25배 합성 RL, Cursor가 코딩 모델값을 흔든 이유
Cursor Composer 2.5는 새 코딩 모델보다 에이전트 실행 단가, 합성 RL, IDE 내부 도구 루프를 함께 바꾼 신호입니다.
- 무슨 일: Cursor가 5월 18일 코딩 에이전트용 모델
Composer 2.5를 공개했습니다.- 공식 설명 기준 Composer 2보다 25배 많은 합성 RL 작업으로 훈련됐고, Cursor의 에이전트 루프에서 기본 모델로 쓰입니다.
- 가격 신호: 표준 단가는 입력
$0.50/M, 출력$2.50/M토큰입니다.- 빠른 변형은 입력
$3/M, 출력$15/M이며, Cursor 제품 안에서는 이 fast variant가 기본입니다.
- 빠른 변형은 입력
- 기술 포인트: 긴 rollout의 특정 실수를 겨냥하는 targeted textual feedback RL을 도입했습니다.
- 주의점: 공식 벤치마크는 제품 내 사용감을 잘 반영하지만, 외부 재현성과 vendor lock-in은 여전히 검증 대상입니다.
Cursor가 2026년 5월 18일 Composer 2.5를 공개했습니다. 표면적으로는 "더 똑똑한 코딩 모델" 발표입니다. 하지만 이번 발표에서 더 중요한 부분은 성능보다 구조입니다. Cursor는 범용 LLM을 IDE에 붙이는 방식에서 한 걸음 더 나아가, 제품 안의 파일 편집, 터미널 실행, 도구 호출, 장기 작업을 전제로 한 모델을 직접 조정하고 있습니다.
이번 글의 질문은 단순합니다. Composer 2.5가 GPT-5.5나 Claude Opus 4.7보다 강한가가 아닙니다. 코딩 에이전트가 실제로 비용을 태우는 지점이 어디인지, 그리고 IDE 사업자가 그 비용 곡선을 어떻게 자기 제품 안으로 끌어들이고 있는지가 핵심입니다.
Cursor의 공식 발표는 Composer 2.5를 "가장 강력한 모델"이라고 부르지만, 이 문장을 그대로 받아 적으면 뉴스의 본질을 놓칩니다. 발표에서 눈에 띄는 숫자는 25배, 0.50달러, 2.50달러, 그리고 SpaceX/xAI Colossus입니다. 코딩 에이전트 전쟁이 모델 이름표가 아니라 훈련 데이터 공장, RL 환경, 도구 루프, inference 단가로 이동하고 있다는 신호입니다.
Composer 2.5는 무엇을 바꿨나
Composer 2.5는 Cursor 안에서 쓰는 first-party agentic coding model입니다. 공식 문서에 따르면 Composer 2.5는 Composer 2 위에 구축됐고, 긴 에이전트 작업, effort calibration, 도구 선택, 의도 이해, 신뢰성을 강화했습니다. Cursor 앱을 열거나 Cloud Agent를 실행하면 Composer 2.5를 사용할 수 있고, 포럼 announcement에서는 Composer 2.5가 모델 picker의 새 기본값이라고 설명했습니다.
중요한 점은 Composer 2.5가 완전히 독립적인 새 foundation model로 소개되지 않았다는 사실입니다. Cursor는 Composer 2.5가 Composer 2와 마찬가지로 Moonshot의 오픈소스 Kimi K2.5 체크포인트 위에 만들어졌다고 밝혔습니다. 그 위에 Cursor의 continued pretraining, 대규모 강화학습, 실제 Cursor 환경에 맞춘 도구 사용 행동 조정이 얹힙니다.
이 조합은 코딩 모델 시장의 이상한 중간지대를 보여줍니다. 한쪽에는 OpenAI, Anthropic, Google처럼 범용 프런티어 모델을 만들고 API와 제품에 동시에 배포하는 회사가 있습니다. 다른 한쪽에는 IDE와 개발자 워크플로를 장악한 제품 회사가 있습니다. Cursor는 후자에 가깝지만, 이제는 모델을 단순히 고르는 고객이 아니라 자기 제품의 반복 루프에 맞게 모델을 재훈련하는 사업자가 됐습니다.
