160ms 액션 채널, 음성 에이전트가 말하며 도구 쓰는 조건
DuplexSLA 논문은 실시간 음성 에이전트의 병목을 ASR 뒤 LLM이 아니라 160ms 액션 채널과 도구 호출 시간축으로 재정의합니다.
- 무슨 일: StepFun 등 연구진이
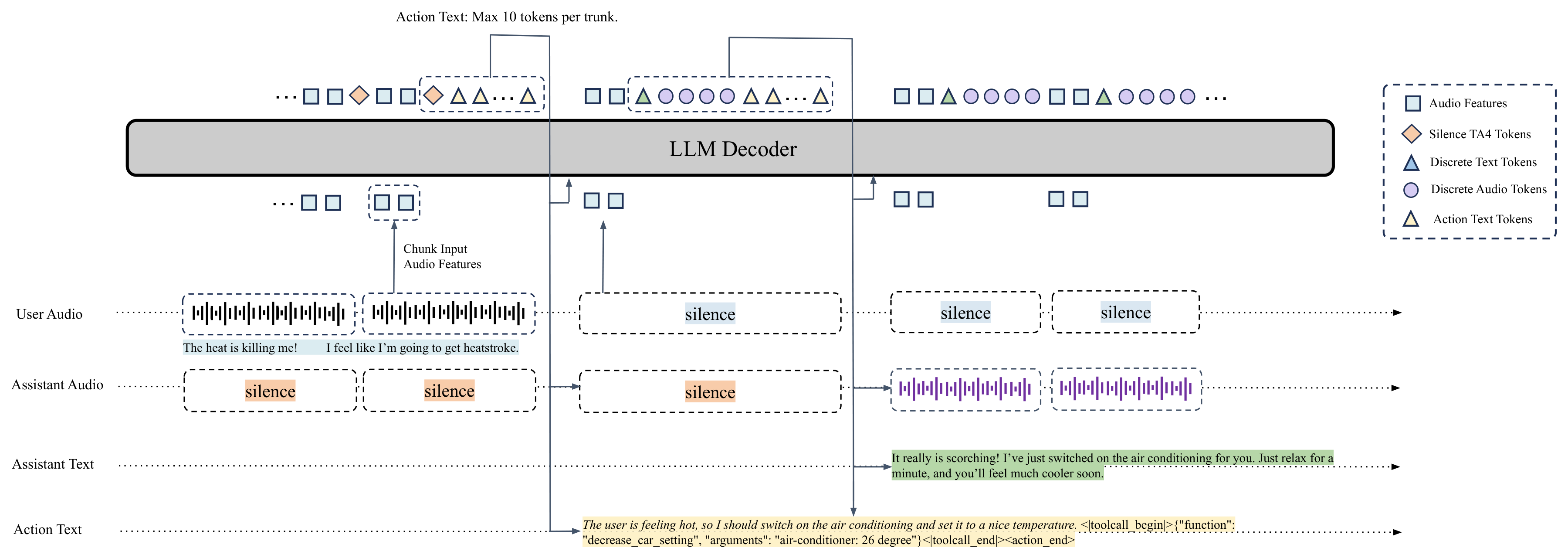
DuplexSLA논문을 공개했습니다.- 듣기, 말하기, 계획, 도구 호출을 160ms 청크의 같은 시간축에 올리는 Speech-Language-Action 구조입니다.
- 핵심 수치: DuplexSLA-Bench tool-call 지연은 0.64초, ASR+LLM cascade는 2.77초입니다.
- 의미: 음성 에이전트 경쟁이 음질보다
action channel설계로 이동합니다.- 다만 checkpoint, inference code, 벤치 데이터는 아직 공개 예정 상태라 재현 검증은 남아 있습니다.
음성 에이전트의 오래된 약점은 말소리를 잘 알아듣지 못한다는 문제만이 아닙니다. 실제 사용자가 말을 할 때는 문장을 끝까지 말하지 않고 잠깐 멈추며, 상대 말에 "맞아요"라고 짧게 끼어들고, 때로는 대답을 듣는 도중에 새 요청을 던집니다. 그런데 많은 음성 AI 시스템은 여전히 이 상황을 VAD, ASR, LLM, TTS의 순차 파이프라인으로 처리합니다. 먼저 음성이 끝났는지 판단하고, 텍스트로 바꾸고, LLM이 답을 만들고, 다시 음성으로 읽어주는 방식입니다.
