65% IDE 선택지, 코딩 에이전트의 조달 시험
Gartner의 기업 AI 코딩 에이전트 평가와 OpenAI, Cursor, GitHub 발표는 AI 코딩 경쟁이 모델 성능에서 거버넌스와 조달로 이동했음을 보여줍니다.
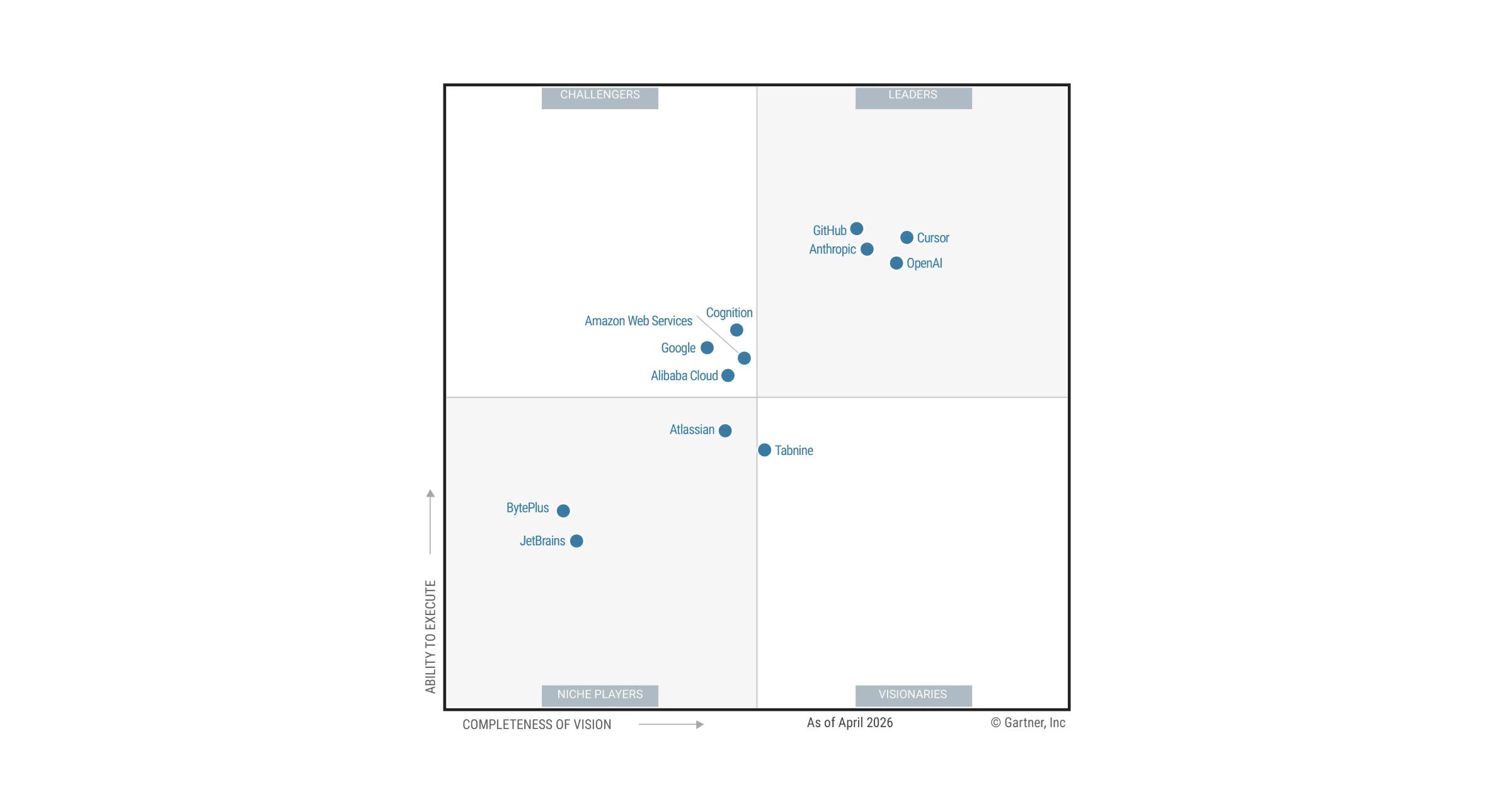
- 무슨 일: Gartner가 Enterprise AI Coding Agents를 별도 시장으로 다루며 2026년 평가를 공개했습니다.
