40% PR이 클라우드에서, Cursor 에이전트 운영층의 실체
Cursor Cloud Agent 회고는 코딩 에이전트 경쟁이 모델보다 VM, Temporal, 인덱싱, 권한, self-healing 운영층으로 이동했음을 보여줍니다.
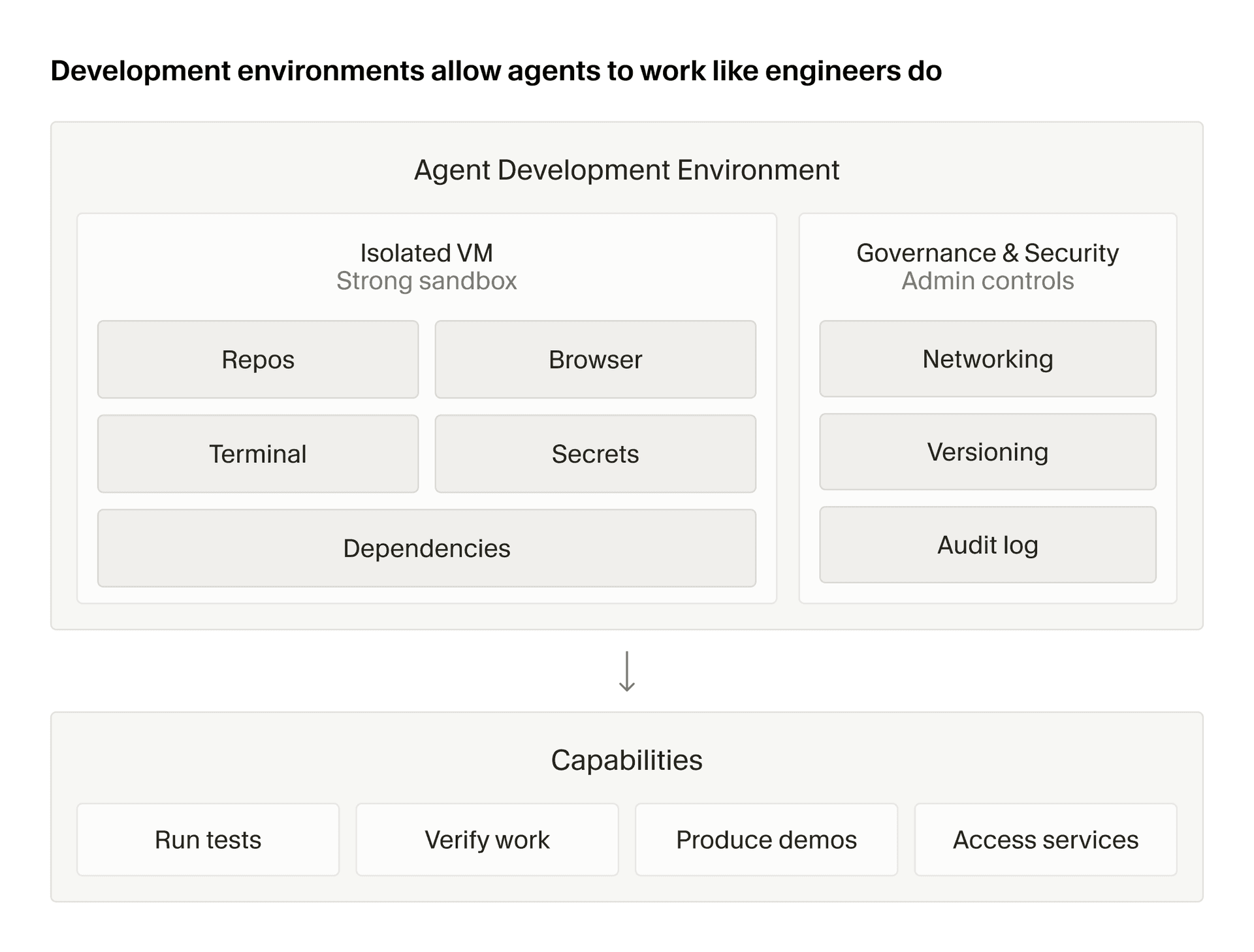
- 무슨 일: Cursor가 Cloud Agent 운영 회고를 공개하며 Cursor에서 병합되는 PR의 40% 이상이 cloud에서 시작된다고 밝혔습니다.