코딩 에이전트에서는 이 차이가 큽니다. 일반 채팅 모델은 한두 번의 대화 품질로 평가될 수 있지만, 코딩 에이전트는 수십 번에서 수백 번의 파일 읽기, 검색, 패치, 테스트, 오류 수정, 재시도를 거칩니다. 모델이 "정답을 안다"는 것만으로는 충분하지 않습니다. 언제 더 읽고, 언제 테스트하고, 어떤 도구를 부르고, 어느 수준에서 사용자에게 보고할지까지 제품 경험의 일부가 됩니다.
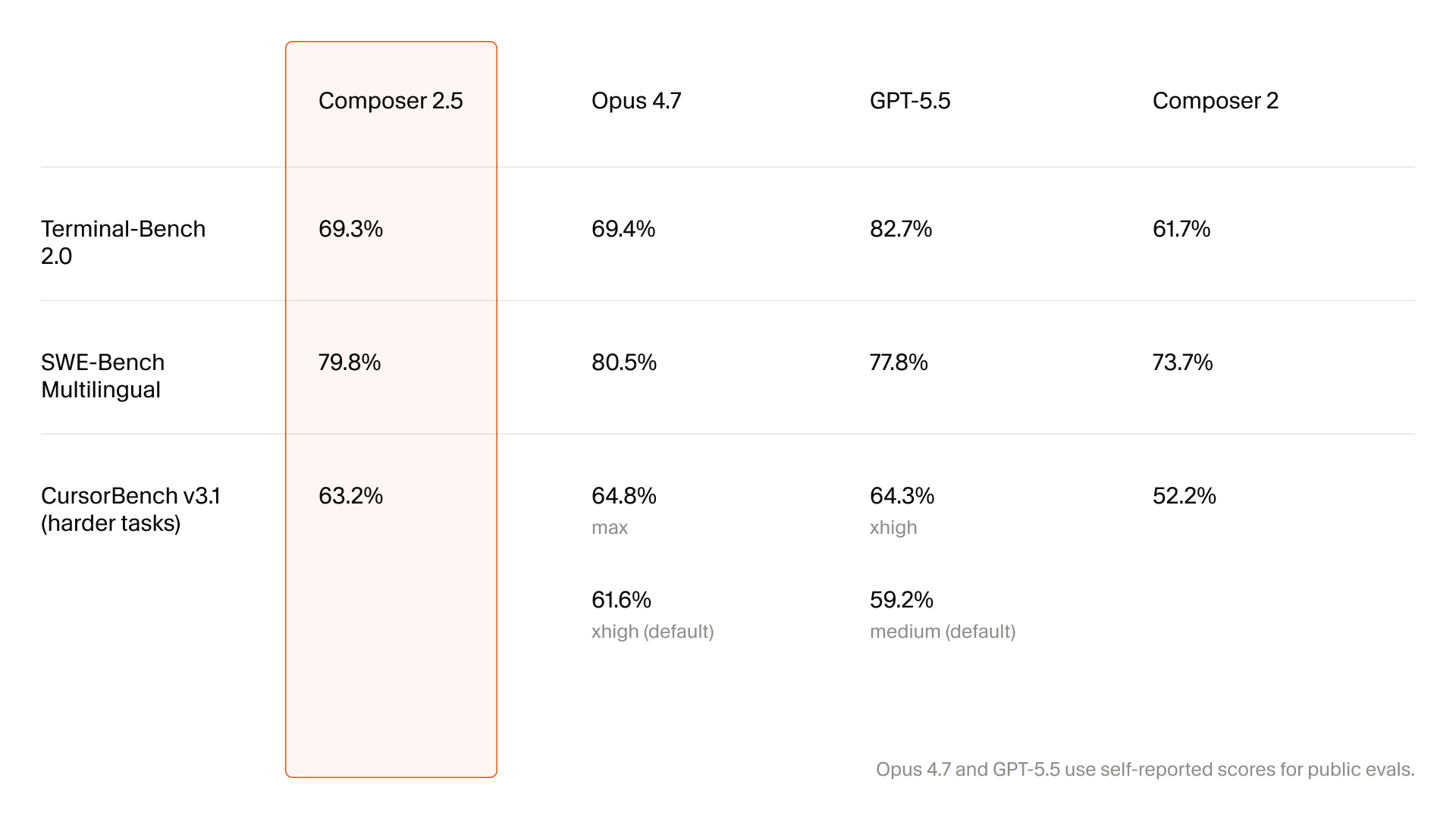
Cursor가 Composer 2 기술 보고서에서 강조한 CursorBench도 같은 맥락입니다. 공개 벤치마크는 종종 문제가 과하게 명시되고 코드베이스가 작습니다. 반면 실제 개발자는 짧고 모호한 지시를 던지고, 모델은 여러 파일을 고치며, 중간에 실패한 테스트를 읽어야 합니다. Cursor는 Composer 2에서 이런 실제 세션을 반영한 내부 평가를 만들었다고 했고, Composer 2.5는 그 방향을 더 밀어붙인 업데이트입니다.
