23,019건 후보, Mythos가 만든 패치 병목의 실명표
Anthropic CVD 대시보드는 Claude Mythos가 찾은 취약점보다 검증, 공개, 패치가 AI 보안의 새 병목임을 보여줍니다.
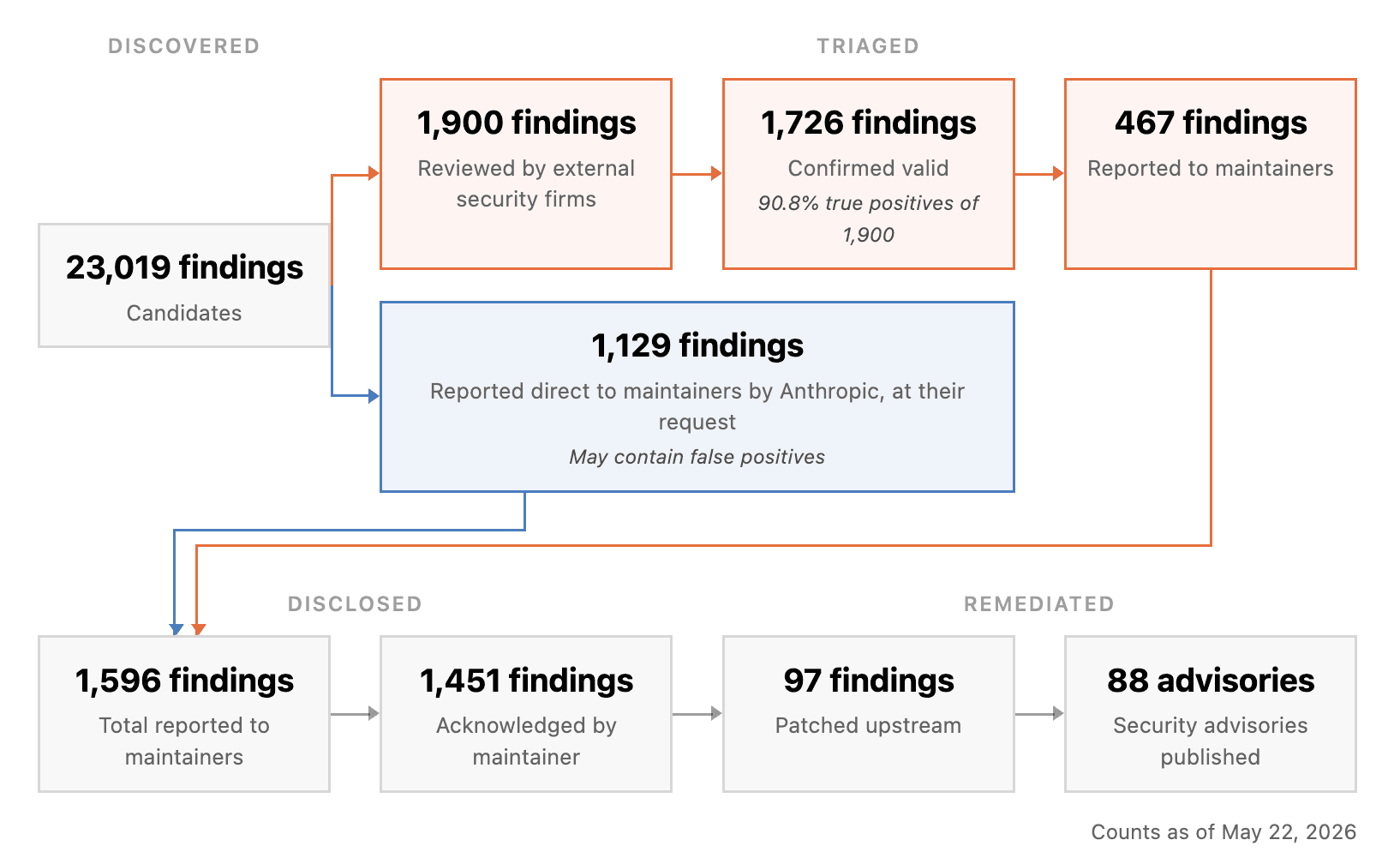
- 무슨 일: Anthropic이
Project Glasswing초기 업데이트와 CVD 대시보드를 공개했습니다.- 기준 시각은 2026년 5월 22일 10:27 PT이며, 공개 수치는 오픈소스 취약점 disclosure pipeline을 대상으로 합니다.
