프런티어 AI 사전심사, 모델 출시의 새 관문이 됐다
CAISI가 Google DeepMind, Microsoft, xAI와 사전 평가 협력을 넓혔습니다. 모델 출시는 이제 벤치마크 경쟁을 넘어 정부 평가 체계 경쟁으로 이동합니다.

- 무슨 일: 미국 CAISI가 Google DeepMind, Microsoft, xAI와 프런티어 모델 사전 평가 협력을 넓혔습니다.
- Microsoft는 같은 날
CAISI와 영국AISI협약을 공식 발표하며 프런티어 모델 테스트와 안전장치 평가를 협력 범위로 명시했습니다.
- Microsoft는 같은 날
- 의미: 모델 출시는 공개 벤치마크 점수보다 비공개 평가, 사전 접근권, 국가안보 리스크 검토의 영향을 더 크게 받기 시작했습니다.
- 개발자 영향: API 모델 선택은 성능표만이 아니라 평가 출처, 안전장치 검증, 조달 가능성, 배포 지연 리스크까지 함께 봐야 합니다.
- 주의점: 현재 협력은 대체로 자발적 평가에 가깝고, 출시 차단권이나 평가 결과 공개 범위는 아직 명확하지 않습니다.
미국 정부의 프런티어 AI 평가 체계가 한 단계 더 구체적인 형태를 갖추기 시작했습니다. 2026년 5월 5일 Microsoft는 미국의 Center for AI Standards and Innovation, 즉 CAISI와 영국 AI Security Institute, AISI와 새 협약을 맺었다고 발표했습니다. 발표의 핵심은 Microsoft의 프런티어 모델을 대상으로 테스트를 수행하고, 안전장치를 평가하며, 국가안보와 대규모 공공 안전 위험을 줄이기 위한 협력 연구를 진행한다는 것입니다.
같은 흐름에서 NIST 산하 CAISI는 Google DeepMind, Microsoft, xAI와의 확장 협력을 통해 프런티어 모델의 사전 배포 평가와 표적 연구를 수행한다고 알려졌습니다. 이 문장은 규제 뉴스처럼 보이지만, 개발자와 AI 제품팀에게는 더 실무적인 신호입니다. 프런티어 모델의 신뢰는 이제 "몇 점을 받았는가"만으로 만들어지지 않습니다. 누가 어떤 환경에서, 어떤 비공개 테스트셋과 어떤 안전 가정으로 평가했는지가 점점 더 중요해지고 있습니다.
이 변화는 모델 제공사만의 문제가 아닙니다. 기업이 LLM API를 도입할 때, 보안팀과 법무팀은 더 이상 "SWE-Bench에서 몇 퍼센트인가", "MMLU에서 어느 모델을 이겼는가"만 묻지 않습니다. 이 모델이 어떤 외부 평가를 받았는지, 국가안보나 사이버 위험 평가에서 어떤 범주에 들어가는지, 조달이나 규제 대응 문서로 쓸 수 있는 근거가 있는지, 출시 후 문제가 생겼을 때 누가 어떤 기준으로 재평가하는지가 중요해집니다. CAISI 협약은 이 질문들이 프런티어 모델 시장의 공식 언어가 되어가고 있다는 신호입니다.
CAISI는 무엇을 평가하려 하나
CAISI는 NIST 산하 조직입니다. NIST의 CAISI 페이지는 이 센터가 상업용 AI 시스템의 테스트와 협력 연구를 조율하는 미국 정부의 접점 역할을 한다고 설명합니다. 역할은 꽤 넓습니다. NIST 내부 조직과 함께 AI 시스템 보안 측정과 개선을 위한 가이드라인을 만들고, 민간 AI 개발자 및 평가자와 자발적 협약을 맺고, 국가안보 위험을 낳을 수 있는 AI 역량의 비공개 평가를 이끕니다.
흥미로운 대목은 평가 대상이 추상적인 "AI 안전"에 머물지 않는다는 점입니다. CAISI는 사이버보안, 바이오보안, 화학무기와 같은 실증 가능한 위험을 명시합니다. 또한 미국과 경쟁국 AI 시스템의 역량, 외국 AI 시스템 채택, 국제 AI 경쟁 상태, 적대적 AI 시스템의 백도어와 악의적 영향 가능성까지 평가 범위에 넣습니다. 이것은 모델 성능표라기보다 전략 기술 평가 체계에 가깝습니다.
