Gemini 3.5 Flash 14X, 코딩 에이전트 과금의 역설
Gemini 3.5 Flash가 GitHub Copilot에 들어왔지만 14배 계수로 표시됐습니다. 모델 속도보다 과금 단위가 더 중요해졌습니다.
- 무슨 일: Google의
Gemini 3.5 Flash가 5월 19일 GitHub Copilot에 일반 제공으로 들어왔습니다.- Copilot Pro, Pro+, Business, Enterprise 대상이며 기업 관리자는 별도 모델 정책을 켜야 합니다.
- 핵심 숫자: Google은 Flash급 속도를 말했지만 GitHub는
14X premium request multiplier를 붙였습니다. - 의미: 코딩 에이전트의 비용은 모델명보다 제품 안의 계량 단위, 라우팅, 정책에서 결정됩니다.
- 같은 모델도 Gemini API, Vercel AI Gateway, Copilot 모델 피커에서 전혀 다른 운영 계산을 만듭니다.
- 주의점: GitHub는 14X 가격이 잠정적이라고 밝혔지만, 6월 사용량 기반 과금 전환 전 모델 선택 기준은 이미 바뀌고 있습니다.
Google I/O 2026의 모델 뉴스는 대체로 같은 문장으로 요약됩니다. Gemini 3.5 Flash는 빠르고, 에이전트 작업에 강하며, 코딩 벤치마크에서 이전 Pro급 모델을 따라잡았습니다. 그런데 개발자가 실제로 마주한 숫자는 조금 다릅니다. 2026년 5월 19일 GitHub Changelog는 Gemini 3.5 Flash가 GitHub Copilot에 일반 제공으로 들어온다고 알리면서, 이 모델이 14X premium request multiplier로 출시된다고 적었습니다.
이 숫자는 이상하게 보입니다. Flash라는 이름은 보통 더 빠르고 더 저렴한 모델 계층을 떠올리게 합니다. Google도 공식 발표에서 Gemini 3.5 Flash를 "frontier intelligence with action"으로 소개하면서 Flash 시리즈의 속도, 에이전트형 작업, 장기 코딩 워크플로를 강조했습니다. 하지만 Copilot 안에서 사용자가 보는 것은 "빠른 모델"만이 아닙니다. 모델 피커 옆에는 플랜, 정책, premium request, 6월 1일 이후 사용량 기반 과금이라는 별도의 제품 문법이 붙습니다.
그래서 이번 뉴스는 Gemini 3.5 Flash가 또 하나의 새 모델로 나왔다는 소식보다 조금 더 흥미롭습니다. 코딩 에이전트 제품의 경쟁이 모델 성능표에서 끝나지 않고, 어떤 플랫폼이 그 모델을 어떤 단위로 팔고 통제하는지로 이동하고 있음을 보여줍니다. 개발자가 "이 모델은 싸겠지"라고 생각하는 순간, 실제 제품 화면의 계산서는 다른 답을 줄 수 있습니다.
같은 날 나온 두 개의 메시지
Google의 공식 발표는 명확합니다. Gemini 3.5 Flash는 2026년 5월 19일 공개됐고, Google은 이를 최신 Gemini 3.5 계열의 첫 모델로 설명했습니다. 제공 경로도 넓습니다. Gemini 앱과 Search AI Mode에는 일반 사용자용 기본 모델로 들어가고, 개발자는 Google Antigravity, Gemini API in Google AI Studio, Android Studio에서 쓸 수 있습니다. 기업은 Gemini Enterprise Agent Platform과 Gemini Enterprise 경로를 받습니다.
