14배 요청값 Gemini 3.5 Flash, 빠른 에이전트의 청구서
Gemini 3.5 Flash는 속도와 에이전트 성능을 앞세웠지만 Copilot 14배 요청값과 초기 쿼터 논쟁이 비용 병목을 드러냅니다.

- 무슨 일: Google이 I/O 2026에서
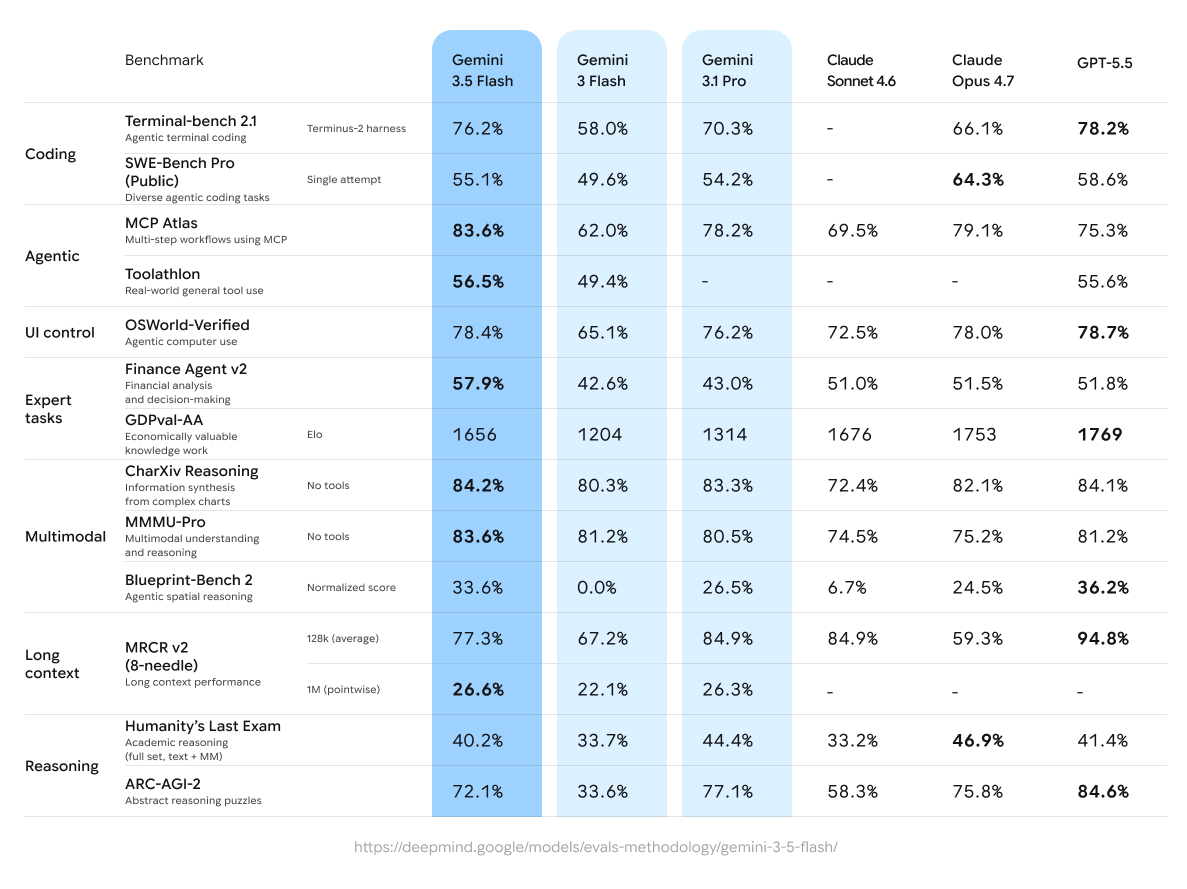
Gemini 3.5 Flash를 공개하고 앱, Search AI Mode, Gemini API, Antigravity, Enterprise에 일반 제공했습니다.- 공식 수치는 Terminal-Bench 2.1 76.2%, MCP Atlas 83.6%, CharXiv Reasoning 84.2%입니다.
