GPU 없이 11초 오디오를 8초 안에, Arm SME2의 온디바이스 AI
Google과 Arm의 LiteRT 최적화는 생성 AI 배포 경쟁이 모델에서 CPU 런타임과 메모리 경계로 내려가고 있음을 보여줍니다.

- 무슨 일: Google과 Arm이
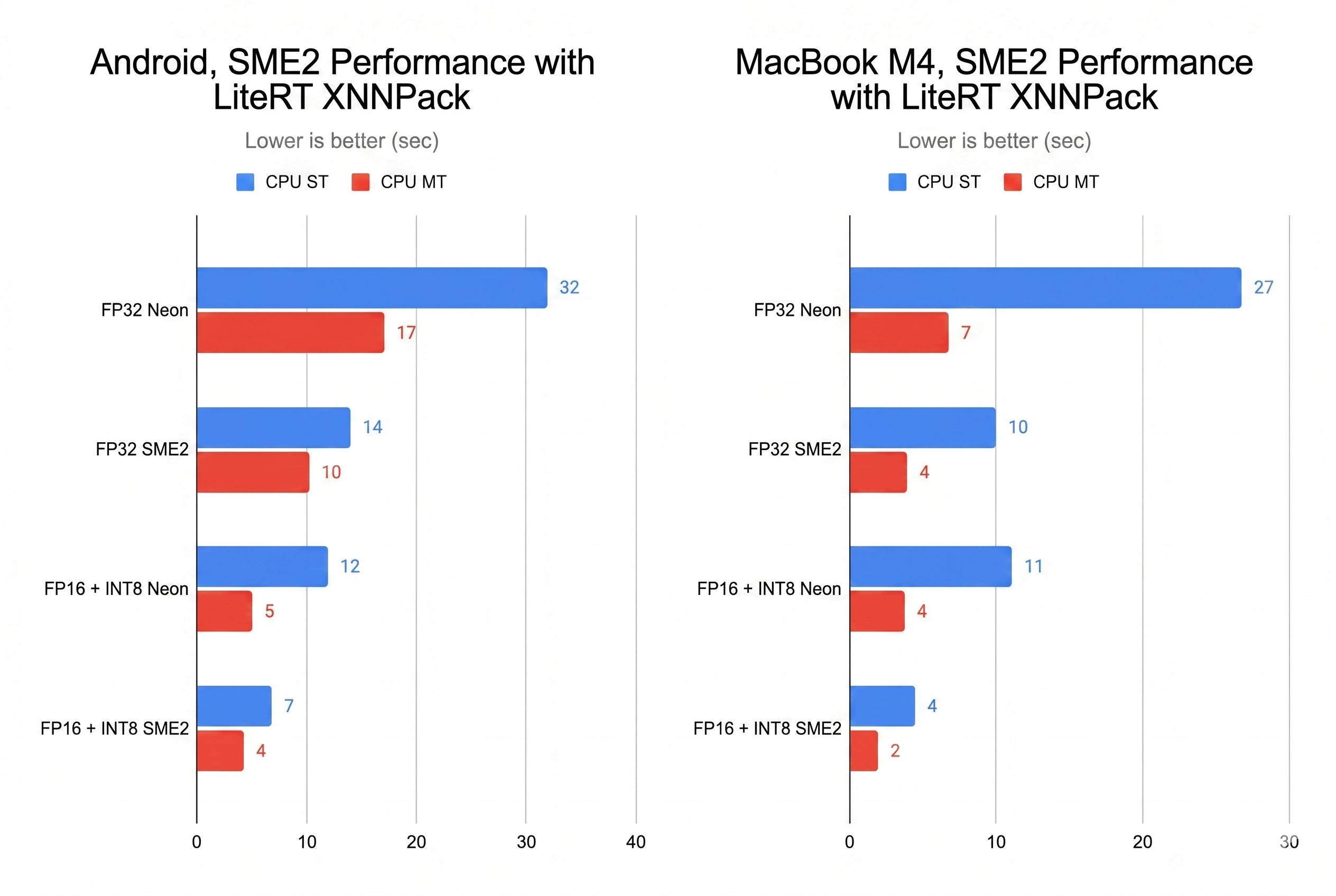
Stable Audio Open Small을 LiteRT, XNNPACK, KleidiAI, SME2로 최적화한 온디바이스 생성 AI 사례를 공개했습니다.- Google Developers Blog 기준 발표일은 2026년 5월 14일이며, Android SME2 device 1 thread에서 14초 작업을 6.6초로 줄였다고 설명했습니다.
