34% 줄어든 재방문, 클린 코드가 만든 에이전트 비용 차이
SonarSource의 660회 Claude Code 실험은 클린 코드가 성공률보다 토큰 비용과 파일 재방문을 줄인다는 점을 보여줍니다.

- 무슨 일: SonarSource 연구진이
Claude Code를 660회 돌려 코드 청결성이 에이전트 행동을 바꾸는지 측정했습니다.- 여섯 개 최소 쌍 저장소와 33개 과제를 만들고, 코드베이스 구조만 다르게 둔 controlled study입니다.
- 핵심 수치: pass rate는 -0.9%p로 거의 같았지만, input token은 7.1%, file revisitation은 33.8% 줄었습니다.
- 의미: 클린 코드는 에이전트가 더 똑똑해지게 한다기보다, 같은 일을 더 적은 탐색과 토큰으로 끝내게 하는 비용 인프라입니다.
- 주의점: 실험은 Claude Sonnet 4.6 기반 Claude Code 한 구성에 한정되며, 토큰 절감이 곧바로 동일한 달러 절감은 아닙니다.
SonarSource 연구자 Priyansh Trivedi와 Olivier Schmitt가 2026년 5월 19일 arXiv에 흥미로운 논문을 올렸습니다. 제목은 Does Code Cleanliness Affect Coding Agents? A Controlled Minimal-Pair Study입니다. 질문은 단순합니다. 코드가 깨끗하면 코딩 에이전트가 일을 더 잘할까요?
논문의 답은 예상보다 미묘합니다. 깨끗한 코드가 Claude Code의 과제 성공률을 유의미하게 끌어올리지는 않았습니다. 깨끗한 쪽 pass rate는 0.913, 지저분한 쪽은 0.921이었습니다. 차이는 -0.9 percentage point입니다. 이 숫자만 보면 "AI가 코드를 읽는 시대에는 클린 코드가 덜 중요해졌다"는 결론을 내리고 싶을 수도 있습니다.
하지만 이 논문의 진짜 뉴스는 성공률이 아니라 비용입니다. 연구진은 같은 과제를 같은 에이전트로 풀게 하면서, 에이전트가 읽은 input token, 만든 output token, reasoning characters, conversation length, 읽은 파일 수, 이미 읽고 수정한 파일을 다시 여는 횟수까지 추적했습니다. 그 결과 깨끗한 코드에서 input token은 7.1%, output token은 8.5%, reasoning characters는 11.1%, conversation messages는 7.0% 줄었습니다. 가장 큰 차이는 file revisitation입니다. 에이전트가 이미 수정한 파일을 다시 열어 확인하는 횟수가 33.8% 줄었습니다.
이 결과는 클린 코드 논쟁의 초점을 바꿉니다. 에이전트가 코드를 대신 읽고 고치더라도, 코드 구조는 사라지지 않습니다. 다만 그 구조를 읽는 주체가 사람만이 아니라 모델과 harness로 넓어집니다. 함수 이름, 제어 흐름, 모듈 경계, dead code, 중복 로직은 이제 사람의 인지 부하뿐 아니라 에이전트의 컨텍스트 비용과 재탐색 루프에도 영향을 줍니다.
왜 이 실험이 까다로운가
코드 청결성이 에이전트에게 영향을 주는지 보려면 단순히 "깨끗한 저장소"와 "지저분한 저장소"를 비교하면 안 됩니다. 저장소가 다르면 도메인, 언어, 테스트, 의존성, 프레임워크, 과제 난이도도 같이 달라집니다. pass rate나 토큰 사용량이 바뀌어도 그것이 코드 청결성 때문인지, 과제 자체가 어려워서인지 알 수 없습니다.
그래서 논문은 최소 쌍(minimal pair)을 만들었습니다. 같은 아키텍처, 같은 의존성, 같은 테스트, 같은 외부 동작을 유지하되, 내부 코드의 청결도만 다르게 만든 저장소 쌍입니다. 청결도는 SonarQube rule violation과 cognitive complexity를 proxy로 삼았습니다. 완전한 철학적 정의의 클린 코드가 아니라, 정적 분석기가 잡을 수 있는 유지보수성 신호를 실험 변수로 삼은 것입니다.