- 핵심 숫자: Mythos Preview 후보 23,019건, 공개 1,596건, 패치 97건, advisory 88건입니다.
- 의미: 병목은 발견 모델보다 human triage, maintainer 대응, 패치 배포로 이동했습니다.
- Anthropic은 독립 검증과 review가 rate-limiting step이라고 설명합니다.
- 주의점: 취약점 리포트가 늘수록 오픈소스 유지보수자의 검증 부담도 같이 커집니다.
Anthropic이 2026년 5월 22일 Project Glasswing 초기 업데이트와 별도의 Coordinated Vulnerability Disclosure 대시보드를 공개했습니다. 이 뉴스는 "Claude Mythos Preview가 취약점을 많이 찾았다"는 한 줄로 요약하면 오히려 핵심을 놓칩니다. 더 중요한 변화는 발견 이후의 병목이 수치로 드러났다는 점입니다.
대시보드의 기준 시각은 2026년 5월 22일 10:27 PT입니다. Anthropic은 2026년 2월부터 Claude Mythos Preview의 early snapshot을 사용해 오픈소스 소프트웨어에서 보안 취약점을 찾기 시작했고, 외부 보안 연구 업체와 함께 후보를 검증한 뒤 maintainers에게 보고하는 절차를 운영했다고 설명합니다. 그 결과 현재 공개된 headline count는 후보 23,019건, disclosed findings 1,596건, affected open source projects 281개, upstream patch 97건, CVE 또는 GHSA advisory 88건입니다.
이 숫자의 방향이 중요합니다. AI가 만든 후보는 2만 건을 넘었지만, 실제 패치와 공개 advisory까지 도달한 수는 아직 두 자리입니다. Anthropic은 이 차이를 실패로만 보지 않습니다. 오히려 취약점 발견 비용이 급격히 낮아진 뒤, 독립 검증과 responsible disclosure, maintainer communication, patch design, 사용자 배포가 새 제한 요인이 됐다고 해석합니다. 개발자와 보안팀 입장에서는 모델 성능보다 더 실무적인 질문이 생깁니다. "이제 취약점을 더 많이 찾을 수 있다면, 그 finding을 누가 검증하고 어떻게 안전하게 고칠 것인가"입니다.

Glasswing의 첫 공개 성적표
Project Glasswing은 Anthropic이 2026년 4월 공개한 사이버 방어 이니셔티브입니다. 핵심은 Claude Mythos Preview라는 제한 공개 모델을 주요 인프라 기업, 보안 조직, 오픈소스 생태계에 제공해 취약점을 먼저 찾고 고치는 것입니다. Anthropic은 Mythos Preview를 일반 사용자에게 공개하지 않았습니다. 이유도 분명하게 적었습니다. 이 수준의 모델은 방어자에게는 강력한 도구지만, 공격자에게도 flawed software를 훨씬 싸고 빠르게 exploit할 수 있게 만들 수 있기 때문입니다.
5월 22일 업데이트는 그 위험과 가능성을 동시에 보여줍니다. Anthropic은 약 50개 파트너가 한 달 동안 Claude Mythos Preview를 사용했고, 가장 중요한 소프트웨어 전반에서 high 또는 critical severity 취약점 1만 건 이상을 찾았다고 밝혔습니다. 일부 파트너는 bug-finding rate가 10배 이상 늘었다고 전했습니다. Cloudflare 사례도 인용됐습니다. Anthropic 설명에 따르면 Cloudflare는 critical-path systems에서 2,000개 bug를 찾았고, 그중 400개가 high 또는 critical severity였습니다.
