Cursor 에이전트 주 2,000회 실행, 자동화의 다음 병목
Faire가 Cursor Cloud Agents로 주간 PR 처리량 2배, 주 2,000회 자동 실행을 공개했습니다. 병목은 모델보다 환경·권한·워크플로입니다.

- 무슨 일: Cursor가 5월 26일 Faire의 Cloud Agents 도입 사례를 공개했습니다.
- Faire는 주간 PR 처리량 2배, 주당 2,000회 이상 자동 에이전트 실행, 25개 이상 Automations를 제시했습니다.
- 의미: 코딩 에이전트 경쟁 기준이 모델 이름에서 실행 환경, 권한, CI 복구, PR 라우팅으로 이동합니다.
- 주의점: 공급자 고객 사례라 성과 수치는 독립 벤치마크가 아닙니다. 운영 비용과 실패 로그를 함께 봐야 합니다.
Cursor가 2026년 5월 26일 공개한 Faire 고객 사례는 코딩 에이전트가 기업 안에서 어디까지 들어왔는지 보여주는 숫자를 담고 있습니다. 북미 전자상거래 회사 Faire는 자체 background agent 시스템을 Cursor Cloud Agents로 대체했고, 그 결과 주간 PR 처리량이 2배로 늘었다고 밝혔습니다. Cursor가 함께 공개한 수치는 더 구체적입니다. Faire는 주당 2,000건 이상 자동 에이전트 실행, 25개 이상 Cursor Automations, 18개월 규모로 예상한 migration 작업을 한 명의 엔지니어와 에이전트 fleet로 조율한 사례를 제시했습니다.
이 글을 단순한 고객 성공 사례로만 읽으면 놓치는 부분이 있습니다. Cursor는 5월 21일 별도 연구 글에서 cloud agents를 "로컬 에이전트를 서버에 올린 것"이 아니라 dedicated VM, dependency, network access, checkpoint, credential management, durable workflow를 포함한 실행 시스템으로 설명했습니다. Faire 사례의 숫자는 그 주장을 실제 회사 workflow에 붙인 예입니다. PR 처리량을 높인 주체는 모델 하나가 아니라 Slack, CI, GitHub, 내부 패키지, AWS credential, React migration list를 잇는 자동화 구조였습니다.
Faire가 먼저 부딪힌 문제는 로컬 병렬 실행의 한계였습니다. 여러 에이전트를 한 노트북에서 동시에 돌리면 memory, CPU, terminal session, worktree 관리가 곧 사용자의 일이 됩니다. Faire는 처음에 Samurai라는 자체 cloud agent 시스템을 만들었지만, Cursor 고객 사례에서 Luke Bjerring은 서버를 세우고, 인력을 고용하고, 복잡한 인프라를 유지하는 비용을 언급했습니다. Faire가 Cursor를 고른 이유로 제시한 항목은 managed infrastructure와 self-hosted machine 선택지, GitHub 통합, agent reliability, 여러 agent를 관리하는 interface, local과 cloud 사이 handoff입니다.
여기서 "cloud"는 단순한 hosting 장소가 아닙니다. Cursor 연구 글은 cloud agent가 각자 dedicated virtual machine을 갖고 dependency와 network access를 사용하며, unattended long-running task를 처리한다고 설명합니다. 로컬 에이전트는 개발자의 노트북 환경을 그대로 물려받지만, cloud agent는 그 환경을 처음부터 재구성해야 합니다. Cursor는 이 차이를 "development environment is the product"라고 표현했습니다. 환경이 조금만 빠져도 agent가 crash하지 않고 품질만 낮아질 수 있기 때문에, 실패 원인을 모델 성능으로 오해하기 쉽다는 설명입니다.
