Flash가 Pro를 넘을 때, 에이전트 비용 전쟁의 시작
Gemini 3.5 Flash는 빠른 모델 출시가 아니라 코딩 에이전트와 AI 검색의 비용, 지연시간, 라우팅 경쟁을 여는 신호입니다.

- 무슨 일: Google이
Gemini 3.5 Flash를 공개하고 Gemini app, Search AI Mode, Antigravity, Gemini API에 투입했습니다.- 같은 발표에서
Gemini 3.5 Pro는 다음 달 출시 예정으로 남았고, Flash가 먼저 실사용 표면을 넓혔습니다.
- 같은 발표에서
- 핵심 숫자: Google은 Terminal-Bench 2.1
76.2%, MCP Atlas83.6%, frontier model 대비4배tokens/sec를 제시했습니다. - 개발자 영향: GitHub Copilot의
0.25xpremium request 신호처럼, 에이전트 운영은 최고 성능보다 비용·속도 라우팅 문제가 됩니다.- 장기 코딩 작업, 검색형 UI, 관리형 에이전트는 한 번의 답변보다 반복 호출과 실패 복구 비용이 더 크게 작동합니다.
- 주의점: 벤치마크와 실제 에이전트 경험은 다릅니다. 도구 호출, 로그 해석, 컨텍스트 유지, 정책 통제가 함께 검증돼야 합니다.
Google I/O 2026의 Gemini 발표에서 가장 눈에 띄는 이름은 당연히 Gemini 3.5 Flash입니다. Google은 2026년 5월 19일 공식 발표에서 Gemini 3.5 Flash를 "frontier intelligence with action"으로 소개하고, Gemini 앱, Search AI Mode, Antigravity, Gemini API, AI Studio, Android Studio, Gemini Enterprise Agent Platform에서 사용할 수 있다고 밝혔습니다. 같은 글에서 Gemini 3.5 Pro는 다음 달 출시 예정으로 남았습니다.
이 순서가 중요합니다. 예전의 Flash는 대체로 빠르고 싼 모델, Pro는 어려운 작업을 맡는 모델이라는 인상이 강했습니다. 이번 발표는 그 경계를 흐립니다. Google이 먼저 넓게 배치한 모델은 Pro가 아니라 Flash입니다. 게다가 단순 채팅 보조 모델이 아니라 Search AI Mode, Antigravity, Gemini API, Android Studio 같은 실행형 표면에 연결했습니다. 즉 Flash가 "가벼운 보조 옵션"에서 "매일 돌아가는 에이전트 작업의 기본 엔진"으로 올라오는 장면입니다.
개발자에게 이 뉴스는 모델 이름 하나가 늘었다는 뜻으로 끝나지 않습니다. 에이전트 제품은 한 번의 답변보다 반복 호출이 많습니다. 코딩 에이전트는 파일을 읽고, 테스트를 돌리고, 실패 로그를 해석하고, 다시 고칩니다. AI 검색은 질문을 하위 검색으로 나누고, 결과를 비교하고, UI를 구성합니다. 관리형 에이전트는 샌드박스 안에서 웹을 탐색하고 도구를 호출합니다. 이런 작업에서는 최고 성능 모델을 한 번 호출하는 비용보다, 충분히 강한 모델을 얼마나 빠르고 싸게 여러 번 돌릴 수 있는지가 더 중요해집니다.
Google이 내세운 숫자
Google 공식 발표는 Gemini 3.5 Flash를 coding과 agentic workflow에 맞춘 새 모델로 설명합니다. 발표에서 제시된 수치는 구체적입니다. Terminal-Bench 2.1은 76.2%, GDPval-AA는 1656 Elo, MCP Atlas는 83.6%, CharXiv Reasoning은 84.2%입니다. 또한 Artificial Analysis 기준 frontier model보다 output tokens per second가 4배라고 설명했습니다.