Mozilla 사례도 눈에 띕니다. Anthropic은 Mozilla가 Firefox 150을 테스트하면서 271개 취약점을 찾고 고쳤고, 이는 Firefox 148에서 Claude Opus 4.6으로 찾은 것보다 10배 이상 많았다고 설명합니다. 이 수치는 "AI가 보안 연구자를 대체한다"는 식의 단순한 결론보다, 보안 테스트의 처리량 자체가 달라지고 있음을 보여줍니다. 예전에는 expert time이 부족해 못 훑던 코드 경로를 모델이 반복적으로 탐색할 수 있고, 그 결과 기존 patch cadence가 감당해야 할 입력량이 늘어납니다.
다만 파트너 사례는 대부분 aggregate 형태입니다. 취약점 상세가 모두 공개되지는 않습니다. Anthropic은 그 이유를 responsible disclosure 관행으로 설명합니다. 일반적으로 취약점은 발견 직후 세부 내용을 공개하지 않습니다. 패치와 사용자 업데이트가 충분히 진행되기 전에 공격자가 정보를 이용할 수 있기 때문입니다. 그래서 이번 업데이트의 중심은 exploit 세부 기술이 아니라 pipeline 숫자입니다. 발견, 검증, 공개, 패치, advisory로 이어지는 단계별 수치가 공개됐다는 점이 이번 뉴스의 실질적 가치입니다.
23,019건 후보에서 97건 패치까지
CVD 대시보드는 오픈소스 취약점 처리 과정을 두 갈래로 보여줍니다. 첫 번째 갈래는 외부 보안 업체가 검토한 경로입니다. Claude Mythos Preview가 찾은 candidate findings는 23,019건입니다. 이 중 1,900건이 외부 보안 업체의 검토 대상으로 올라갔고, 대시보드는 1,726건을 confirmed valid로 표시합니다. 1,900건 대비 90.8% true positive라는 수치도 함께 제시됩니다.
두 번째 갈래는 Anthropic이 maintainer 요청에 따라 직접 보고한 경로입니다. 대시보드는 1,129건이 "reported direct to maintainers by Anthropic, at their request"라고 설명합니다. 이 경로에는 false positive가 섞일 수 있다는 단서도 붙어 있습니다. 보안적으로 흥미로운 부분은 바로 이 지점입니다. 모든 finding을 독립 업체가 완전히 검증한 뒤 보내면 정확도는 올라가지만 속도가 느려집니다. 반대로 maintainer에게 더 빨리 넘기면 대응은 빨라질 수 있지만, 유지보수자가 직접 검증해야 할 부담이 늘어납니다.
최종 공개 숫자는 1,596건입니다. 이 중 1,451건은 maintainer acknowledgement를 받았고, 97건은 upstream patch가 나왔으며, 88건은 CVE 또는 GitHub Security Advisory로 공개됐습니다. 같은 페이지에는 공개 가능한 항목의 예시도 있습니다. jq의 heap-buffer-overflow, MapServer의 heap buffer overflow, temporalio/temporal의 broken access control, wolfSSL의 crypto failure와 signature bypass, nomad의 path traversal 같은 항목이 보입니다.
이 숫자들을 볼 때 조심할 점이 있습니다. 97건 패치가 낮다고 해서 나머지 1,499건이 모두 방치됐다는 뜻은 아닙니다. Anthropic은 아직 90일 disclosure window 초반이고, advisory 없이 조용히 패치되는 경우도 있어 patch count를 과소 집계할 수 있다고 설명합니다. 하지만 그렇다고 병목이 사라지는 것도 아닙니다. 공식 업데이트는 "상대적으로 쉽게 취약점을 찾는 것과 고치기 어려운 것의 차이"가 사이버보안의 주요 도전이라고 직접 말합니다.
AI 보안의 병목은 이제 발견 뒤에 있습니다
지난 몇 년 동안 AI 보안 뉴스는 주로 두 질문에 집중했습니다. 첫째, 모델이 취약점을 찾을 수 있는가. 둘째, 모델이 exploit을 만들 수 있는가. Mythos Preview와 Glasswing은 이 질문을 한 단계 밀어냈습니다. 이제 더 중요한 질문은 "finding이 너무 많아졌을 때 어떤 운영 체계가 이를 처리할 수 있는가"입니다.