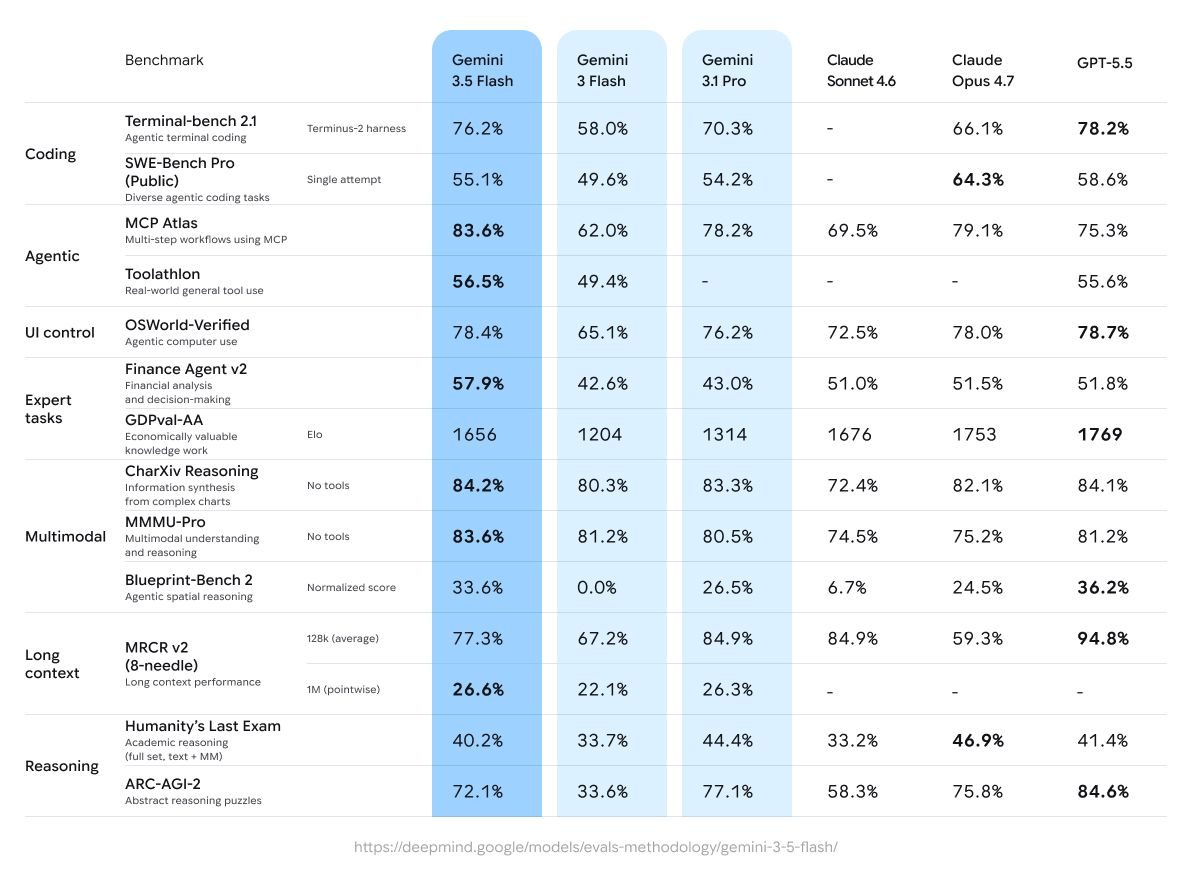
Google이 내세운 기술 메시지는 "Flash급 속도와 Pro급 작업 능력의 결합"입니다. 공식 발표에 따르면 Gemini 3.5 Flash는 Terminal-Bench 2.1에서 76.2%, GDPval-AA에서 1656 Elo, MCP Atlas에서 83.6%, CharXiv Reasoning에서 84.2%를 기록했습니다. Google DeepMind 모델 카드도 이 모델이 reasoning, coding, agentic tool use, multimodal, multilingual, long-context 벤치마크에서 평가됐다고 설명합니다. 입력은 텍스트, 이미지, 오디오, 비디오를 포함하고, context window는 최대 1M token, 출력은 64K token입니다.