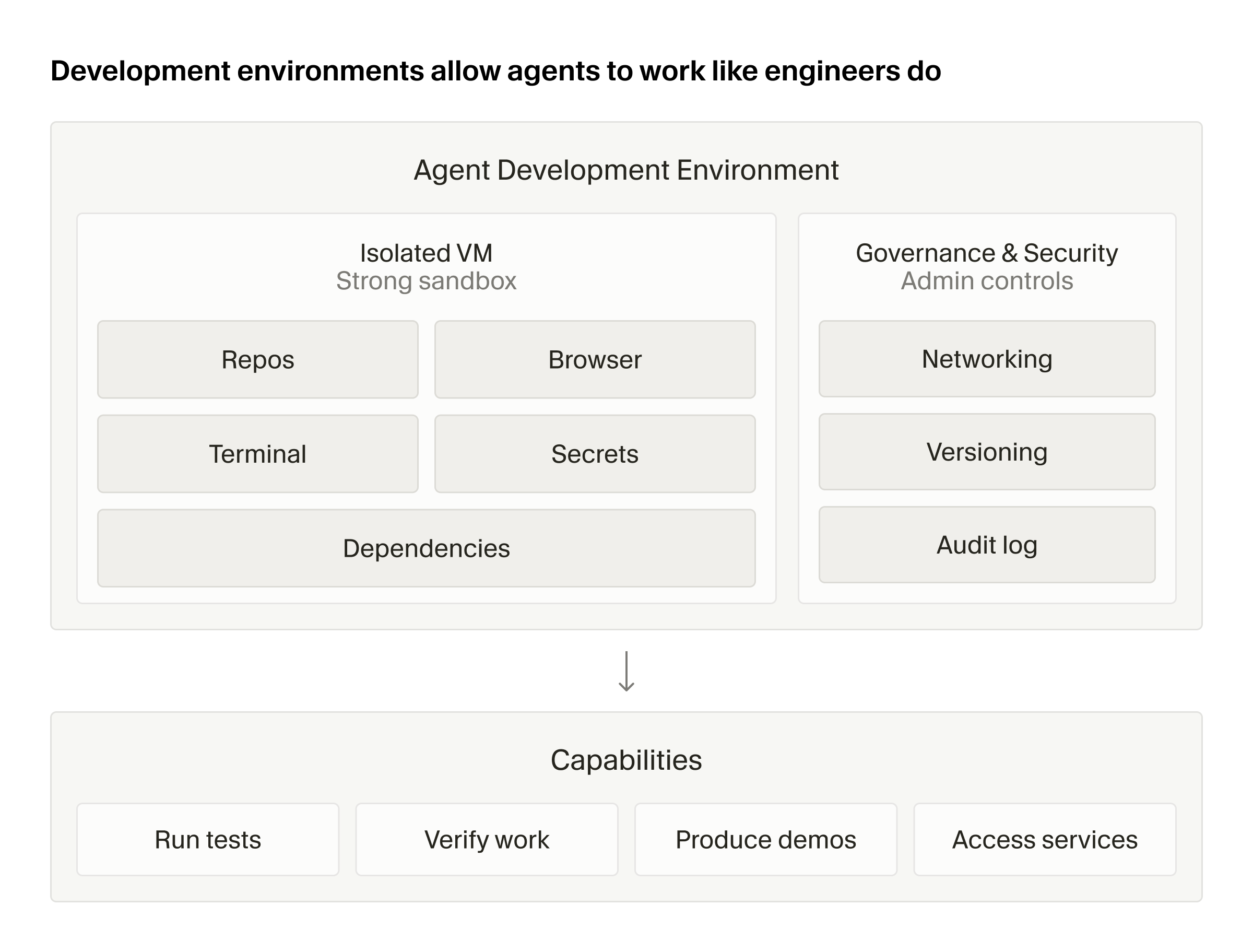
Faire 사례에서도 이 환경 문제가 직접 등장합니다. Faire의 backend와 frontend는 separate repo이고, 내부 package dependency는 Gradle과 Bazel에 묶여 있으며, 작업마다 별도 AWS credential이 필요합니다. Cursor 고객 사례는 Faire가 agent-led onboarding을 사용해 Cursor가 각 repo를 조사하고 toolchain과 dependency를 파악한 뒤 environment configuration을 만든다고 설명합니다. tighter control이 필요한 workflow에는 Dockerfile로 development environment를 정의할 수 있다고 했습니다. 에이전트가 코드를 쓰는 것보다 build, test, internal service 접근, credential 경계 설정이 먼저 병목이 되는 장면입니다.
Faire가 공개한 workflow 중 개발팀에 가장 직접적인 것은 Slack에서 시작하는 PR입니다. Faire는 Slack-heavy 회사이고, 많은 engineering work가 channel의 질문이나 bug report에서 시작된다고 설명했습니다. 엔지니어가 Slack thread에서 @cursor를 호출하면 conversation context가 cloud agent로 넘어가고, agent는 조사한 뒤 PR로 돌아옵니다. 이 구조에서 사용자는 issue tracker로 옮기거나 terminal을 열기 전에 agent에게 조사를 위임합니다. 몇 분 뒤 PR이 돌아온다는 설명은 매력적이지만, 같은 문장 안에는 context capture, permission, repository routing, audit log가 함께 숨어 있습니다.