- OpenAI, Cursor, GitHub가 같은 주 자사 리더 포지션과 사용량, 기업 채택 수치를 앞세웠습니다.
- 핵심 숫자: Gartner는 2027년 agentic coding 팀의 65% 이상이 IDE를 선택지로 볼 것이라고 예측했습니다.
- 의미: AI 코딩 경쟁은
자동완성에서 SDLC 운영, 감사, 가격, 권한, 조달 성숙도로 이동합니다. - 주의점: Magic Quadrant는 구매 참고 자료일 뿐입니다. 실제 도입에서는 코드 품질보다 권한 경계와 책임 소재가 먼저 깨질 수 있습니다.
- Gartner도 제품 모멘텀만으로는 기업 채택을 설명할 수 없다고 강조했습니다.
Gartner가 2026년 5월 20일 기업용 AI 코딩 에이전트 시장을 정면으로 다루는 자료를 공개했습니다. 보도자료 제목은 시장이 "확장과 경쟁 재편의 새 단계"에 들어섰다는 것입니다. 이것만 보면 흔한 애널리스트 리포트처럼 보일 수 있습니다. 그러나 이번 사건은 코딩 에이전트 경쟁의 기준이 바뀌고 있다는 꽤 선명한 신호입니다.
지난 1년 동안 AI 코딩 도구의 공개 논쟁은 주로 모델 성능, IDE 경험, 자동완성 품질, benchmark 점수, "얼마나 긴 작업을 맡길 수 있는가"에 집중됐습니다. 하지만 Gartner가 잡은 시장 언어는 다릅니다. 보도자료는 frontier model provider가 stack 위로 올라오고, agentic workflow가 늘고, SDLC 전반으로 범위가 넓어지고, 가격과 ROI가 더 복잡해졌다고 설명합니다. 즉 "좋은 코드를 써주는가"보다 "기업이 이 시스템을 어떤 통제 아래 살 수 있는가"가 앞에 놓이기 시작했습니다.
이 변화는 같은 날 전후로 나온 벤더들의 반응에서도 드러납니다. OpenAI는 Codex가 Gartner Magic Quadrant for Enterprise AI Coding Agents에서 Leader로 인정받았다고 발표하며, Codex가 매주 400만 명 이상에게 사용되고 Cisco, Datadog, Dell Technologies, NVIDIA 같은 기업에서 쓰인다고 밝혔습니다. Cursor는 Fortune 500의 70% 이상이 Cursor를 사용한다고 주장하며, Completeness of Vision 축에서 가장 멀리 배치됐다고 설명했습니다. GitHub는 Copilot이 14만 조직에 쓰이고 전년 대비 100% 이상 성장했다고 밝혔습니다. 세 회사 모두 "우리 모델이 코드를 잘 씁니다"가 아니라 "우리 플랫폼은 기업이 살 수 있는 운영 체계입니다"라고 말하고 있습니다.
IDE 중심 개발의 다음 단계
Gartner가 가장 강하게 던진 숫자는 65%입니다. 2027년까지 agentic coding을 쓰는 엔지니어링 팀의 65% 이상이 IDE를 선택적 도구로 보게 되고, 통제와 거버넌스와 검증이 자동화 플랫폼으로 이동할 것이라는 예측입니다. 이 문장은 개발자에게 꽤 도발적입니다. IDE는 지난 수십 년 동안 개발자의 작업 공간이었습니다. 코드를 읽고, 검색하고, 테스트를 실행하고, 디버깅하고, 커밋 전 변경을 검토하는 중심이 IDE였습니다.
하지만 코딩 에이전트가 비동기 작업을 맡기 시작하면 중심은 달라집니다. 개발자가 모든 편집을 직접 하는 대신 이슈를 할당하고, 에이전트가 브랜치를 만들고, 테스트를 돌리고, PR을 열고, 리뷰 코멘트를 반영하고, 보안 검사를 통과해야 합니다. 이 흐름에서 IDE는 여전히 중요하지만 유일한 제어면은 아닙니다. GitHub 웹, cloud agent dashboard, CLI, desktop app, issue tracker, CI, security scanner, policy engine이 함께 제어면이 됩니다.