2026년 5월 20일 arXiv에 올라온 DuplexSLA 논문은 이 병목을 꽤 직접적으로 찌릅니다. 연구진은 full-duplex 음성 모델이 계속 듣고 말할 수 있게 되었지만, 여전히 "대화 중 계획과 도구 호출을 위한 native channel"이 부족하다고 봅니다. 그래서 모델 이름에 Speech, Language, Action을 붙였습니다. 핵심은 음성 에이전트가 말을 끝낸 뒤 도구를 부르는 것이 아니라, 말하는 동안 별도의 action channel에서 계획 텍스트와 JSON tool call을 내보내는 구조입니다.
이 주제는 단순한 음성 모델 논문보다 AI 에이전트 쪽에 더 가깝습니다. 지금까지 많은 에이전트 논의는 웹 브라우저, 코드 에디터, 터미널, MCP 서버처럼 텍스트 기반 도구 호출에 집중했습니다. DuplexSLA가 던지는 질문은 조금 다릅니다. 사용자가 음성으로 말하는 동안 에이전트가 동시에 듣고, 대답하고, 도구를 호출하려면 모델 인터페이스 자체가 어떻게 바뀌어야 하는가입니다.
ASR 뒤 LLM이 아니라 같은 시계의 문제
논문이 겨냥하는 기존 구조는 익숙합니다. 음성 입력이 들어오면 VAD가 발화 종료를 감지하고, ASR이 텍스트를 만들고, LLM이 응답이나 function call을 생성하고, TTS가 음성으로 변환합니다. 이 구조는 구현과 디버깅이 쉽습니다. 각 부품을 바꾸기도 쉽습니다. 그러나 자연스러운 대화에는 구조적인 비용이 있습니다.
첫째, VAD는 침묵의 의미를 모릅니다. 사용자가 생각하느라 1초 멈춘 것인지, 발화를 끝낸 것인지, 짧은 맞장구를 넣은 것인지, 진짜로 말을 끊은 것인지 음량만으로는 판단하기 어렵습니다. semantic VAD를 덧붙이면 일부를 보완할 수 있지만, 논문은 그 역시 외부 detector chain의 지연과 표현력 한계에 묶인다고 지적합니다.
둘째, tool call이 턴 기반 루프에 잘 들어맞지 않습니다. assistant가 말하기 전에 도구를 호출하면 사용자는 답을 늦게 듣습니다. 말이 끝난 뒤 호출하면 실제 행동은 한 턴 늦어집니다. 말하는 중 같은 텍스트 채널에 tool call을 끼워 넣으면 음성 응답 자체가 깨질 수 있습니다. 그래서 DuplexSLA는 "말하기 채널"과 "행동 채널"을 분리합니다.
GitHub 저장소의 README도 같은 방향을 설명합니다. DuplexSLA는 user audio channel, assistant audio channel, action channel의 dual-stream three-channel formulation을 씁니다. user와 assistant는 실제 음성 스트림이고, action channel은 assistant timeline 위에 올라간 텍스트 전용 레인입니다. 이 레인에는 delayed transcript, planning text, interaction-control label, structured tool call이 들어갑니다.
160ms 청크가 만든 action channel
DuplexSLA의 시간 단위는 160ms 청크입니다. 각 청크에서 user channel은 80ms stride의 causal audio feature 2개를 제공합니다. assistant channel은 TA4 layout을 씁니다. 하나의 text anchor와 40ms 단위 discrete audio token 4개가 한 청크를 구성합니다. action channel은 최대 10개의 텍스트 토큰을 내보낼 수 있습니다. 논문은 이 제한을 아키텍처의 본질적 한계가 아니라 실시간 추론 예산에 맞춘 배포상의 budget이라고 설명합니다.