연구진은 두 방향의 파이프라인을 사용했습니다. 하나는 깨끗한 저장소를 지저분하게 만드는 Slopify입니다. 이 파이프라인은 helper를 caller 안으로 밀어 넣고, 로직을 중복하고, dead code를 넣고, 때로는 모듈을 큰 파일로 합치며, 테스트가 깨지면 해당 pass를 버립니다. 목표는 일부러 망가뜨린 장난감 코드가 아니라, 리뷰와 linting 없이 자란 듯한 plausible messy code입니다.
반대 방향은 지저분한 저장소를 정리하는 Vibeclean입니다. 이 파이프라인은 SonarQube issue 목록을 따라 모듈별로 정리하고, 테스트를 다시 돌려 외부 동작을 유지합니다. 문자열 중복 제거, 주석 처리된 코드 삭제, legacy collection idiom 교체, dead branch 제거 같은 기계적 정리도 있고, 200줄 넘는 dispatch switch를 helper로 쪼개거나 2,800줄 class에서 persistence helper를 분리하는 구조적 변경도 있습니다.
같은 외부 동작의 저장소
같은 과제, 같은 Claude Code, 다른 코드 청결성
실험 대상은 여섯 개 저장소 쌍입니다. 세 쌍은 SonarSource의 비공개 코드베이스이고, 세 쌍은 공개 저장소인 Apache commons-bcel, Netflix genie, ckan입니다. 비공개 저장소를 섞은 이유도 중요합니다. 공개 저장소는 모델이 학습 과정에서 봤을 가능성이 있지만, 비공개 저장소는 그렇지 않습니다. 에이전트가 기억으로 푸는지, 실제로 탐색하는지에 대한 confound를 줄이려는 장치입니다.
성공률보다 footprint
이 논문이 흥미로운 이유는 pass rate만 보지 않는다는 데 있습니다. 지금까지 코딩 에이전트 평가는 대체로 "테스트를 통과했는가"에 몰려 있었습니다. SWE-bench류 벤치마크가 그 대표입니다. 물론 pass rate는 중요합니다. 하지만 실제 개발팀이 에이전트를 운영할 때는 성공 여부만큼 비용과 반복도 중요합니다.
코딩 에이전트는 한 번 답하고 끝나는 챗봇이 아닙니다. 파일을 찾고, 읽고, grep하고, 수정하고, 테스트하고, 실패하면 로그를 읽고, 다시 수정합니다. 이전 대화와 파일 내용이 다음 호출의 input으로 들어갑니다. 도구 호출도 모델 output입니다. 같은 과제를 성공하더라도 어떤 에이전트는 한 번에 방향을 잡고, 어떤 에이전트는 같은 파일을 여러 번 열어 확인합니다. 이 차이는 사용자에게는 느린 응답, 공급자에게는 토큰 비용, 팀에게는 예측 불가능한 자동화 비용으로 나타납니다.
논문은 33개 과제를 각 저장소 쌍의 양쪽에서 10회씩 실행했습니다. 총 660 trials입니다. 모든 숫자는 Claude Sonnet 4.6을 쓰는 Claude Code에서 나왔습니다. 연구진은 Haiku 4.5도 시도했지만 pass rate가 낮아 footprint 차이를 안정적으로 읽기 어렵다고 보고, 핵심 결과에서는 제외했습니다.
결과는 이렇게 요약할 수 있습니다.
pass rate가 거의 같다는 점은 오히려 결과를 더 선명하게 만듭니다. 깨끗한 코드는 이 실험에서 "정답을 더 많이 맞히게 하는 변수"가 아니었습니다. 대신 같은 정답에 도달하는 경로를 바꿨습니다. 에이전트는 더 적은 input을 읽고, 더 적은 output을 만들고, reasoning text도 줄이고, 무엇보다 이미 고친 파일로 되돌아가는 횟수를 크게 줄였습니다.