Anthropic은 오픈소스 1,000개 이상을 스캔했고, Mythos Preview가 자체 추정으로 6,202건의 high 또는 critical 후보를 찾았다고 밝혔습니다. 그중 1,752건을 평가했고, 90.6%인 1,587건이 true positive로 판정됐으며, 62.4%인 1,094건은 high 또는 critical로 확인됐다고 설명합니다. 이 true-positive rate가 유지된다면, 이미 찾은 후보만으로도 오픈소스 high/critical 취약점 약 3,900건을 surfaced할 수 있다는 계산도 제시했습니다.
숫자만 보면 매우 강한 주장입니다. 하지만 실무에서는 바로 다음 문장이 더 중요합니다. Anthropic은 high 또는 critical bug 하나가 patch되기까지 평균 2주가 걸린다고 밝혔습니다. 그리고 일부 maintainers가 disclosure 속도를 늦춰 달라고 요청했다고 적었습니다. 이유는 단순합니다. 오픈소스 유지보수자는 이미 저품질 AI 생성 버그 리포트에 시달리고 있습니다. 여기에 Mythos가 만든 높은 품질의 finding까지 들어오면, 정확하더라도 처리량 문제가 생깁니다.
이것은 AI 보안 도구의 역설입니다. 좋은 도구는 더 많은 진짜 문제를 찾습니다. 하지만 진짜 문제도 사람이 읽고, 재현하고, severity를 재평가하고, 패치를 설계하고, 회귀 테스트를 돌리고, advisory를 써야 합니다. finding이 증가할수록 보안팀은 좋아질 수도 있지만, maintainer queue는 터질 수도 있습니다. 결국 AI 보안 제품의 가치는 "찾았다"에서 끝나지 않고, "검증 가능한 patch와 안전한 disclosure까지 밀어 넣었다"로 평가돼야 합니다.
Mythos가 보여준 능력과 공개의 한계
Anthropic의 Claude Mythos Preview 기술 글은 모델 능력에 대한 더 강한 사례를 제시합니다. 예를 들어 Mythos Preview가 FreeBSD에서 17년 된 remote code execution 취약점을 자율적으로 찾고 exploit까지 작성했다는 설명이 있습니다. Linux kernel에서는 여러 취약점을 chain으로 묶어 local privilege escalation을 만드는 사례도 소개됐습니다. 브라우저 JIT heap spray, cryptography library weakness, web application logic vulnerability 같은 범주도 언급됩니다.
하지만 대부분의 상세는 아직 공개되지 않았습니다. 패치되지 않았거나 최근에야 패치된 취약점이 많기 때문입니다. Anthropic은 cryptographic commitment를 남기고, 나중에 disclosure window가 닫히면 상세를 공개하겠다고 설명합니다. CVD 대시보드에도 아직 공개할 수 없는 finding에 대한 hash commitment ledger가 들어갑니다. 이는 완전한 투명성은 아니지만, "우리가 특정 시점에 이 finding을 갖고 있었다"는 증거를 남기는 절충입니다.
개발자 입장에서 이 절충은 불편하지만 현실적입니다. 취약점 정보는 연구성과인 동시에 공격 매뉴얼이 될 수 있습니다. AI가 exploit 작성까지 도울 수 있다면, 공개 시점과 상세 수준은 더 민감해집니다. 그래서 이번 대시보드는 기술 세부보다 process transparency에 가깝습니다. 어떤 프로젝트가 어떤 취약점에 영향을 받았고, 어느 단계까지 왔는지, advisory가 나왔는지, patch가 됐는지를 tracking하는 쪽입니다.