Microsoft의 발표도 같은 방향입니다. Microsoft는 CAISI와의 협력이 자사 내부 테스트를 대체한다고 말하지 않습니다. 오히려 내부 테스트만으로는 국가안보와 대규모 공공 안전 위험을 다루기 어렵다고 봅니다. 고위험 역량 평가에는 기술, 과학, 국가안보 전문성이 결합되어야 하고, 이런 전문성은 CAISI와 AISI 같은 기관 및 그들이 연결하는 정부 기관에 있다는 설명입니다.
개발자 입장에서 이 문장은 중요합니다. 프런티어 모델의 위험 평가는 모델 제공사의 보안 백서, 투명성 보고서, 레드팀 요약만으로 끝나지 않을 수 있습니다. 특히 정부, 금융, 의료, 국방, 중요 인프라 고객에게 모델을 공급하거나 그 위에 서비스를 구축하는 팀이라면 외부 평가 체계가 곧 영업과 조달의 일부가 됩니다. 모델이 좋다는 주장보다, 어떤 평가기관이 어떤 범주에서 검증했는지가 구매 문서의 언어가 됩니다.
| 항목 | 기존 출시 경쟁 | CAISI식 평가 경쟁 |
|---|---|---|
| 핵심 근거 | 공개 벤치마크, 데모, 개발사 자체 보고 | 사전 배포 접근, 비공개 평가, 정부 협력 연구 |
| 위험 범주 | 일반 안전성, 유해 출력, 제품 정책 위반 | 사이버, 바이오, 화학, 국가안보, 적대 모델 영향 |
| 개발자 질문 | 이 모델이 더 빠르고 저렴한가 | 이 모델을 어떤 규제·조달 환경에서 쓸 수 있는가 |
| 약점 | 벤치마크 오염과 체리피킹에 취약 | 평가 결과 공개 범위와 출시 구속력이 불명확 |
DeepSeek V4 Pro 평가는 예고편입니다
CAISI가 어떤 방식으로 모델을 보려 하는지는 2026년 5월 1일 공개된 DeepSeek V4 Pro 평가에서 더 잘 드러납니다. 이 평가는 이번 Microsoft 협약 발표보다 며칠 앞서 나왔지만, 두 뉴스를 함께 읽어야 합니다. 협약은 "누가 정부 평가에 모델을 제공하는가"를 보여주고, DeepSeek 평가는 "정부 평가가 무엇을 다르게 볼 수 있는가"를 보여줍니다.
CAISI는 DeepSeek V4 Pro를 중국 공개 모델 중 가장 강력한 모델로 평가했습니다. 동시에 공개된 차트에서는 이 모델이 미국 프런티어 모델보다 약 8개월 뒤처진다고 분석했습니다. 여기서 중요한 점은 단순히 어느 나라 모델이 앞섰느냐가 아닙니다. CAISI는 공개 벤치마크와 개발사 자체 보고가 주는 인상과, 비공개 또는 반비공개 평가가 주는 결론이 다를 수 있음을 보여줬습니다.
