사회과학자 20%만 코딩 에이전트를 쓴다, 연구 생산성의 격차
Anthropic이 사회과학자 1,260명 설문을 공개했습니다. AI 사용 81%, 코딩 에이전트 20%, 생산성 신호와 채택 격차를 짚습니다.
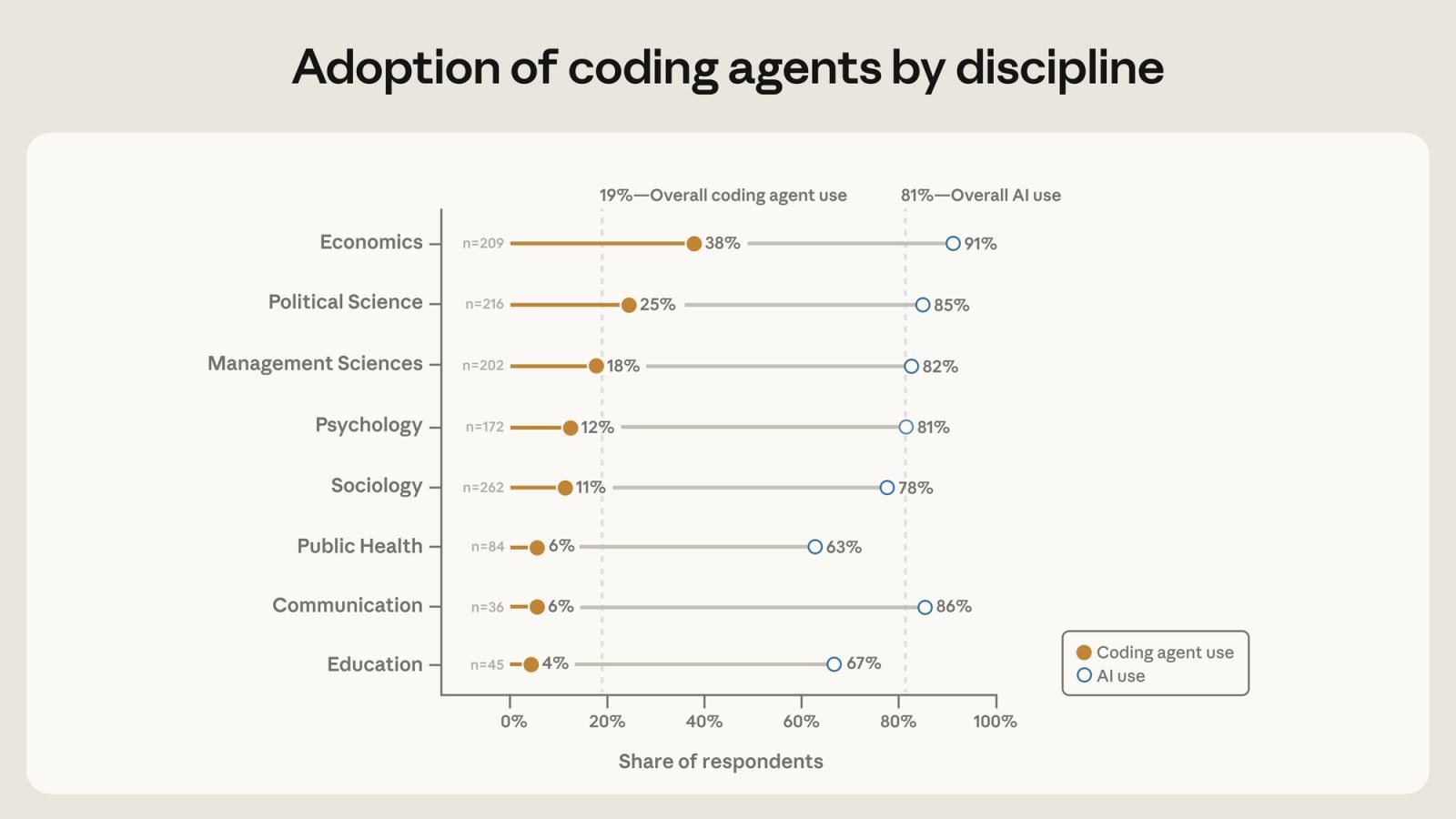
- 무슨 일: Anthropic이 정량 사회과학자 1,260명의 AI·코딩 에이전트 사용 설문을 공개했습니다.