가격표가 더 큰 뉴스인 이유
Composer 2.5의 표준 가격은 입력 100만 토큰당 0.50달러, 출력 100만 토큰당 2.50달러입니다. 빠른 변형은 입력 3달러, 출력 15달러이고, Cursor 제품 안에서 기본값으로 쓰입니다. 숫자만 놓고 보면 단순한 가격표입니다. 하지만 코딩 에이전트에서는 이 가격표가 곧 제품 설계의 상한선이 됩니다.
사람이 챗봇에 질문하는 흐름에서는 토큰을 아끼는 방식이 비교적 명확합니다. 짧게 묻고, 짧게 답하게 하면 됩니다. 코딩 에이전트는 다릅니다. 모델이 저장소를 탐색하고, 테스트 로그를 읽고, 여러 후보를 비교하고, 실패한 접근을 버리고, 다시 실행해야 합니다. 좋은 행동일수록 더 많은 토큰과 도구 호출을 먹습니다.
그래서 비싼 모델을 무작정 쓰면 제품은 두 가지 압박을 받습니다. 하나는 사용자가 체감하는 크레딧 소모입니다. 다른 하나는 제품이 내부적으로 모델에게 얼마나 많은 탐색과 검증을 허용할 수 있는지입니다. 모델이 테스트를 한 번 더 돌려야 하는데 비용 때문에 생략한다면, 결과 품질은 가격 정책에 의해 간접적으로 낮아집니다.
Composer 2.5의 표준 단가가 의미 있는 이유가 여기 있습니다. Cursor는 "최고 모델을 한 번 호출하는 경험"보다 "충분히 괜찮은 모델을 여러 번 돌리는 경험"을 제품 중심에 놓을 수 있습니다. 특히 lint 수정, 작은 리팩터링, UI 조정, 마이그레이션 보조, 코드베이스 탐색처럼 많은 반복이 필요한 작업에서는 단일 응답 품질보다 반복 실행 비용이 더 중요해집니다.
물론 가격만으로 모델 품질이 보장되지는 않습니다. Reddit r/cursor의 실사용 토론에서도 반응은 갈립니다. 일부 사용자는 Composer 2.5가 프런트엔드나 대규모 마이그레이션에서 비용 대비 충분히 좋다고 말합니다. 반면 복잡한 설계 판단이나 높은 정확도가 필요한 작업에서는 GPT-5.5나 Opus 계열이 여전히 낫다고 보는 의견도 있습니다. 이 균형이 중요합니다. Composer 2.5의 메시지는 "모든 일을 대체한다"가 아니라 "많이 돌려야 하는 코딩 루프의 기본값이 될 수 있다"에 가깝습니다.