- 공식 글은 worker pool,
Temporal, VM, sync server, repository indexer를 하나의 에이전트 실행 계층으로 설명합니다.
- 공식 글은 worker pool,
- 핵심: 코딩 에이전트 품질은 모델만이 아니라 worktree 초기화, 컨텍스트 동기화, 실시간 변경 표시, 권한, 신뢰로 갈립니다.
- 주의점: Cloud Agent는 생산성을 약속하지만 저장소, credential, setup script, production 접근 권한을 다루는 새 운영 리스크를 만듭니다.
- Cursor도 trust는 어렵고 얻어야 하는 것이라고 적으며 user-provided API key와 GitHub 설치 권한을 별도 쟁점으로 다뤘습니다.
Cursor가 2026년 5월 21일 Cloud Agent를 운영하며 배운 점을 공개했습니다. 제목은 "What we've learned building cloud agents"입니다. 겉으로는 제품 회고처럼 보이지만, 실제로는 코딩 에이전트 시장의 무게중심이 어디로 이동하는지 보여주는 문서에 가깝습니다. Cursor는 Cloud Agents가 수만 명의 개발자에게 사용되고 있으며, Cursor에서 병합되는 PR의 40% 이상이 cloud에서 originated한다고 밝혔습니다.
이 숫자가 중요한 이유는 단순합니다. 코딩 에이전트가 IDE 안의 보조 기능을 넘어 실제 변경을 만들고, PR을 만들고, 병합 흐름에 들어갔다는 뜻입니다. 그러나 Cursor의 글에서 더 흥미로운 대목은 모델 이름이 아닙니다. 글의 대부분은 VM, durable workflow, repository indexer, sync server, setup script, permission, trust 같은 운영 단어로 채워져 있습니다. 모델이 코드를 쓴다는 뉴스가 아니라, 모델이 코드를 쓰기 위해 필요한 작업장이 무엇인지 드러난 뉴스입니다.
AI 코딩 도구 경쟁은 오래도록 "어떤 모델이 더 잘 고치는가"로 설명됐습니다. 이제는 질문이 달라지고 있습니다. 에이전트가 저장소를 어디에 clone하는가. 의존성은 누가 설치하는가. 브랜치와 PR 상태는 IDE와 어떻게 동기화되는가. agent가 실패한 setup을 다시 고칠 수 있는가. 사용자 secret과 production 데이터에는 어디까지 접근할 수 있는가. Cursor의 회고는 이 질문들이 제품의 주변부가 아니라 핵심이라는 점을 보여줍니다.
40% PR이라는 신호
Cursor가 공개한 "40% 이상" 수치는 조심해서 읽어야 합니다. 이것은 전체 소프트웨어 산업의 PR 중 40%가 AI로 만들어진다는 뜻이 아닙니다. Cursor 사용자 집단 안에서 병합되는 PR 중 cloud-originated PR이 차지하는 비중입니다. 그래도 이 숫자는 의미가 큽니다. cloud agent가 데모나 실험이 아니라, 실제 팀의 코드 변경 경로에 들어갔다는 신호이기 때문입니다.