이 설계의 중요한 점은 tool call에도 timestamp가 생긴다는 것입니다. 기존 function calling에서는 모델이 어느 순간에 사용자의 어떤 말에 반응해 도구를 호출했는지 대략적인 턴 단위로만 알 수 있습니다. DuplexSLA에서는 action object가 특정 청크에 붙습니다. 예를 들어 사용자가 자동차 안에서 "에어컨 좀 올리고, 편한 음악 틀고, 근처 식당으로 안내해줘"라고 말하면, 세 개의 도구 호출이 사용자의 의미 순서에 맞춰 각각 다른 청크의 action channel에 정렬될 수 있습니다.
| 채널 | 청크당 내용 | 역할 |
|---|---|---|
| User audio | 80ms causal feature 2개 | 사용자 발화를 계속 듣는 입력 레인 |
| Assistant audio | text anchor 1개와 audio token 4개 | assistant가 말하는 음성 출력 레인 |
| Action text | 최대 10개 text token | 계획, 제어 라벨, JSON tool call 레인 |
이 구조는 "에이전트가 생각을 말로 노출해야 하는가"라는 논쟁과도 연결됩니다. DuplexSLA의 action channel에는 planning text가 들어갑니다. 논문은 이것을 사용자에게 보여주는 설명문이라기보다 tool call과 turn-taking을 정렬하기 위한 내부 텍스트 레인으로 다룹니다. 실제 제품에 적용한다면 이 레인을 어디까지 로깅하고, 어디까지 사용자에게 노출하며, 어떤 보안 정책을 붙일지가 별도 문제로 남습니다.
Backchannel은 작은 기능이 아니라 에이전트성의 시험대
DuplexSLA 논문에서 흥미로운 단어는 backchannel입니다. 한국어로는 맞장구, 추임새, 짧은 피드백에 가깝습니다. 사용자가 "맞아요"라고 말했을 때 assistant가 말을 멈춰야 할까요. 아니면 이것을 대화권을 빼앗는 interruption이 아니라 계속 말해도 되는 신호로 봐야 할까요. 사람은 맥락으로 구분하지만, 턴 기반 음성 시스템은 자주 헷갈립니다.
논문은 pause, interrupt, backchannel을 외부 VAD가 아니라 모델 내부의 semantic state로 처리하려 합니다. action channel에 response, interrupt, backchannel 같은 라벨이 나가고, assistant audio channel은 그 라벨에 맞춰 계속 말하거나 침묵합니다. 이 접근이 중요한 이유는 음성 에이전트의 행동이 "발화가 끝났는가"가 아니라 "이 사용자의 짧은 소리가 어떤 대화 행위인가"에 달려 있기 때문입니다.
이것은 고객지원 봇이나 차량 assistant처럼 실시간성이 중요한 환경에서 더 뚜렷합니다. 운전자가 "춥다"라고 말하는 도중 assistant가 계속 안내 멘트를 하고 있다면, 에어컨 조정 도구 호출은 assistant의 문장이 끝날 때까지 기다릴 필요가 없습니다. 반대로 사용자가 assistant 말을 끊고 안전 관련 새 지시를 한다면 즉시 멈춰야 합니다. 같은 짧은 음성 입력이라도 action channel은 tool call과 대화 제어를 분리해서 다룰 수 있어야 합니다.
2,100개 벤치와 0.64초 지연
논문은 DuplexSLA-Bench라는 평가 세트를 함께 제안합니다. 구성은 1,200개 turn-taking 사례와 900개 tool-call 사례입니다. turn-taking은 normal, pause, interrupt, backchannel이 각각 300개입니다. tool-call은 single-action, multi-action, backchannel-action이 각각 300개입니다. 즉 단순히 "도구 호출 정확도가 높은가"가 아니라, 실시간 음성 상황에서 언제 호출했는가를 같이 봅니다.
