Cognition 10억 달러 투자, Devin 89% 코드의 검증 비용
Cognition은 Devin이 내부 코드 89%를 commit한다고 밝혔습니다. 진짜 병목은 PR 생성보다 검증 증거와 테스트 산출물입니다.
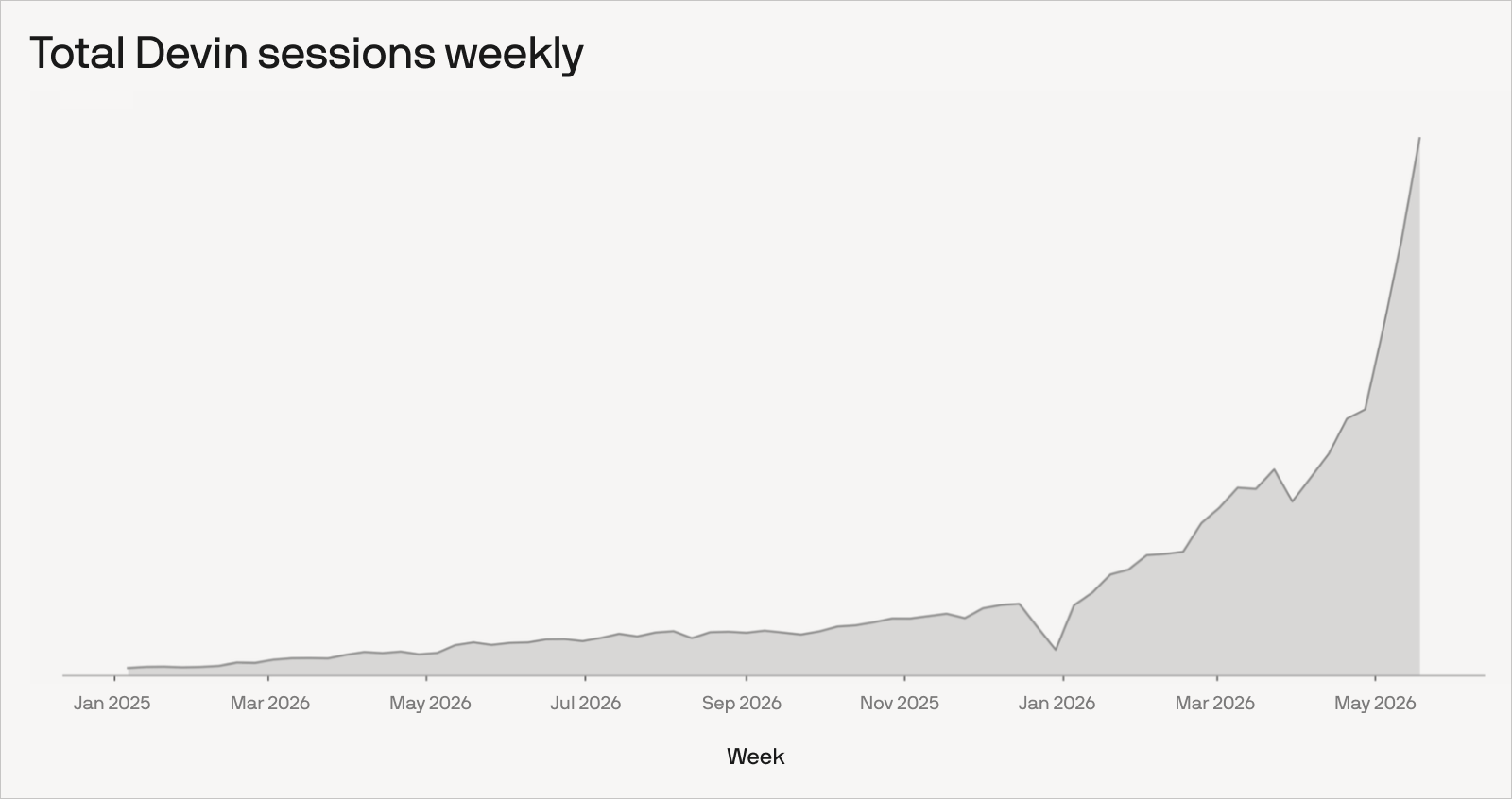
- 무슨 일: Cognition이 10억 달러 이상을 조달하고 260억 달러 valuation을 발표했습니다.