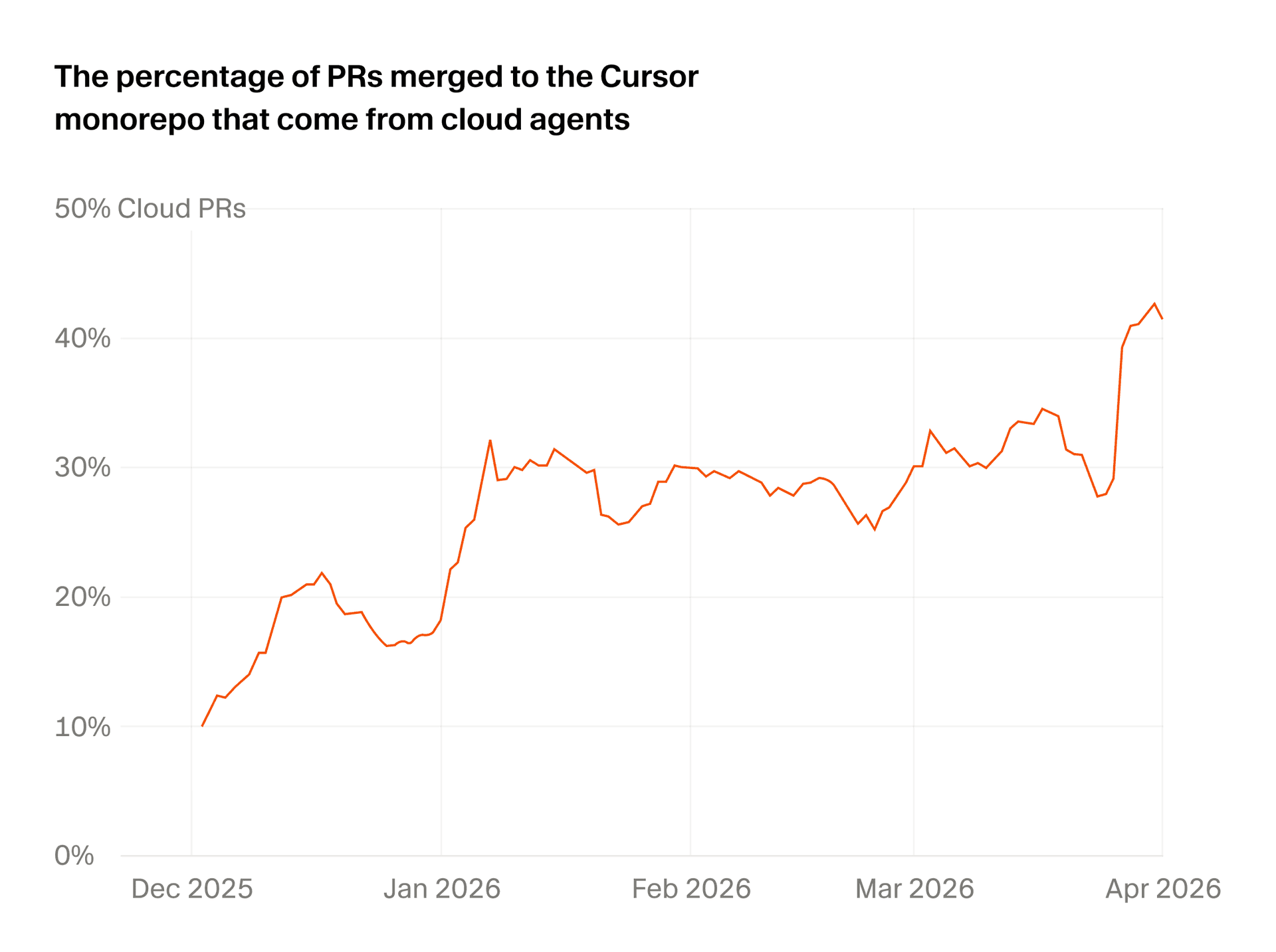
로컬 IDE 에이전트와 cloud agent의 차이는 실행 위치만이 아닙니다. 로컬 에이전트는 사용자의 현재 머신, 현재 checkout, 현재 terminal, 현재 credential 위에서 움직입니다. 그래서 빠르게 시작할 수 있지만, 사용자가 자리를 비우면 작업도 멈추기 쉽습니다. 반대로 cloud agent는 독립된 VM과 durable workflow 위에서 돌아갑니다. 사용자가 다른 일을 하는 동안에도 실행될 수 있고, 여러 task를 병렬로 맡길 수 있습니다. 대신 그만큼 초기화, 동기화, 보안, 비용 문제가 커집니다.