- 의미: Google은 Flash 계층을 단순 저가 모델이 아니라 에이전트와 코딩 워크로드의 기본 실행 엔진으로 올리고 있습니다.
- 주의점: GitHub Copilot의 14배 premium request multiplier와 초기 쿼터 불만은 빠른 모델도 에이전트 반복 실행에서는 곧바로 원가 문제가 된다는 신호입니다.
- 속도, 품질, 단가, 쿼터가 따로 움직이면 "Flash"라는 이름만으로 운영 비용을 예측하기 어렵습니다.
Google이 I/O 2026에서 Gemini 3.5 Flash를 공개했습니다. 발표 자체만 보면 익숙한 신모델 뉴스처럼 보입니다. 더 빠르고, 더 똑똑하고, 코딩과 에이전트에 강하며, Gemini 앱과 Search AI Mode에 바로 들어간다는 이야기입니다. 하지만 이번 발표에서 개발자가 봐야 할 지점은 모델 이름보다 배치 방식입니다. Google은 Flash 계층을 "작고 저렴한 보조 모델"이 아니라, 24시간 개인 에이전트와 코딩 에이전트, 검색의 생성형 UI, 기업 자동화 워크플로를 돌리는 기본 엔진으로 올리고 있습니다.
공식 발표는 2026년 5월 19일에 나왔습니다. Google은 Gemini 3.5 발표문에서 3.5 Flash를 "frontier intelligence with action"이라는 새 계열의 첫 모델로 소개했습니다. 제공 범위도 넓습니다. Gemini 앱과 Google Search의 AI Mode, 개발자용 Google Antigravity, Gemini API in Google AI Studio, Android Studio, Gemini Enterprise Agent Platform, Gemini Enterprise에 들어갑니다. 같은 날 개발자 하이라이트에서는 Antigravity 2.0 desktop app, Managed Agents in the Gemini API, AI Studio의 Android 앱 생성까지 함께 묶었습니다.
이 조합은 Google의 방향을 꽤 분명하게 보여줍니다. Gemini 3.5 Flash는 채팅 답변을 빠르게 만드는 모델이 아니라, 여러 표면에서 에이전트가 실제 작업을 반복 실행할 때 쓰는 모델입니다. Google은 3.5 Flash가 Terminal-Bench 2.1에서 76.2%, GDPval-AA에서 1656 Elo, MCP Atlas에서 83.6%, CharXiv Reasoning에서 84.2%를 기록했다고 밝혔습니다. 개발자 포스트에서는 Gemini 3.1 Pro를 거의 모든 벤치마크에서 앞서며 다른 frontier model보다 4배 빠르다고 설명했습니다. 이름은 Flash이지만 포지셔닝은 "빠른 보급형"이 아니라 "대규모 에이전트 실행의 기본값"에 가깝습니다.
흥미로운 점은 이 발표가 Gemini Spark와 맞물려 있다는 것입니다. Google은 Gemini 앱 발표에서 월간 9억 명 이상이 230개국, 70개 이상 언어에서 Gemini를 사용한다고 밝혔고, Gemini Spark를 24시간 개인 AI 에이전트로 소개했습니다. Spark는 3.5 Flash를 사용합니다. trusted tester 대상으로 먼저 롤아웃하고, 다음 주 미국 Google AI Ultra 가입자에게 Beta를 제공한다는 계획도 함께 나왔습니다. 즉 3.5 Flash는 "앱 안에서 답하는 모델"이면서 동시에 사용자의 디지털 생활을 따라다니는 에이전트의 실행층입니다.