도구 호출 subset 결과는 이 논문의 가장 눈에 띄는 숫자입니다. ASR+LLM cascade baseline은 평균 정확도 91.33%, 평균 지연 2.77초입니다. DuplexSLA는 평균 정확도 85.56%, 평균 지연 0.64초입니다. 정확도는 cascade가 더 높지만, 지연은 DuplexSLA가 약 4배 낮습니다. 이 숫자는 상용 제품 성능을 바로 의미하지는 않습니다. 다만 "조금 덜 정확하지만 훨씬 먼저 행동하는" 음성 에이전트 설계가 어떤 trade-off를 만드는지 보여줍니다.
context-prefill turn-taking 결과도 눈에 띕니다. DuplexSLA는 normal 96.00%, pause 93.33%, interrupt 99.33%, backchannel 98.33%를 보고했습니다. 비교 대상으로 나온 Gemini 3.1 Flash Live, gpt-realtime-1.5 semantic-vad-high, gpt-realtime-1.5 server-vad-40ms는 backchannel에서 각각 40.00%, 0.33%, 13.00%로 낮게 나왔습니다. 다만 closed-source baseline은 backchannel label을 직접 노출하지 않기 때문에, 논문도 backchannel delay를 N/A로 처리합니다. 같은 조건의 완전한 내부 비교라고 보기는 어렵습니다.
그래도 이 결과는 방향성을 보여줍니다. 실시간 음성 에이전트의 평가는 단순 latency 평균이나 WER만으로 부족합니다. 사용자가 중간에 끼어든 것이 interruption인지 backchannel인지, 도구 호출이 의미적으로 너무 이르거나 늦지 않은지, assistant 음성이 끊기지 않고 coherent하게 유지되는지가 평가 항목으로 들어와야 합니다.
훈련 데이터가 말하는 비용 구조
DuplexSLA는 backbone을 Step-Audio-2-mini 약 7B 파라미터 모델에서 초기화했다고 설명합니다. 데이터 구성은 두 단계입니다. Continued pretraining에는 약 500k 시간의 오디오와 약 1.92M 텍스트 샘플이 쓰였고, post-training에는 약 50k 시간의 오디오가 쓰였습니다. CPT 쪽은 duplex dialogue 320k 시간, user-channel ASR 90k 시간, assistant-channel ASR 90k 시간으로 구성됩니다. Post-training은 interrupt, backchannel, pause 36k 시간과 tool-call 14k 시간으로 구성됩니다.
이 숫자는 이 구조가 단순한 prompting trick이 아니라는 점을 보여줍니다. action channel을 붙였다고 해서 기존 LLM에 프롬프트 몇 줄을 추가하는 수준으로 끝나지 않습니다. 모델은 음성, assistant audio token, action text가 같은 청크 시계에 정렬된 형식을 학습해야 합니다. 특히 tool call은 action object마다 semantic trigger offset이 붙고, 훈련 시 chunk index에 snap됩니다. 즉 "어떤 함수를 호출할까"만이 아니라 "언제 호출할까"까지 데이터 문제가 됩니다.
여기서 AI 인프라 관점의 비용도 보입니다. 논문은 7B급 backbone에서 assistant TA4 unit을 생성한 뒤 action channel에 남는 토큰 budget을 청크당 10개로 둡니다. 160ms 안에 음성 생성과 action text 생성을 모두 처리해야 하기 때문입니다. 고성능 모델을 붙이면 품질은 올라갈 수 있지만, chunk clock을 놓치면 full-duplex 경험은 무너집니다. 음성 에이전트의 병목이 모델 크기만이 아니라 serving budget과 token scheduling으로 이동하는 셈입니다.
개발자에게 중요한 이유
개발자나 AI 제품 팀이 이 논문을 봐야 하는 이유는 DuplexSLA 자체를 곧바로 쓸 수 있어서가 아닙니다. 오히려 저장소는 현재 technical report 공개 상태이고, inference code, deployment recipe, model checkpoint, DuplexSLA-Bench evaluation harness와 data는 공개 예정입니다. 당장 npm 패키지처럼 가져다 붙일 수 있는 단계는 아닙니다.
그럼에도 구조가 중요합니다. 앞으로 음성 에이전트 제품을 만들 때 "Realtime API를 붙이면 끝"이라는 접근은 한계가 빨리 드러날 수 있습니다. 일정 변경, 차량 제어, 음악 재생, 결제 승인, 고객 상담 전환처럼 도구 호출이 음성 경험 안으로 깊게 들어오면, 언제 듣고 언제 말하고 언제 행동했는지를 이벤트 로그로 남겨야 합니다. DuplexSLA의 action channel은 그 문제를 모델 인터페이스 레벨에서 다루는 한 가지 설계안입니다.