- 연구용 생성 AI를 써본 응답자는 81%, CLI 기반 코딩 에이전트를 주 1회 이상 쓰는 응답자는 20%였습니다.
- 격차: 경제학 38-39%, 박사과정 27%, 남성 이름 22%, 여성 이름 9%처럼 초기 채택이 고르게 퍼지지 않았습니다.
- 생산성: 에이전트 사용자는 working paper와 grant proposal을 더 많이 냈지만, Anthropic은 인과 해석을 경계했습니다.
- 저널 신규 투고나 재투고 증가 증거는 아직 없고, 품질 평가는 다음 연구로 남았습니다.
- 실무 영향: 코딩 에이전트는 소프트웨어 팀 밖의 데이터 분석 업무로 이동하지만, 검증과 접근성 비용을 함께 만듭니다.
Anthropic이 2026년 5월 27일 공개한 사회과학 코딩 에이전트 조사는 Claude Code 홍보 글보다 연구 현장의 baseline 조사에 가깝습니다. 조사 대상은 2026년 2월 20일부터 3월 24일까지 설문에 응답한 미국·캐나다 정량 사회과학자 1,260명입니다. 연구 과정에서 생성 AI를 써본 사람은 81%였지만, Claude Code, Codex, Cursor, Google Antigravity 같은 CLI 통합 코딩 에이전트를 주 1회 이상 정기적으로 쓰는 사람은 20%였습니다.
이 숫자에서 확인되는 변화는 AI 코딩 도구가 개발자 시장을 넘어 연구실로 들어간다는 점입니다. 확산 속도도 균등하지 않습니다. Anthropic의 도표에서 경제학자는 38-39%가 코딩 에이전트를 쓴다고 답했지만, 교육 분야는 4%, 공중보건과 커뮤니케이션은 각각 6%였습니다. 박사과정과 포스트닥은 각각 27%, 28%였고 정교수는 9%였습니다. 일반적으로 남성 이름으로 분류된 응답자는 22%, 여성 이름으로 분류된 응답자는 9%였습니다.
챗봇은 이미 보편적이지만 에이전트는 좁은 입구입니다
Anthropic은 설문에서 AI 사용을 두 단계로 나눴습니다. 첫 질문은 "연구 과정에서 생성 AI 모델을 써본 적이 있는가"였습니다. 여기서 81%가 그렇다고 답했습니다. 두 번째 질문은 "Codex, Cursor, Claude Code 같은 명령줄 통합 AI 코딩 어시스턴트를 주 1회 이상 정기적으로 쓰는가"였습니다. 이어서 해당 도구나 Google Antigravity를 실제로 쓰는지 확인했습니다. 이 기준을 통과한 응답자는 20%였습니다.
이 구분은 개발자 조직에서도 중요합니다. ChatGPT나 Claude에게 코드 한 조각을 묻는 행위와, 에이전트에게 데이터셋을 주고 분석 코드를 쓰게 하며 실행 결과까지 반복시키는 행위는 다른 운영 단위입니다. 전자는 문장과 코드 조각의 보조입니다. 후자는 로컬 환경, 패키지, 파일, 권한, 결과 해석을 포함합니다. 사회과학 연구에서는 이 차이가 곧 연구 설계, 회귀분석, 시각화, 재현성, 논문 초안으로 이어집니다.
Anthropic은 본문에서 에이전트형 코딩 플랫폼이 연구 아이디어와 데이터셋을 받아 분석 코드를 쓰고, 실행하고, 결과를 해석하며, 자율적으로 반복할 수 있다고 설명합니다. 이 정의는 과장된 미래 시나리오가 아닙니다. 정량 연구자의 일상 업무에는 데이터 정리, 변수 생성, 모형 추정, robustness check, 표 생성, 그래프 생성이 이미 코드로 묶여 있습니다. 코딩 에이전트가 들어갈 수 있는 면적이 넓습니다.