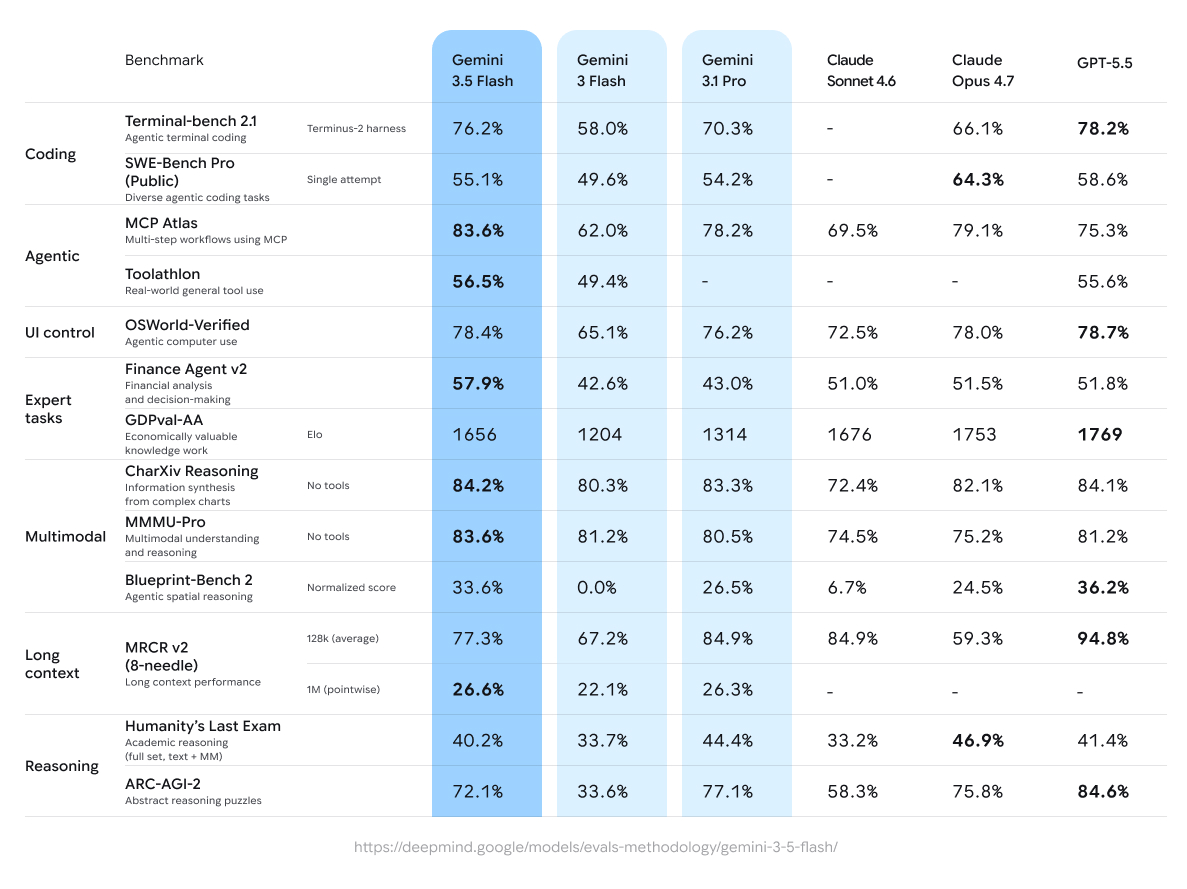
이 숫자들은 서로 다른 방향을 가리킵니다. Terminal-Bench는 터미널과 코딩 작업에서 모델이 얼마나 잘 버티는지 보여주는 지표입니다. MCP Atlas는 에이전트가 외부 도구와 프로토콜을 다루는 흐름과 더 맞닿아 있습니다. CharXiv Reasoning은 차트와 시각 자료를 읽고 reasoning하는 능력과 관련됩니다. Google이 이 숫자를 한꺼번에 전면에 놓은 것은 Flash를 단순 대화 모델이 아니라 tool use, coding, visual reasoning, agentic workflow를 모두 건드리는 모델로 포지셔닝하려는 의도입니다.