논문은 file revisitation을 에이전트의 불확실성 신호로 읽습니다. 전형적인 패턴은 read → edit → 다른 작업 → read again입니다. 사람이 코드를 고칠 때도 비슷합니다. 구조가 불분명하면 방금 바꾼 곳이 맞는지 다시 확인합니다. 이름이 명확하고 제어 흐름이 작고 모듈 경계가 읽히면, 처음 탐색에서 더 빨리 mental model을 만들고 다음 단계로 넘어갑니다. 모델도 크게 다르지 않았다는 뜻입니다.
multi-module 과제에서 더 커진 차이
전체 평균만 보면 input token 7.1% 감소가 아주 크지는 않아 보입니다. 하지만 과제 유형별로 보면 더 흥미로운 패턴이 나옵니다. 논문은 과제를 cognitive-hotspot, multi-module, calibration 세 트랙으로 나눕니다.
cognitive-hotspot 과제는 복잡한 단일 method나 class 주변을 고치는 과제입니다. multi-module 과제는 두 개 이상의 module boundary를 건너야 합니다. calibration 과제는 청결도 차이를 직접 건드리지 않는 중립 대조군에 가깝습니다.
multi-module 과제에서 깨끗한 코드는 훨씬 강한 비용 차이를 만들었습니다. input token은 10.7% 줄고, file revisitation은 50.8% 줄었습니다. 읽은 파일 수는 거의 같았습니다. 즉 에이전트가 덜 탐색한 것이 아니라, 비슷한 범위를 읽고도 이미 수정한 파일로 덜 되돌아갔습니다. 모듈 경계와 이름, 구조가 명확하면 여러 파일을 오가는 작업에서 "여기가 맞나"를 반복 확인하는 비용이 줄어든다는 해석이 가능합니다.