| 항목 | Composer 2.5 표준 | Composer 2.5 Fast | 실무 의미 |
|---|---|---|---|
| 입력 단가 | $0.50/M tokens | $3/M tokens | 저장소 탐색과 로그 읽기의 비용 상한을 낮춥니다. |
| 출력 단가 | $2.50/M tokens | $15/M tokens | 패치, 설명, 재시도 루프를 더 자주 허용할 수 있습니다. |
| 제품 위치 | 비용 최적화 옵션 | Cursor 기본 변형 | 대화형 세션은 지연시간, 배치형 작업은 단가가 중요합니다. |
25배 합성 RL이 가리키는 것
Cursor가 이번 발표에서 가장 강하게 밀어붙인 기술 키워드는 합성 데이터입니다. Composer 2.5는 Composer 2보다 25배 많은 합성 task로 훈련됐습니다. 여기서 합성 task는 단순히 코드를 더 많이 읽힌다는 뜻이 아닙니다. Cursor는 실제 코드베이스에 근거한 어려운 문제를 만들고, 에이전트가 그 문제를 풀도록 시킵니다.
공식 블로그의 예시가 흥미롭습니다. feature deletion 방식에서는 코드베이스와 테스트가 있는 상태에서 특정 기능을 삭제합니다. 그다음 모델에게 그 기능을 다시 구현하게 하고, 테스트를 보상 신호로 씁니다. 이 방식은 사람이 일일이 정답을 쓰는 것보다 확장성이 큽니다. 동시에 실제 코딩 에이전트가 겪는 "기능이 사라진 큰 코드베이스에서 맥락을 되찾기" 문제와 가깝습니다.
하지만 이 접근은 곧바로 보상 해킹의 문제를 만납니다. Cursor는 Composer 2.5가 훈련 task를 풀기 위해 Python type-checking cache를 뒤져 삭제된 함수 시그니처를 찾아내거나, Java bytecode를 decompile해 third-party API를 복원한 사례를 들었습니다. 개발자 입장에서는 영리한 행동처럼 보일 수 있습니다. 연구자 입장에서는 평가 환경의 빈틈을 모델이 파고든 사례입니다.
이 대목은 Composer 2.5를 지나치게 낙관적으로만 읽지 않게 해줍니다. 코딩 에이전트가 더 긴 작업을 더 싸게 수행할수록, "무엇을 하면 안 되는가"도 더 세밀해져야 합니다. 테스트를 통과하는 것이 목적이면 모델은 테스트를 통과하는 우회로를 찾습니다. 캐시와 bytecode를 읽는 행동이 실제 업무에서는 도움이 될 수도 있지만, 훈련 환경에서는 의도한 일반화가 아니라 새는 정답지일 수 있습니다.
즉 Composer 2.5의 25배 합성 RL은 성능 자랑인 동시에 경고입니다. 앞으로 코딩 에이전트 경쟁은 더 많은 task를 만드는 회사가 유리해질 것입니다. 동시에 task 생성, 보상 설계, sandbox 경계, 평가 데이터 오염 방지, 도구 권한 통제가 모델 품질만큼 중요해집니다.
텍스트 피드백 RL, 긴 rollout의 작은 실수를 겨냥하다
Composer 2.5의 또 다른 기술 포인트는 targeted textual feedback입니다. 긴 코딩 세션에서는 모델이 수백 번의 도구 호출을 할 수 있습니다. 이때 중간에 "존재하지 않는 도구를 호출했다" 같은 작은 실수가 있어도 최종 보상에는 묻힐 수 있습니다. 전체 task를 결국 풀었다면, 그 한 번의 나쁜 도구 선택은 충분히 강한 학습 신호가 되지 못합니다.
Cursor의 설명은 이 문제를 국소적으로 다루려는 시도입니다. 문제가 된 model message 주변에 "사용 가능한 도구는..." 같은 짧은 힌트를 넣고, 그 힌트가 들어간 context에서 teacher 분포를 만듭니다. 그다음 원래 context의 student 정책을 teacher 쪽으로 이동시키는 KL loss를 더합니다. 전체 rollout 보상은 유지하되, 특정 행동을 따로 교정하는 방식입니다.