다만 이 방식에도 한계가 있습니다. aggregate 숫자는 강하지만, 외부 독자가 각 finding의 실제 exploitability와 severity를 독립적으로 검증하기는 어렵습니다. 일부 커뮤니티에서 "Mythos가 과장됐다"는 반응이 나오는 이유도 여기에 있습니다. Anthropic이 제시하는 공개 사례가 늘어날수록 논쟁은 줄어들겠지만, 당분간은 비공개 disclosure와 공개 검증 사이의 긴장이 계속될 가능성이 큽니다.
오픈소스 유지보수자의 새 부담
이번 업데이트에서 가장 현실적인 문장은 maintainer capacity에 관한 부분입니다. Anthropic은 유지보수자들이 이미 AI 생성 저품질 bug report의 홍수에 직면해 있고, 일부는 공개 속도를 늦춰 달라고 요청했다고 밝혔습니다. 이 문장은 AI 보안 경쟁의 어두운 면을 잘 보여줍니다. AI가 취약점을 더 잘 찾는 것과, AI가 보안 생태계 전체를 더 건강하게 만드는 것은 같은 일이 아닙니다.
오픈소스 유지보수자는 대개 전담 보안팀이 아닙니다. 인기 라이브러리라도 소수 maintainer가 issue, PR, release, 문서, 사용자 지원을 함께 처리하는 경우가 많습니다. 여기에 high/critical로 추정되는 보고서가 대량으로 들어오면, maintainer는 먼저 "이것이 실제 취약점인가"부터 확인해야 합니다. 재현 환경을 만들고, 영향을 받는 버전을 확인하고, exploit 가능성을 평가하고, 회귀 테스트를 추가하고, 패치를 릴리스하고, downstream 사용자에게 전달해야 합니다.
이 과정은 모델이 대신할 수 있는 부분과 그렇지 않은 부분이 섞여 있습니다. 모델은 code path를 추적하고, PoC를 만들고, patch 후보를 제안할 수 있습니다. 하지만 maintainer는 프로젝트의 호환성, release policy, API 안정성, distribution channel, downstream 생태계를 압니다. 보안 패치는 코드 한 줄이 아니라 release engineering입니다. 잘못된 긴급 패치는 다른 장애를 만들 수 있고, 너무 늦은 패치는 공격 창을 남깁니다.
그래서 Anthropic이 Claude Security public beta, skills, harness, threat model builder를 함께 언급한 점이 중요합니다. 취약점 발견만으로는 maintainer 병목을 풀기 어렵습니다. 필요한 것은 finding을 재현 가능한 evidence, 최소 patch, regression test, advisory 초안, release checklist로 바꾸는 도구입니다. AI가 정말 도움이 되려면 maintainer에게 "여기 100개 취약점 후보입니다"라고 던지는 것이 아니라, 검증과 수정의 단계를 줄여야 합니다.
OpenAI Daybreak와 같은 질문, 다른 표면
이 흐름은 OpenAI의 Daybreak와도 연결됩니다. OpenAI는 GPT-5.5-Cyber, Trusted Access for Cyber, Codex Security를 통해 취약점 발견, threat modeling, patch validation, detection engineering을 하나의 security flywheel로 묶으려 합니다. Anthropic은 Mythos Preview와 Project Glasswing을 통해 partner와 open source CVD pipeline을 전면에 둡니다. 표현은 다르지만 질문은 같습니다. 강한 사이버 모델을 누구에게, 어떤 통제 아래, 어떤 workflow로 제공할 것인가입니다.
Anthropic 쪽의 특징은 "제한 공개 모델로 먼저 발견하고, 공개 대시보드로 disclosure 상태를 추적한다"는 점입니다. OpenAI 쪽은 "trusted access와 Codex Security workflow로 방어팀 안에 모델을 넣는다"는 방향에 가깝습니다. AWS Security Agent나 Microsoft의 AI app misconfiguration 연구까지 포함하면, AI 보안 경쟁은 세 가지 축으로 나뉩니다. 모델 능력, 실행 harness, 그리고 운영 거버넌스입니다.