반대로 cognitive-hotspot 과제에서는 input token이 1.8% 늘고 files read가 11.2% 늘었습니다. 처음 보면 이상합니다. 깨끗한 코드인데 왜 더 읽을까요? 논문은 정리 파이프라인의 성격에서 이유를 찾습니다. 큰 god method나 깊은 control flow를 helper로 나누면, 복잡도는 한 곳에서 여러 곳으로 분산됩니다. 사람에게는 작은 이름 붙은 helper가 읽기 좋지만, 에이전트 입장에서는 관련 파일과 함수를 더 많이 열어야 할 수 있습니다. 깨끗한 코드가 항상 단일 지표를 줄이는 것은 아닙니다.
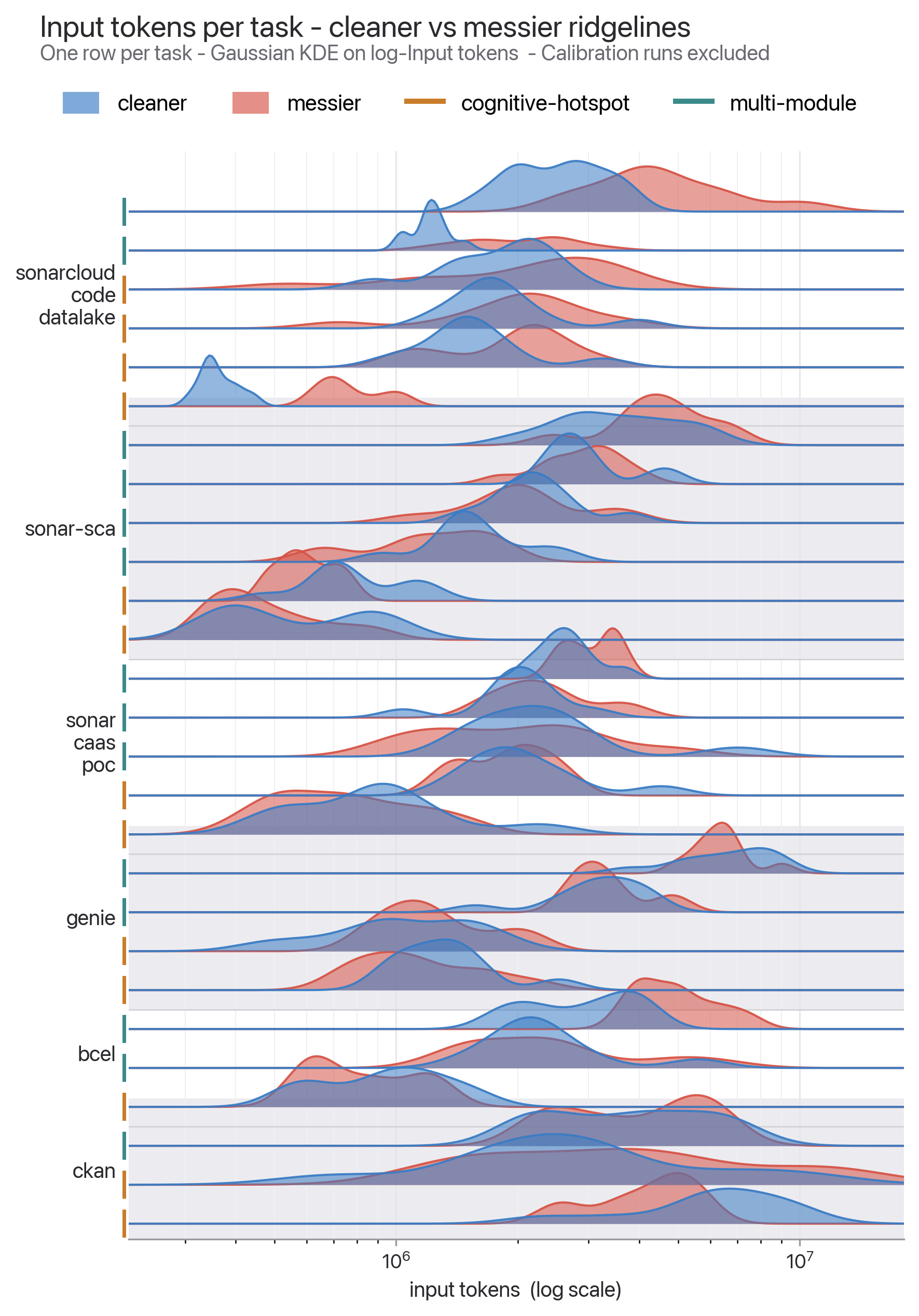
이 그림도 같은 점을 보여줍니다. 논문 Figure 2는 calibration을 제외한 27개 과제의 input token 분포를 task별로 나눠 보여줍니다. 한 줄 안의 분산은 같은 과제를 같은 조건에서 10회 반복했을 때의 run-to-run variance이고, 줄 사이의 차이는 task-to-task variance입니다. 연구진은 한 task와 한 side 안에서도 가장 비싼 trial이 가장 싼 trial의 2.5배 정도인 경우가 흔하고, group의 약 72%에서 2배 이상 차이가 난다고 설명합니다.
이 점은 실무적으로 중요합니다. "이번 작업에서 토큰이 10% 줄었다"는 단일 사례는 노이즈일 수 있습니다. 반대로 660회 실험을 묶어 봤을 때 일관되게 줄어드는 지표는 운영 지표로 볼 가치가 있습니다. 코딩 에이전트 비용은 모델 가격표만으로 계산되지 않습니다. 같은 모델과 같은 과제에서도 코드 구조, harness, 도구 호출, 캐시 상태, 재시도 패턴이 비용을 흔듭니다.
클린 코드는 사람을 위한 미학이 아니다
AI 코딩 도구가 빠르게 좋아지면서 가끔 이런 주장이 나옵니다. "어차피 사람이 코드를 덜 읽게 되면 클린 코드의 가치는 줄어드는 것 아닌가?" 이 논문은 그 주장에 작지만 중요한 반례를 제공합니다. 사람이 덜 읽더라도, 누군가는 읽습니다. 그 누군가가 모델이라면 읽는 비용은 토큰과 지연 시간, 재시도, 툴 호출로 나타납니다.