1,260명 표본은 AI 친화적일 수 있습니다
설문 표본을 읽을 때 첫 번째 caveat는 모집 방식입니다. 부록에 따르면 연구진은 R1 및 주요 캐나다 연구대학의 학과 웹사이트, OpenAlex, 학회 프로그램, 대학원 담당자, 학회 메일링 리스트 등을 통해 연구자를 찾았습니다. 직접 이메일을 보낸 대상은 44,700명이었습니다. 응답자는 정량·실증 데이터를 다루는 미국·캐나다 기반 사회과학자로 제한됐고, 박사과정생은 최소 2년 이상 수련을 마치고 학계 진입을 계획한 경우로 좁혔습니다.
두 번째 caveat는 설문이 Claude Max 계정 접근권을 제공하는 무작위 실험의 모집과 연결됐다는 점입니다. Anthropic은 이 때문에 응답자가 일반 사회과학자보다 AI 도구에 더 관심이 많고 더 낙관적일 수 있다고 적었습니다. 그래서 20%라는 채택률은 "사회과학 전체에서 이미 5명 중 1명이 코딩 에이전트를 쓴다"는 보수적 하한이 아닙니다. AI 실험 참여에 관심을 보인 표본에서도 정기 사용자가 20%에 그쳤다는 사실로 읽는 편이 안전합니다.
세 번째 caveat는 질문이 CLI 기반 도구에 맞춰졌다는 점입니다. 부록의 각주에 따르면 설문은 Claude Cowork 출시 한 달 뒤, OpenAI Codex 앱 출시 전 시점에 진행됐습니다. 그래서 일반 데스크톱 앱에서만 에이전트를 쓰는 연구자는 이 지표에 잡히지 않았을 수 있습니다. 반대로 "주 1회 이상"이라는 기준은 단순 체험자를 걸러냅니다. 이 설문은 넓은 AI 호기심보다 실제 연구 워크플로에 들어간 코딩 에이전트를 보려는 설계입니다.
분야와 경력의 차이는 도구 능력보다 업무 구조를 말합니다
분야별 차이는 큽니다. Anthropic 도표의 코딩 에이전트 사용률은 경제학 38-39%, 정치학 25%, 경영과학 18%, 심리학 12%, 사회학 11%, 공중보건 6%, 커뮤니케이션 6%, 교육 4%입니다. 경제학과 정치학은 정량 데이터 분석, working paper 문화, 코드 기반 replication, preprint 순환이 강한 분야입니다. 교육과 공중보건도 정량 연구가 많지만, 표본 수가 각각 45명과 84명으로 작고 기관·윤리·데이터 접근 제약이 더 클 수 있습니다.
