Kafka 위의 4나인 에이전트, Confluent의 실시간 AI 승부수
Confluent Intelligence Q2 업데이트는 Kafka/Flink 스트림을 AI 에이전트의 실시간 컨텍스트와 운영 제어판으로 바꿉니다.

- 무슨 일: Confluent가
Real-Time Context Engine, Streaming Agents, MCP 서버, Agent Skills를 GA로 묶었습니다.- Kafka/Flink 기반 운영 데이터를 에이전트가 저지연으로 읽고 쓰는 인프라를 전면에 세웠습니다.
- 의미: AI 에이전트 경쟁의 병목이 모델 호출에서 데이터 신선도와 권한 경계로 이동합니다.
- 개발자 영향: Claude Code, Cursor, GitHub Copilot 같은 MCP 클라이언트가 Confluent Cloud 리소스까지 다룰 수 있습니다.
- 주의점: 강력한 연결은 곧 운영 위험입니다. PII 감추기, private link, regional MCP 경계를 함께 봐야 합니다.
Confluent가 2026년 5월 19일 발표한 Q2 업데이트는 겉으로 보면 데이터 스트리밍 플랫폼의 기능 확장입니다. 하지만 AI 개발자 관점에서 보면 조금 다르게 읽힙니다. Kafka와 Flink가 단지 이벤트를 운반하는 배관이 아니라, AI 에이전트가 실제 업무 상태를 읽고 행동을 결정하는 실시간 컨텍스트 엔진으로 재정의되고 있습니다.
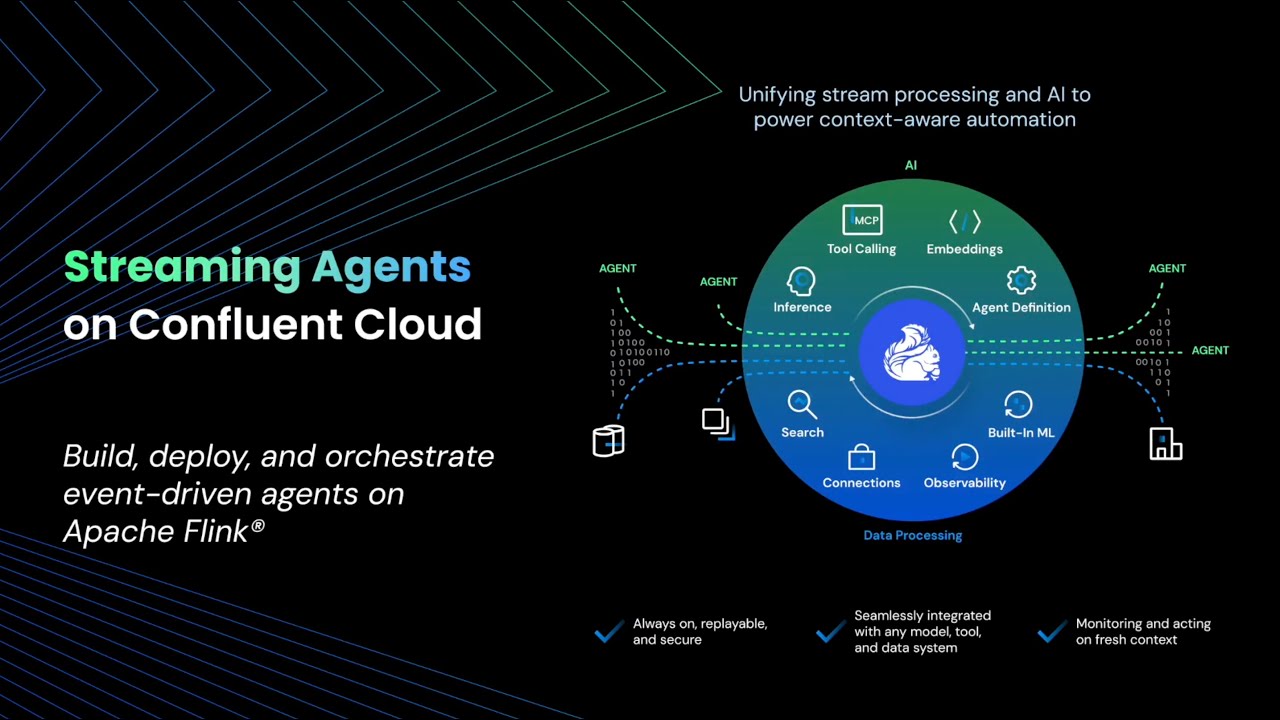
발표의 중심에는 네 가지 묶음이 있습니다. Confluent Intelligence의 Real-Time Context Engine이 일반 제공으로 전환됐고, Streaming Agents와 Agent Management Console도 GA가 됐습니다. 여기에 관리형 MCP 서버와 Agent Skills가 붙었습니다. Confluent는 보도자료에서 이를 "실시간 AI를 구축하고 보호하기 위한 업데이트"로 설명했습니다. 제품 이름은 많지만, 메시지는 하나입니다. 에이전트가 낡은 스냅샷이 아니라 지금 흐르는 데이터 위에서 작동해야 한다는 주장입니다.