물론 이 결과를 "클린 코드를 쓰면 에이전트 성능이 오른다"로 단순화하면 안 됩니다. 이 실험에서 성공률은 거의 같았습니다. 더 정확한 표현은 이렇습니다. 클린 코드는 코딩 에이전트의 capability lever라기보다 cost lever입니다. 더 많은 문제를 풀게 하기보다, 이미 풀 수 있는 문제를 더 덜 헤매며 풀게 합니다.
개발팀 입장에서는 이 차이가 작지 않습니다. 개인이 가끔 Claude Code나 Codex에 작업을 맡길 때 7% token 차이는 체감이 약할 수 있습니다. 하지만 PR 리뷰, 테스트 수정, migration, 문서 업데이트, 릴리스 노트, 보안 패치 재현 같은 작업이 CI와 백그라운드 에이전트로 들어가면 이야기가 달라집니다. 같은 코드베이스에서 수백, 수천 번 반복되는 에이전트 작업은 작은 footprint 차이를 누적합니다.
특히 file revisitation 33.8% 감소는 단순 비용 이상의 신호입니다. 에이전트가 같은 파일로 계속 돌아간다는 것은 불확실성이 남아 있다는 뜻일 수 있습니다. 불확실한 에이전트는 오래 걸릴 뿐 아니라, 이전 수정과 이후 수정이 충돌하거나, 테스트 실패 후 원인을 잘못 추적하거나, 불필요한 변경을 덧붙일 가능성이 커집니다. 논문은 이 부분을 직접 품질 결함으로 연결하지는 않지만, 운영팀이 관찰해야 할 지표로 충분히 중요합니다.
코드 품질 도구의 역할도 바뀐다
SonarSource가 쓴 논문이라는 점도 맥락상 중요합니다. SonarQube rule violation을 청결도 proxy로 쓰는 연구는 당연히 도구 회사의 관점과 맞닿아 있습니다. 그래서 결과를 읽을 때는 두 가지를 동시에 봐야 합니다. 하나는 실험 설계가 충분히 통제되어 있다는 점입니다. 다른 하나는 "SonarQube issue가 곧 클린 코드 전체"는 아니라는 점입니다.
논문도 이를 인정합니다. clean code는 정확히 정의하기 어렵고, 이 연구는 정적 분석 rule violation과 cognitive complexity를 사용합니다. 어떤 좋은 코드 구조는 정적 분석기에 잘 잡히지 않습니다. 반대로 rule violation을 줄였다고 항상 더 읽기 좋은 설계가 되는 것도 아닙니다. 일부 hotspot task에서 깨끗한 쪽 files read가 늘어난 결과도 이 한계를 보여줍니다.
그럼에도 코드 품질 도구의 역할은 넓어집니다. 과거의 정적 분석은 사람 리뷰어의 부담을 줄이는 도구였습니다. 에이전트 시대에는 모델의 탐색 비용을 줄이는 사전 정리 도구가 될 수 있습니다. lint, type check, dead code 제거, 함수 추출, naming consistency, module boundary 정리는 더 이상 "사람이 보기 좋게"만 설명되지 않습니다. 에이전트가 grep하고 읽고 수정하는 표면을 더 예측 가능하게 만드는 작업입니다.
이 관점은 AI 코딩 도구 도입 전략에도 영향을 줍니다. 많은 팀이 먼저 "어떤 모델을 쓸 것인가"를 묻습니다. 그다음 "어떤 IDE나 CLI를 쓸 것인가"를 묻습니다. 하지만 장기적으로는 "우리 코드베이스는 에이전트가 싸게 탐색할 수 있는 구조인가"도 물어야 합니다. 모델 라우팅과 prompt caching만으로는 해결되지 않는 비용이 코드 안에 있을 수 있기 때문입니다.
한계는 분명하다
이 논문을 과장하지 않으려면 한계를 분명히 해야 합니다. 첫째, 모든 숫자는 Claude Sonnet 4.6을 쓰는 Claude Code 한 구성에서 나왔습니다. OpenAI Codex, GitHub Copilot coding agent, Cursor, Gemini CLI, 다른 harness에서도 같은 수치가 나올지는 아직 모릅니다. 논문은 "같은 mechanism이 옮겨갈 가능성은 있지만, 이 paper 안에서는 conjecture"라고 선을 긋습니다.
