델이 더 말을 잘하게 만드는 장치가 아닙니다. 모델이 행동하기 전에 무엇을 근거로 삼았는지 제한하고, 확인하고, 기록하는 장치입니다. Gemini File Search가 이미지를 읽기 시작했다는 것은 그래서 중요합니다. 기업 지식은 원래부터 멀티모달이었고, 이제 RAG 도구가 그 현실을 따라잡기 시작했습니다.