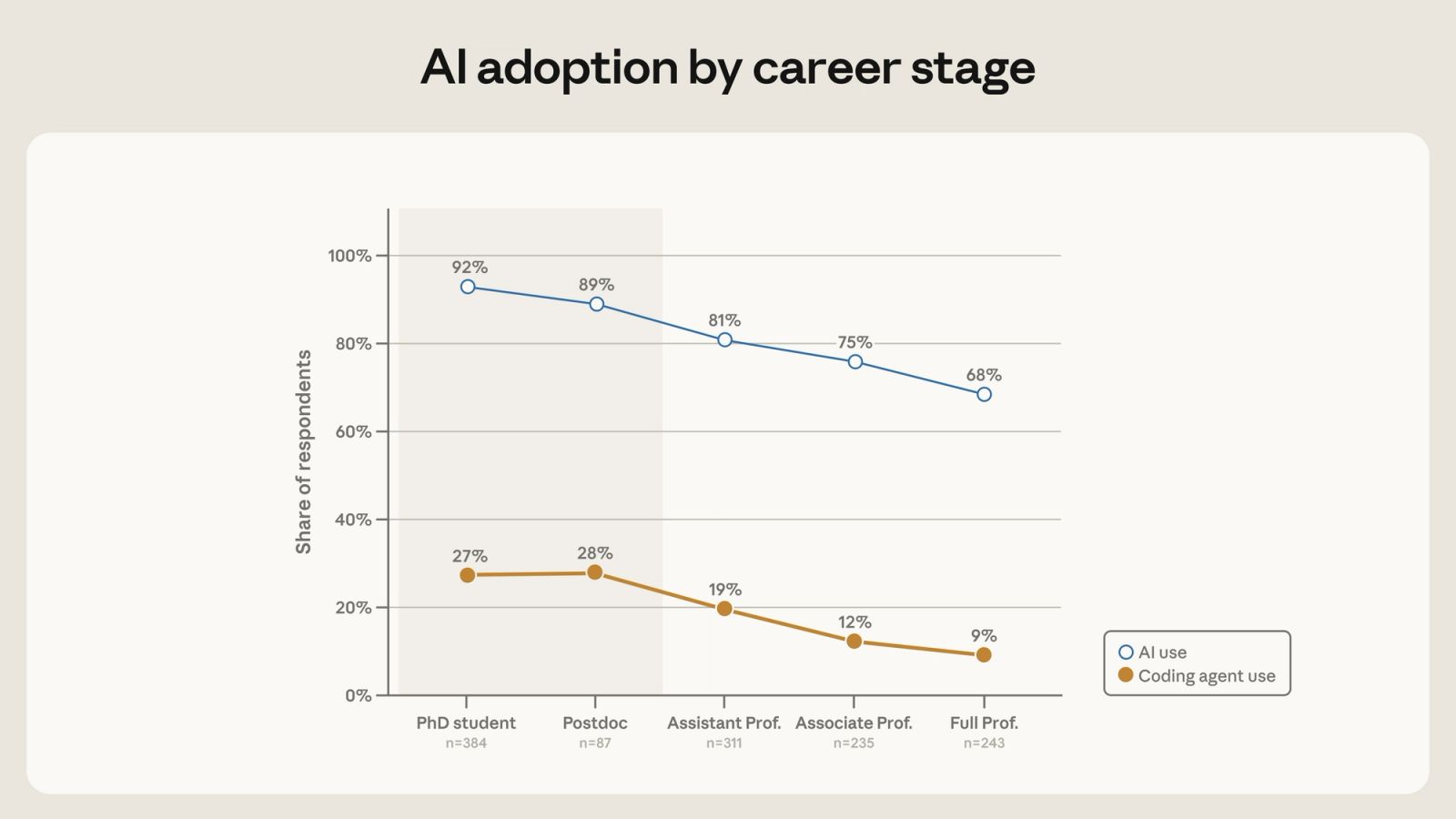
경력 단계별 차이는 에이전트의 확산 경로를 더 직접적으로 드러냅니다. 박사과정 27%, 포스트닥 28%는 assistant professor 19%, associate professor 12%, full professor 9%보다 높습니다. Anthropic은 초기 채택자가 더 기술 친화적이고, 코드와 데이터에 직접 닿아 있으며, 더 강한 연구 산출 압박을 받는 junior 연구자라고 해석합니다. 이 해석은 개발팀의 AI 도입에서도 익숙합니다. 새 도구는 보통 권한이 큰 관리자보다 실제 작업 파일을 매일 만지는 사람에게 먼저 붙습니다.
여기서 코딩 에이전트는 단순한 productivity app이 아닙니다. 박사과정 연구자가 replication package를 정리하거나, 포스트닥이 grant proposal용 preliminary analysis를 만들거나, assistant professor가 여러 프로젝트의 robustness check를 돌리는 방식에 개입합니다. 도구를 잘 쓰는 사람은 더 많은 프로젝트를 동시에 시작할 수 있고, 그렇지 않은 사람은 같은 기간 더 느린 루프에 남을 수 있습니다. 초기 채택 격차가 누적되면 연구 주제 선택과 협업 기회에도 영향을 줄 수 있습니다.
남성 이름 22%, 여성 이름 9%라는 불편한 숫자
Anthropic은 응답자의 self-reported first name을 gender_guesser Python 라이브러리로 분류해 일반적으로 남성 이름과 여성 이름 범주를 만들었습니다. unknown과 androgynous 이름은 분석에서 제외했습니다. 이 방법은 성별 정체성을 직접 측정하지 못합니다. 다국적 이름과 문화권별 오류도 남습니다. 그래서 기사에서 이 숫자를 "남성 연구자와 여성 연구자의 실제 비율"로 단정하면 안 됩니다.