Cursor는 Cloud Agent가 좋은 경험이 되기 위해 다섯 가지가 필요하다고 정리했습니다. initialized worktree, automatic context, real-time interactivity, consistent behavior, trust입니다. 각각은 간단해 보이지만 실제로는 별도 시스템을 요구합니다. worktree 초기화를 위해서는 저장소 clone과 dependency setup이 필요합니다. context를 위해서는 IDE의 열린 파일, 선택 영역, 최근 변경, 코드베이스 인덱스가 필요합니다. 실시간 상호작용을 위해서는 agent가 바꾸는 파일과 로그를 UI에 즉시 보여줘야 합니다. consistent behavior를 위해서는 durable workflow와 재시도, 상태 저장이 필요합니다. trust를 위해서는 권한 모델과 감사 가능한 실행 환경이 필요합니다.
이 목록은 코딩 에이전트가 왜 단순한 챗봇 기능이 아닌지 설명합니다. 모델이 아무리 좋아도 빈 VM에 떨어진 상태로는 제대로 된 PR을 만들기 어렵습니다. 반대로 모델이 약간 덜 똑똑하더라도 정확한 repository context, 재현 가능한 개발 환경, 빠른 feedback loop가 있으면 실제 작업 성공률은 올라갈 수 있습니다. Cursor가 말한 교훈은 "agent product의 성능은 모델 호출 바깥에서 결정된다"에 가깝습니다.
아키텍처가 말하는 제품의 방향
Cursor가 공개한 구조도는 cloud agent를 하나의 원격 작업자로 표현하지 않습니다. 사용자가 task를 시작하면 backend가 worker pool에 action을 dispatch하고, worker는 Temporal action을 통해 오래 걸리는 작업을 orchestration합니다. 각 agent는 VM에서 실행되고, sync server와 repository indexer는 로컬 IDE와 cloud 환경 사이의 상태를 맞춥니다. 여기서 핵심은 "모델 호출"이 아니라 "상태가 여러 층에 흩어져 있다"는 사실입니다.
Cursor는 worker pool, Temporal, VM, sync server, repository indexer를 조합해 Cloud Agent를 만들었습니다. Temporal은 durable execution을 제공합니다. 즉 workflow가 중간에 끊기거나 worker가 바뀌어도 상태를 이어갈 수 있습니다. 코딩 에이전트에서는 이 특성이 중요합니다. dependency install, test run, branch push, PR 생성, user feedback 반영 같은 작업은 몇 초짜리 함수 호출이 아니라 긴 작업 흐름입니다. 중간 실패를 다루지 못하면 사용자는 "agent가 멈췄다"고 느낍니다.
이 지점은 최근 AI 인프라 시장의 흐름과 맞닿아 있습니다. Modal은 에이전트 runtime과 sandbox를 AI 워크로드의 핵심 primitive로 설명합니다. Vercel Sandbox, E2B, Daytona 같은 실행 환경도 개발자 에이전트가 코드를 안전하게 실행할 장소를 제공합니다. Cognition은 Devin 2.1을 공개하며 cloud agent infrastructure에서 isolated environment, secure remote access, agent state, collaboration UX가 중요하다고 설명했습니다. 각 회사의 구현은 다르지만, 공통된 결론은 같습니다. 코딩 에이전트는 모델 API 하나로 끝나지 않습니다.
Cursor의 선택에서 특히 눈에 띄는 것은 cloud agent를 IDE 경험과 끊지 않으려는 방향입니다. 사용자가 로컬에서 보고 있던 파일과 cloud에서 agent가 바꾸는 파일이 서로 다른 세계가 되면 생산성은 빠르게 무너집니다. 그래서 Cursor는 automatic context와 real-time interactivity를 첫 번째 조건으로 끌어올립니다. 이 말은 cloud agent가 "원격에서 알아서 해주는 봇"이 아니라 "IDE와 연결된 원격 실행 계층"이라는 뜻입니다.