GitHub의 메시지도 겉으로는 같은 방향입니다. GitHub Changelog는 Gemini 3.5 Flash가 Copilot에서 "near-Pro coding quality at Flash-tier speed and cost"를 제공한다고 설명했습니다. 강한 도구 사용, 빠른 응답, 높은 cache efficiency 때문에 빠른 반복형 agentic coding workflow에 적합하다는 평가도 붙였습니다. 사용 가능한 환경은 VS Code 1.115.0 이상, Visual Studio 17.14.22 또는 18.1.0 이상, JetBrains, Xcode, Eclipse입니다. 대상 플랜은 Copilot Pro, Pro+, Business, Enterprise입니다.
그러나 바로 다음 줄에서 긴장이 생깁니다. GitHub은 이 모델이 14X premium request multiplier로 출시된다고 밝혔습니다. 문서의 supported models 표도 paid plan에서 Gemini 3.5 Flash multiplier를 14로 표시합니다. 기존 Gemini 3 Flash는 0.33, Gemini 3.1 Pro는 1로 표시됩니다. 같은 Gemini 계열 안에서도 Copilot의 계량표에서는 Flash라는 이름과 숫자의 직관이 흔들립니다.
14X는 왜 기사 제목이 되는가
14X는 단순한 가격 각주가 아닙니다. 코딩 에이전트에서는 한 번의 요청이 일반 채팅 한 문장보다 훨씬 큽니다. 에이전트는 저장소를 읽고, 여러 파일을 비교하고, 테스트를 실행하고, 실패 로그를 다시 읽고, 수정안을 반복합니다. 이 과정은 사용자의 눈에는 "하나의 작업"처럼 보이지만, 제품 내부에서는 여러 번의 모델 호출과 도구 호출, 컨텍스트 재구성으로 쪼개집니다.
Copilot이 premium request multiplier를 쓰는 이유도 여기에 있습니다. 모델마다 추론 비용, 지연시간, 도구 사용 패턴, 시스템 부하가 다르기 때문에 같은 "요청 1회"로 묶으면 제품 운영이 맞지 않습니다. 문제는 사용자가 모델 이름에서 기대하는 비용 감각과 제품의 계량 단위가 다를 수 있다는 점입니다. Flash는 API 시장에서는 낮은 지연시간과 낮은 비용을 암시하지만, Copilot 안에서는 14배 premium request로 시작합니다.
GitHub은 이 가격이 잠정적이며 변경될 수 있다고 주석을 달았습니다. 따라서 "GitHub이 Gemini 3.5 Flash를 영구적으로 비싸게 팔기로 했다"라고 단정하는 것은 이릅니다. 하지만 2026년 6월 1일 Copilot의 사용량 기반 과금 전환을 앞둔 시점이라는 맥락을 빼면 이 숫자의 의미를 놓치게 됩니다. GitHub은 이미 AI Credits, 사용량 리포트, 모델별 multiplier, 기업 정책을 통해 Copilot을 월 구독형 자동완성에서 측정 가능한 에이전트 실행 플랫폼으로 바꾸고 있습니다.
여기서 개발자가 배워야 할 것은 "Gemini 3.5 Flash를 쓰지 말라"가 아닙니다. 더 정확한 결론은 "모델의 API 포지션과 Copilot 안의 과금 포지션을 분리해서 봐야 한다"입니다. 같은 모델이라도 Gemini API로 직접 호출할 때, Vercel AI Gateway로 라우팅할 때, GitHub Copilot 모델 피커에서 선택할 때 비용 구조와 통제권이 다릅니다.