이 변화는 "IDE가 사라진다"는 뜻이 아닙니다. 오히려 IDE가 개발자의 손도구에서 에이전트 운영 시스템의 여러 표면 중 하나가 된다는 뜻에 가깝습니다. 개발자는 여전히 어려운 설계와 검토를 IDE에서 할 것입니다. 다만 agentic coding이 커질수록 팀장은 "어떤 IDE를 쓰는가"보다 "에이전트가 어디서 실행되고, 어떤 권한으로 저장소를 읽고, 어떤 변경은 사람 승인 없이는 못 하고, 비용은 누가 추적하는가"를 먼저 묻게 됩니다.
평가표가 모델 성능 밖으로 넓어졌습니다
Gartner Critical Capabilities 초록을 보면 이 시장이 어디까지 넓어졌는지 보입니다. 포함된 벤더는 Alibaba Cloud, AWS, Anthropic, Atlassian, BytePlus, Cognition, Cursor, GitHub, Google Cloud, JetBrains, OpenAI, Tabnine입니다. 비교 항목도 단순한 code completion이 아닙니다. 동기 개발, 비동기 개발, 애플리케이션 전달, 테스트와 디버깅, context enrichment and selection, 코드 번역, 문서화, 요구사항 관리, 배포 유형과 모델 선택, 코드 리뷰, analytics dashboard, spec-driven development, custom specialized agents, FinOps, agent governance까지 들어갑니다.
이 목록은 현재 코딩 에이전트 시장의 진짜 전장을 보여줍니다. 모델이 한 파일을 잘 고치는지는 이제 시작점입니다. 기업 구매자는 "우리 monorepo를 얼마나 잘 이해하는가", "PR 리뷰와 보안 게이트에 어떻게 들어오는가", "개발자가 아닌 관리자도 비용과 위험을 볼 수 있는가", "모델을 바꾸거나 배포 위치를 통제할 수 있는가", "감사 로그가 남는가", "에이전트가 실패했을 때 책임 흐름이 있는가"를 봅니다.
| 이전 평가 질문 | 새 평가 질문 | 실무상 의미 |
|---|---|---|
| 코드를 잘 완성하는가 | 이슈에서 PR까지 맡길 수 있는가 | 단일 편집보다 비동기 작업 관리가 중요해집니다. |
| 어떤 모델이 더 똑똑한가 | 모델 선택과 배포 위치를 통제할 수 있는가 | 규제 산업과 대기업은 모델 성능만으로 구매하지 않습니다. |
| 개발자가 좋아하는가 | 관리자가 비용, 권한, 감사 로그를 볼 수 있는가 | DX와 거버넌스가 같은 제품 안에서 충돌합니다. |
| 테스트를 실행하는가 | 검증과 승인을 조직 정책으로 강제할 수 있는가 | 에이전트의 속도보다 변경의 설명 가능성이 중요해집니다. |
이 지점에서 코딩 에이전트는 일반 개발자 도구와 다르게 행동합니다. 린터나 formatter는 실패해도 영향이 제한적입니다. 하지만 에이전트는 파일을 읽고, 명령을 실행하고, 네트워크를 호출하고, test fixture를 만들고, PR을 열고, 때로는 배포 파이프라인을 건드립니다. 그래서 기업은 "이 도구가 생산성을 얼마나 높이는가"와 함께 "어디까지 권한을 줄 것인가"를 동시에 결정해야 합니다.
OpenAI, Codex를 기업 운영층으로 설명하다
OpenAI 발표에서 눈에 띄는 부분은 Codex의 사용량보다 설명 방식입니다. OpenAI는 Codex가 매주 400만 명 이상에게 사용된다고 밝혔습니다. 이 숫자 자체도 큽니다. 그러나 더 중요한 것은 OpenAI가 Codex를 "코딩 모델"이 아니라 enterprise software development workflow를 지원하는 agentic system으로 설명한다는 점입니다.