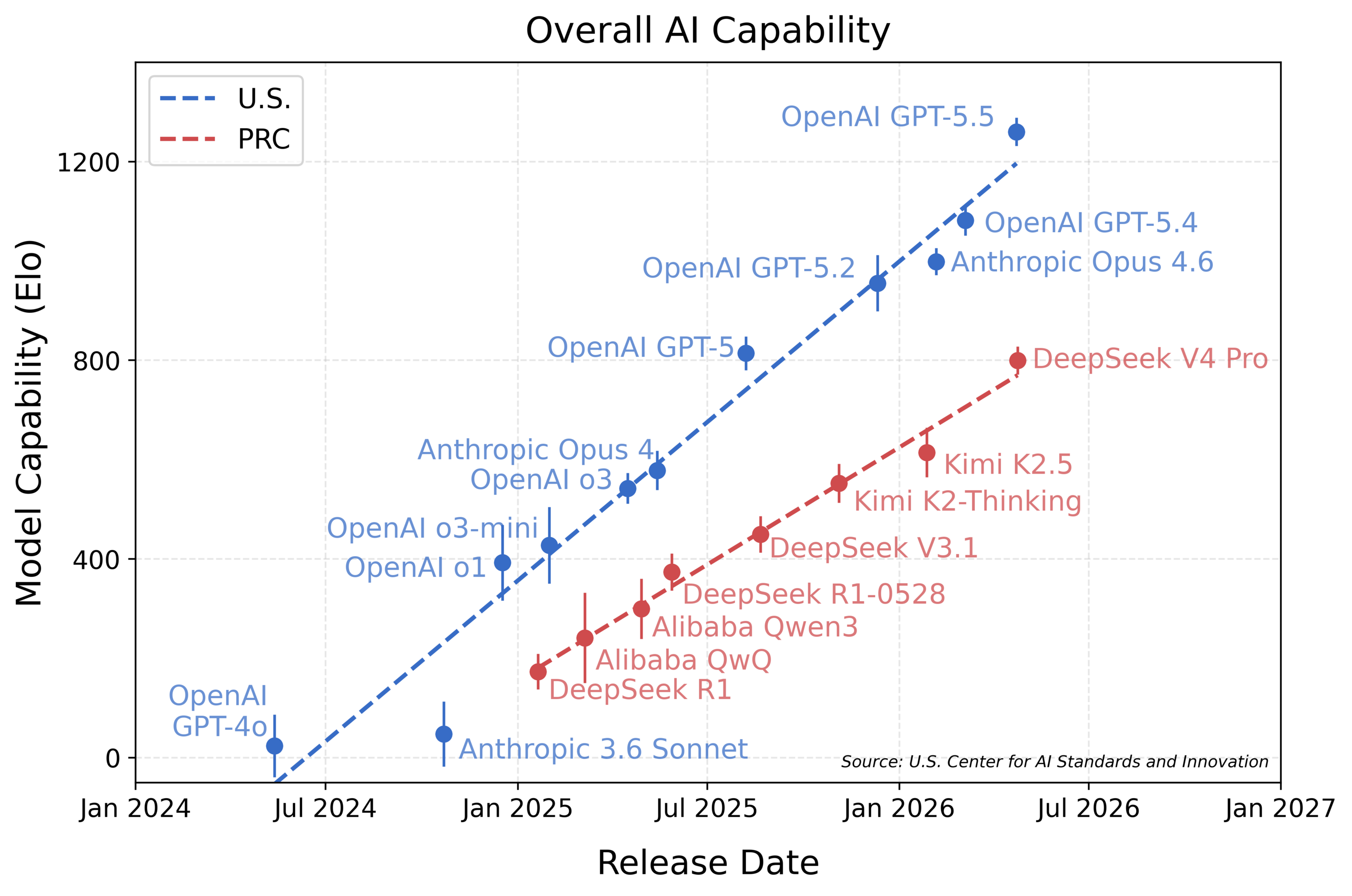
평가 도메인은 사이버, 소프트웨어 엔지니어링, 자연과학, 추상 추론, 수학입니다. 개발자에게 특히 눈에 띄는 것은 SWE-Bench Verified, PortBench, CTF-Archive-Diamond입니다. SWE-Bench Verified는 이미 코딩 모델 비교의 표준처럼 쓰이고 있지만, CAISI는 시스템 프롬프트, 스캐폴딩, 토큰 예산 차이 때문에 다른 평가자의 점수보다 낮게 나올 수 있다고 주석을 달았습니다. PortBench는 CAISI가 내부적으로 만든 비공개 소프트웨어 엔지니어링 평가입니다. CTF-Archive-Diamond는 어려운 CTF 문제를 기반으로 한 사이버 역량 평가입니다.
이 조합은 한 가지 메시지를 줍니다. 앞으로 프런티어 모델 평가는 "코딩을 잘한다"와 "위험한 사이버 행동도 잘한다"를 분리해서 보기 어렵습니다. 에이전트가 코드를 고치고, 파일을 읽고, 명령을 실행하고, 장시간 작업을 수행하는 시대에는 개발 생산성과 공격 역량이 같은 도구 사용 능력에서 나올 수 있습니다. 그래서 정부 평가기관은 코딩 벤치마크를 단순 생산성 지표로만 보지 않습니다. 그것은 동시에 자동화된 취약점 탐색, 악성 코드 작성, 시스템 조작 가능성을 가늠하는 간접 지표가 될 수 있습니다.