하지만 발표에서 더 중요한 표현은 "action"입니다. Google은 같은 I/O에서 Search AI Mode의 생성형 UI, Search agents, Antigravity 2.0, Gemini API Managed Agents를 함께 밀었습니다. 이 제품들은 모두 모델이 긴 설명을 잘 쓰는지만으로 성패가 갈리지 않습니다. 사용자의 목표를 여러 단계로 나누고, 도구를 호출하고, 상태를 보존하고, 결과를 UI나 코드 변경으로 되돌려야 합니다. Flash가 이 표면에 먼저 들어간다는 것은 Google이 에이전트 제품의 기본 단가와 지연시간을 모델 전략의 중심에 놓고 있다는 신호입니다.
Pro보다 먼저 온 Flash
모델 라인업에서 이름만 보면 Pro가 상위이고 Flash가 하위처럼 보입니다. 그래서 "Flash가 먼저 나왔다"는 사실은 가볍게 지나치기 쉽습니다. 그러나 제품 배치 관점에서는 반대입니다. 사용자가 매일 접하는 검색, IDE, CLI, API, 엔터프라이즈 에이전트에 먼저 깔리는 모델이 플랫폼의 기본 경험을 만듭니다. Pro는 어려운 작업을 위한 선택지일 수 있지만, 사용량을 만드는 모델은 Flash입니다.
이 차이는 AI 제품을 운영해 본 팀에게 익숙합니다. 데모에서는 가장 강한 모델을 쓰고 싶습니다. 그러나 실제 제품에서는 평균 지연시간, 실패 재시도, 토큰 사용량, 컨텍스트 길이, 동시 처리량, 요금제를 함께 봐야 합니다. 사용자가 "이 저장소의 버그를 고쳐줘"라고 말했을 때 모델은 한 번 답하지 않습니다. 파일을 찾고, 코드를 읽고, 수정하고, 테스트하고, 로그를 해석하고, 다시 수정합니다. 한 작업 안에서 수십 번의 reasoning과 tool call이 일어날 수 있습니다.
이 구조에서는 모델 선택이 경제성 문제로 바뀝니다. 너무 약한 모델은 실패와 재시도를 늘려 전체 비용을 키웁니다. 너무 비싼 모델은 모든 단계에 쓰기 어렵습니다. 그래서 실무 시스템은 빠른 모델, 강한 모델, 긴 컨텍스트 모델, 시각 reasoning 모델을 작업 단계별로 섞게 됩니다. Gemini 3.5 Flash의 의미는 바로 이 중간 지점에 있습니다. Google은 Flash가 충분히 강하면서도 빠르게 반복 호출될 수 있는 모델이라는 주장을 하고 있습니다.
| 작업 단계 | 에이전트가 실제로 하는 일 | 모델 선택 기준 |
|---|---|---|
| 탐색 | 파일, 문서, 이슈, 검색 결과를 빠르게 훑습니다. | 낮은 지연시간과 넓은 처리량 |
| 계획 | 작업을 나누고 위험한 변경을 가려냅니다. | reasoning 품질과 컨텍스트 유지 |
| 수정 | 코드를 고치고 테스트 로그를 다시 읽습니다. | 코딩 정확도와 재시도 비용 |
| 검증 | 실패 원인을 추적하고 결과를 요약합니다. | tool trace 이해와 긴 출력 처리 |
Copilot의 0.25x가 보여주는 가격표
Gemini 3.5 Flash가 발표 당일 GitHub Copilot에도 들어간 점은 별도 신호입니다. GitHub는 2026년 5월 19일 changelog에서 Copilot Pro, Pro+, Business, Enterprise 사용자가 Gemini 3.5 Flash를 모델 선택 옵션으로 사용할 수 있다고 공지했습니다. GitHub Docs의 모델 multiplier 표에서는 Gemini 3.5 Flash가 premium request 0.25x로 표시됩니다.