둘째, 토큰은 비용 proxy일 뿐입니다. 실제 달러 비용은 provider 가격, 캐시 hit rate, cached token 과금, queue delay, plan quota, priority processing 여부에 따라 달라집니다. input token이 7.1% 줄었다고 청구서가 정확히 7.1% 줄어드는 것은 아닙니다. 다만 token footprint가 줄면 비용과 지연을 함께 낮출 여지가 생깁니다.
셋째, pass rate는 논문이 작성한 hidden tests 기준입니다. 에이전트가 기존 저장소의 다른 테스트를 깨뜨렸는지까지 검증하지는 않습니다. cleaner side와 messier side의 솔루션이 모두 hidden tests를 통과하더라도, 숨은 품질 차이가 있을 수 있습니다. 이는 현재 대부분의 코딩 에이전트 벤치마크가 안고 있는 공통 한계이기도 합니다.
넷째, 실험은 short-horizon입니다. 한 과제 단위에서 footprint가 줄어드는 것과, 1년 동안 에이전트가 계속 코드를 고치는 코드베이스에서 이 차이가 누적되는 것은 다른 질문입니다. 깨끗한 코드가 에이전트 작업을 더 싸게 만들고, 싸진 작업이 더 많은 정리를 가능하게 하는 선순환이 생길 수도 있습니다. 반대로 에이전트가 장기간 만든 코드가 점점 drift하면서 처음의 청결성을 잃을 수도 있습니다. 논문은 이 compounding question을 다음 연구 과제로 남깁니다.
개발팀이 가져갈 질문
이 논문을 읽고 "그래서 클린 코드를 더 열심히 쓰자"로 끝내면 아쉽습니다. 더 실용적인 질문은 이것입니다. 우리 팀의 코딩 에이전트는 어떤 코드 구조에서 토큰을 많이 쓰고, 어떤 파일을 반복해서 열며, 어떤 과제에서 재시도가 늘어나는가?
이미 Claude Code, Codex, Cursor, Copilot, Gemini CLI를 팀 workflow에 넣고 있다면 에이전트 실행 로그를 단순 성공/실패로만 보지 않는 편이 좋습니다. 작업당 input/output token, 읽은 파일 수, 같은 파일 재방문 횟수, 첫 edit까지 걸린 turn, test rerun 횟수, 최종 diff 크기를 같이 봐야 합니다. 이 지표가 특정 module에서 반복적으로 튀면, 문제는 모델이 아니라 코드 구조일 수 있습니다.
또 하나의 실무 포인트는 refactoring의 ROI입니다. 사람만 개발하던 시대에는 리팩터링 ROI를 리뷰 시간, 버그 감소, 온보딩 속도로 설명했습니다. 이제는 에이전트 실행 비용도 포함할 수 있습니다. 어떤 module을 정리했더니 에이전트가 같은 작업에서 덜 읽고 덜 되돌아간다면, 리팩터링은 품질 비용이 아니라 inference 비용 절감 프로젝트가 됩니다.
그렇다고 모든 코드를 무조건 더 잘게 쪼개야 한다는 뜻은 아닙니다. cognitive-hotspot 결과가 보여주듯, helper 추출은 에이전트가 읽어야 할 위치를 늘릴 수도 있습니다. 좋은 구조는 단순히 함수가 작다는 뜻이 아니라, 변경할 위치를 찾기 쉽고, 이름이 의미를 전달하며, 모듈 경계가 과제의 경계와 잘 맞는 상태에 가깝습니다.
결국 이 논문이 던지는 메시지는 꽤 현실적입니다. AI가 코드를 쓰는 시대에도 코드베이스는 여전히 작업 환경입니다. 사람이 읽기 좋은 작업장은 에이전트에게도 덜 비싼 작업장이 될 가능성이 큽니다. 다만 그 가치는 "성공률이 오른다"보다 "덜 헤맨다"에 가깝습니다. 코딩 에이전트의 다음 병목이 모델 지능만이 아니라 운영 비용과 예측 가능성이라면, 클린 코드는 다시 인프라 문제로 돌아옵니다.