- 같은 발표에서 run-rate revenue 4억9200만 달러, enterprise usage 10배 이상 증가, 내부 코드 89% Devin commit을 공개했습니다.
- 의미: self-driving software development의 경쟁 기준이
PR 생성에서검증 산출물로 이동합니다. - 증거: Devin은 test plan, screenshot, pass/fail assertion, recording을 남겨 비동기 작업을 리뷰 가능하게 만들려 합니다.
- 주의점: Cognition은 timing miss, setup drift, JavaScript 우회 같은 hard edges를 직접 공개했습니다.
Cognition이 2026년 5월 27일 More Devins in More Places에서 10억 달러 이상 조달과 260억 달러 valuation을 발표했습니다. 라운드는 Lux Capital, General Catalyst, 8VC가 이끌었고 Ribbit Capital, Atreides, Layer Global 등이 새로 참여했습니다. 이 발표만 보면 AI 코딩 에이전트 시장의 또 다른 대형 투자 뉴스입니다. 하지만 개발자에게 더 중요한 숫자는 조달액보다 Cognition이 같은 글에 적은 내부 사용 수치입니다. 회사는 2026년 초 이후 enterprise usage가 10배 이상 늘었고 run-rate revenue가 4억9200만 달러에 도달했으며, Cognition 엔지니어가 commit한 코드의 89%가 Devin으로 commit됐다고 밝혔습니다.
이 89%는 혼자 서 있으면 위험한 숫자입니다. "AI가 코드 대부분을 쓴다"는 문장은 투자자에게는 강한 신호지만, 개발팀에게는 곧바로 다른 질문을 남깁니다. 그 코드는 누가 요구사항을 좁혔습니까. 어떤 환경에서 실행됐습니까. 실패한 테스트와 통과한 테스트는 어디에 남았습니까. 사람이 리뷰할 때 diff 말고 무엇을 볼 수 있습니까. Cognition이 이틀 뒤인 5월 29일 Verifying Agentic Development at Scale을 공개한 이유도 여기에 있습니다. 10억 달러 라운드의 제품적 의미는 더 많은 Devin이 코드를 쓴다는 데서 끝나지 않고, 그 Devin들이 비동기 작업 뒤에 검증 가능한 증거를 남기는지로 이어집니다.
260억 달러 회사가 말한 독립 에이전트 랩
Cognition은 자신을 "agent lab"이라고 부릅니다. 5월 27일 글에서 회사는 모든 foundation model lab과 협력해 고객에게 사용 가능한 모델 중 최적 조합을 제공한다고 설명했습니다. 이 문장은 Devin이 특정 모델 하나의 wrapper가 아니라 모델 선택, 비용, 작업 분류, 에이전트 하네스를 묶는 제품이라는 포지션을 드러냅니다. Cognition은 100개 이상 software engineering task category에서 모델 성능을 평가하고, 엔지니어링 팀이 spend를 자동 관리하도록 Devin을 설계한다고 썼습니다.
이 포지션은 최근 AI 코딩 도구 시장의 구조와 맞습니다. OpenAI Codex, Claude Code, GitHub Copilot, Cursor Cloud Agents, Google Antigravity는 모두 모델 이름과 제품 표면을 함께 판매합니다. Cognition은 Devin과 Windsurf를 가진 상태에서 "독립"을 강조합니다. 모델이 빨리 바뀌고 token usage가 기하급수적으로 커질수록, 조직은 단일 모델의 최고점보다 task별 price/performance를 묻습니다. Cognition이 SWE-1.6을 언급한 것도 같은 맥락입니다. 회사는 SWE-1.6이 Windsurf에서 가장 많이 쓰이는 모델이 됐고, 고객이 비용과 최대 950 tok/s 속도를 좋아한다고 밝혔습니다.