| 경로 | 개발자가 얻는 것 | 주의할 계산 |
|---|---|---|
| Gemini API | 모델 직접 호출, token 기반 비용, 자체 하네스 구성 | 컨텍스트 수집, 도구 실행, 정책 계층을 직접 설계해야 합니다. |
| Vercel AI Gateway | 통합 API, 사용량 추적, 재시도와 failover, BYOK 경로 | 게이트웨이 운영 규칙과 provider별 실제 단가를 함께 봐야 합니다. |
| GitHub Copilot | IDE 통합, 저장소 맥락, 기업 정책, 코드 필터, 에이전트 UX | 14X multiplier와 AI Credits 전환 이후의 사용량을 따로 계산해야 합니다. |
Flash라는 이름의 방향과 Copilot의 방향
Google 입장에서 Gemini 3.5 Flash는 굉장히 중요한 포지셔닝입니다. 이전 세대에서 Flash 계열은 대체로 빠른 응답과 비용 효율을 담당했습니다. 이번 발표에서는 그 계층이 단순한 경량 모델이 아니라 에이전트와 코딩 워크플로까지 다루는 주력 작업 모델로 올라왔습니다. Google은 이 모델을 Antigravity의 collaborative subagents, AI Studio의 UI 생성, Search의 24시간 정보 에이전트, Gemini Spark의 개인 에이전트 기반으로 묶었습니다.
모델 카드의 수치도 그 방향을 뒷받침합니다. Terminal-Bench 2.1은 agentic terminal coding을, MCP Atlas는 MCP를 사용하는 multi-step workflow를, OSWorld-Verified는 컴퓨터 사용 능력을 봅니다. 이들은 단순 질의응답보다 에이전트 실행에 가까운 평가입니다. Google이 Gemini 3.5 Flash를 "가볍게 대화하는 모델"이 아니라 "오래 실행되는 작업을 빠르게 밀어붙이는 모델"로 배치하는 이유입니다.
하지만 GitHub Copilot은 다른 문제를 풀고 있습니다. Copilot은 모델 회사가 아니라 개발자 워크플로 플랫폼입니다. 사용자는 같은 화면에서 OpenAI, Anthropic, Google 계열 모델을 고르고, 기업 관리자는 어떤 모델을 허용할지 정책으로 통제합니다. 저장소 컨텍스트, public code matching, harmful content filter, IDE 버전, 플랜별 권한, 사용량 보고서가 모두 붙습니다. 이 제품에서 모델은 독립 상품이 아니라 관리되는 리소스입니다.
따라서 GitHub의 14X는 단순히 "Google 모델이 비싸다"는 뜻으로만 읽기 어렵습니다. Copilot이 Gemini 3.5 Flash를 어떤 부하와 어떤 제품 약속 아래에서 운영할지에 대한 플랫폼 신호입니다. GitHub은 Changelog에서 strong tool use, cache efficiency, iterative agentic workflow를 강조했습니다. 바로 그 강점이 비용 측정에서는 multiplier로 돌아옵니다. 에이전트가 더 잘 반복할수록, 사용자는 더 오래 맡기고, 제품은 더 촘촘하게 측정해야 합니다.
기업 관리자에게 더 민감한 뉴스
개인 개발자에게 14X는 "이번 달 quota가 빨리 줄어들 수 있다"는 체감으로 다가옵니다. 기업 관리자에게는 조금 더 복잡합니다. Copilot Business와 Enterprise에서는 Gemini 3.5 Flash 정책을 별도로 켜야 합니다. 이는 모델 추가가 단순한 기능 업데이트가 아니라 조직의 허용 목록과 비용 통제에 들어가는 항목이라는 뜻입니다.
이 흐름은 최근 Copilot 업데이트들과도 이어집니다. GitHub은 Copilot cloud agent 설정을 REST API로 감사할 수 있게 했고, cloud agent에 저비용 모델 옵션을 추가했으며, usage metrics와 billing preview를 계속 정비하고 있습니다. 모델 선택은 이제 개발자 개인의 취향이 아니라 조직의 운영 정책입니다. 어떤 모델이 어느 IDE에서 보이는지, 어떤 에이전트 작업에 쓰이는지, multiplier가 얼마인지, 6월 이후 AI Credits가 어떻게 소진되는지를 함께 봐야 합니다.