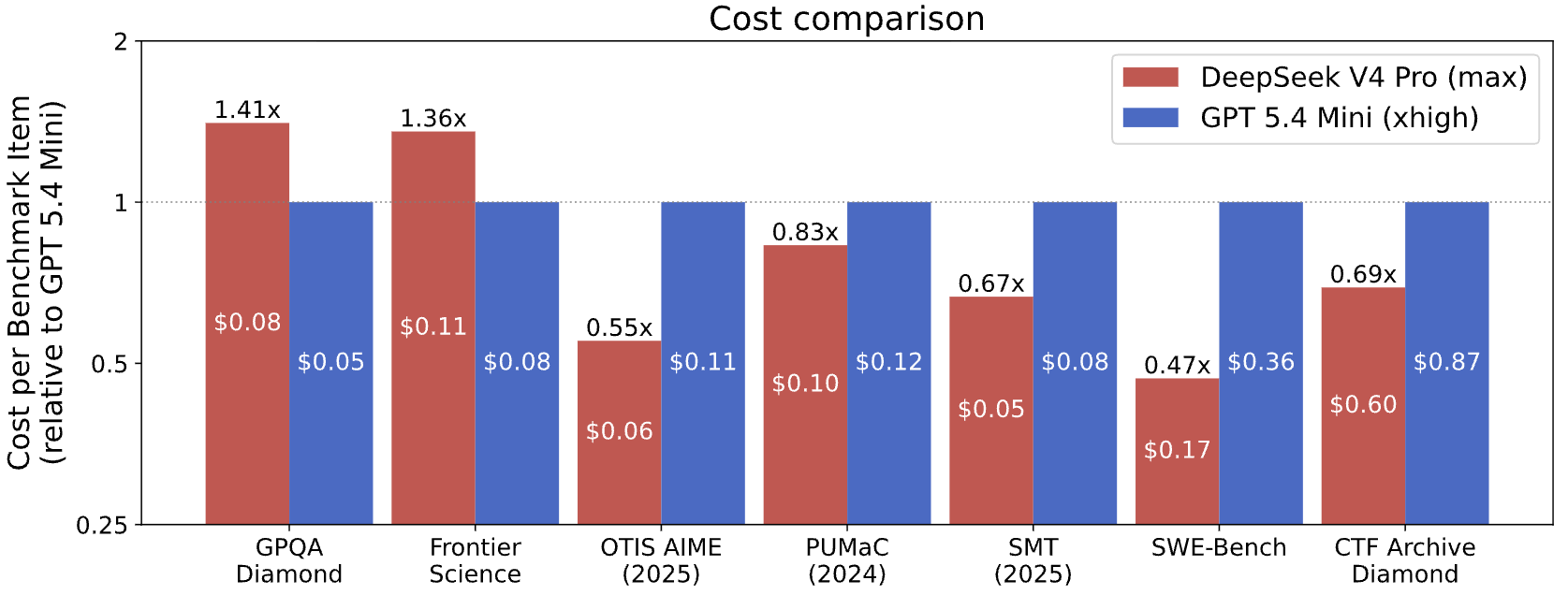
CAISI가 공개한 비용 분석도 흥미롭습니다. DeepSeek V4 Pro는 CAISI가 비교 가능한 7개 벤치마크에서 GPT-5.4 mini와 비교됐고, 그중 5개에서 더 비용 효율적이라고 평가됐습니다. 차이는 53% 저렴함부터 41% 비쌈까지 넓게 나타났습니다. 이 수치는 오픈 모델 또는 저비용 모델을 도입하려는 기업에게 매력적입니다. 하지만 바로 그 지점 때문에 평가 체계가 중요해집니다. 모델이 충분히 저렴하고 충분히 강력하다면, 정부와 기업은 "어디에 쓰면 안 되는가"를 더 세밀하게 따지게 됩니다.