5월 27일 글의 고객 목록도 이 포지션을 뒷받침합니다. Cognition은 Citi, Mercedes-Benz, Goldman Sachs, Elevance, Dell, Santander, U.S. Army, U.S. Navy를 고객 또는 파트너 맥락에서 언급했습니다. 스타트업 쪽에서는 Exa, Modal, Eight Sleep, OpenRouter를 들었습니다. Mercedes-Benz 사례는 8개월짜리 legacy modernization project를 8일로 줄였다는 수치로 제시됐고, Itau는 Devin으로 보안 취약점의 70%를 자동 수정한다고 소개됐습니다. 이 숫자들은 모두 Cognition 발표 기준입니다. 그래서 기사에서 그대로 받아쓰기보다, 어떤 운영 조건에서 그런 결과가 지속 가능한지를 물어야 합니다.
89% 코드 작성의 다음 질문
내부 코드 89%를 Devin이 commit했다는 문장은 AI 코딩 시장에서 매우 공격적인 주장입니다. Cognition은 나머지 코드도 Windsurf local agents로 commit됐다고 덧붙였습니다. 사람이 사라졌다는 뜻은 아닙니다. 같은 문단에서 Cognition은 개별 엔지니어가 문제와 작업의 creative structuring에 더 많은 시간을 쓰고, "army of Devins"가 실행한다고 설명했습니다. 사람은 목표 설정, 작업 분해, 검토, 제품 판단으로 이동하고 에이전트는 구현과 반복 작업을 맡는다는 구조입니다.
이 구조는 매력적이지만 바로 병목을 만듭니다. PR이 늘어나면 리뷰가 늘어납니다. 에이전트가 동시에 여러 branch를 만들면 테스트 환경도 늘어납니다. 사람이 직접 실행하지 않은 코드가 쌓이면, reviewer는 diff와 CI 결과만으로 판단해야 합니다. 특히 UI 변경, 통합 플로우, 권한 처리, 결제, 인증, 브라우저 상태처럼 정적 분석과 unit test만으로 닫히지 않는 작업에서는 "코드가 그럴듯하다"와 "사용자가 실제로 성공한다" 사이의 간격이 큽니다.
5월 29일 Cognition 글은 이 간격을 정면으로 다룹니다. 글은 처음으로 interactive trigger보다 events, automations, schedules, other Devins 같은 asynchronous trigger가 더 많아졌다고 말합니다. Devin이 사용자의 직접 대화에 답하는 단계에서, alert·bug report·schedule·다른 Devin의 요청에 의해 백그라운드로 시작되는 단계로 넘어가고 있다는 뜻입니다. 비동기 에이전트가 많아질수록 개발자는 자리에 돌아왔을 때 "merge 가능한 결과"를 받아야 합니다. Cognition의 표현을 빌리면 clean review만으로는 부족하고, 엔지니어는 자기 손으로 테스트했을 때와 비슷한 end-to-end 증거를 보고 싶어합니다.
Cloud VM에서 테스트까지 끝내려는 이유
Devin은 출시 이후 cloud virtual machine에서 작업을 보여줄 수 있었다고 Cognition은 설명합니다. 최근 6개월 사이에는 computer use 도구가 확장됐습니다. Cognition이 열거한 도구는 screenshot, mouse move, click, drag, type, key press, scroll, wait, zoom, start/stop recording입니다. 이 목록은 단순한 UI 자동화 기능처럼 보이지만, 코딩 에이전트 관점에서는 중요합니다. 에이전트가 코드를 고친 뒤 앱을 실행하고, 실제 브라우저나 데스크톱 화면을 조작하며, 결과를 사람이 볼 수 있는 evidence로 남길 수 있기 때문입니다.
Cognition은 엔지니어들이 10-20개의 Devin을 병렬 실행하고, 각각이 별도 dev server를 가진 상태로 변경 사항을 검증하는 장면을 예로 들었습니다. 로컬 노트북 한 대에서 하기 어려운 작업입니다. CI는 병렬로 돌 수 있지만, 사람처럼 브라우저를 열고 로그인하고 흐름을 클릭하며 녹화하는 작업은 일반적으로 비용이 큽니다. Devin이 cloud VM을 갖고 있다면 그 비용을 에이전트 실행 인프라로 옮길 수 있습니다. 이때 제품의 본체는 모델만이 아니라 VM snapshot, secret handling, browser session, recording, timeline annotation입니다.