특히 코딩 에이전트는 실패 비용이 누적되는 방식이 다릅니다. 일반 채팅 모델이 틀린 답을 한 번 내면 사용자가 멈춥니다. 코딩 에이전트는 틀린 가설로 테스트를 돌리고, 실패 로그를 다시 읽고, 우회 수정을 만들고, 더 큰 컨텍스트를 끌어올 수 있습니다. 성능이 좋아질수록 반복 횟수가 줄어들 수도 있지만, 사용자가 맡기는 작업의 크기도 커집니다. 결국 총비용은 모델 단가만으로 결정되지 않습니다.
커뮤니티가 숫자에 먼저 반응한 이유
Reddit r/GitHubCopilot에서는 Gemini 3.5 Flash의 Copilot 탑재보다 14배 계수에 더 빠르게 반응했습니다. "Flash인데 14X인가"라는 의문은 단순한 불평이 아닙니다. 지난 몇 달 동안 GitHub Copilot 커뮤니티는 사용량 기반 과금, premium request, 모델 퇴장, 무료 모델 축소, cloud agent 비용을 계속 토론해 왔습니다. 이 상황에서 새 모델의 첫인상은 benchmark 표가 아니라 multiplier 표가 됩니다.
반대로 Google·Gemini 커뮤니티에서는 벤치마크와 실제 코딩 품질에 대한 논쟁이 더 큽니다. 어떤 사용자는 Google의 공식 수치가 드디어 Flash 계층을 에이전트 주력 모델로 만들었다고 보고, 다른 사용자는 공개 벤치마크와 실제 저장소 작업의 간극을 의심합니다. 두 반응은 서로 충돌하지 않습니다. 모델 품질은 실제로 좋아졌을 수 있고, 동시에 Copilot 안의 가격 신호는 개발자에게 부담으로 보일 수 있습니다.
이런 반응의 공통점은 에이전트 시대의 사용자가 더 이상 "가장 똑똑한 모델"만 고르지 않는다는 점입니다. 사용자는 모델이 어느 제품 안에 들어왔는지, 얼마나 오래 실행할 수 있는지, 실패했을 때 다시 돌릴 비용이 얼마인지, 조직 정책에서 막히는지, 로그와 감사가 남는지를 같이 봅니다. 모델 선택은 벤치마크 선택이 아니라 운영 선택에 가까워지고 있습니다.
직접 API와 제품형 에이전트의 갈림길
Vercel이 같은 날 Gemini 3.5 Flash를 AI Gateway에 추가한 것도 눈여겨볼 만합니다. Vercel Changelog는 google/gemini-3.5-flash 모델명을 제시하면서, coding proficiency, parallel agentic execution loops, instruction following, multi-turn coherence 개선을 언급했습니다. AI Gateway는 모델 호출, 사용량과 비용 추적, retry, failover, BYOK를 하나의 API로 묶는 계층입니다.
이것은 Copilot과 다른 선택지입니다. Copilot은 GitHub 저장소와 IDE 표면에 강하게 붙어 있습니다. AI Gateway나 직접 API는 제품 통합을 직접 설계해야 하지만, 호출 경로와 비용 추적의 자유도가 큽니다. 엔터프라이즈 팀이라면 두 경로를 나눠 쓸 가능성이 큽니다. 일상적인 IDE 보조와 작은 수정은 Copilot에서 처리하고, 대량 반복 평가나 자체 에이전트 하네스는 직접 API 또는 gateway로 빼는 방식입니다.
중요한 점은 어느 쪽이 항상 낫다는 결론이 아니라, 각 경로의 비용 단위가 다르다는 점입니다. Copilot의 14X는 GitHub 제품 안에서의 premium request 계산입니다. Gemini API의 비용은 token과 caching, thinking 설정, 입력·출력 비율에 따라 달라집니다. Gateway는 여기에 라우팅, 관측성, 재시도, 공급자 장애 대응이라는 운영 계층을 더합니다. 같은 모델 이름 아래 세 개의 다른 경제가 존재합니다.