이 점이 중요합니다. 최근 AI 에이전트 논의는 모델, 프롬프트, 도구 호출, 평가 벤치마크에 집중해 왔습니다. 그러나 실제 기업 환경에서 에이전트가 실패하는 지점은 더 지저분합니다. 데이터가 최신이 아니거나, 개인 식별 정보가 모델 호출로 흘러가거나, 운영 시스템을 건드릴 권한이 너무 넓거나, 실패한 작업을 추적할 로그가 충분하지 않은 경우입니다. Confluent의 이번 업데이트는 이 문제를 "데이터 플랫폼 쪽에서 풀겠다"는 선언에 가깝습니다.
모델보다 느린 데이터라는 병목
생성 AI 앱의 초창기 구조는 비교적 단순했습니다. 문서를 벡터 데이터베이스에 넣고, 검색 결과를 프롬프트에 붙여 모델에 넘겼습니다. 이 구조는 지식 문서, FAQ, 고객지원 초안에는 꽤 잘 맞습니다. 하지만 에이전트가 실시간 주문, 결제, 재고, 보안 이벤트, IoT 상태, 사용자 행동을 다뤄야 할 때는 이야기가 달라집니다. 어제 만든 임베딩이나 5분 전 동기화한 테이블은 의사결정의 근거로 부족할 수 있습니다.
Confluent가 Real-Time Context Engine을 전면에 세운 이유도 여기에 있습니다. Confluent의 Q2 업데이트 글은 이 엔진이 라이브 쿼리, 필터, 범위 조건, 복합 쿼리, projection, ordering을 지원한다고 설명합니다. 에이전트가 단순히 주 키로 한 레코드를 찾는 것이 아니라, 스트림에서 유지되는 최신 상태를 조건별로 읽고, 그 결과를 모델 호출이나 자동화 단계에 넣을 수 있게 하려는 방향입니다.
이는 RAG의 확장판이라기보다 운영 데이터 계층의 재배치에 가깝습니다. 정적 문서 검색은 "무엇을 알고 있는가"에 답합니다. 실시간 컨텍스트 엔진은 "지금 어떤 상태인가"에 답합니다. 에이전트가 실제 업무를 맡으려면 두 질문을 모두 처리해야 합니다. Confluent는 자신들의 기존 강점인 Kafka, Flink, Schema Registry, Stream Governance를 이 두 번째 질문의 인프라로 연결하고 있습니다.
Kafka 토픽과 Flink 스트림
Real-Time Context Engine
Streaming Agents와 MCP 클라이언트
운영 조치, 추천, 탐지, 자동화
Streaming Agents GA가 말하는 것
Streaming Agents는 이번 발표에서 가장 직접적으로 "에이전트 런타임"을 겨냥한 부분입니다. Confluent는 이를 Kafka와 Flink 위에서 동작하는 이벤트 기반 에이전트 구성요소로 제시합니다. 개발자는 스트리밍 데이터를 읽고, 모델을 호출하고, 결과를 다시 스트림이나 외부 시스템에 반영하는 흐름을 만들 수 있습니다.
여기서 주목할 점은 에이전트가 챗봇 UI에 묶여 있지 않다는 것입니다. 많은 팀이 에이전트를 여전히 대화창 안의 도우미로 상상합니다. 하지만 업무 자동화에서 더 중요한 형태는 사용자가 매번 질문하지 않아도 이벤트를 감시하고, 이상 징후를 잡고, 정책에 따라 조치 초안을 만들고, 필요하면 사람의 승인을 요청하는 흐름입니다. Confluent가 Streaming Agents라고 부르는 것은 이런 종류의 "상시 실행형 에이전트"에 더 가깝습니다.
Agent Management Console GA도 같은 방향입니다. Confluent의 설명에 따르면 이 콘솔은 에이전트의 입력, 출력, 프롬프트, 모델, 도구, 테이블, 로그를 관리하는 표면입니다. 모델 API 호출만 보면 에이전트는 검은 상자처럼 보이기 쉽습니다. 하지만 운영팀이 실제로 봐야 하는 것은 어떤 이벤트가 들어왔고, 어떤 프롬프트와 컨텍스트가 구성됐고, 어떤 모델과 도구가 쓰였고, 어떤 출력이 나갔는지입니다. Confluent는 이 관측과 운영의 문제를 데이터 스트리밍 플랫폼 안으로 끌어오고 있습니다.