자동화 범위는 일회성 호출보다 넓습니다. Faire는 25개 이상 Cursor Automations를 운영하며, 주당 2,000건 이상 autonomous agent run을 수동 prompt 없이 실행한다고 밝혔습니다. 대표 use case는 Slack bug report triage, CI failure 조사와 fix push, PR routing입니다. PR routing에서는 agent가 author, risk, size 기준으로 PR을 labeling하고 review workflow에 보냅니다. 이 대목에서 코딩 에이전트의 역할은 "코드를 작성하는 도구"에서 "개발 queue를 움직이는 actor"로 바뀝니다. merge 전 human review가 남아 있어도, triage와 repair loop를 먼저 잡는 주체가 바뀝니다.
18개월 migration 사례는 더 공격적인 형태입니다. Faire는 retailer-facing application을 MobX에서 native React state management로 옮기는 작업을 위해 Cursor 위에 Swarm이라는 coordination system을 만들었습니다. scraper가 codebase에서 MobX 사용 지점을 찾아 S3에 목록을 쓰고, Swarm이 이 목록을 읽어 Cursor cloud agents에 migration task를 나눠 줍니다. 한 agent가 작업을 끝내고 PR을 merge하면 Swarm이 다음 작업을 시작합니다. Cursor 고객 사례는 이 일을 한 명의 엔지니어가 agent fleet를 관리하는 방식으로 조율했다고 설명합니다.
이 migration 이야기는 "AI가 18개월 일을 하루 만에 끝냈다"는 식으로 받아들이면 부정확합니다. Cursor의 공개 문장에는 완료 기간 전체, 실패율, review load, rollback 비용, test coverage 변화가 없습니다. 확인 가능한 사실은 Faire가 18개월 규모로 보던 작업을 task list, S3, Swarm, isolated VM, PR merge loop로 쪼갰다는 점입니다. 개발팀이 참고할 부분은 마법 같은 압축률보다 작업을 작게 쪼개는 방식입니다. agent가 성공한 단위는 "큰 migration 전체"가 아니라 "MobX 사용 지점 하나 또는 일부를 고치고 PR로 검증받는 반복"에 가깝습니다.
Cursor의 5월 21일 연구 글은 이런 반복을 견디기 위해 durable execution을 강조합니다. 초기 cloud agents는 worker node가 agent를 집어 끝까지 loop하는 work-stealing architecture였고, Cursor는 이를 one 9 수준의 reliability라고 표현했습니다. 이후 Temporal로 옮기면서 inference provider outage, pod hibernation/resumption, EC2 node failure, 며칠 또는 몇 주에 걸친 run을 견딜 수 있게 됐다고 설명했습니다. Cursor는 이 migration 하나로 two 9s 이상 reliability에 도달했고, Temporal이 하루 5,000만 actions와 700만 unique workflows 이상을 처리한다고 밝혔습니다.
이 수치는 코딩 에이전트 제품의 내부 시스템을 드러냅니다. 사용자는 chat window에서 "이 issue 고쳐줘"라고 말하지만, 공급자는 workflow engine, VM lifecycle, storage stream, retry semantics, log handling, network policy를 운영합니다. Cursor는 agent loop, machine state, conversation state를 분리했다고 설명합니다. agent loop는 Temporal에 있고, pod lifecycle은 별도로 관리되며, conversation update는 append-only storage에서 web과 desktop client로 stream됩니다. retry 중 partial output이 바뀌면 client가 stream을 되감고 새 데이터를 표시해야 한다는 설명도 나옵니다.
이 설계는 GitHub Copilot cloud agent, OpenAI Codex, Claude Code/Cowork와 직접 경쟁하는 지점입니다. 최근 GitHub는 Copilot app, cloud agent, model rules, memory control을 빠르게 늘리고 있고, Anthropic은 Claude 제품군에서 sandbox와 MCP connector 경계를 공개했습니다. OpenAI는 Codex 내부 사용 사례와 mobile handoff를 강조했습니다. Cursor Faire 사례가 다른 점은 "우리 모델이 더 강하다"가 아니라 "한 회사의 PR queue와 migration queue에 cloud agent를 얼마나 많이 태웠는가"를 숫자로 제시했다는 점입니다.