12,000개 setup script가 보여준 현실
Cloud Agent 운영에서 가장 거친 현실은 setup입니다. Cursor는 12,000개 이상의 서로 다른 setup script가 Cloud Agents에서 사용됐다고 밝혔습니다. 이 숫자는 코딩 에이전트의 난도가 benchmark보다 훨씬 지저분하다는 점을 보여줍니다. 저장소마다 package manager가 다르고, node version이 다르고, database가 다르고, secret 주입 방식이 다르고, 사내 registry와 private dependency가 있습니다. 어떤 저장소는 문서화가 잘돼 있지만, 어떤 저장소는 특정 개발자의 노트북 상태를 암묵적으로 전제합니다.
일반적인 코드 생성 benchmark에서는 이런 문제가 사라집니다. 테스트 파일과 정답이 있고, 환경은 이미 준비돼 있습니다. 하지만 실제 회사 저장소에서는 agent가 먼저 "이 프로젝트를 실행 가능한 상태로 만드는 법"을 알아내야 합니다. Cursor는 setup 실패를 agent가 스스로 고치도록 만들었다고 설명합니다. 예를 들어 missing dependency, OS package, database startup 문제를 agent가 보고, setup script를 수정하거나 추가 명령을 실행합니다. Cursor는 이 self-healing setup에 3분을 주고, 해결하지 못하면 timeout한다고 밝혔습니다.
이 설계는 중요한 방향을 가리킵니다. 코딩 에이전트는 점점 더 "코드 작성자"가 아니라 "환경 복구자"가 됩니다. 실제 개발 시간의 상당 부분은 코드를 쓰는 행위보다 환경을 이해하고, test failure를 재현하고, dependency mismatch를 해결하고, CI와 로컬의 차이를 좁히는 데 쓰입니다. Cloud Agent가 이 영역을 다루지 못하면, 아무리 좋은 patch를 만들어도 팀 workflow에 들어가기 어렵습니다.
한국 개발팀 입장에서도 이 부분은 실무적입니다. AI 코딩 도구를 도입할 때 "우리 저장소에서 잘 작동하는가"는 모델 성능표로 알 수 없습니다. .env.example이 최신인지, setup script가 idempotent한지, seed data가 준비돼 있는지, test가 local과 CI에서 같은 결과를 내는지, secret 없이도 의미 있는 검증이 가능한지가 중요합니다. Cloud Agent는 지저분한 개발 환경을 더 선명하게 드러냅니다. 에이전트를 도입하면 기술 부채가 사라지는 것이 아니라, 자동화 가능한 형태로 노출됩니다.
신뢰는 기능이 아니라 인프라 요구사항
Cursor 글에서 가장 신중한 표현은 trust입니다. Cursor는 trust is difficult and earned라고 썼습니다. 클라우드 코딩 에이전트가 사용자 저장소를 clone하고, 코드를 실행하고, GitHub에 접근하고, 때로는 외부 API를 호출한다면 신뢰는 마케팅 문구가 아니라 인프라 요구사항입니다. 사용자는 agent가 무엇을 읽고, 무엇을 실행하고, 어떤 credential을 쓰고, 어떤 변경을 push하는지 알아야 합니다.
이 문제는 로컬 IDE보다 cloud에서 더 날카롭습니다. 로컬에서는 사용자가 자신의 머신과 네트워크 안에서 어느 정도 통제감을 가집니다. cloud agent는 vendor의 실행 환경에서 돌아갑니다. GitHub App 설치 권한, user-provided API key, repository checkout, branch push, PR 생성 권한이 모두 별도 surface가 됩니다. 에이전트가 유용해지려면 더 많은 권한이 필요하지만, 더 많은 권한은 더 큰 사고 반경을 만듭니다.