또 하나의 실무 포인트는 observability입니다. 텍스트 에이전트에서는 tool call 로그, reasoning trace, function result를 비교적 명확히 남길 수 있습니다. 음성 에이전트는 시간이 더 중요합니다. 사용자가 "아니 그거 말고"라고 말한 시점, assistant가 실제로 멈춘 시점, tool call이 발행된 시점, tool result가 도착한 시점이 모두 UX와 안전성에 영향을 줍니다. action channel이 timestamped lane으로 설계된다는 점은 운영 로그와 평가에도 영향을 줄 수 있습니다.
아직 조심해서 읽어야 할 부분
가장 큰 유보점은 재현성입니다. 논문과 README는 공개됐지만 핵심 artifact는 아직 "coming soon"입니다. 모델 checkpoint가 없고, inference server가 없고, 벤치 데이터와 평가 harness도 아직 공개 예정입니다. 따라서 현재 단계에서 DuplexSLA의 수치를 제품 성능처럼 받아들이면 안 됩니다. 논문의 주장과 수치는 연구진이 구성한 benchmark와 비교 조건 안에서 읽어야 합니다.
두 번째는 baseline 비교의 비대칭성입니다. closed-source realtime 모델은 내부 backchannel label을 노출하지 않습니다. 그래서 논문은 오디오 변화나 stop/speak event를 통해 일부를 평가합니다. DuplexSLA는 action channel label을 직접 읽을 수 있습니다. 이것은 DuplexSLA의 설계 장점이기도 하지만, 평가 지표에서는 비교 방식의 차이를 만듭니다.
세 번째는 안전과 권한 문제입니다. 말하는 중 도구 호출이 가능해지면 지연은 줄지만, 오작동의 표면도 커집니다. 사용자의 짧은 backchannel을 실제 명령으로 오해하면 원치 않는 side effect가 발생할 수 있습니다. 반대로 실제 interruption을 backchannel로 착각하면 assistant가 계속 말하거나 잘못된 도구 호출을 이어갈 수 있습니다. 음성 에이전트에서 권한 확인, 취소, undo, human confirmation은 더 중요해집니다.
음성 에이전트의 다음 병목
DuplexSLA가 흥미로운 이유는 "더 자연스러운 음성"이라는 익숙한 문구를 넘어, 에이전트가 행동하는 시점을 모델 구조로 끌어들였기 때문입니다. 지금까지 AI 음성 제품의 데모는 반응 속도와 목소리 품질을 앞세웠습니다. 다음 단계의 차이는 아마 대화 중에 어떤 도구를 얼마나 정확한 순간에 호출하고, 사용자의 짧은 개입을 어떻게 해석하며, 그 행동을 어떻게 검증 가능한 로그로 남기느냐에서 날 가능성이 큽니다.
이 관점에서 160ms action channel은 작은 구현 세부사항이 아닙니다. 음성 에이전트가 텍스트 에이전트처럼 도구를 호출하려면, tool call이 문장 끝에 매달린 후처리 이벤트가 아니라 대화의 시간축 위에 있는 1급 객체가 되어야 합니다. DuplexSLA는 그 가설을 연구 모델 형태로 밀어붙인 사례입니다.
아직 공개되지 않은 코드와 checkpoint가 나오면 더 중요한 질문이 남습니다. 이 구조가 실제 noisy 환경에서도 유지되는가. 한국어와 영어가 섞인 대화나 여러 화자가 있는 상황에서 backchannel 판단은 안정적인가. 자동차나 스마트홈처럼 side effect가 있는 도구 호출에서 confirmation policy는 어떻게 붙는가. 그리고 160ms 청크의 serving budget은 더 큰 모델이나 더 복잡한 tool schema에서도 버틸 수 있는가.
지금 단계에서 DuplexSLA는 완성된 제품보다 방향성 있는 신호에 가깝습니다. 음성 에이전트 경쟁은 더 이상 "듣고 답하는 모델"만의 문제가 아닙니다. 말하는 동안 계획하고, 맞장구를 이해하고, 행동을 같은 시계에 맞추는 운영체제에 가까워지고 있습니다.