OpenAI가 강조한 항목은 Codex app, IDE extension, CLI, SDK, cloud-based orchestration 같은 developer surface입니다. 여기에 approval gates, RBAC, customizable policies, OS-level sandboxing, auditable workspace governance 같은 enterprise control을 붙였습니다. 이는 Codex가 더 이상 단일 채팅창이나 CLI가 아니라, 여러 실행 표면과 정책 계층을 가진 개발 운영 인프라로 팔리고 있다는 뜻입니다.
OpenAI는 Cisco 사례도 전면에 배치했습니다. Cisco가 AI Defense 보안 플랫폼의 다수 부분을 Codex로 개발해, 몇 분기 걸릴 수 있던 작업을 몇 주로 줄였다는 주장입니다. 이 사례의 메시지는 단순한 생산성입니다. 하지만 기업 구매자가 실제로 보는 메시지는 더 구체적입니다. "보안 제품 같은 중요한 코드에도 agent를 넣을 수 있는가", "그 과정에서 검토와 통제가 가능했는가"입니다. OpenAI가 Gartner 발표와 함께 이 사례를 꺼낸 이유도 여기에 있습니다.
Cursor는 개발자 경험에서 기업 플랫폼으로 이동 중입니다
Cursor의 발표는 다른 방향에서 같은 결론에 도달합니다. Cursor는 Gartner가 자사를 Leader로 지정했고, Completeness of Vision에서 가장 멀리 배치했다고 설명했습니다. 동시에 Fortune 500의 70% 이상이 Cursor를 사용한다고 밝혔습니다. 이 숫자는 Cursor가 개인 개발자와 스타트업 사이의 인기 도구를 넘어 대기업 구매 논의 안으로 들어갔다는 신호입니다.
Cursor가 제시한 다음 방향도 흥미롭습니다. 첫째는 장시간 코딩 에이전트를 위한 frontier intelligence입니다. 둘째는 Bugbot, security agents, Automations, Cursor SDK 같은 SDLC 전반 자동화입니다. 셋째는 admin integration, agent controls, analytics dashboard, self-hosted cloud agents 같은 기업 통제입니다. 이것은 Gartner의 평가 항목과 거의 같은 언어입니다. 즉 Cursor도 이제 "좋은 AI IDE"만으로는 충분하지 않다는 점을 알고 있습니다.
최근 Cursor Cloud Agent 회고에서 이미 비슷한 흐름이 보였습니다. 클라우드 에이전트의 어려움은 모델보다 VM, indexing, 권한, Temporal 같은 운영층에 있었습니다. 이번 Gartner 발표는 그 운영층이 단순한 내부 구현 문제가 아니라 시장 평가 기준이 됐다는 점을 보여줍니다. 개발자에게 부드러운 에디터 경험을 주는 회사도 결국 구매자에게는 보안, 비용, 관리, 지역, self-hosting 옵션을 설명해야 합니다.
GitHub는 SDLC 홈그라운드를 앞세웁니다
GitHub의 메시지는 더 노골적으로 SDLC입니다. GitHub는 Gartner가 Copilot을 3년 연속 Leader로 인정했다고 발표하면서, 병목이 code generation에서 shipping software로 이동했다고 말했습니다. 리뷰, 보안, 거버넌스, 배포가 병목이라는 것입니다. GitHub는 Copilot이 14만 조직에서 쓰이고, 전년 대비 100% 이상 성장했으며, CLI 사용량이 월간 거의 두 배씩 늘고 있다고 밝혔습니다.
GitHub가 강한 지점은 명확합니다. 이슈, PR, Actions, code review, security scanning, repository permission이 이미 GitHub 안에 있습니다. 코딩 에이전트가 실제 조직에서 일하려면 이런 표면을 건드려야 합니다. 별도 IDE나 CLI가 아무리 좋더라도 최종 변경은 저장소와 PR과 배포 파이프라인으로 들어갑니다. GitHub는 바로 그 홈그라운드를 갖고 있습니다.
GitHub는 Gartner가 비동기 AI 코딩 에이전트 워크플로가 2028년까지 소프트웨어 엔지니어링 생산성을 30-50% 높일 수 있다고 예측했다고 인용했습니다. 이 숫자는 조심해서 읽어야 합니다. 생산성은 팀 구조, 코드베이스 품질, 테스트 성숙도, 리뷰 문화, 에이전트 권한 설계에 따라 크게 달라집니다. 하지만 GitHub가 이 수치를 가져온 방식은 분명합니다. "자동완성은 0-20%의 도구였고, 비동기 에이전트는 더 큰 workflow redesign의 도구"라는 주장입니다.