- 핵심 수치: DiT submodule은
3x성능 개선과4x메모리 감소, SME2는 NEON 대비 2배 이상 향상을 보였습니다. - 의미: 온디바이스 AI 경쟁이 모델 크기만이 아니라 runtime, quantization, CPU instruction set, 배포 도구의 문제로 내려가고 있습니다.
- 주의점: 데모 workload는 오디오 생성 하나입니다. 실제 앱에서는 발열, 배터리, 기기별 SME2 지원, 모델 license, 품질 회귀를 따로 검증해야 합니다.
2026년 5월 14일, Google Developers Blog에 올라온 Arm과 Google AI Edge 최적화 글은 겉으로 보면 모바일 AI 성능 개선 사례입니다. Stability AI의 Stable Audio Open Small 모델을 가져와 PyTorch에서 LiteRT로 변환하고, INT8/FP16 mixed precision으로 줄이고, XNNPACK과 Arm KleidiAI를 통해 Arm CPU의 SME2를 활용했다는 내용입니다. 하지만 이 발표가 흥미로운 이유는 단순히 "더 빨라졌다"가 아닙니다. 생성 AI 배포 경쟁이 프런티어 모델 발표에서 점점 더 낮은 층, 즉 runtime, quantization, memory, instruction set, device coverage로 내려가고 있다는 신호이기 때문입니다.
Google과 Arm이 제시한 숫자는 꽤 구체적입니다. DiT, 즉 Diffusion Transformer submodule에 dynamic INT8 quantization을 적용해 3배 성능 개선과 4배 메모리 사용량 감소를 얻었다고 설명합니다. 전체 benchmark에서는 Apple MacBook M4에서 오디오 생성 시간이 10초에서 4.3초로 줄었고, Arm SME2 기반 Android device 1 thread에서는 14초에서 6.6초로 줄었다고 밝혔습니다. 더 중요한 문장은 그 다음입니다. SME2가 NEON instruction set 대비 2배 이상 성능을 냈고, 단일 코어에서도 11초 오디오를 8초 미만에 생성할 수 있다는 설명입니다. 모바일 생성 AI에서 "실시간에 가까운 사용자 경험"이 GPU나 NPU 전용 경로만의 이야기가 아닐 수 있다는 주장입니다.
이 뉴스는 화려한 모델 출시와 달리 조용해 보입니다. 그러나 AI 앱을 실제 기기에 배포하는 팀에게는 더 실질적인 질문을 던집니다. 클라우드 API를 부르면 품질은 좋지만 비용, 지연시간, 개인정보, 네트워크 의존성이 따라옵니다. 온디바이스로 내리면 그 반대 문제가 생깁니다. 모델이 너무 크고, 메모리가 부족하고, 기기별 acceleration path가 다르고, 배터리와 발열이 제품 경험을 망칠 수 있습니다. 결국 AI 기능은 "어떤 모델을 쓰는가"와 "어디에서 실행하는가" 사이에서 계속 타협해야 합니다. 이번 Google/Arm 사례는 그 타협의 폭을 CPU 계층에서 넓히려는 시도입니다.
GPU가 아니라 CPU를 다시 보는 이유
온디바이스 AI를 말할 때 가장 먼저 떠오르는 것은 NPU입니다. Apple Neural Engine, Qualcomm Hexagon NPU, Google Tensor의 TPU 계열, MediaTek NPU처럼 모바일 SoC에는 AI 전용 가속기가 붙습니다. GPU도 여전히 중요한 경로입니다. 문제는 개발자가 모든 device, OS, driver, delegate, model format을 안정적으로 맞춰야 한다는 점입니다. 실제 상용 앱에서는 가장 빠른 path보다 가장 넓고 예측 가능한 path가 더 중요할 때가 많습니다.
CPU는 이 지점에서 다시 등장합니다. CPU는 거의 모든 기기에 있고, 운영체제와 런타임이 가장 오래 다듬어 온 실행 기반입니다. 다만 생성 AI의 행렬 연산 workload에는 전통적인 CPU path가 느렸습니다. Arm이 내세우는 Scalable Matrix Extension 2, 즉 SME2는 이 약점을 줄이려는 기술입니다. Arm은 SME2를 Armv9 CPU 안에 들어간 matrix compute 확장으로 설명합니다. Google 글은 이를 "CPU cluster 안에 dedicated matrix-compute unit을 통합한다"는 식으로 풀이합니다. 말하자면 CPU를 fallback path로만 두지 않고, matrix-heavy 생성 AI workload를 처리할 수 있는 배포 대상 중 하나로 끌어올리려는 것입니다.