개발자에게 더 직접적인 표면은 Antigravity와 GitHub Copilot입니다. Google은 Antigravity를 아이디어에서 production-ready app까지 이어주는 agent-first development platform이라고 설명합니다. 3.5 Flash는 여기서 하위 에이전트를 병렬로 움직이고, 긴 작업을 반복하며, 코드베이스 유지보수와 문서·재무 작업 같은 장시간 워크플로를 처리하는 엔진으로 제시됩니다. 발표문에는 AlphaZero 논문을 합성하고 6시간 동안 게임을 만드는 데 두 에이전트를 쓰는 사례, 레거시 코드베이스를 Next.js로 바꾸는 사례, 도시 풍경을 생성하는 하위 에이전트 사례가 나옵니다.
하지만 바로 여기서 비용 문제가 등장합니다. 에이전트는 한 번 답하고 끝나는 챗봇과 다릅니다. 계획을 세우고, 파일을 읽고, 도구를 호출하고, 실패하면 다시 시도하고, 로그를 해석하고, 테스트를 돌리고, 결과를 요약합니다. 모델이 빠르면 이 루프는 더 촘촘해집니다. 빠른 모델은 사용자가 더 자주 실행하게 만들고, 에이전트 프레임워크는 더 많은 중간 단계를 자동으로 생성합니다. 그래서 Flash급 속도가 곧 낮은 비용으로 이어진다고 단정하기 어렵습니다. 모델 단가가 낮아도 반복 횟수와 토큰 사용량이 늘면 총비용은 올라갈 수 있습니다.
GitHub의 Copilot 발표는 이 긴장을 숫자로 보여줍니다. GitHub는 2026년 5월 19일 Gemini 3.5 Flash를 Copilot에 일반 제공한다고 발표했습니다. Visual Studio Code, Visual Studio, JetBrains, Xcode, Eclipse에서 선택할 수 있고, Copilot Pro, Pro+, Business, Enterprise 사용자에게 제공됩니다. 핵심 문장은 가격 부분입니다. GitHub는 이 모델이 출시 시점에 14배 premium request multiplier로 시작하며, 가격은 잠정적이고 바뀔 수 있다고 적었습니다.
14배라는 숫자는 단순한 가격표 이상입니다. Copilot 같은 도구에서 사용자는 "한 번의 요청"을 누르지만, 내부에서는 모델별 단가, 컨텍스트 캐시 효율, 도구 호출, 장기 작업의 재시도 비용이 모두 합쳐집니다. GitHub는 Gemini 3.5 Flash가 near-Pro coding quality, Flash-tier speed and cost, strong tool use, fast response, high cache efficiency를 보인다고 설명합니다. 동시에 14배 요청값을 붙였습니다. 이 조합은 빠른 모델의 경제성이 아직 간단한 문제가 아니라는 점을 드러냅니다. "Flash"라는 이름이 사용자의 체감 비용을 자동으로 낮춰주지는 않습니다.
커뮤니티 반응도 같은 방향입니다. 2026년 5월 22일 기준 Hacker News나 GeekNews에서 Gemini 3.5 Flash 단독 토론이 크게 번진 흔적은 아직 뚜렷하지 않습니다. 대신 Reddit의 Antigravity와 모델 벤치마크 커뮤니티에서는 빠른 체감과 쿼터 불만이 동시에 나옵니다. r/google_antigravity의 한 사용자는 3.5 Flash high 모드로 설정과 마이그레이션 문제를 고치는 데 42분을 썼을 뿐인데 사용량이 급격히 줄었다고 적었습니다. 다른 댓글들은 이전 Gemini 3 Flash에서는 하루 종일 반복 작업을 해도 제한이 덜했지만, 3.5 Flash에서는 30분 안팎에 제한을 만났다고 주장했습니다.
물론 Reddit 반응은 표본도 작고, 사용자의 플랜과 지역, 실제 요청 패턴을 통제하지 않습니다. 그대로 일반화하면 위험합니다. 그래도 초기 사용자의 불만이 어디에 집중되는지는 볼 수 있습니다. 품질이 나쁘다는 불만보다 "좋은데 너무 빨리 닳는다"는 반응이 많습니다. r/mlscaling에서는 280 output tokens/s 이상이라는 속도 주장을 공유하면서도, 토큰 단가와 토큰 사용량 때문에 자체 계산 기준에서 Gemini 3 Flash보다 비용이 크게 올랐다는 논의가 나왔습니다. r/GithubCopilot에서는 14배 request multiplier가 다른 고급 모델과 어떻게 비교되는지 따지는 댓글이 이어졌습니다.