왜 조달이 기술보다 어려운가
코딩 에이전트 시장이 기업 조달 카테고리가 되면 어려움은 더 복잡해집니다. 개발자는 "써보니 좋다"라고 말할 수 있습니다. 보안팀은 "어떤 데이터가 어디로 가는가"를 묻습니다. 법무팀은 "생성 코드의 책임과 라이선스는 무엇인가"를 묻습니다. 재무팀은 "토큰 비용과 agent run 비용을 프로젝트별로 나눌 수 있는가"를 묻습니다. 플랫폼팀은 "이 도구가 self-hosted runner, VPC, SSO, SCIM, RBAC, audit log와 붙는가"를 묻습니다.
Gartner가 보도자료에서 product excellence와 momentum만으로는 충분하지 않다고 한 이유가 여기 있습니다. 공개 데모에서 강한 도구와 기업 전체에 배포할 수 있는 도구는 다릅니다. 특히 코딩 에이전트는 일반 SaaS보다 사고 반경이 큽니다. 저장소 전체를 읽을 수 있고, secret이 들어 있는 설정 파일을 볼 수 있고, migration을 수정할 수 있고, shell command를 실행할 수 있습니다. 따라서 조달 질문은 귀찮은 절차가 아니라 시스템 설계의 일부입니다.
Reddit의 기업 agent 관련 토론에서도 반복되는 회의론은 비슷합니다. 데모를 만드는 것은 쉬워졌지만, 실제 기업 환경에서 비용 가시성, 책임 소재, 감사 로그, 보안 검토, 데이터 위치를 해결하는 것이 어렵다는 의견입니다. 특히 "agent가 무엇을 했는지 설명할 수 있는가"는 작은 팀보다 대기업에서 훨씬 큰 문제입니다. 사람이 직접 코드를 썼을 때도 버그는 납니다. 그러나 agent가 쓴 코드가 배포 사고를 만들면 조직은 "누가 승인했고, 어떤 정책이 작동했고, 어떤 로그가 남았는가"를 물을 수밖에 없습니다.
개발자에게는 선택지가 늘고, 팀에는 표준화 압력이 옵니다
개인 개발자에게 이 시장 재편은 좋은 일처럼 보입니다. Codex, Cursor, Copilot, Claude Code, JetBrains, Cognition, Tabnine, Google Cloud, AWS 같은 선택지가 경쟁하면 기능은 빨리 좋아집니다. 모델 선택도 넓어지고, IDE 밖 실행 표면도 늘고, cloud agent와 local agent가 함께 발전합니다. 실제로 많은 개발자는 여러 도구를 동시에 씁니다. 한 도구로 설계를 시키고, 다른 도구로 구현하고, 또 다른 도구로 리뷰하는 방식도 자연스러워졌습니다.
하지만 팀 단위로 가면 표준화 압력이 생깁니다. 모든 개발자가 서로 다른 에이전트에 저장소 권한을 주고, 서로 다른 MCP 서버를 붙이고, 서로 다른 billing account로 실행하면 관리가 어렵습니다. 같은 코드베이스에 여러 에이전트가 서로 다른 규칙 파일을 읽으면 지식이 갈라집니다. 어떤 에이전트는 보안 정책을 알고, 어떤 에이전트는 모릅니다. 어떤 에이전트는 내부 API를 호출할 수 있고, 어떤 에이전트는 못 합니다. 이 차이는 생산성보다 운영 리스크로 먼저 보일 수 있습니다.
그래서 기업은 결국 플랫폼을 고르려고 합니다. 단일 도구만 쓰겠다는 뜻은 아닙니다. 다만 SSO, RBAC, audit log, data retention, model routing, policy, cost dashboard, approved connectors를 공통 계층으로 묶으려 할 가능성이 큽니다. Gartner의 시장 정의가 중요한 이유도 여기에 있습니다. 시장이 이름을 얻으면 예산 항목이 생기고, 비교표가 생기고, 구매 프로세스가 생깁니다. 코딩 에이전트는 개발자 개인의 생산성 도구에서 CIO와 플랫폼 조직의 관리 대상으로 올라갑니다.