여기서 중요한 주체가 Google AI Edge입니다. LiteRT GitHub 저장소는 LiteRT를 TensorFlow Lite의 후속 온디바이스 framework로 소개합니다. Android, iOS, Linux, macOS, Windows, Web, IoT까지 넓은 platform support를 내세우고, GPU/NPU acceleration뿐 아니라 GenAI model 배포를 runtime 차원에서 다루겠다고 합니다. 이번 사례에서는 LiteRT가 XNNPACK delegate를 통해 KleidiAI micro-kernel을 자동 활용합니다. 개발자가 assembly나 custom hardware code를 직접 쓰는 방식이 아니라, PyTorch model을 변환하고 quantization을 적용하면 runtime이 적절한 CPU acceleration path를 타도록 만드는 그림입니다.
Stable Audio Open Small이 좋은 시험대인 이유
이번 발표의 workload는 text-to-audio입니다. Stable Audio Open Small은 prompt에서 stereo audio sample을 생성하는 공개 모델입니다. Google 글은 "single prompt로 11초 stereo clip을 생성한다"는 시나리오를 잡았습니다. 이 workload가 흥미로운 이유는 LLM chat보다 사용자 경험 기준이 더 냉정하기 때문입니다. 텍스트 답변은 2초 늦어도 사용자가 기다릴 수 있습니다. 오디오 생성은 결과물이 binary media이고, latency가 길면 창작 흐름이 끊깁니다. 동시에 output quality가 조금만 깨져도 사용자가 바로 듣습니다.
이 모델은 세 가지 점에서 온디바이스 배포 난도를 잘 드러냅니다. 첫째, diffusion 기반 생성 모델은 반복 계산이 많습니다. 둘째, audio 품질은 quantization으로 쉽게 망가질 수 있습니다. 셋째, mobile app에 넣으려면 모델 footprint와 peak memory를 줄여야 합니다. Google/Arm이 단순히 "전부 INT8로 줄였다"고 말하지 않는 이유도 여기에 있습니다. 발표는 naive quantization이 audio quality를 심각하게 손상할 수 있다고 짚고, DiT submodule처럼 quantization-safe한 부분을 찾아 dynamic INT8을 적용했다고 설명합니다.
이때 Model Explorer가 등장합니다. Google의 Model Explorer는 graph를 시각화하고, node data overlay plugin을 통해 어떤 operator가 compute-intensive인지, 어떤 layer가 quantization-safe한지 확인하는 도구로 소개됩니다. 발표에 따르면 DiT transformer block들의 FP32 대비 FP32+INT8 error가 낮게 나타났고, 이를 근거로 dynamic INT8 quantization을 적용했습니다. 온디바이스 AI 최적화는 단순한 압축 레시피가 아니라 "어디를 줄여도 품질이 유지되는가"를 확인하는 작업이라는 점을 보여줍니다.

Convert, Optimize, Deploy가 뉴스인 이유
Google 글은 전체 흐름을 Convert -> Optimize -> Deploy로 정리합니다. 이 구조는 개발 문서처럼 보이지만, 실제로는 플랫폼 전략입니다. 연구 모델을 production mobile app으로 옮기는 과정에서 가장 많은 시간이 사라지는 곳이 바로 format conversion, quantization, runtime integration입니다. 모델 카드와 논문은 PyTorch 기준으로 나옵니다. 모바일 앱은 .tflite, Core ML, ONNX, vendor SDK 같은 runtime format을 요구합니다. 여기서 shape, operator support, tokenizer, memory layout, delegate compatibility가 계속 문제를 일으킵니다.
LiteRT-Torch는 PyTorch 모델을 LiteRT ecosystem으로 가져오는 경로입니다. AI Edge Quantizer는 model compression을 담당합니다. Model Explorer는 optimization이 품질을 얼마나 해치는지 확인하는 시각화 계층입니다. Runtime에서는 LiteRT의 CompiledModel API와 XNNPACK delegate가 실제 device execution을 맡습니다. Arm 쪽에서는 KleidiAI micro-kernel과 SME2가 하드웨어 가까운 층을 담당합니다. 이 조합을 하나의 개발자 경험으로 묶는 것이 이번 발표의 핵심입니다.