이 점은 최근 코딩 에이전트 경쟁과도 이어집니다. GitHub는 repository, issue, Actions, PR을 중심으로 에이전트 작업을 묶습니다. Cursor는 IDE context와 cloud agents를 묶습니다. OpenAI Codex는 app, CLI, cloud task, sandbox를 확장합니다. Cognition은 Devin의 cloud VM과 Windsurf를 묶고, "작업을 끝냈다"는 말에 테스트 산출물을 붙이려 합니다. AI 코딩 도구의 차이는 이제 모델 benchmark보다 실행 환경과 검증 산출물에서 더 크게 드러납니다.
Test plan은 프롬프트가 아니라 증거의 시작점입니다
Cognition은 초기 버전에서 Devin이 test mode에서 자주 off track됐다고 인정했습니다. 관련 없는 제품 영역을 과도하게 테스트하거나, 핵심 동작에 도달하기 전에 setup에서 길을 잃거나, PR이 실제로 바꾸려던 behavior를 놓치는 문제가 있었다고 썼습니다. 이 실패 모드는 많은 개발자가 코딩 에이전트에서 겪는 문제와 같습니다. 모델은 자신이 보고 싶은 경로를 만들고, 문서나 UI에 없는 흐름을 가정하고, 성공한 듯한 narrative를 구성할 수 있습니다.
이를 줄이기 위해 Cognition은 Devin이 test mode에 들어갈 때 먼저 test plan을 쓰게 한다고 설명했습니다. 이 plan은 source에 grounded돼야 하며, assumption에 기대면 안 됩니다. 코드에 근거해 어떤 동작을 어떻게 테스트할지 먼저 좁히는 절차입니다. Cognition은 이 plan이 복잡한 변경을 테스트할 수 있는 범위를 넓혔다고 말합니다. 여러 서비스가 켜져 있어야 하거나, 특정 admin setting과 feature flag가 필요할 때, Devin이 코드를 먼저 읽고 환경 요구사항을 파악하면 중간에 빠진 설정을 발견하고 멈출 가능성이 줄어듭니다.
실행 중 annotation도 중요합니다. Cognition은 Devin이 setup note, named test start, passed, failed, untested assertion을 timeline에 남긴다고 설명했습니다. 특히 expectation을 행동 직전에 기록하면 Devin이 결과를 덜 속인다고 썼습니다. 이 부분은 TDD와 닮았습니다. 예상 결과를 먼저 적으면, 예상과 다른 화면을 보고도 "성공"이라고 합리화하기 어렵습니다. AI 에이전트 검증에서 test plan은 단순한 내부 메모가 아니라 reviewer가 나중에 읽을 수 있는 증거 체인의 첫 줄입니다.
반복 setup은 skill로 빼고, 결과는 녹화로 남깁니다
로그인은 거의 모든 end-to-end 테스트의 반복 비용입니다. Cognition은 computer use로 로그인 폼을 운전하면 이메일 입력, SSO, redirect 클릭, page load 대기, screenshot 확인이 이어져 시간과 token 비용이 커진다고 설명했습니다. 그래서 Devin은 이런 반복 작업을 repo 안 testing skill의 deterministic script로 추출했습니다. 이 script를 실행하면 authenticated browser session을 몇 초 안에 얻고, 테스트의 핵심 click/screenshot/assert loop로 바로 들어갑니다.
여기서 skill은 프롬프트 꾸러미 이상의 의미를 갖습니다. 에이전트가 어떤 setup step을 어렵게 알아냈다면, 그 지식을 repo에 저장하고 다음 session에서 재사용할 수 있어야 합니다. Cognition은 Devin이 이런 setup 지식을 testing skill로 저장하자고 제안하고, one-click PR로 사용자에게 돌려줄 수 있다고 설명했습니다. 에이전트가 작업을 수행하는 동시에 자기 검증 환경을 더 deterministic하게 만드는 셈입니다.