그 한계를 감안해도 격차는 큽니다. 일반적으로 남성 이름으로 분류된 응답자의 코딩 에이전트 사용률은 22%, 여성 이름으로 분류된 응답자는 9%였습니다. 전체 AI 사용률은 각각 81%와 78%로 차이가 작았습니다. 즉 격차는 "AI를 한 번 써봤는가"보다 "CLI 통합 코딩 에이전트를 연구 워크플로에 넣었는가"에서 커졌습니다. Anthropic은 같은 분야와 경력 단계 안에서 비교해도 차이가 남는다고 적었습니다.
기관 격차도 같은 방향입니다. Nature Index 2025 Leading Institutions 기준 Top 25 기관 응답자는 코딩 에이전트 사용률 24%, 그 밖의 기관은 17%였습니다. 사립대는 23%, 공립대는 17%였습니다. AI 챗봇 사용률 차이보다 코딩 에이전트 사용률 차이가 더 컸습니다. 코딩 에이전트가 연구 생산성을 조금이라도 높인다면, 초기 접근성과 훈련 격차는 연구 산출의 기존 불평등을 줄이기보다 키울 수 있습니다.

자료: Anthropic.
연구자는 AI를 글쓰기보다 코드에 더 많이 씁니다
학계의 AI 논쟁은 흔히 논문 문장, hallucinated literature review, peer review overload, AI slop에 집중합니다. Anthropic 설문에서는 조금 다른 사용 패턴이 나왔습니다. 코딩 에이전트 사용자의 97%, 그 밖의 AI 사용자의 77%가 정량 데이터 분석 코드 생성을 용도로 보고했습니다. 다음으로 많이 나온 용도는 prose editing, methods advice, prior research background였습니다. 전체 AI 사용자 중 prose draft를 써본 비율은 약 3분의 1이었습니다.
이 결과는 사회과학 AI 도입을 "논문을 대신 써주는 도구"로만 보면 놓치는 부분을 드러냅니다. 많은 연구자에게 병목은 빈 문서가 아니라 분석 코드입니다. 데이터셋을 불러오고, 결측치를 처리하고, 회귀식과 고정효과를 바꾸고, 표를 다시 만들고, 부록 그래프를 갱신하는 작업이 반복됩니다. 코딩 에이전트는 이 반복을 한 번의 프롬프트로 끝내지는 못해도, 실패 로그를 읽고 파일을 고치며 다음 실행까지 밀어붙일 수 있습니다.
개발자 독자에게는 이 대목이 더 직접적입니다. AI 코딩 에이전트의 다음 고객은 소프트웨어 엔지니어만이 아닙니다. 데이터 분석을 코드로 처리하는 연구자, 금융 애널리스트, 정책 분석가, 운영팀, 마케팅 과학자도 같은 도구를 씁니다. 이 시장에서 "코딩"은 앱을 배포하는 행위가 아니라 작업 지식을 실행 가능한 스크립트와 notebook으로 바꾸는 행위입니다. 에이전트 제품이 CLI, 파일 시스템, 패키지 관리자, 로컬 데이터 권한을 어떻게 다루는지가 중요해지는 이유입니다.
생산성 신호는 있지만 인과는 아직 없습니다
Anthropic은 코딩 에이전트 사용자가 같은 분야와 경력 단계의 다른 연구자보다 프로젝트를 더 많이 시작하고, working paper를 더 많이 올리고, grant proposal을 더 많이 제출한다고 보고했습니다. 본문은 코딩 에이전트 사용자가 empirical project starts에서 약 10%, working paper posted에서 약 75% 더 생산적인 것처럼 보인다고 설명합니다. 조정 모델은 경력 단계, 분야, 설문 완료 주차를 통제했습니다.
이 문장은 곧바로 "코딩 에이전트가 생산성을 75% 높였다"로 번역하면 안 됩니다. Anthropic은 비교가 순수하게 descriptive라고 못 박았습니다. 코딩 에이전트 사용자는 원래 더 생산적이거나, 더 실험적인 연구자이거나, 더 많은 프로젝트를 시작할 수 있는 팀과 데이터 접근권을 가졌을 수 있습니다. 설문이 baseline wave라는 점도 중요합니다. Claude Code 접근권을 제공하는 무작위 실험의 결과는 아직 나오지 않았습니다.