이 대목에서 Gemini 3.5 Flash를 단순히 Google의 신모델로 보면 놓치는 것이 있습니다. 지금 AI 개발 도구 시장은 "누가 가장 강한 모델을 갖고 있는가"에서 "어떤 모델을 어떤 작업에 자동 배치할 것인가"로 움직이고 있습니다. GitHub Copilot은 모델 선택기와 자동 라우팅을 강화하고 있습니다. OpenAI Codex는 앱, CLI, IDE, 클라우드 작업, 자동화로 표면을 넓히고 있습니다. Anthropic Claude Code는 긴 작업과 기업 사용을 파고듭니다. Google은 Antigravity와 Gemini API, AI Studio, Android Studio를 묶고, Flash 계층을 실행 모델로 밀고 있습니다.
이 경쟁에서 빠른 모델은 두 가지 역할을 합니다. 첫째, 사람과의 대화 지연을 줄입니다. 코딩 도구에서 2초와 20초의 차이는 사용 패턴을 바꿉니다. 둘째, 에이전트 내부 루프의 단가를 낮추려는 시도입니다. planner, researcher, builder, reviewer 같은 여러 역할을 모두 큰 모델에 맡기면 비용이 폭발합니다. 그래서 플랫폼은 작은 모델, 빠른 모델, 캐시 효율이 높은 모델을 기본으로 두고, 어려운 단계에서만 더 비싼 모델을 호출하려 합니다. Gemini 3.5 Flash가 중요한 이유는 바로 이 계층화 전략의 후보이기 때문입니다.
하지만 에이전트 경제성은 모델 단가 하나로 결정되지 않습니다. 실제 비용을 좌우하는 변수는 더 많습니다. 컨텍스트가 얼마나 길게 유지되는지, 캐시가 얼마나 재사용되는지, 도구 호출 전후에 모델이 몇 번 추론하는지, 실패한 테스트를 몇 번 반복하는지, 하위 에이전트가 병렬로 몇 개 뜨는지, 사용자에게 보이지 않는 검증 단계가 얼마나 많은지에 따라 청구서는 달라집니다. Google이 "빠르고 강한 Flash"를 제시해도, Copilot이 14배 요청값을 붙이고 Antigravity 사용자가 쿼터를 걱정한다면 실무자는 총 사용량 모델을 다시 계산해야 합니다.
개발팀이 지금 확인해야 할 질문은 명확합니다. 첫째, Gemini 3.5 Flash를 어디에 쓸 것인가입니다. 단발성 코드 완성, 파일 단위 리팩터링, 테스트 수정, 브라우저 조작, 장시간 마이그레이션은 사용량 패턴이 다릅니다. 둘째, 모델 선택을 사람이 직접 할 것인지, 플랫폼의 자동 라우팅에 맡길 것인지입니다. 자동 라우팅은 편하지만 비용 설명 가능성이 낮아질 수 있습니다. 셋째, 성공 기준을 벤치마크 점수로 둘 것인지, 작업당 완성 비용으로 둘 것인지입니다. 에이전트 운영에서는 "한 번에 맞혔는가"보다 "몇 번의 루프와 얼마의 비용으로 안전하게 끝냈는가"가 더 중요합니다.
특히 코딩 에이전트에서는 Flash 계층의 장점과 위험이 동시에 커집니다. 빠른 모델은 작은 수정, 테스트 에러 해석, 로그 요약, 파일 탐색, 반복적인 코드 생성에서 매우 유용합니다. 반대로 큰 설계 변경, 모호한 요구사항, 보안 민감 작업, 데이터 삭제 위험이 있는 작업에서는 빠른 실행이 오히려 리스크가 될 수 있습니다. 하위 에이전트를 여러 개 띄워 병렬로 시도하는 방식은 성공 확률을 올릴 수 있지만, 토큰과 요청량도 함께 늘립니다. 따라서 빠른 모델을 도입할수록 권한, 샌드박스, 검증, 예산 제한이 함께 설계돼야 합니다.