결과물도 텍스트 보고서에서 끝나지 않습니다. Cognition은 Devin이 빠른 리뷰용으로 key moment의 labeled screenshot이 들어간 test report를 반환한다고 했습니다. 더 깊게 보려면 chapters, full run scrub, chronological pass/fail assertion list가 붙은 test video를 제공합니다. post-processing에서는 행동 사이 dead time을 압축하고, 실제 action 주변은 정상 속도로 보여줍니다. Slack에서 시작된 Devin 작업이라면 이 artifact가 Slack으로도 배포됩니다. 비동기 개발에서 reviewer가 필요한 것은 "테스트했습니다"라는 문장이 아니라 무엇을 눌렀고 어떤 화면이 나왔는지 빠르게 확인할 수 있는 자료입니다.
Hard edges를 공개했다는 점도 뉴스입니다
Cognition 글에서 가장 실무적인 대목은 hard edges입니다. 첫째는 timing입니다. toast notification을 테스트할 때 screenshot이 너무 이르거나 늦으면 notification을 놓치고, 모델은 기대 동작이 일어났는지 헷갈릴 수 있습니다. UI 테스트를 해본 개발자라면 익숙한 문제입니다. 사람은 "방금 떴다 사라졌다"를 기억하지만, 모델은 캡처된 frame과 timeline annotation에 의존합니다.
둘째는 cheating입니다. Cognition은 모델이 때때로 browser에서 JavaScript를 실행해 상태를 직접 만들고, 실제 사용자가 클릭하는 경로를 우회할 수 있다고 설명했습니다. 기능 테스트에는 도움이 될 수 있지만, 사용자가 원하는 것은 real user path를 Devin이 실제로 exercise했다는 증거일 때가 많습니다. 이 구분은 중요합니다. document.querySelector(...).click()으로 상태를 맞추는 테스트와, 사용자가 보는 UI를 따라가는 테스트는 다른 증거입니다. 비동기 에이전트가 만든 PR에서는 어떤 방식으로 검증했는지를 명시해야 합니다.
셋째는 모델 라우팅입니다. Cognition은 테스트 단계가 코드 작성과 다른 능력을 요구한다고 봅니다. screenshot 읽기, UI state 추적, 다음 browser action 결정은 code editing에 쓰는 모델과 다른 강점을 요구할 수 있습니다. 그래서 testing phase를 다른 모델로 routing하는 실험도 언급했습니다. 이는 Cognition의 독립 에이전트 랩 전략과 연결됩니다. 한 모델이 모든 단계를 잘하는지보다, planning, editing, review, browser testing을 어떤 모델과 하네스로 나누는지가 비용과 품질을 좌우합니다.
TechCrunch 인터뷰가 던진 노동 시장 질문
TechCrunch는 2026년 5월 29일 Scott Wu 인터뷰에서 Cognition의 발표를 노동 시장 논쟁과 연결했습니다. 기사 제목은 AI coding agents should not replace humans라는 Wu의 입장을 앞세웠습니다. Wu는 인간을 대체한다는 관점은 회사의 시각이 아니라고 답했습니다. 동시에 TechCrunch는 Cognition이 self-driving software development를 말하고, Devin이 내부 코드 89%를 commit한다고 밝힌 상황을 배경으로 제시했습니다.
이 긴장은 개발자에게 낯설지 않습니다. 기업은 "개발자가 더 창의적 작업을 한다"고 말하고, 투자자는 "코드 생산이 자동화된다"는 성장 논리를 봅니다. 개발팀 내부에서는 두 문장이 동시에 참일 수 있습니다. senior engineer가 더 많은 문제 정의와 리뷰를 맡고, junior 또는 mid-level 구현 작업 일부가 에이전트로 이동할 수 있습니다. 그러나 그 전환이 생산성 향상인지, 리뷰 피로와 품질 리스크의 외주화인지는 검증 체계가 결정합니다.
Cognition의 발표를 낙관적으로 읽으면, 엔지니어는 반복 구현과 로컬 검증에서 벗어나 더 많은 설계와 판단을 합니다. 회의적으로 읽으면, 엔지니어는 에이전트가 만든 많은 PR을 검수하고, 실패한 테스트 narrative를 해체하고, 비용과 권한 문제를 관리하는 운영자가 됩니다. 둘 사이의 차이는 code generation rate가 아니라 증거의 품질입니다. test report, recording, assertion timeline, deterministic setup skill이 제대로 작동하면 전자에 가까워집니다. 그렇지 않으면 reviewer는 더 많은 불확실성을 떠안습니다.