이 지점에서 "4나인"이라는 표현도 단순한 가용성 마케팅 문구가 아닙니다. Confluent는 보도자료에서 중요 업무 환경을 위한 신뢰성과 확장을 강조합니다. AI 에이전트가 단순 추천을 넘어 결제, 보안, 물류, 고객 응대 같은 워크플로에 붙으면, 모델의 창의성보다 실패 모드의 예측 가능성이 더 중요해집니다. 실시간 데이터 위에서 실행되는 에이전트는 멋진 데모보다 운영 계약을 먼저 요구합니다.
MCP와 Agent Skills, 데이터 플랫폼이 코딩 에이전트로 열리는 순간
이번 업데이트에서 개발자에게 가장 직접적인 변화는 관리형 MCP 서버와 Agent Skills의 GA입니다. Confluent의 MCP 문서는 Claude Code, Cursor, VS Code with GitHub Copilot 같은 클라이언트 예시를 언급합니다. 이는 AI 코딩 도구가 Confluent Cloud의 조직, 환경, 클러스터, 토픽, 스키마, 커넥터, 메시지, 메트릭을 탐색하고 일부 작업을 수행하는 경로가 공식화됐다는 뜻입니다.
MCP는 요즘 너무 자주 등장해 피로감이 있는 단어입니다. 그러나 Confluent 사례에서는 꽤 실용적인 의미가 있습니다. 데이터 플랫폼은 원래 CLI, 콘솔, SDK, Terraform, REST API 사이에 작업이 흩어져 있습니다. 개발자가 "이 토픽의 스키마가 왜 깨졌는가", "커넥터가 왜 실패했는가", "최근 메시지 구조가 어떻게 바뀌었는가"를 확인하려면 여러 화면과 명령을 오가야 합니다. MCP 서버가 제대로 작동하면 AI assistant가 이 조사 과정을 대화형 작업으로 묶을 수 있습니다.
다만 Confluent 문서가 글로벌 서버와 regional 서버를 나누는 점은 중요합니다. 글로벌 MCP 서버는 조직 수준 리소스, 커넥터 디버깅, 메트릭 조회를 담당합니다. regional MCP 서버는 특정 리전의 Kafka 클러스터, 토픽, 스키마, 메시지 접근을 담당합니다. 이는 단지 배포 편의를 위한 구분이 아니라 권한과 데이터 경계의 구분입니다. 에이전트가 메시지를 읽을 수 있는 위치와 조직 메타데이터를 읽을 수 있는 위치가 같아지는 순간, 보안 검토는 훨씬 어려워집니다.
Agent Skills는 MCP보다 더 좁은 문제를 풉니다. Confluent는 Schema Registry, Apache Flink, Kafka Streams, Python Kafka Client, CDC to Tableflow 같은 워크플로를 위한 기술별 skill을 제공합니다. 이것은 범용 에이전트에게 "Confluent에서 이 작업은 이렇게 해야 한다"는 작업 맥락을 주는 방식입니다. AI 코딩 도구가 일반적인 Kafka 지식만으로 코드를 만들 때 생기는 버전 차이, 설정 누락, 운영 관례 누락을 줄이려는 시도입니다.
| 구성요소 | 역할 | 개발자에게 중요한 점 |
|---|---|---|
| Real-Time Context Engine | 실시간 운영 상태를 쿼리 가능한 컨텍스트로 제공 | 에이전트가 낡은 스냅샷이 아니라 현재 상태를 근거로 판단 |
| Streaming Agents | 이벤트 기반 에이전트를 Kafka/Flink 위에서 실행 | 챗봇이 아닌 상시 실행 자동화와 감시 흐름에 적합 |
| Managed MCP Server | AI assistant와 Confluent Cloud 리소스를 연결 | Claude Code, Cursor, Copilot류 도구가 데이터 플랫폼 조사를 보조 |
| Agent Skills | Confluent 작업별 절차와 관례를 에이전트에 제공 | 일반 LLM 지식보다 제품 맥락이 있는 코드와 설정을 유도 |
보안 발표가 본론인 이유
Confluent가 같은 발표에서 PII redaction과 Azure Private Link를 강조한 것도 우연이 아닙니다. 실시간 컨텍스트를 모델에 넘기는 순간, 데이터 보호 문제는 훨씬 까다로워집니다. 문서 RAG에서는 검색 대상 컬렉션을 제한하거나 인덱싱 단계에서 민감 정보를 제거할 수 있습니다. 스트리밍 에이전트에서는 데이터가 계속 흐르고, 모델 호출 시점의 컨텍스트가 매번 달라집니다. 잘못 설계하면 민감 정보가 모델 요청에 그대로 포함될 수 있습니다.