PyTorch Stable Audio Open Small
LiteRT-Torch 변환과 AI Edge Quantizer
Model Explorer로 quantization-safe layer 확인
LiteRT + XNNPACK + KleidiAI
Arm SME2 CPU에서 온디바이스 오디오 생성
개발자에게 이 흐름이 중요한 이유는 선택지를 바꾸기 때문입니다. 지금까지 온디바이스 생성 AI를 검토할 때 많은 팀은 "품질을 낮춘 작은 모델을 쓸 것인가, 클라우드로 보낼 것인가"를 먼저 고민했습니다. 앞으로는 "어떤 submodule을 quantize할 수 있는가", "어떤 runtime이 device별 delegate를 자동 선택하는가", "CPU path가 최소 경험을 보장할 수 있는가"도 같은 수준의 제품 질문이 됩니다. 특히 prompt-to-audio, voice effect, local sound design, short-form media tool처럼 개인화와 privacy가 중요한 기능에서는 클라우드 왕복을 줄이는 가치가 큽니다.
숫자를 어떻게 읽어야 하나
이번 발표에서 가장 눈에 띄는 수치는 네 가지입니다. DiT submodule 3배 성능 향상, DiT memory 4배 감소, MacBook M4 10초에서 4.3초, Arm SME2 Android 1 thread 14초에서 6.6초입니다. 여기에 "SME2가 NEON보다 2배 이상 빠르다"와 "single core로 11초 audio를 8초 미만 생성"이라는 문장이 붙습니다.
이 숫자를 과장해서 읽으면 안 됩니다. 하나의 model, 하나의 audio generation pipeline, 특정 test device 조건입니다. Android ecosystem 전체를 대표한다고 볼 수 없습니다. SME2 지원 여부도 중요합니다. 오래된 Arm device나 다른 SoC에서는 같은 결과가 나오지 않을 수 있습니다. multi-threading을 쓰면 thermal throttling과 battery drain도 봐야 합니다. 사용자가 실제로 앱을 켠 상태에서 browser, camera, background sync, notification이 같이 도는 환경은 benchmark보다 복잡합니다.
그럼에도 이 숫자가 의미 있는 이유는 "가능성"이 아니라 "배포 경로"를 보여주기 때문입니다. Google과 Arm은 연구용 모델 하나를 단순 demo로 돌린 것이 아니라, conversion, quantization, visualization, runtime, micro-kernel, instruction set을 이어 붙였습니다. 그리고 그 결과를 공식 chart와 sample repository, Learning Path로 공개했습니다. 실무 팀이 바로 제품에 넣을 수 있다는 뜻은 아니지만, 최소한 같은 경로를 따라 자기 모델과 device matrix를 검증할 수 있는 출발점이 생깁니다.
LiteRT는 TensorFlow Lite 이후를 어떻게 정리하나
LiteRT라는 이름은 TensorFlow Lite 이후의 재정리에 가깝습니다. TensorFlow Lite는 오랫동안 모바일 ML 배포의 대표 runtime이었습니다. 하지만 생성 AI 시대에는 기존 image classification, object detection 중심의 배포 경험만으로 부족합니다. LLM, diffusion model, multimodal encoder-decoder, audio generation은 memory와 operator pattern이 다릅니다. tokenizer, KV cache, quantization strategy, streaming output, long-running inference 같은 요구도 붙습니다.
LiteRT 저장소는 "high-performance ML & GenAI deployment on edge platforms"를 전면에 놓습니다. Readme는 Compiled Model API, automated accelerator selection, async execution, NPU runtime, GPU performance, GenAI inference를 강조합니다. 이 문구를 그대로 제품 가치로 받아들일 필요는 없지만, 방향은 분명합니다. Google은 온디바이스 AI를 단일 delegate나 단일 framework 문제가 아니라, model conversion부터 execution까지 이어지는 runtime product로 묶으려 합니다.
Arm 입장에서도 이 흐름은 중요합니다. Arm은 모바일 CPU 시장의 기반을 쥐고 있지만, AI 마케팅의 중심은 한동안 NPU와 GPU로 이동했습니다. SME2와 KleidiAI는 CPU도 생성 AI workload에서 의미 있는 acceleration layer가 될 수 있다는 메시지입니다. 더 정확히 말하면 CPU가 최고 성능 path가 되겠다는 주장보다, 넓은 device coverage와 predictable fallback path에서 AI 경험의 바닥을 끌어올리겠다는 주장에 가깝습니다. 생성 AI 앱이 mass-market으로 갈수록 이 바닥 성능이 중요해집니다.