개발 조직 관점에서 첫 번째 질문은 비용입니다. 주당 2,000회 autonomous run은 성공하면 triage와 CI recovery 시간을 줄입니다. 실패하면 token, VM, CI minute, reviewer attention을 소비합니다. Cursor 고객 사례는 Faire의 engineering output이 2~3배에 접근하면서 다음 bottleneck을 broader product development process로 보고 있다고 전합니다. 이 말은 코딩 속도가 빨라질수록 product spec, design review, QA, rollout, support triage가 새 제한 요소가 된다는 뜻으로 읽을 수 있습니다. PR 수가 늘어도 review와 release capacity가 그대로면 backlog 모양만 바뀝니다.
두 번째 질문은 권한입니다. Slack thread에서 @cursor를 부르는 흐름은 편하지만, 어떤 channel context가 repo에 전달되는지, agent가 어떤 secret과 internal service에 접근하는지, PR branch와 CI permission이 어디까지 열리는지 명확해야 합니다. Cursor 연구 글은 cloud agents가 시간이 지나며 secret redaction, network policies, credential management를 포함한 "enterprise IT for agents"가 됐다고 설명합니다. 이 표현은 고객 사례의 밝은 숫자 뒤에 있는 실제 작업 목록입니다. agent를 많이 돌릴수록 모델 prompt보다 identity, network, audit policy가 먼저 문서화돼야 합니다.
세 번째 질문은 실패 관측성입니다. Cursor forum에는 5월 말 configured environment가 있는 Cloud Agents를 시작하지 못했다는 bug report가 올라와 있습니다. 이 thread 하나로 제품 품질을 일반화할 수는 없지만, cloud agent 운영의 실패 mode를 보여주는 신호입니다. 에이전트가 시작하지 못하거나, 오래된 완료 session이 동시 실행 quota를 잡아먹거나, web/mobile handoff가 누락되면 개발자는 "AI가 못했다"가 아니라 "작업 실행 환경이 닫혔다"는 문제를 다뤄야 합니다. 자동화 수가 2,000회를 넘으면 이런 실패는 개별 annoyance가 아니라 platform SLO가 됩니다.
Faire 사례에서 실무자가 가져갈 기준은 세 가지입니다. 첫째, cloud agent를 도입하기 전에 repository별 development environment를 코드로 재현할 수 있어야 합니다. Gradle, Bazel, internal package registry, AWS credential, local service mock이 문서와 Dockerfile 또는 agent configuration으로 남아야 합니다. 둘째, automation trigger는 Slack, CI, PR event처럼 사람이 이미 일하는 곳에 붙여야 합니다. 별도 dashboard에 task를 복사하는 방식이면 agent 운영자가 새 병목이 됩니다. 셋째, agent가 만든 PR을 작은 단위로 merge하고 다음 작업을 여는 queue가 필요합니다.
이 글의 headline 숫자인 "주 2,000회"는 그대로 받아들이기보다 계측 질문으로 바꿔야 합니다. 2,000회 중 몇 퍼센트가 PR로 끝났는지, 몇 퍼센트가 human intervention을 요구했는지, 평균 CI minute과 token 비용이 얼마였는지, reviewer가 거절한 비율은 얼마인지가 다음 표준 지표입니다. Cursor 연구 글이 말한 reliability도 같은 방식으로 봐야 합니다. one 9에서 two 9s로 올라갔다는 것은 공급자 내부 metric이지만, 고객 조직은 "agent run이 실패했을 때 누가 alert를 받고 어떻게 재시도하는가"를 자기 SLO로 정의해야 합니다.
Cursor와 Faire의 발표가 개발자에게 남기는 결론은 단순합니다. 코딩 에이전트를 많이 쓰는 팀은 더 이상 editor plugin만 고르는 문제가 아닙니다. 팀은 agent가 일할 VM, build cache, credential, branch policy, CI approval, Slack event, PR review queue를 함께 설계해야 합니다. Cursor가 고객 사례로 보여준 성과는 이 설계가 맞아떨어졌을 때의 상한입니다. 동시에 같은 사례는 에이전트 자동화가 커질수록 모델보다 환경과 운영이 병목이 된다는 사실을 숫자로 드러냅니다.