이 숫자는 API 가격표 그 자체는 아닙니다. Copilot의 요금제와 request 계산 방식 안에서 쓰이는 상대값입니다. 그러나 개발자 경험 관점에서는 매우 선명한 메시지입니다. Copilot 사용자는 더 이상 "AI 모델" 하나를 쓰는 것이 아니라, 작업마다 모델을 고릅니다. 어떤 작업은 Claude 계열이 낫고, 어떤 작업은 OpenAI 계열이 낫고, 어떤 작업은 Gemini 3.5 Flash처럼 낮은 multiplier와 빠른 응답이 더 적합할 수 있습니다.
코딩 에이전트가 보편화되면 이 모델 선택은 더 자주 일어납니다. 짧은 리팩터링, 테스트 로그 요약, 문서 탐색, 타입 오류 수정, pull request 설명 작성은 반드시 최고가 모델이 필요하지 않을 수 있습니다. 반대로 복잡한 설계 변경, 보안 취약점 분석, 대규모 마이그레이션은 더 강한 reasoning 모델을 요구할 수 있습니다. Copilot의 모델 선택 UI는 이 현실을 사용자에게 노출합니다. 모델 라우팅이 플랫폼 내부 최적화에서 개발자의 일상적 선택으로 내려오는 것입니다.
이 변화는 AI 코딩 도구 회사에도 부담을 줍니다. 지금까지는 "우리 도구가 어떤 모델을 쓴다"가 마케팅 포인트였습니다. 앞으로는 "어떤 작업에 어떤 모델을, 어떤 비용 한도와 정책으로 라우팅하는가"가 더 중요해집니다. 사용자는 빠른 autocomplete, 느린 agent task, 장기 백그라운드 작업, 리뷰 코멘트 생성에 같은 모델을 쓰고 싶어하지 않을 수 있습니다. 모델 품질 경쟁은 여전히 중요하지만, 제품 품질은 라우팅과 예산 제어에서 갈립니다.
Flash가 검색과 에이전트를 묶는 방식
최근 Google 발표를 따로따로 보면 각각 다른 제품처럼 보입니다. Search AI Mode는 검색 발표입니다. Managed Agents는 Gemini API 발표입니다. Antigravity는 개발자 도구 발표입니다. Gemini 3.5 Flash는 모델 발표입니다. 그러나 이들을 묶어 보면 한 방향이 보입니다. Google은 빠른 모델, 실행 환경, 생성형 UI, 개발자 에이전트, 검색 표면을 같은 경제성 안에 넣으려 합니다.
Search AI Mode는 사용자의 질문을 여러 하위 검색으로 나누고 답변과 UI를 만듭니다. Search agents는 가격, 예약, 조건 변화를 계속 확인하는 쪽으로 확장됩니다. Gemini API Managed Agents는 격리된 Linux 환경에서 파일 작업, 코드 실행, 웹 탐색을 수행합니다. Antigravity는 IDE와 CLI에서 여러 에이전트를 조정합니다. 이 모든 흐름은 많은 호출, 많은 중간 상태, 많은 실패 복구를 전제로 합니다.
여기서 Flash 계열이 의미를 갖습니다. 검색 결과 한 번을 만드는 데 모델 호출이 여러 번 들어가고, 에이전트가 한 작업을 완료하는 데 수많은 tool loop가 필요하다면, 모델의 초당 출력과 단가가 곧 제품의 가능 범위를 정합니다. 아무리 똑똑한 모델이라도 사용자가 기다릴 수 없거나 제품이 감당할 수 없는 비용을 만든다면 기본 엔진이 되기 어렵습니다. 반대로 충분히 강하고 빠른 모델은 더 많은 곳에 기본값으로 깔릴 수 있습니다.
이 지점에서 Gemini 3.5 Flash는 Gemini 3.5 Pro의 예고편이 아닙니다. 오히려 Google의 에이전트 제품군이 실제 사용량을 감당하기 위해 필요한 기본 인프라입니다. Pro가 어려운 작업의 최고점을 담당한다면, Flash는 자주 호출되는 작업의 바닥을 만듭니다. 사용량 경제에서 바닥은 매우 중요합니다.