Google의 발표가 흥미로운 이유는 이 문제가 소비자 앱과 개발자 도구를 동시에 관통하기 때문입니다. Gemini 앱에서는 3.5 Flash가 기본 모델이 되고, Spark는 사용자의 일상 작업을 대신 처리하는 24시간 에이전트가 됩니다. 개발자 표면에서는 Antigravity와 AI Studio가 같은 모델을 작업 실행에 사용합니다. 기업 표면에서는 Gemini Enterprise Agent Platform이 워크플로 자동화를 겨냥합니다. 결국 한 모델 계층이 검색, 개인 비서, 코딩 도구, 기업 자동화의 공통 실행 엔진으로 쓰이는 셈입니다. 규모가 커질수록 작은 단가 차이와 쿼터 정책은 제품 경험 전체를 좌우합니다.
경쟁사도 같은 문제를 피할 수 없습니다. OpenAI Codex가 더 많은 사용자와 자동화를 끌어들이면 rate limit과 프로모션 정책은 곧 제품 경험이 됩니다. Anthropic Claude Code가 기업 개발팀 깊숙이 들어가면 Opus와 Sonnet의 작업 배분, 장시간 세션 비용, 팀 단위 사용량 관리가 중요해집니다. GitHub Copilot은 이미 모델별 premium request multiplier를 통해 사용자에게 모델 선택의 비용 신호를 노출하고 있습니다. Google의 Gemini 3.5 Flash는 이 시장에서 "빠른 모델로 에이전트 비용을 낮춘다"는 명제를 시험하는 가장 큰 사례 중 하나가 됐습니다.
그래서 이번 발표의 핵심은 "Gemini 3.5 Flash가 Gemini 3.1 Pro보다 낫다"가 아닙니다. 더 중요한 질문은 "Flash 계층이 에이전트 운영의 기본 단위가 될 만큼 충분히 빠르고, 충분히 좋고, 충분히 예측 가능한가"입니다. 공식 벤치마크와 Google의 배포 범위는 첫 두 조건에 힘을 실어줍니다. 하지만 Copilot의 14배 요청값과 초기 쿼터 반응은 세 번째 조건, 즉 예측 가능한 경제성이 아직 논쟁 중임을 보여줍니다.
실무적으로는 Gemini 3.5 Flash를 도입할 때 모델 성능표만 보지 않는 편이 좋습니다. 작은 파일 수정 100건, 테스트 실패 자동 수정 20건, 브라우저 기반 회귀 테스트 10건처럼 실제 워크로드 단위로 측정해야 합니다. 성공률, 평균 루프 수, 요청 배수, 토큰 사용량, 캐시 적중률, 사람이 개입한 횟수를 같이 봐야 합니다. 빠른 모델은 개발자의 기다림을 줄일 수 있지만, 자동 반복이 늘어나면 예산을 더 빨리 소모할 수도 있습니다.
Gemini 3.5 Flash는 Google이 에이전트 시대의 모델 계층을 어떻게 재배치하는지 보여주는 신호입니다. Pro급 품질에 가까운 Flash, 검색과 앱의 기본 모델, Antigravity의 실행 엔진, Copilot의 새 선택지라는 조합은 충분히 큽니다. 그러나 이번 뉴스의 더 날카로운 부분은 숫자 사이의 긴장입니다. 76.2% Terminal-Bench, 4배 속도, 14배 요청값이 한 화면에 놓이면 질문이 바뀝니다. 이제 에이전트 모델 경쟁은 누가 더 빨리 답하는가만이 아니라, 누가 그 빠른 반복을 예측 가능한 비용으로 운영하게 해주는가의 싸움입니다.