Cursor는 production 전용 접근을 agent에 맡기는 것을 안티패턴으로 다룹니다. 이것은 중요한 경계입니다. agent가 staging database나 mock service만으로 검증할 수 있도록 시스템을 설계하면 위험을 줄일 수 있습니다. 반대로 agent가 실제 production credential 없이는 테스트도 못 하는 구조라면, cloud agent 도입은 곧 보안 설계 문제로 바뀝니다. 에이전트 시대의 좋은 개발 환경은 사람에게 편한 환경을 넘어, agent에게 안전하게 위임 가능한 환경이어야 합니다.
이 관점에서 최근 코딩 에이전트 보안 논의와도 연결됩니다. prompt injection, over-permission, secret exfiltration, unsafe tool call은 모두 "모델이 나쁜 답을 했다"보다 "실행 환경이 무엇을 허용했는가"의 문제입니다. Cloud Agent는 명령을 실행할 수 있기 때문에 더 강력하지만, 같은 이유로 더 위험합니다. 따라서 제품 경쟁은 권한 범위, audit log, network policy, sandbox isolation, approval flow를 누가 더 잘 설계하는지로 이동합니다.
UI와 실시간성이 성능의 일부가 됐습니다
Cursor가 강조한 real-time interactivity도 가볍게 볼 수 없습니다. 코딩 에이전트는 긴 작업을 합니다. 사용자는 그동안 무슨 일이 일어나는지 보고 싶어 합니다. 어떤 파일이 바뀌었는지, 어떤 test가 실패했는지, agent가 왜 특정 방향으로 갔는지 확인해야 합니다. 이 피드백이 느리거나 불명확하면 사용자는 agent를 믿지 못합니다.
Cursor는 PR 페이지와 background agent 페이지를 같은 persistent agent state model 위에 얹었다고 설명합니다. 이 선택은 UI가 단순 표시 계층이 아니라 agent orchestration의 일부라는 점을 보여줍니다. 사용자는 agent의 state를 보고, 중간에 개입하고, 방향을 바꾸고, 결과를 review합니다. cloud agent가 완전히 자율적인 worker라기보다 human-in-the-loop 개발 흐름에 들어가는 이유입니다.
여기서 좋은 UX는 예쁜 화면보다 정확한 상태 전달입니다. 어떤 변경이 agent가 만든 것인지, 어떤 명령이 실행됐는지, 어떤 실패가 해결됐는지, 어떤 파일이 아직 불안정한지 보여줘야 합니다. 특히 여러 agent를 병렬로 돌릴 때는 충돌과 중복 작업을 관리해야 합니다. 같은 저장소에서 agent 두 개가 같은 파일을 고치면 merge conflict가 생깁니다. 같은 bug를 서로 다른 방식으로 고치면 review 비용이 올라갑니다. cloud agent가 많아질수록 orchestration UI와 작업 큐가 중요해집니다.
Cognition과 GitHub가 같은 질문을 하고 있습니다
Cursor만 이 방향을 보는 것은 아닙니다. Cognition은 Devin 2.1과 API를 발표하며 cloud agent infrastructure의 요구사항을 정리했습니다. isolated compute, browser와 shell 접근, persistent state, collaboration UI, secure credential handling은 Devin류 제품의 기본 조건입니다. GitHub Copilot coding agent도 issue에서 작업을 받아 branch와 PR을 만드는 원격 에이전트 흐름을 밀고 있습니다. OpenAI Codex도 repository를 읽고 작업을 수행하는 원격 코딩 경험을 강화했습니다.
차이는 distribution입니다. GitHub는 repository와 PR workflow를 이미 가지고 있습니다. Cursor는 IDE와 개발자 attention을 가지고 있습니다. Cognition은 autonomous software engineer라는 제품 포지션을 가지고 있습니다. OpenAI는 모델과 agent platform을 가지고 있습니다. 하지만 모두 같은 문제를 만납니다. 에이전트가 코드를 고치려면 실행 환경, 권한, 상태, 검증, review가 필요합니다.