벤치마크가 답하지 못하는 것
물론 공식 벤치마크만으로 에이전트 모델을 판단할 수는 없습니다. 코딩 에이전트의 실제 품질은 모델 답변 하나보다 훨씬 복잡합니다. 어떤 파일을 읽을지 고르는 능력, 테스트 실패를 제대로 해석하는 능력, 불필요한 대규모 수정으로 번지지 않는 절제, 도구 호출의 순서, 사용자에게 승인을 요청해야 하는 지점, 긴 작업을 중단하고 재개하는 방식이 모두 중요합니다.
커뮤니티 반응도 이 지점에서 갈립니다. Google의 수치와 제품 배치에 기대를 거는 개발자는 많습니다. 빠른 Flash 모델이 충분히 강해지면, 이전에는 비용 때문에 제한했던 에이전트 호출을 더 넓게 열 수 있습니다. 반면 회의적인 쪽은 벤치마크 점수와 day-to-day agent experience가 다르다고 봅니다. 실제 IDE에서의 편의성, 모델의 고집, 실패 후 복구, 컨텍스트 누락, 도구 권한 제어가 더 직접적인 체감 품질을 만듭니다.
이 회의는 타당합니다. Gemini 3.5 Flash가 Terminal-Bench나 MCP Atlas에서 높은 점수를 냈다고 해서 모든 저장소에서 안정적인 코딩 에이전트가 되는 것은 아닙니다. 특히 기업 환경에서는 코드베이스 접근 권한, 비밀 정보, 네트워크 정책, 로그 보관, 감사 추적이 중요합니다. 모델이 빠를수록 더 많은 작업을 시도할 수 있지만, 그만큼 잘못된 작업도 빠르게 커질 수 있습니다.
그래서 개발팀이 봐야 할 질문은 "Gemini 3.5 Flash가 Claude나 GPT보다 무조건 좋은가"가 아닙니다. 더 현실적인 질문은 "우리 작업 유형 중 어떤 단계가 빠르고 싼 모델로 내려갈 수 있는가"입니다. 로그 요약과 파일 탐색은 Flash로 충분할 수 있습니다. 설계 판단과 보안 검토는 다른 모델을 써야 할 수 있습니다. 모델 라우팅은 승자독식보다 포트폴리오 운영에 가까워지고 있습니다.
개발팀의 실무 체크리스트
첫째, 작업 단위별 모델 예산을 나눠야 합니다. autocomplete, 채팅, pull request 설명, 테스트 실패 분석, 장기 코딩 에이전트, 문서 검색은 비용 구조가 다릅니다. Gemini 3.5 Flash처럼 낮은 multiplier 또는 빠른 출력 특성을 가진 모델은 반복 호출이 많은 구간에 먼저 맞춰보는 것이 현실적입니다.
둘째, latency와 success rate를 함께 봐야 합니다. 빠른 모델이 한 번에 해결하지 못해 세 번 재시도하면 전체 지연시간과 비용은 오히려 커집니다. 반대로 강한 모델을 모든 탐색 단계에 쓰면 품질 차이를 체감하기 전에 quota가 먼저 소모될 수 있습니다. 에이전트 제품은 평균 latency보다 작업 완료까지의 전체 경로를 측정해야 합니다.
셋째, tool trace를 남겨야 합니다. 모델 라우팅이 들어가면 실패 원인 분석이 어려워집니다. 어떤 모델이 어떤 파일을 읽었고, 어떤 명령을 실행했고, 어떤 테스트 실패를 보고 판단했는지 기록해야 합니다. "모델이 틀렸다"는 말만으로는 다음 라우팅 정책을 고칠 수 없습니다.
넷째, 사용자에게 모델 선택을 모두 떠넘기면 안 됩니다. GitHub Copilot의 모델 선택 UI는 강력하지만, 모든 사용자가 매번 모델 성능표를 읽고 선택하고 싶어하지는 않습니다. 제품은 기본 라우팅을 제공하되, 민감한 작업이나 비용이 큰 작업에서는 사용자가 명시적으로 모델과 예산을 바꿀 수 있게 해야 합니다.