좋은 질문은 "누가 이겼나"가 아닙니다
Magic Quadrant가 나오면 자연스럽게 누가 위에 있고 누가 아래에 있는지 보게 됩니다. 그러나 이번 뉴스에서 더 중요한 질문은 순위가 아닙니다. 좋은 질문은 "우리 조직의 코딩 에이전트 운영 모델은 무엇인가"입니다. 어떤 작업을 에이전트에게 맡길지, 어떤 저장소는 제외할지, 어떤 변경은 사람 승인 없이는 못 하게 할지, 테스트 실패 시 자동 수정까지 허용할지, 외부 네트워크 호출은 막을지, 비용 한도는 어떻게 둘지 정해야 합니다.
또 하나의 질문은 "개발자의 주도권을 어떻게 유지할 것인가"입니다. 에이전트가 더 많은 작업을 처리할수록 개발자는 직접 타이핑하는 시간보다 지시, 검토, 승인, rollback, 품질 기준 정의에 더 많은 시간을 쓰게 됩니다. 이것은 생산성을 높일 수도 있지만, 나쁜 설정에서는 개발자를 agent output reviewer로 가둘 수도 있습니다. 그래서 팀은 에이전트가 만든 PR의 크기, 변경 범위, 테스트 증거, 설명 형식을 관리해야 합니다. 빠른 agent보다 작은 diff와 좋은 증거를 남기는 agent가 더 가치 있을 수 있습니다.
마지막 질문은 "벤더 lock-in을 어떻게 다룰 것인가"입니다. Cursor는 IDE와 agent runtime 경험이 강합니다. GitHub는 저장소와 SDLC 통합이 강합니다. OpenAI는 모델과 Codex 생태계, sandbox, 여러 표면을 밀고 있습니다. Anthropic은 Claude Code와 MCP 주변 생태계에서 강한 존재감을 갖고 있습니다. 어느 하나가 모든 상황에서 정답이 되기는 어렵습니다. 기업은 모델, 실행 환경, 저장소 권한, 지식 베이스, 정책, billing을 분리할 수 있는 구조를 선호하게 될 것입니다.
결론은 운영 가능한 AI 코딩입니다
이번 Gartner 발표의 의미는 코딩 에이전트가 성숙했다는 선언이 아닙니다. 오히려 이제부터 더 까다로운 질문을 받게 됐다는 신호입니다. 에이전트가 코드를 쓸 수 있다는 것은 이미 많은 팀이 경험했습니다. 다음 질문은 그 에이전트를 수백 명, 수천 명 개발자가 쓰는 조직에서 어떻게 운영하느냐입니다. 권한, 비용, 감사, 검증, 책임, 배포 위치, 모델 선택, 데이터 정책이 같은 문장 안으로 들어옵니다.
OpenAI의 400만 명 주간 사용량, Cursor의 Fortune 500 70% 이상 사용 주장, GitHub의 14만 조직 수치는 모두 시장이 커졌다는 증거입니다. 그러나 시장이 커질수록 구매자는 더 까다로워집니다. 자동완성은 개인이 켜고 끌 수 있었습니다. 코딩 에이전트는 조직의 개발 프로세스를 바꿉니다. 이 차이가 이번 주 Gartner가 포착한 핵심입니다.
개발자에게 실용적인 결론은 간단합니다. 코딩 에이전트를 평가할 때 더 이상 "답변이 똑똑한가"만 보지 말아야 합니다. 저장소 이해, 테스트 실행, 브라우저 검증, PR 설명, 권한 제한, 로그, 비용 추적, 실패 후 복구를 함께 봐야 합니다. 팀 리더에게는 더 직접적입니다. 지금 필요한 것은 멋진 데모가 아니라 운영 가능한 AI 코딩 정책입니다. 2026년의 코딩 에이전트 경쟁은 모델을 고르는 싸움으로 시작했지만, 기업 안에서는 조달과 거버넌스의 시험으로 이어지고 있습니다.