클라우드 AI 비용 압박과 온디바이스의 재부상
온디바이스 AI가 다시 중요해지는 배경에는 비용도 있습니다. AI 기능이 실험 단계일 때는 API 호출 비용이 제품 전체 비용에서 작아 보입니다. 하지만 기능이 core workflow가 되고, 사용량이 많아지고, media generation처럼 token보다 compute가 무거운 작업이 붙으면 비용 구조가 달라집니다. 모든 prompt, intermediate state, media output을 클라우드로 보내는 방식은 latency와 privacy뿐 아니라 gross margin 문제를 만듭니다.
물론 온디바이스가 공짜는 아닙니다. 모델 최적화 비용, device QA, crash 분석, store binary size, local storage, battery regression, support matrix가 생깁니다. 그러나 일정 비율의 작업을 local path로 돌릴 수 있다면 cloud inference는 더 고부가 작업에 집중할 수 있습니다. 예를 들어 초안 생성, preview, 개인화된 효과, offline fallback은 device에서 처리하고, 최종 고품질 render나 긴 작업은 cloud로 올리는 hybrid architecture가 가능합니다. 이때 CPU path의 성능이 올라가면 hybrid 설계의 선택지가 늘어납니다.
이번 Stable Audio Open Small 사례는 audio generation이라는 특정 분야를 다루지만, 구조적 함의는 더 넓습니다. 같은 논리가 local image editing, short video preprocessing, voice transformation, meeting note redaction, private document embedding, small action model에도 적용될 수 있습니다. 모든 workload가 CPU에 맞지는 않지만, model partitioning과 selective quantization이 정교해질수록 "일부는 local, 일부는 cloud"의 경계가 더 유연해집니다.
개발자가 바로 확인해야 할 질문
이 발표를 보고 온디바이스 AI를 검토하는 팀이라면, 먼저 자기 workload의 bottleneck을 분해해야 합니다. 모델 전체가 느린지, 특정 submodule이 느린지, memory bandwidth가 문제인지, operator support가 문제인지, tokenizer나 post-processing이 병목인지 확인해야 합니다. Google/Arm 사례에서 DiT submodule을 따로 잡은 것처럼, 전체 모델을 하나의 black box로 보면 최적화 지점이 흐려집니다.
두 번째는 품질 회귀입니다. INT8이나 FP16을 적용하면 benchmark는 좋아질 수 있지만, user-facing quality는 나빠질 수 있습니다. 오디오에서는 잡음, high-frequency artifact, stereo image 붕괴, prompt adherence 저하가 나타날 수 있습니다. 텍스트 모델에서는 hallucination, tool call accuracy, format stability가 흔들릴 수 있습니다. Google 글이 Model Explorer의 error overlay를 강조한 이유는 성능 수치만으로는 production decision을 내릴 수 없기 때문입니다.
세 번째는 device policy입니다. SME2가 있는 최신 Armv9-A CPU와 그렇지 않은 device를 같은 경험으로 묶을 수 없습니다. 앱은 capability detection, model variant selection, fallback latency, user-facing messaging을 설계해야 합니다. "이 기기에서는 local 생성이 빠릅니다", "이 기기에서는 cloud mode를 권장합니다" 같은 product surface가 필요할 수 있습니다. AI 기능의 품질이 device tier에 따라 달라지는 시대에는 runtime capability가 UX의 일부가 됩니다.
커뮤니티 반응은 아직 조용하지만 방향은 분명하다
Hacker News에서 이번 Google Developers Blog 글이 독립적으로 큰 토론으로 번진 흔적은 확인하지 못했습니다. daily.dev와 TECH Dashboard 같은 개발자 큐레이션 사이트는 이를 "온디바이스 오디오 생성과 CPU inference 최적화"로 요약했습니다. 반응이 조용한 이유는 이 뉴스가 소비자 제품 출시가 아니라 runtime engineering 발표이기 때문입니다. 그러나 개발자 생태계에서는 이런 종류의 발표가 나중에 더 큰 제품 변화의 기반이 되는 경우가 많습니다.