자발적 협약인가, 사전 허가제의 출발점인가
이번 뉴스에서 가장 조심해서 읽어야 할 단어는 "사전 평가"입니다. 사전 평가가 곧 사전 허가를 뜻하지는 않습니다. CAISI의 설명은 민간 개발자와의 자발적 협약, 비공개 평가, 협력 연구에 가깝습니다. 현재 공개된 정보만으로는 CAISI가 특정 모델 출시를 막을 수 있는지, 평가 결과를 반드시 공개해야 하는지, 어떤 기준을 통과해야 API 출시가 가능한지 알 수 없습니다.
그래서 커뮤니티 반응도 갈립니다. 일부는 프런티어 AI가 중요 인프라처럼 취급되기 시작한 명확한 신호라고 봅니다. 반대로 일부 보안 커뮤니티와 Reddit 반응은 "자발적 테스트라면 출시를 실제로 막지 못한다"는 점을 지적합니다. 둘 다 일리가 있습니다. 사전 평가 체계는 출시 차단권이 없어도 시장에서 힘을 가질 수 있습니다. 대형 고객이 "CAISI 또는 AISI와 협력 평가를 받은 모델인가"를 조달 조건에 넣기 시작하면, 자발적 협약은 사실상의 시장 표준이 됩니다.
개발자에게 더 실질적인 질문은 이것입니다. 모델 제공사가 외부 평가를 받았다는 사실이 어떤 API 보증으로 이어지는가. 평가 범위가 일반 채팅 모델에만 적용되는가, 아니면 코드 실행 에이전트, 도구 호출, 브라우저 조작, 장기 작업 모드에도 적용되는가. 평가 당시의 모델 버전, 시스템 프롬프트, 안전 필터, 도구 스캐폴딩이 실제 API와 얼마나 같은가. 기업 고객이 사고 조사나 규제 대응에서 해당 평가를 근거로 쓸 수 있는가.
이 질문에 답하지 못하면 외부 평가는 마케팅 문구가 되기 쉽습니다. 반대로 평가 범위와 조건이 명확해지면, 프런티어 모델 시장에는 새로운 차별화 축이 생깁니다. 단순히 "가장 똑똑한 모델"이 아니라, "고위험 환경에 배치할 수 있음을 더 잘 증명한 모델"이 경쟁력을 얻게 됩니다.
모델 벤치마크의 정치성이 커집니다
CAISI의 DeepSeek V4 Pro 평가는 기술 평가가 점점 지정학적 문맥을 띠게 된다는 점도 보여줍니다. NIST 페이지는 CAISI가 미국과 경쟁국 AI 시스템의 역량, 외국 AI 시스템 채택, 국제 AI 경쟁 상태를 평가한다고 설명합니다. 이는 모델 평가가 연구 커뮤니티의 리더보드 경쟁을 넘어 국가 기술 경쟁의 언어로 편입되고 있다는 뜻입니다.
이 흐름은 개발자에게 불편한 면이 있습니다. 개발자는 대체로 "내 작업에 가장 좋은 모델"을 고르고 싶어 합니다. 하지만 기업과 정부 고객은 "내 규제 환경에서 설명 가능한 모델"을 고릅니다. 예컨대 어떤 오픈 웨이트 모델이 비용 대비 성능이 좋더라도, 데이터 출처, 공급망, 백도어 가능성, 비공개 평가 결과의 부재가 도입 리스크로 작동할 수 있습니다. 반대로 폐쇄형 모델은 투명성이 낮다는 비판을 받지만, 정부 평가기관과의 협력 기록이 조달 문서에서 강점이 될 수 있습니다.
이 때문에 앞으로 모델 릴리스 노트는 더 복잡해질 가능성이 큽니다. 지금까지는 컨텍스트 길이, 가격, 벤치마크, 도구 호출, 멀티모달 성능이 핵심이었습니다. 앞으로는 평가 파트너, 평가 범위, 사전 배포 접근 여부, 위험 범주, 정책 적용 모드, 배포 후 모니터링 체계가 같이 등장할 수 있습니다. 특히 에이전트 제품에서는 이 변화가 더 빠르게 올 것입니다. 에이전트는 단순 텍스트 생성보다 권한과 실행 환경이 넓기 때문입니다.