앞으로 볼 지점
첫째, GitHub이 Gemini 3.5 Flash의 multiplier를 조정하는지 봐야 합니다. Changelog가 가격을 잠정적이라고 명시했기 때문에, 초기 운영 데이터나 사용자 반응에 따라 바뀔 여지가 있습니다. 만약 14X가 유지된다면 이 모델은 Copilot 안에서 "일상 기본 모델"보다는 특정 고난도 에이전트 작업용 선택지가 될 가능성이 큽니다.
둘째, 자동 모델 선택이 어떤 식으로 Gemini 3.5 Flash를 라우팅하는지 중요해집니다. 사용자가 직접 14X 모델을 선택하는 것과, Copilot의 auto model selection이 작업 난도에 따라 고계수 모델을 선택하는 것은 체감이 다릅니다. 사용량 기반 과금 체계에서는 자동 라우팅의 설명 가능성이 제품 신뢰와 직결됩니다.
셋째, Google의 Flash 전략이 실제 API 시장에서 어떤 가격 압력을 만들지도 봐야 합니다. Google은 Gemini 3.5 Flash를 에이전트와 코딩의 주력 모델로 밀고 있습니다. 이 모델이 빠르고 충분히 좋다면, 많은 팀은 직접 API나 gateway에서 대량 작업을 돌리고 싶어질 것입니다. 그러면 Copilot 같은 제품형 에이전트는 편의성과 통제, 감사, 저장소 통합의 가치를 더 명확히 설명해야 합니다.
넷째, 벤치마크가 실제 코딩 에이전트 비용을 얼마나 설명하는지도 남은 질문입니다. Terminal-Bench, SWE-Bench Pro, MCP Atlas, OSWorld 같은 평가는 분명 중요합니다. 그러나 조직이 실제로 지불하는 것은 벤치마크 점수가 아니라 해결된 이슈, 줄어든 리뷰 시간, 실패한 반복의 비용, 보안 정책을 통과한 실행입니다. 76.2%와 14X가 같은 기사에 들어가는 이유가 여기에 있습니다.
결론
Gemini 3.5 Flash는 Google의 모델 전략에서 중요한 출시입니다. Flash 계층이 더 이상 가벼운 대화 모델에 머물지 않고, 코딩과 agentic workflow의 주력 후보로 올라왔기 때문입니다. Google의 발표와 모델 카드는 이 방향을 숫자로 밀어붙입니다. Terminal-Bench 2.1 76.2%, MCP Atlas 83.6%, 최대 1M token context window는 개발자에게 충분히 주목할 만한 신호입니다.
하지만 GitHub Copilot에 들어온 순간, 같은 모델은 다른 질문을 받습니다. 이 모델은 내 IDE에서 어떤 플랜에 보이는가. 기업 관리자가 켜야 하는가. premium request를 얼마나 소모하는가. 6월 사용량 기반 과금 이후 자동 라우팅은 어떻게 설명되는가. Copilot의 Gemini 3.5 Flash 뉴스에서 가장 큰 숫자가 벤치마크가 아니라 14X로 읽히는 이유입니다.
코딩 에이전트 시대의 모델 선택은 이제 "가장 빠른가"나 "가장 똑똑한가"만으로 끝나지 않습니다. 같은 모델도 API에서는 작업 엔진이고, gateway에서는 라우팅 대상이며, Copilot에서는 정책과 과금이 붙은 제품 리소스입니다. Gemini 3.5 Flash의 Copilot 탑재는 이 차이를 아주 선명하게 보여줍니다. Flash급 속도는 매력적이지만, 실제 운영에서는 그 옆의 계수까지 읽는 팀이 더 오래 버팁니다.