더 건조한 결과도 있습니다. journal submission과 journal resubmission에서는 증가 증거가 없었습니다. Anthropic은 코딩 에이전트가 프로젝트를 시작하고 working paper까지 끌어올리는 데 더 유용할 수 있지만, 저널 투고 직전의 마지막 품질 정리에는 아직 효과가 덜 보일 수 있다고 해석했습니다. 다른 설명도 가능합니다. 코딩 에이전트 사용이 최근 현상이라 투고까지 시간이 부족했을 수 있고, 초기 adopter의 working paper 증가가 논문 품질 증가로 이어지지 않을 수도 있습니다.
연구 자동화가 늘리기 쉬운 것은 양이고, 어려운 것은 품질입니다
이번 조사에서 빠진 가장 큰 변수는 품질입니다. 부록은 output이 self-reported라고 적고, 본문도 프로젝트 수와 논문 수만 봤다고 밝힙니다. working paper가 늘어도 식별 전략이 강해졌는지, 데이터 정리가 재현 가능한지, p-hacking 위험이 줄었는지, 표와 그래프가 더 정확해졌는지는 따로 봐야 합니다. Anthropic도 추후 연구에서 coding agent augmented work의 내용과 품질을 평가하겠다고 했습니다.
사회과학의 위험은 소프트웨어 개발의 위험과 닮았습니다. 코딩 에이전트가 빠르게 코드를 만들면 첫 실행까지의 시간은 줄어듭니다. 그러나 분석 코드가 통계적 가정을 잘못 구현하거나, 표본 제한을 누락하거나, clustering을 잘못 지정하거나, robustness check를 형식적으로만 늘리면 생산성은 착시가 됩니다. 소프트웨어에서 테스트 없는 대량 PR이 리뷰 병목을 만들듯, 연구에서는 검증 없는 대량 working paper가 peer review와 replication 병목을 만들 수 있습니다.
Anthropic 본문은 이 점을 직접 언급합니다. 더 많은 논문은 attention 경쟁과 학술 기록의 혼잡을 키울 수 있고, 선택적 보고와 위험 회피적 incremental research 같은 기존 문제를 악화시킬 수 있습니다. 이 문장은 AI 안전 담론보다 연구 운영의 문제에 가깝습니다. 에이전트는 분석을 빨리 실행할 수 있지만, 무엇을 비교해야 하는지, 어떤 결과를 보고해야 하는지, 어떤 null result를 남겨야 하는지까지 자동으로 보장하지 않습니다.
개발팀에는 연구실이 좋은 예고편입니다
사회과학 연구실은 코딩 에이전트의 비개발자 시장을 미리 보여주는 작은 실험장입니다. 사용자는 전문 소프트웨어 엔지니어가 아니지만, 데이터와 코드에 의존합니다. 결과물은 제품 배포가 아니라 논문, grant proposal, conference submission입니다. 실패 비용은 다릅니다. 버그가 고객 장애로 터지지는 않지만, 잘못된 분석은 연구 결론과 정책 논의에 남을 수 있습니다.
이 환경에서 필요한 에이전트 기능은 개발팀에도 그대로 돌아옵니다. 첫째, 분석 코드의 provenance가 필요합니다. 어떤 데이터 파일을 읽었고, 어떤 전처리 단계를 거쳤고, 어떤 모형을 실행했는지 기록해야 합니다. 둘째, 실행 결과와 설명을 분리해야 합니다. 에이전트가 p-value를 해석하는 문장과 실제 출력값은 다른 검증 대상을 갖습니다. 셋째, 리뷰 가능한 단위로 변경을 나눠야 합니다. 데이터 cleaning, model specification, plotting, manuscript editing이 한 덩어리로 섞이면 동료가 검토하기 어렵습니다.
넷째, 접근권과 재현성을 함께 다뤄야 합니다. 연구 데이터에는 개인정보, 라이선스, IRB, 기관 서버 제한이 붙습니다. 개발팀의 고객 데이터와 같은 문제입니다. 에이전트가 로컬 파일을 읽고 실행할 수 있게 할수록 편해지지만, 누가 어떤 데이터에 접근했고 어떤 결과물을 만들었는지 감사할 수 있어야 합니다. 코딩 에이전트의 enterprise 기능이 단순한 좌석 관리가 아니라 로그, 권한, sandbox, 정책으로 확장되는 이유입니다.