그래서 이 경쟁은 모델 benchmark만으로 끝나지 않습니다. 오히려 각 회사가 어떤 control plane을 만드는지가 중요합니다. GitHub는 issues, PR, Actions, repository permissions를 control plane으로 삼을 수 있습니다. Cursor는 IDE context, local edits, background agents, cloud VM을 묶을 수 있습니다. Cognition은 long-running agent session과 task API를 전면에 둡니다. 개발팀은 어느 control plane이 자기 workflow와 덜 충돌하는지 봐야 합니다.
도입 전 봐야 할 체크리스트
Cloud Agent를 도입하려는 팀은 먼저 저장소의 실행 가능성을 점검해야 합니다. 새 VM에서 repository를 clone한 뒤 문서만 보고 test를 돌릴 수 있는지 확인해야 합니다. package manager lockfile이 안정적인지, system dependency가 명시돼 있는지, private registry 접근 방식이 정리돼 있는지, test database를 자동으로 띄울 수 있는지 봐야 합니다. 사람만 아는 setup 절차는 agent에게도 병목입니다.
둘째, 권한을 나눠야 합니다. agent에게 production credential을 주는 구조는 피해야 합니다. read-only token, scoped GitHub App permission, temporary secret, staging-only resource, network egress policy가 필요합니다. 셋째, review boundary를 정해야 합니다. agent가 PR을 만들 수는 있어도 자동 병합할 수 있는 조건은 더 엄격해야 합니다. 넷째, 비용을 추적해야 합니다. cloud VM, model call, indexing, test run, artifact storage, failed retry가 모두 비용입니다.
마지막으로 좋은 task를 정의해야 합니다. Cloud Agent는 모호한 대형 프로젝트보다 context가 충분하고 검증 기준이 있는 작업에서 먼저 성과가 납니다. 작은 bug fix, dependency upgrade, test repair, documentation-linked implementation, reproducible issue가 좋은 출발점입니다. 반대로 제품 방향이 불명확하거나, domain decision이 필요한 기능은 agent가 많은 변경을 만들수록 review 비용이 커질 수 있습니다.
결론은 원격 작업장의 경쟁입니다
Cursor의 Cloud Agent 회고는 코딩 에이전트 시장을 보는 렌즈를 바꿉니다. 더 좋은 모델이 중요하지 않다는 뜻은 아닙니다. 하지만 실제 제품에서 개발자가 체감하는 품질은 모델과 실행 계층의 곱입니다. repository가 준비돼 있고, context가 자동으로 들어가고, 변경이 실시간으로 보이고, workflow가 durable하고, 권한이 통제될 때 agent는 팀의 작업 흐름에 들어갑니다.
40% PR이라는 숫자는 Cursor 내부 생태계의 지표입니다. 그러나 그 숫자가 가리키는 방향은 더 넓습니다. 코딩 에이전트는 이제 채팅창 안의 기능이 아니라, 원격 VM과 workflow engine, indexer, sync layer, permission model을 포함한 운영층으로 진화하고 있습니다. 개발팀이 봐야 할 질문도 바뀝니다. "어떤 AI가 코드를 잘 쓰는가"에서 "우리 저장소는 AI가 안전하게 일할 수 있는 작업장인가"로 이동합니다.
이 변화는 불편하지만 생산적입니다. Cloud Agent는 잘 정리된 개발 환경에서는 병렬 작업자처럼 보입니다. 반대로 엉킨 저장소에서는 숨은 setup 지식과 권한 부채를 폭로합니다. Cursor의 회고가 흥미로운 이유도 여기에 있습니다. 제품 홍보 문서처럼 시작하지만, 실제로는 코딩 에이전트가 현실의 소프트웨어 공장에 들어갈 때 무엇이 부서지는지 보여주는 운영 보고서에 가깝습니다.