Confluent는 Flink SQL에서 PII 탐지와 감추기 함수를 제공한다고 발표했습니다. 이것은 AI 보안이 애플리케이션 프롬프트 계층만의 문제가 아니라 데이터 처리 계층의 문제가 됐다는 신호입니다. 모델에 "개인 정보를 노출하지 말라"고 지시하는 것보다, 모델에 들어가기 전에 스트림 처리 단계에서 개인 정보를 식별하고 마스킹하는 편이 더 검증 가능합니다.
Azure Private Link 지원도 같은 맥락입니다. Confluent는 Azure OpenAI, Azure SQL, Cosmos DB 같은 Azure-hosted 서비스와 Confluent Cloud를 private backbone으로 연결할 수 있다고 설명합니다. 에이전트 앱이 모델, 데이터베이스, 스트림 플랫폼을 동시에 사용한다면 네트워크 경계는 더 이상 부수적인 설정이 아닙니다. 어떤 데이터가 공용 인터넷을 지나지 않는지, 어떤 모델 제공자에게 어떤 컨텍스트가 전달되는지, 어떤 리전에서 메시지를 읽는지가 설계의 일부가 됩니다.
이런 발표는 화려하지 않습니다. 하지만 실제 AI 도입에서는 여기서 차이가 납니다. 많은 기업이 "우리 데이터로 AI를 쓰고 싶다"고 말하지만, 실제 질문은 더 구체적입니다. 어느 데이터까지 모델에 보여줄 수 있는가. 어떤 필드는 감춰야 하는가. 어떤 리소스 접근은 사람이 승인해야 하는가. 에이전트가 조치를 취했을 때 어떤 로그가 남는가. Confluent는 이번 업데이트에서 이 질문들을 데이터 스트리밍 플랫폼의 기능 목록으로 바꾸려 합니다.
모델 선택은 부품이 되고, 컨텍스트 계층이 차별점이 된다
Q2 업데이트에는 모델 관련 내용도 포함됩니다. Confluent는 Anthropic Claude와 Fireworks AI 지원을 GA로 전환했고, TimesFM 2.5 기반 이상 탐지 함수인 AI_DETECT_ANOMALIES도 언급했습니다. 이 조합은 흥미롭습니다. 한편으로는 외부 LLM을 호출하고, 다른 한편으로는 시계열 이상 탐지 같은 built-in ML 함수를 Flink SQL 가까이에 둡니다.
이 구조는 "한 모델이 모든 것을 해결한다"는 그림과 다릅니다. 운영 데이터에서는 모델 호출 비용, 지연, 정확도, 거버넌스가 모두 중요합니다. 어떤 문제는 Claude 같은 범용 모델이 문맥을 읽고 판단하는 편이 낫습니다. 어떤 문제는 TimesFM 같은 시계열 모델이 이상 패턴을 잡는 편이 낫습니다. 어떤 문제는 모델 없이 SQL과 규칙으로 처리하는 편이 더 안전합니다. Confluent의 포지션은 이 선택지를 스트림 처리 파이프라인 안에서 조합하게 만드는 쪽입니다.
개발자 입장에서는 이 점이 실용적입니다. AI 앱을 만들 때 모든 것을 프롬프트로 밀어 넣으면 디버깅이 어렵습니다. 반대로 데이터 전처리, 정책 적용, 모델 선택, 결과 저장을 스트림 처리 단계로 나누면 각 단계의 책임이 분명해집니다. 실패했을 때도 "모델이 이상했다"는 막연한 말 대신, 어떤 이벤트, 어떤 컨텍스트, 어떤 함수, 어떤 모델 호출이 문제였는지 추적할 수 있습니다.
커뮤니티의 조용함도 하나의 신호
이번 발표는 HN이나 GeekNews에서 대형 모델 발표처럼 즉각적인 화제를 만들지는 못했습니다. 이것은 발표가 중요하지 않다는 뜻이라기보다, AI 인프라의 많은 변화가 커뮤니티 밈이 아니라 구매, 보안, 운영 검토의 언어로 움직인다는 뜻에 가깝습니다. "새 모델이 코딩을 더 잘한다"는 뉴스는 누구나 바로 시험해 볼 수 있습니다. "Kafka/Flink 스트림을 에이전트 컨텍스트 엔진으로 운영한다"는 뉴스는 데이터 플랫폼을 이미 운영하는 팀에게 더 직접적입니다.