Arm은 이미 2025년에도 Stable Audio Open Small을 KleidiAI와 함께 Arm CPU에서 실행하는 사례를 공개했고, Learning Path와 sample repository를 제공했습니다. 이번 Google 글은 그 흐름을 Google AI Edge 제품군과 결합해 더 넓은 Android/edge developer narrative로 가져온 성격이 있습니다. 즉, "한 번의 데모"보다 "공식 runtime stack에 들어오는 경로"가 중요합니다. LiteRT, XNNPACK, KleidiAI, SME2가 연결되면 개발자는 vendor blog를 복사하는 대신, 자기 모델을 같은 경로에 태워 볼 수 있습니다.
아직 남은 리스크
가장 큰 리스크는 generalization입니다. Stable Audio Open Small에서 잘 된 최적화가 다른 audio model, LLM, vision-language model, diffusion image model에서도 같은 비율로 통하지는 않습니다. 모델 architecture, layer distribution, activation range, operator support가 다르기 때문입니다. 특히 LLM에서는 attention, KV cache, memory bandwidth, long-context behavior가 병목으로 떠오를 수 있습니다. diffusion image나 video generation은 compute pattern과 memory footprint가 다시 달라집니다.
두 번째 리스크는 license와 배포입니다. Stable Audio Open Small은 공개 모델이지만, 제품에서 어떤 license 조건으로 쓸 수 있는지 확인해야 합니다. 생성 audio는 copyright와 training data 논쟁도 따라옵니다. 온디바이스에서 실행된다고 해서 output 책임이 사라지는 것은 아닙니다. 오히려 cloud moderation이나 centralized logging이 줄어들면 abuse detection과 user safety 설계를 앱 안에서 다시 해야 할 수 있습니다.
세 번째 리스크는 battery와 thermal입니다. benchmark는 latency를 보여주지만, 사용자가 하루에 여러 번 audio를 생성할 때 battery drain이 어떤지, thermal throttling 이후 성능이 얼마나 떨어지는지, background state에서 OS가 어떤 제한을 거는지까지 보여주지는 않습니다. 온디바이스 AI는 privacy와 latency의 장점만큼이나 전력 관리와 사용자 기대치 관리가 중요합니다.
모델 전쟁의 아래층
지난 몇 년 동안 AI 뉴스의 중심은 더 큰 모델, 더 긴 context, 더 높은 benchmark였습니다. 그 경쟁은 계속됩니다. 그러나 실제 제품으로 내려오면 다른 질문이 커집니다. 이 모델을 어디서 실행할 것인가. 사용자의 data를 어디로 보낼 것인가. inference 비용을 누가 부담할 것인가. network가 끊겼을 때 기능은 어떻게 되는가. 오래된 device에서도 쓸 수 있는가. 최신 device에서는 더 좋은 경험을 줄 수 있는가.
Google과 Arm의 이번 발표는 이 질문들에 대한 한 가지 답입니다. 모든 것을 cloud로 보내지 않고, 모든 것을 NPU에만 맡기지도 않고, CPU runtime과 quantization 도구를 끌어올려 생성 AI의 배포 경로를 넓히겠다는 답입니다. 아직은 오디오 생성 workload 하나의 사례입니다. 하지만 숫자가 구체적이고, 도구 흐름이 공개되어 있고, LiteRT라는 Google의 온디바이스 runtime 전략과 맞물린다는 점에서 그냥 지나칠 발표는 아닙니다.
온디바이스 AI의 다음 경쟁은 "작은 모델을 발표했다"에서 끝나지 않을 가능성이 큽니다. 어떤 runtime이 변환을 덜 아프게 만드는지, 어떤 quantizer가 품질 회귀를 눈에 보이게 해주는지, 어떤 CPU/GPU/NPU delegate가 자동으로 선택되는지, 어떤 instruction set이 최소 사용자 경험을 보장하는지가 중요해집니다. 모델은 여전히 주인공이지만, 사용자가 손에 든 기기에서 AI가 실제로 작동하게 만드는 것은 이 아래층입니다.
그래서 이번 뉴스의 핵심은 Stable Audio Open Small 하나가 빨라졌다는 데 있지 않습니다. 생성 AI가 클라우드 API의 기능 목록을 넘어, device runtime과 silicon feature를 함께 설계해야 하는 제품 문제가 되었다는 데 있습니다. GPU 없이 11초 오디오를 8초 안에 만든다는 숫자는 그 전환을 설명하기 좋은 표지판입니다. AI 앱을 만드는 팀이라면 이제 모델 카드만 볼 것이 아니라, runtime chart와 memory graph도 같은 무게로 봐야 합니다.