낙관은 논문 생산성에 몰리고, 분야 전체 평가는 낮습니다
Anthropic은 응답자에게 두 가지 기대를 물었습니다. 하나는 AI가 publishable paper 작성 생산성을 높이는가입니다. 다른 하나는 AI가 사회과학 전체를 더 좋게 만드는가입니다. 1-10 척도에서 응답자의 88%는 논문 생산성 질문에 5보다 높은 점수를 줬고, 절반은 8 이상을 줬습니다. AI use case가 많을수록, 코딩 에이전트 사용자일수록 더 낙관적이었습니다.
하지만 같은 응답자들은 사회과학 전체 영향에 더 조심스러웠습니다. Anthropic은 응답자의 70%가 논문 생산성보다 분야 전체 영향에 덜 낙관적이었다고 적었습니다. 이 차이는 에이전트 도입 논쟁에서 자주 빠지는 부분입니다. 개인 연구자의 생산성은 올라갈 수 있습니다. 동시에 전체 시스템은 더 많은 초안, 더 많은 submission, 더 많은 replication 부담, 더 많은 방법론 편차를 처리해야 합니다.
소프트웨어 팀도 같은 구조를 겪습니다. 한 개발자가 에이전트로 PR을 더 빨리 만들 수 있습니다. 그러나 팀 전체의 리뷰 대기열, 테스트 시간, 릴리스 위험, 보안 검토가 늘면 조직 생산성은 개인 생산성과 다르게 움직입니다. 사회과학자의 응답에는 이 차이가 숫자로 남았습니다. 도구 사용자는 자신이 논문을 더 빨리 쓸 수 있다고 믿지만, 그 결과가 분야 전체를 더 좋게 만든다고 같은 강도로 믿지는 않습니다.
이번 뉴스의 실제 의미
이번 발표는 "AI가 사회과학자를 대체한다"는 결론을 주지 않습니다. 더 정확한 결론은 코딩 에이전트가 연구 워크플로의 코드 구간에 먼저 들어가고 있으며, 초기 채택은 분야, 경력, 이름 기반 성별 분류, 기관 지위에 따라 크게 갈린다는 것입니다. 연구 산출물의 초기 단계에서는 생산성 신호가 있지만, 인과와 품질 평가는 남았습니다.
AI 제품을 만드는 팀에게는 세 가지 질문이 남습니다. 첫째, 비개발자 지식 노동자가 코드 실행을 에이전트에게 맡길 때 어떤 guardrail이 필요한가입니다. 둘째, 에이전트 사용이 기존 격차를 줄이는가, 아니면 CLI와 데이터 권한을 다룰 수 있는 사람에게 더 큰 이익을 주는가입니다. 셋째, 산출물 수가 늘 때 검증 시스템이 함께 늘어나는가입니다.
Anthropic의 다음 실험 결과가 중요한 이유도 여기에 있습니다. baseline 설문은 기존 사용자를 식별합니다. 무작위로 Claude Code 접근권을 제공한 뒤의 결과는 도구가 실제로 생산성, 품질, 연구 선택을 바꾸는지 더 깨끗하게 볼 수 있습니다. 지금 확인된 것은 충분히 구체적입니다. 챗봇 사용은 사회과학 연구에서 이미 넓게 퍼졌고, 코딩 에이전트는 아직 좁지만 강한 사용자층을 만들고 있습니다. 그 좁은 입구를 통과한 사람이 더 많은 working paper와 grant proposal을 만든다는 신호가 나왔고, 그 신호가 연구 품질로 이어지는지는 아직 증명되지 않았습니다.
개발자에게 이 뉴스는 연구실 바깥의 이야기로 끝나지 않습니다. 코딩 에이전트는 IDE 안의 도구에서 데이터 분석과 지식 생산의 실행 도구로 이동하고 있습니다. 이 이동은 더 많은 사용자를 만들지만, 더 많은 책임도 만듭니다. 앞으로 에이전트 제품을 평가할 때는 모델 성능만 볼 수 없습니다. 누가 접근할 수 있는지, 어떤 작업을 자동화하는지, 어떤 검증 로그를 남기는지, 산출물의 양과 품질을 어떻게 구분하는지를 함께 봐야 합니다.