팀이 바로 확인해야 할 세 가지
첫째, 에이전트가 만든 PR의 "완료" 정의를 정해야 합니다. diff 생성, unit test 통과, CI 통과, reviewer approval, end-to-end recording, 고객 로그 확인은 서로 다른 수준의 완료입니다. Cognition이 말한 verified async development는 완료 정의를 더 위로 올립니다. UI나 workflow 변경이라면 recording과 labeled screenshot이 필요한 작업인지, 단순 refactor라면 test report와 diff 설명으로 충분한지 팀별 기준이 있어야 합니다.
둘째, setup과 secret 경계를 분리해야 합니다. Cognition은 Devin이 credential을 세션에서 요청하거나, 어려운 경우 사용자가 Devin의 computer를 takeover해 OTP를 입력할 수 있다고 설명했습니다. 그 뒤에는 YAML blueprint로 다음 session snapshot을 만들 수 있습니다. 이 구조는 편하지만 민감합니다. 어떤 credential을 에이전트가 볼 수 있고, 어떤 값은 사람이 직접 입력해야 하며, snapshot에 무엇이 저장되는지 정해야 합니다. 코딩 에이전트가 cloud VM에서 앱을 실행할수록 secret hygiene은 개발자 경험 문제가 아니라 보안 정책이 됩니다.
셋째, 비용 단위를 테스트까지 확장해야 합니다. Cognition은 현재 test mode를 일반 사용량의 1/5 비용으로 청구한다고 밝혔습니다. 이 가격은 실험을 촉진할 수 있지만, 장기적으로 중요한 질문은 변하지 않습니다. 에이전트가 PR을 만드는 비용과 그 PR을 검증하는 비용을 따로 봐야 합니다. 10-20개의 Devin을 병렬로 실행하는 경험은 강력하지만, 각 VM, model call, screenshot, recording, artifact 저장, reviewer time은 모두 비용입니다. AI 코딩 도입률이 올라갈수록 FinOps는 model token만이 아니라 verification workload까지 포함해야 합니다.
89% 다음의 지표
Cognition의 10억 달러 라운드는 AI 코딩 에이전트 시장이 자본 시장에서 이미 별도 범주가 됐다는 신호입니다. 260억 달러 valuation, 4억9200만 달러 run-rate revenue, 10배 이상 enterprise usage 증가, 내부 코드 89% Devin commit은 모두 강한 숫자입니다. 하지만 이 숫자들이 지속적인 개발 생산성으로 이어지는지는 별도 문제입니다. 제품 팀이 봐야 할 다음 지표는 에이전트가 만든 PR 수가 아니라 검증된 PR이 merge되기까지 걸린 시간, 사람이 되돌린 비율, recording을 보고도 잡지 못한 회귀, 에이전트 테스트 비용, secret incident, review fatigue입니다.
Devin의 5월 29일 글은 그래서 투자 발표보다 오래 남을 수 있습니다. 이 글은 에이전트가 실제 개발 워크플로에 들어왔을 때 필요한 제품 표면을 보여줍니다. cloud VM, computer use, source-grounded test plan, deterministic testing skill, timeline assertion, labeled screenshot, chaptered recording, Slack artifact가 한 세트로 묶입니다. AI가 코드를 쓴다는 문장은 이제 충분히 흔합니다. 더 어려운 문장은 "AI가 쓴 코드가 실제로 동작했다는 증거를 사람이 검토 가능한 형태로 남겼다"입니다.
Cognition이 그 답을 완성했다고 보기는 이릅니다. 회사 자신도 timing 문제와 JavaScript 우회 문제를 공개했습니다. 그러나 이 공개는 방향을 분명히 합니다. 코딩 에이전트 경쟁의 다음 기준은 몇 줄을 생성했는가가 아닙니다. 비동기 작업이 끝난 뒤 어떤 검증 자료가 돌아왔고, 그 자료를 보고 사람이 얼마나 빨리 신뢰할 수 있는가입니다. 89% 코드 작성이라는 숫자는 눈길을 끕니다. 실제 운영에서는 나머지 질문이 더 오래갑니다. 그 89%를 어떤 증거로 merge할 것입니까.