그럼에도 개발자 생태계에는 간접 영향이 큽니다. Claude Code, Cursor, Copilot 같은 도구가 MCP를 통해 Confluent 리소스를 다룰 수 있게 되면, 코딩 에이전트의 작업 범위가 코드 저장소 밖으로 확장됩니다. 에이전트가 스키마를 확인하고, 커넥터 상태를 조사하고, 메시지 흐름을 요약하고, Flink 쿼리 초안을 만들 수 있습니다. 좋은 쪽으로는 반복적인 운영 조사가 줄어듭니다. 나쁜 쪽으로는 잘못된 권한 설정이 더 빨리 문제를 키울 수 있습니다.
이 때문에 MCP 도입은 "연결되니 편하다"에서 끝나면 안 됩니다. 어떤 클라이언트가 어떤 서버에 붙는지, regional 서버가 어떤 클러스터 메시지를 읽는지, 토큰과 API key가 어떻게 발급되는지, 감사 로그가 어디에 남는지, 에이전트가 제안만 하는지 실행까지 하는지 분리해야 합니다. Confluent가 관리형 MCP와 Agent Skills를 내놓은 것은 이런 검토를 피하게 해주는 것이 아니라, 오히려 검토 대상을 더 분명하게 만든 사건입니다.
AI 에이전트의 다음 경쟁 축
이번 Confluent 업데이트를 단순히 "Kafka 회사가 AI 기능을 붙였다"고 보면 핵심을 놓칩니다. 더 큰 흐름은 데이터 플랫폼, 클라우드, 코딩 에이전트, MCP 생태계가 하나의 운영 표면으로 붙기 시작했다는 점입니다. 모델 제공자는 더 긴 컨텍스트와 더 나은 추론을 제공합니다. 코딩 도구는 더 많은 작업을 자동화합니다. 데이터 플랫폼은 에이전트가 행동할 수 있는 최신 상태와 권한 경계를 제공합니다.
이 흐름에서 Confluent의 강점은 명확합니다. 실시간 이벤트와 스트림 처리 인프라를 이미 보유한 팀에게 AI 에이전트용 별도 데이터 계층을 새로 만들지 말고, 기존 Kafka/Flink 기반 운영 데이터 위에 컨텍스트 엔진과 에이전트 런타임을 얹으라고 제안할 수 있습니다. 반대로 약점도 있습니다. Confluent 생태계에 깊게 들어가야 가치가 커지고, 에이전트 앱을 처음 만드는 팀에게는 구조가 복잡하게 느껴질 수 있습니다.
경쟁 구도도 넓습니다. Databricks와 Snowflake는 AI와 데이터 거버넌스를 웨어하우스/레이크하우스 중심으로 묶고 있습니다. 클라우드 사업자는 자체 AI 모델, 네트워크, 데이터베이스, 보안 서비스를 한 계정 안에서 엮습니다. LangGraph, Temporal, 자체 워크플로 엔진은 에이전트 실행과 재시도를 애플리케이션 계층에서 다룹니다. Confluent의 차별점은 "이벤트가 발생하는 순간"과 "운영 상태가 변하는 순간"을 AI 컨텍스트로 삼겠다는 데 있습니다.
개발자와 AI 팀이 지금 확인해야 할 질문은 비교적 현실적입니다. 우리 에이전트가 판단할 때 필요한 데이터는 문서인가, 현재 상태인가. 현재 상태라면 그 상태는 어디에서 가장 신뢰할 수 있게 계산되는가. 모델 호출 전에 제거해야 할 PII는 무엇인가. 에이전트가 읽기만 해도 되는가, 쓰기와 조치까지 해야 하는가. Confluent의 발표는 이 질문들을 피하지 말고 인프라 설계의 첫 단계로 끌어올리라고 요구합니다.
결국 이번 뉴스의 핵심은 "Kafka가 AI를 한다"가 아닙니다. AI 에이전트가 실제 업무에 들어갈수록 컨텍스트는 더 실시간이어야 하고, 권한은 더 좁아야 하며, 관측은 더 자세해야 한다는 점입니다. Confluent Intelligence Q2 업데이트는 그 방향을 데이터 스트리밍 플랫폼의 언어로 구현한 사례입니다. 모델 경쟁의 속도가 빨라질수록, 모델에 무엇을 보여주고 어떤 행동을 허용할지 정하는 데이터 계층의 경쟁도 함께 빨라지고 있습니다.