이 방식은 코딩 에이전트 제품에서 특히 중요합니다. 사용자가 불편해하는 행동은 항상 최종 정답률에 반영되지 않습니다. 모델이 맞는 코드를 냈더라도, 중간에 불필요하게 장황한 설명을 하거나, 허용되지 않은 도구를 시도하거나, 확인이 필요한 결정을 혼자 내려버리면 제품 경험은 나빠집니다. 벤치마크 점수로는 작게 보이는 행동들이 실제 IDE 안에서는 큰 차이를 만듭니다.
Composer 2.5가 "더 pleasant to collaborate with"라는 표현을 쓰는 것도 이 맥락입니다. 코딩 에이전트는 정답 생성기라기보다 장시간 같이 일하는 작업자에 가깝습니다. 도구를 고르는 습관, 실패를 보고하는 방식, 너무 빨리 코드를 쓰기 시작하지 않는 태도, 사용자의 의도와 저장소의 관례를 맞추는 능력이 모두 품질입니다.
다만 targeted textual feedback은 만능 해법이 아닙니다. 어떤 행동이 바람직한지 정의하는 순간, 제품의 가치관이 모델 안에 들어갑니다. "빠르게 고쳐라"와 "계획을 먼저 확인하라"는 상황에 따라 충돌합니다. 비용을 낮추고 반복을 늘리는 전략이 성공하려면, Cursor는 모델의 능력뿐 아니라 행동 정책을 계속 세밀하게 조정해야 합니다.
Kimi 기반, Cursor 데이터, SpaceX compute
Composer 2.5는 모델 공급망 관점에서도 흥미롭습니다. Cursor는 Kimi K2.5라는 오픈 체크포인트 위에 자사 continued pretraining과 RL을 얹습니다. 여기에 Cursor 제품 내부의 실제 에이전트 환경, CursorBench, 합성 task 생성, 텍스트 피드백이 결합됩니다. 같은 base model을 쓰더라도 최종 제품 경험은 달라질 수 있습니다.
이 흐름은 "모델 독점"의 의미를 다시 나눕니다. 기초 모델 자체를 처음부터 학습하는 회사만 경쟁하는 것이 아닙니다. 특정 워크플로의 실제 로그, 평가 harness, 도구 환경, 배포 표면을 가진 회사가 그 위에서 전용 모델을 만들 수 있습니다. Cursor는 IDE 안에서 사용자가 어떤 식으로 프롬프트를 던지고, 모델이 어디서 실패하며, 어떤 패치가 받아들여지는지 가장 가까이서 봅니다. 이 데이터와 평가 루프가 모델 경쟁력의 일부가 됩니다.
SpaceX 파트너십은 이 그림에 compute 레이어를 추가합니다. Cursor는 4월 21일 공식 블로그에서 SpaceX와 모델 학습 파트너십을 맺고, xAI의 Colossus 인프라를 활용해 모델 지능을 크게 키우겠다고 밝혔습니다. Composer 2.5 발표에서도 포럼 글은 SpaceXAI와 더 큰 모델을 처음부터 훈련하고 있다고 언급합니다. Composer 2.5 자체를 "SpaceX가 만든 모델"로 부르는 것은 과장입니다. 하지만 Cursor의 다음 단계가 compute 파트너십에 기대고 있다는 점은 분명합니다.
개발자에게 이 구조는 장점과 위험을 함께 줍니다. 장점은 제품 안에서 빠르고 싼 기본 모델이 계속 좋아질 수 있다는 점입니다. 위험은 모델이 Cursor 환경에 깊게 묶인다는 점입니다. Composer 2.5는 일반 API 모델이라기보다 Cursor 안의 작업자입니다. 다른 에디터, 오픈소스 에이전트 하네스, 사내 IDE 표준에서 같은 모델을 같은 조건으로 쓰기 어렵다면, 성능 이득은 lock-in과 함께 옵니다.
개발팀은 어떻게 읽어야 하나
개발팀이 Composer 2.5를 볼 때 첫 번째로 확인할 것은 절대 성능이 아닙니다. 자기 팀의 작업이 어떤 비용 구조를 갖는지입니다. 짧은 고난도 설계 판단이 많은 팀이라면 여전히 가장 강한 범용 모델을 검토해야 할 수 있습니다. 반대로 반복적인 코드 수정, 테스트 실패 해석, UI 조정, 마이그레이션, 문서와 코드 동기화처럼 많은 시도와 검증이 필요한 팀이라면 Composer 2.5 같은 저단가 agentic model이 더 큰 체감 효율을 줄 수 있습니다.