다섯째, Pro급 모델의 역할을 다시 정의해야 합니다. Flash가 충분히 강해질수록 Pro 모델은 "항상 쓰는 기본값"보다 "어려운 판단의 에스컬레이션 경로"가 됩니다. 복잡한 설계 변경, 모호한 버그, 보안 리뷰, 장기 계획은 상위 모델로 올리고, 반복 탐색과 정리 작업은 Flash 계열로 처리하는 식입니다.
경쟁은 모델 점수에서 운영층으로 이동합니다
OpenAI, Anthropic, Google, xAI, Mistral은 모두 모델 성능을 계속 밀어 올리고 있습니다. 하지만 코딩 에이전트와 AI 검색의 경쟁은 모델 점수만으로 끝나지 않습니다. 사용자가 실제로 느끼는 차이는 종종 더 낮은 곳에서 발생합니다. 작업이 빨리 시작되는지, 중간 결과가 보이는지, 실패했을 때 왜 실패했는지 알 수 있는지, quota가 갑자기 소진되지 않는지, 회사 정책에 맞게 모델을 제한할 수 있는지가 제품 선택을 좌우합니다.
Gemini 3.5 Flash는 이 경쟁 축을 잘 보여줍니다. Google은 최고 성능 모델 발표를 기다리지 않고 Flash를 Search, Antigravity, Gemini API, Copilot 같은 표면에 먼저 배치했습니다. 그리고 speed, coding, agentic benchmark, Copilot multiplier라는 신호를 함께 냈습니다. 이 조합은 "더 똑똑한 모델"보다 "더 자주 돌릴 수 있는 에이전트 엔진"에 가깝습니다.
물론 Google이 이 전략에서 자동으로 이기는 것은 아닙니다. Claude Code와 OpenAI Codex 계열은 이미 개발자 경험에서 강한 존재감을 갖고 있습니다. GitHub Copilot은 모델 공급자를 여럿 품는 라우팅 허브가 되고 있습니다. Cursor 같은 도구는 IDE 안의 실제 작업 흐름을 장악하려 합니다. Google은 검색, Android, Workspace, Gemini API, Antigravity라는 넓은 표면을 갖고 있지만, 개발자가 매일 믿고 맡기는 에이전트 경험은 벤치마크가 아니라 반복 사용에서 검증됩니다.
결론: Flash는 보조 모델이 아니라 사용량의 모델입니다
Gemini 3.5 Flash 발표를 단순 모델 출시로 읽으면 핵심을 놓칩니다. 이 발표의 흥미로운 부분은 Pro보다 먼저 실사용 표면에 깔린 Flash가 에이전트 제품의 비용 구조를 드러낸다는 점입니다. 검색이 생성형 UI를 만들고, 코딩 에이전트가 터미널을 다루고, 관리형 에이전트가 샌드박스 안에서 도구를 호출하려면 모델은 한 번이 아니라 계속 불립니다.
그래서 Gemini 3.5 Flash의 질문은 "최고 성능인가"보다 "얼마나 넓게, 얼마나 자주, 얼마나 예측 가능한 비용으로 쓸 수 있는가"에 가깝습니다. Google이 제시한 4배 tokens/sec, Terminal-Bench와 MCP Atlas 수치, GitHub Copilot의 0.25x multiplier는 모두 같은 방향을 가리킵니다. 에이전트 시대의 모델 경쟁은 성능표의 맨 위만이 아니라 사용량을 감당하는 운영층에서 벌어집니다.
개발자와 AI 제품팀은 이 변화를 모델 교체 뉴스로만 넘기기 어렵습니다. 앞으로 제품 안의 AI 호출은 하나의 모델 이름으로 설명되지 않을 가능성이 큽니다. 빠른 모델이 탐색하고, 강한 모델이 판단하고, 긴 컨텍스트 모델이 정리하고, 정책이 민감한 작업을 제한합니다. Gemini 3.5 Flash는 그 라우팅 경쟁에서 Google이 던진 가장 현실적인 카드입니다. Flash가 Pro를 대체한다기보다, Pro가 필요한 순간을 줄이고 에이전트 사용량의 바닥을 넓히는 모델이 되는 것입니다.