이번 CVD 대시보드는 세 번째 축을 강하게 드러냅니다. 모델이 얼마나 강한지는 벤치마크와 사례로 말할 수 있습니다. 하지만 운영 거버넌스는 숫자 흐름으로 드러납니다. 후보가 몇 건이고, 외부 검토는 몇 건이며, maintainer가 확인한 것은 몇 건이고, patch와 advisory는 몇 건인가. 이 흐름을 공개해야 "AI가 보안을 개선했다"는 주장이 실제 개선으로 이어지는지 볼 수 있습니다.
개발팀이 지금 봐야 할 것
첫째, dependency patch cycle을 다시 봐야 합니다. Mythos-class 모델이 취약점을 더 빨리 찾는다면, 공격자도 비슷한 능력을 갖는 시점이 옵니다. Anthropic도 이 점을 직접 경고합니다. 발견과 exploit 비용이 내려가면, 오래된 dependency를 몇 주씩 미루는 관행은 더 위험해집니다. Dependabot 알림을 보는 수준을 넘어, critical patch를 얼마나 빨리 테스트하고 배포할 수 있는지 측정해야 합니다.
둘째, 내부 코드에 대한 AI 보안 리뷰를 도입하더라도 triage capacity를 같이 설계해야 합니다. AI scanner를 켜면 report가 늘어납니다. report가 늘면 보안팀과 개발팀이 검증해야 할 일이 늘어납니다. 이때 finding quality, reproduction evidence, severity 기준, duplicate 제거, patch suggestion, test generation이 함께 없으면 도구는 alert fatigue만 키울 수 있습니다.
셋째, 오픈소스 maintainer와 소비자 사이의 책임 분담을 재정의해야 합니다. 기업은 "우리가 쓰는 라이브러리 maintainer가 알아서 고치겠지"라고 생각하기 어렵습니다. 프로젝트마다 maintainership capacity가 다르고, disclosure queue가 몰릴 수 있습니다. 중요한 dependency라면 기업 사용자가 patch testing, backport, funding, 보안 리뷰 지원을 제공해야 할 수도 있습니다.
넷째, 취약점 공개 대시보드는 제품 기능이 될 가능성이 큽니다. 앞으로 AI 보안 도구는 "몇 개 찾았다"보다 "몇 개가 검증됐고, 몇 개가 patch됐고, 몇 개가 production에 배포됐는가"를 보여줘야 합니다. 소프트웨어 보안의 KPI가 finding count에서 remediation flow로 이동하는 것입니다.
발견 속도와 패치 속도의 간격
이번 뉴스의 가장 큰 의미는 AI가 취약점을 찾을 수 있다는 사실이 아닙니다. 그 사실은 이미 여러 사례와 벤치마크로 충분히 예고됐습니다. Anthropic CVD 대시보드가 새롭게 보여준 것은 발견 속도와 패치 속도의 간격입니다. 23,019건 후보와 97건 upstream patch 사이에는 모델 능력보다 더 오래된 소프트웨어 운영 문제가 놓여 있습니다.
그 간격은 쉽게 사라지지 않습니다. 취약점은 code finding이 아니라 release event입니다. maintainer가 이해하고, 사용자가 업데이트하고, downstream 배포판이 반영하고, 기업 보안팀이 테스트하고, 운영 환경에서 충돌 없이 배포해야 끝납니다. AI는 이 과정의 많은 부분을 도울 수 있지만, 책임과 승인, 사용자 영향은 여전히 사람이 관리해야 합니다.
그래서 Glasswing의 첫 성적표는 낙관과 경고가 동시에 들어 있습니다. 낙관은 분명합니다. AI는 오래 숨어 있던 취약점을 훨씬 더 많이 찾고, 일부는 patch까지 빠르게 연결할 수 있습니다. 경고도 분명합니다. 보안 생태계가 그대로라면 finding flood는 방어력 향상보다 병목과 피로를 먼저 만들 수 있습니다. 앞으로의 승부는 "누가 더 많은 취약점을 찾는가"가 아니라 "누가 검증 가능한 패치 흐름을 더 잘 만드는가"에 가까워질 것입니다.