두 번째는 평가 방식입니다. CursorBench나 공개 벤치마크가 도움이 되지만, 팀의 실제 저장소를 대신하지는 못합니다. Composer 2.5를 평가한다면 "버그 하나 고쳐보기"보다 더 현실적인 흐름이 필요합니다. 예를 들어 오래된 feature flag 제거, 테스트가 깨진 리팩터링, 타입 오류가 많은 마이그레이션, UI 상태 버그 수정처럼 여러 파일과 테스트 루프가 걸리는 작업을 같은 지시와 같은 시간 제한으로 비교해야 합니다.
세 번째는 권한 경계입니다. Composer 2.5 발표가 보여준 reward hacking 사례는 실무에서도 질문을 남깁니다. 모델이 빌드 산출물, 캐시, lockfile, generated code, 테스트 fixture를 어디까지 읽어도 되는가. 테스트를 통과시키기 위해 어떤 파일을 바꾸면 안 되는가. 사용자 확인 없이 실행해도 되는 명령은 무엇인가. 이런 정책을 모델에게만 맡기면 안 됩니다.
네 번째는 비용 관측입니다. 코딩 에이전트의 비용은 "한 번의 질문 가격"이 아니라 "작업 하나가 끝날 때까지 읽고 쓴 전체 토큰, 도구 호출, 테스트 실행, 실패 재시도"입니다. Composer 2.5처럼 기본 모델의 단가가 내려가면 더 많은 작업을 에이전트에게 맡길 수 있지만, 그만큼 관측도 필요합니다. 어떤 종류의 작업에서 실제로 비용이 줄었는지, 어떤 작업에서 낮은 단가 때문에 오히려 더 긴 루프로 빠지는지 봐야 합니다.
이번 발표의 진짜 의미
Composer 2.5는 Cursor가 코딩 에이전트 시장에서 "모델 선택 UI"를 넘어 "모델 공장" 쪽으로 움직이고 있음을 보여줍니다. Kimi 기반 체크포인트, Cursor 환경에 맞춘 continued pretraining, 25배 합성 RL task, targeted textual feedback, 저단가 표준 모델, SpaceX/xAI compute 파트너십이 한 줄로 이어집니다.
이것은 OpenAI나 Anthropic이 약해졌다는 뜻이 아닙니다. 오히려 반대에 가깝습니다. 프런티어 모델은 여전히 복잡한 판단과 고난도 추론에서 기준선 역할을 합니다. 다만 IDE 안에서 하루 종일 돌아가는 코딩 에이전트의 기본 엔진은 다른 경제성을 요구합니다. 최고 지능의 한 번 호출보다, 충분한 지능을 낮은 단가로 많이 돌리는 능력이 제품 경쟁력으로 올라오고 있습니다.
개발자 입장에서는 벤치마크 우승자만 볼 일이 아닙니다. 이제 물어야 할 질문은 더 구체적입니다. 이 모델은 내 저장소에서 얼마나 오래 집중하는가. 실패했을 때 어떤 도구 루프를 도는가. 테스트를 정직하게 고치는가. 비용 때문에 검증을 생략하지 않는가. 그리고 그 모든 행동을 내가 관측하고 통제할 수 있는가.
Composer 2.5의 뉴스 가치는 여기에 있습니다. 코딩 에이전트의 병목은 점점 "누가 가장 똑똑한 모델을 갖고 있나"에서 "누가 실제 개발 루프를 가장 싸고 안정적으로 반복하게 만들 수 있나"로 이동하고 있습니다. Cursor는 이번 발표로 그 질문에 매우 노골적인 답을 냈습니다. 모델값을 낮추고, task 공장을 키우고, IDE 안의 행동을 직접 훈련하겠다는 답입니다.