AI 제품팀은 무엇을 봐야 하나
이 뉴스가 당장 API 사용법을 바꾸지는 않습니다. 하지만 모델 선택 기준은 바꿉니다. 첫째, 벤치마크 숫자의 출처를 더 엄격히 봐야 합니다. 공개 벤치마크는 여전히 유용하지만, 모델 제공사가 고른 항목만으로는 충분하지 않습니다. CAISI가 DeepSeek 평가에서 보여준 것처럼 개발사 자체 보고와 독립 평가의 결론은 다를 수 있습니다.
둘째, 평가가 어떤 스캐폴딩에서 수행됐는지 확인해야 합니다. 코딩 에이전트는 모델 단독 성능보다 도구, 프롬프트, 파일시스템 접근, 토큰 예산, 재시도 전략의 영향을 크게 받습니다. CAISI가 SWE-Bench 점수 주석에서 시스템 프롬프트와 스캐폴딩 차이를 언급한 이유가 여기에 있습니다. 어떤 모델이 특정 리더보드에서 높게 나왔다고 해서, 여러분의 에이전트 런타임에서도 같은 위험과 성능 프로파일을 갖는 것은 아닙니다.
셋째, 고위험 사용처에서는 외부 평가와 내부 평가를 분리하지 말아야 합니다. CAISI나 AISI 평가를 받은 모델이라도, 여러분의 데이터, 도구, 권한, 업무 흐름에서는 다른 실패 모드가 생길 수 있습니다. 외부 평가는 출발점이고, 제품 수준의 권한 설계와 로그, 샌드박스, 데이터 경계, 휴먼 승인 정책이 뒤따라야 합니다.
넷째, 출시 지연 리스크를 고려해야 합니다. 사전 배포 평가가 시장 표준이 되면, 가장 강력한 모델이 곧바로 모든 고객에게 제공되지 않을 수 있습니다. 특정 모델은 정부 평가, 안전장치 조정, 제한적 베타를 거친 뒤에야 일반 API로 내려올 수 있습니다. 프런티어 모델에 강하게 의존하는 제품팀은 대체 모델 경로와 평가 기준을 미리 준비해야 합니다.
결론: 모델 출시의 병목은 GPU만이 아닙니다
AI 업계는 오랫동안 모델 출시의 병목을 컴퓨트로 설명해왔습니다. 더 많은 GPU, 더 큰 데이터센터, 더 빠른 추론 인프라가 곧 경쟁력이라는 이야기입니다. 그 설명은 여전히 맞습니다. 하지만 CAISI 협약과 DeepSeek V4 Pro 평가는 또 다른 병목을 보여줍니다. 프런티어 모델은 이제 출시 전에 신뢰를 증명해야 합니다.
그 신뢰는 단순한 브랜드 신뢰가 아닙니다. 누가 모델을 사전에 봤는지, 어떤 비공개 평가가 있었는지, 사이버와 바이오 같은 고위험 역량을 어떻게 측정했는지, 개발자용 에이전트 성능이 어떤 위험 범주와 함께 해석됐는지가 중요해집니다. 모델 제공사에게는 평가 협력 능력이 제품 경쟁력이 됩니다. 개발자에게는 모델 선택이 기술 성능과 규제 해석을 동시에 다루는 일이 됩니다.
이번 뉴스의 핵심은 "정부가 AI를 규제한다"는 넓은 문장이 아닙니다. 더 정확히는 프런티어 모델 출시의 신뢰 인프라가 만들어지고 있다는 것입니다. 이 인프라가 투명하고 재현 가능하며 개발자가 실제로 사용할 수 있는 정보로 이어진다면, 모델 시장은 조금 더 성숙해질 수 있습니다. 반대로 평가 결과가 비공개 협약과 홍보 문구에 머문다면, 우리는 또 하나의 불투명한 권위 지표를 얻게 될 뿐입니다.
그래서 다음에 봐야 할 것은 새 협약 자체보다 그 후속 산출물입니다. CAISI와 AISI가 어떤 평가 방법을 공개하는지, 모델 제공사가 평가 범위를 API 문서에 어떻게 연결하는지, 고객이 조달과 보안 심사에서 이 결과를 어떻게 사용하는지입니다. 프런티어 AI 경쟁은 모델의 지능뿐 아니라, 그 지능을 사회와 기업 시스템에 넣어도 된다고 설득하는 능력의 경쟁으로 이동하고 있습니다.